W zeszłym tygodniu dokonałem kilku szybkich porównań wydajności, używając nowego STRING_AGG() funkcja w stosunku do tradycyjnego FOR XML PATH podejście, którego używałem od wieków. Przetestowałem zarówno niezdefiniowaną/arbitralną kolejność, jak i jawną kolejność oraz STRING_AGG() w obu przypadkach wypadł na szczycie:
- SQL Server v.Next:Wydajność STRING_AGG(), część 1
W przypadku tych testów pominąłem kilka rzeczy (nie wszystkie celowo):
- Mikael Eriksson i Grzegorz Łyp wskazali, że nie używałem absolutnie najbardziej wydajnego
FOR XML PATHkonstrukt (a żeby było jasne, nigdy nie miałem). - Nie przeprowadzałem żadnych testów na Linuksie; tylko w systemie Windows. Nie spodziewam się, że będą one bardzo różne, ale ponieważ Grzegorz widział bardzo różne czasy trwania, warto to zbadać.
- Testowałem również tylko wtedy, gdy dane wyjściowe byłyby skończonym ciągiem niebędącym ciągiem znaków LOB – co moim zdaniem jest najczęstszym przypadkiem użycia (nie sądzę, że ludzie będą często łączyć każdy wiersz w tabeli w jeden oddzielony przecinkami string, ale właśnie dlatego poprosiłem w poprzednim poście o twoje przypadki użycia.
- W przypadku testów porządkowania nie stworzyłem indeksu, który mógłby być pomocny (ani nie próbowałem czegokolwiek, w którym wszystkie dane pochodzą z jednej tabeli).
W tym poście zajmę się kilkoma z tych elementów, ale nie wszystkimi.
DLA ŚCIEŻKI XML
Używałem następujących:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Po tym komentarzu Mikaela zaktualizowałem swój kod, aby zamiast tego używał nieco innej konstrukcji:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux kontra Windows
Początkowo zawracałem sobie głowę tylko uruchamianiem testów w systemie Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Ale Grzegorz miał rację, że on (i prawdopodobnie wielu innych) miał dostęp tylko do wersji CTP 1.1 dla Linuksa. Więc dodałem Linuksa do mojej macierzy testowej:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Kilka interesujących, ale całkowicie stycznych obserwacji:
@@VERSIONnie pokazuje edycji w tej kompilacji, aleSERVERPROPERTY('Edition')zwraca oczekiwanyDeveloper Edition (64-bit).- Na podstawie czasów kompilacji zakodowanych w plikach binarnych, wersje Windows i Linux wydają się być teraz kompilowane w tym samym czasie iz tego samego źródła. Albo to był jeden szalony zbieg okoliczności.
Testy nieuporządkowane
Zacząłem od przetestowania dowolnie uporządkowanego wyjścia (gdzie nie ma wyraźnie zdefiniowanego porządkowania połączonych wartości). Podążając za Grzegorzem, użyłem WideWorldImporters (Standard), ale wykonałem łączenie między Sales.Orders i Sales.OrderLines . Fikcyjnym wymaganiem jest tutaj wyświetlenie listy wszystkich zamówień, a wraz z każdym zamówieniem oddzielonej przecinkami listy każdego StockItemID .
Od StockItemID jest liczbą całkowitą, możemy użyć zdefiniowanego varchar , co oznacza, że ciąg może mieć 8000 znaków, zanim będziemy musieli martwić się o MAX. Ponieważ int może mieć maksymalną długość 11 (naprawdę 10, jeśli nie ma znaku), plus przecinek, oznacza to, że zamówienie musiałoby obsługiwać około 8 000/12 (666) pozycji magazynowych w najgorszym przypadku (np. wszystkie wartości StockItemID mają 11 cyfr). W naszym przypadku najdłuższy identyfikator to 3 cyfry, więc dopóki dane nie zostaną dodane, potrzebowalibyśmy 8000/4 (2000) unikalnych pozycji magazynowych w jednym zamówieniu, aby uzasadnić MAX. W naszym przypadku jest w sumie tylko 227 pozycji magazynowych, więc MAX nie jest konieczny, ale warto mieć na to oko. Jeśli tak duży ciąg jest możliwy w twoim scenariuszu, będziesz musiał użyć varchar(max) zamiast domyślnego (STRING_AGG() zwraca nvarchar(max) , ale obcina do 8000 bajtów, chyba że dane wejściowe jest typu MAX).
Początkowe zapytania (aby pokazać przykładowe dane wyjściowe i obserwować czasy trwania dla pojedynczych wykonań):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Całkowicie zignorowałem analizowanie i kompilację danych dotyczących czasu, ponieważ zawsze były one dokładnie zerowe lub wystarczająco bliskie, aby były nieistotne. Wystąpiły niewielkie różnice w czasach wykonania dla każdego uruchomienia, ale niewiele — powyższe komentarze odzwierciedlają typową różnicę w czasie wykonywania (STRING_AGG wydawało się, że trochę korzysta z równoległości, ale tylko w Linuksie, podczas gdy FOR XML PATH nie na żadnej platformie). Obie maszyny miały jedno gniazdo, czterordzeniowy procesor, 8 GB pamięci, gotową konfigurację i nie miały żadnej innej aktywności.
Następnie chciałem przetestować na dużą skalę (po prostu pojedynczą sesję wykonującą to samo zapytanie 500 razy). Nie chciałem zwracać wszystkich wyników, jak w powyższym zapytaniu, 500 razy, ponieważ przytłoczyłoby to SSMS – i mam nadzieję, że i tak nie reprezentuje rzeczywistych scenariuszy zapytań. Więc przypisałem wyjście do zmiennych i po prostu zmierzyłem całkowity czas dla każdej partii:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Przeprowadziłem te testy trzy razy i różnica była głęboka – prawie o rząd wielkości. Oto średni czas trwania trzech testów:
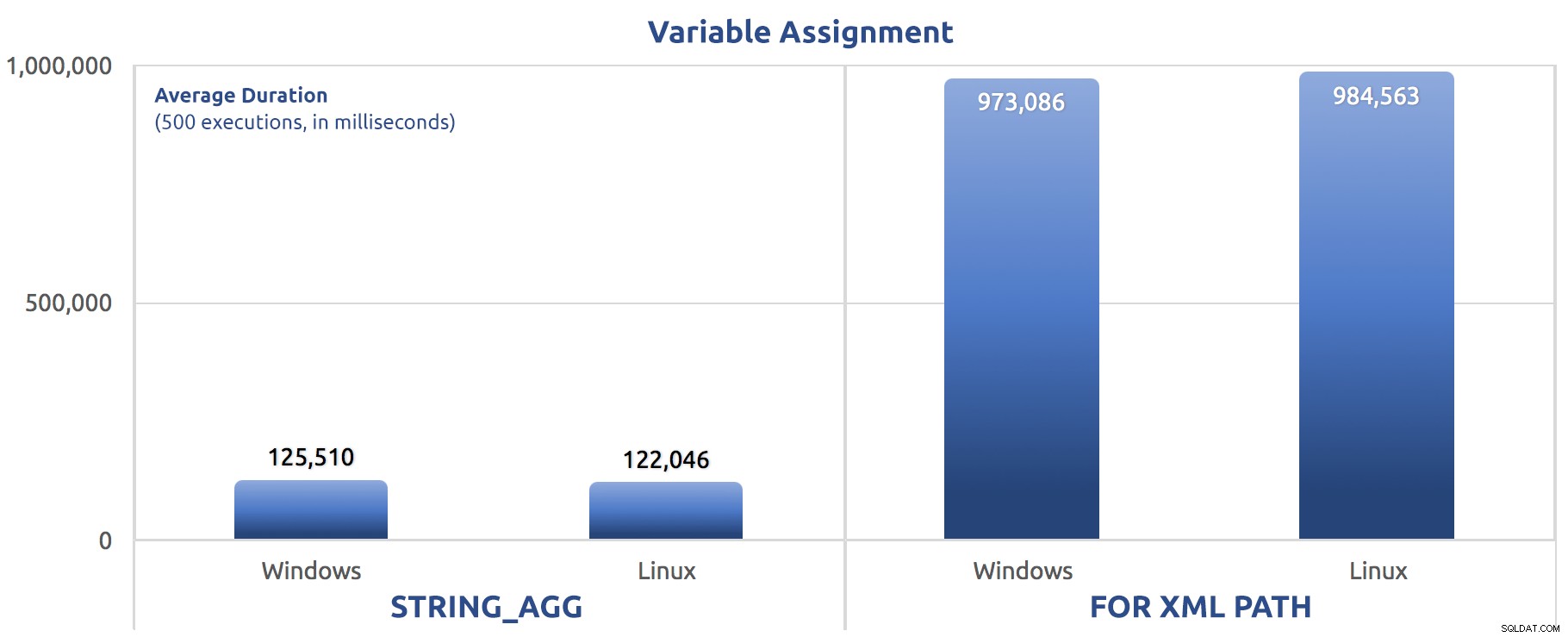 Średni czas trwania w milisekundach dla 500 wykonań przypisania zmiennej
Średni czas trwania w milisekundach dla 500 wykonań przypisania zmiennej
W ten sposób testowałem wiele innych rzeczy, głównie po to, by upewnić się, że omawiam typy testów, które prowadził Grzegorz (bez części LOB).
- Wybieranie tylko długości wyjścia
- Uzyskiwanie maksymalnej długości wyjścia (dowolnego wiersza)
- Wybieranie wszystkich danych wyjściowych do nowej tabeli
Wybieranie tylko długości wyjścia
Ten kod po prostu przechodzi przez każde zamówienie, łączy wszystkie wartości StockItemID, a następnie zwraca tylko długość.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ W przypadku wersji wsadowej ponownie użyłem przypisania zmiennych, zamiast próbować zwrócić wiele zestawów wyników do SSMS. Przypisanie zmiennej skończyłoby się na dowolnym wierszu, ale nadal wymaga to pełnego skanowania, ponieważ dowolny wiersz nie jest zaznaczany jako pierwszy.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Wskaźniki wydajności 500 wykonań:
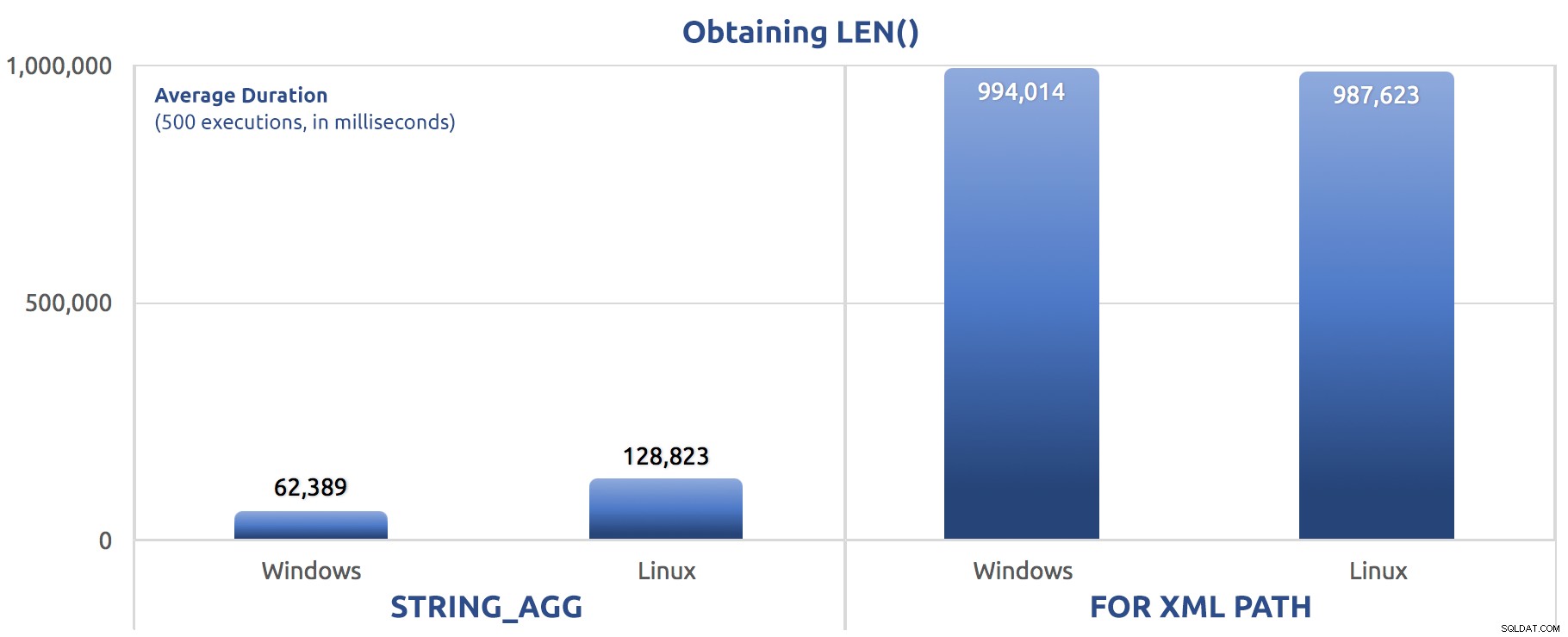 500 wykonań przypisania LEN() do zmiennej
500 wykonań przypisania LEN() do zmiennej
Ponownie widzimy FOR XML PATH jest znacznie wolniejszy, zarówno w systemie Windows, jak i Linux.
Wybieranie maksymalnej długości wyjścia
Niewielka odmiana poprzedniego testu, ten po prostu pobiera maksimum długość połączonego wyjścia:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ I w skali, po prostu ponownie przypisujemy to wyjście do zmiennej:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Wyniki wydajności dla 500 wykonań, uśrednione dla trzech przebiegów:
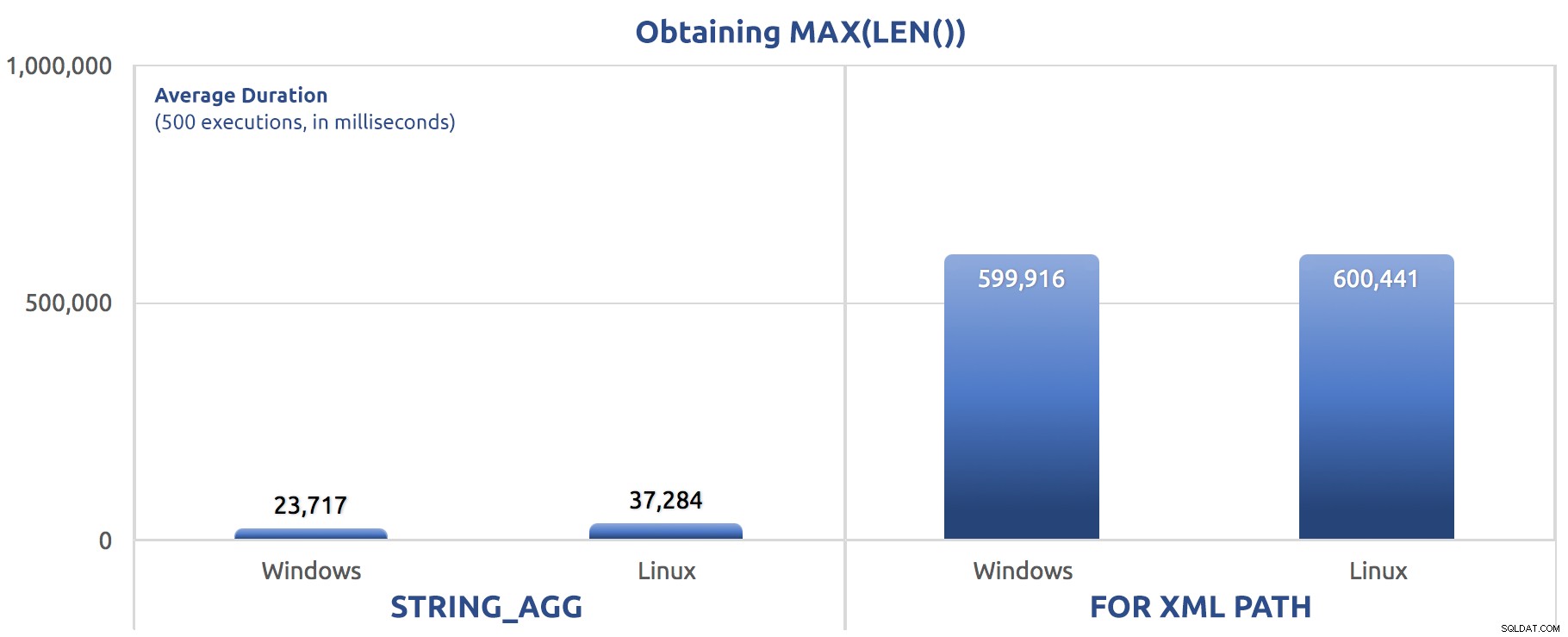 500 wykonań przypisania MAX(LEN()) do zmiennej
500 wykonań przypisania MAX(LEN()) do zmiennej
Możesz zacząć zauważać wzorzec w tych testach — FOR XML PATH jest zawsze psem, nawet z ulepszeniami wydajności sugerowanymi w moim poprzednim poście.
WYBIERZ DO
Chciałem sprawdzić, czy metoda konkatenacji ma jakiś wpływ na pisanie dane z powrotem na dysk, tak jak w niektórych innych scenariuszach:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
W tym przypadku widzimy, że być może SELECT INTO był w stanie wykorzystać trochę paralelizmu, ale nadal widzimy FOR XML PATH walka, z czasem pracy o rząd wielkości dłuższym niż STRING_AGG .
Wersja wsadowa właśnie zamieniła polecenia SET STATISTICS dla SELECT sysdatetime(); i dodałem ten sam GO 500 po dwóch głównych partiach jak w poprzednich testach. Oto, jak to się potoczyło (ponownie, powiedz mi, czy słyszałeś to wcześniej):
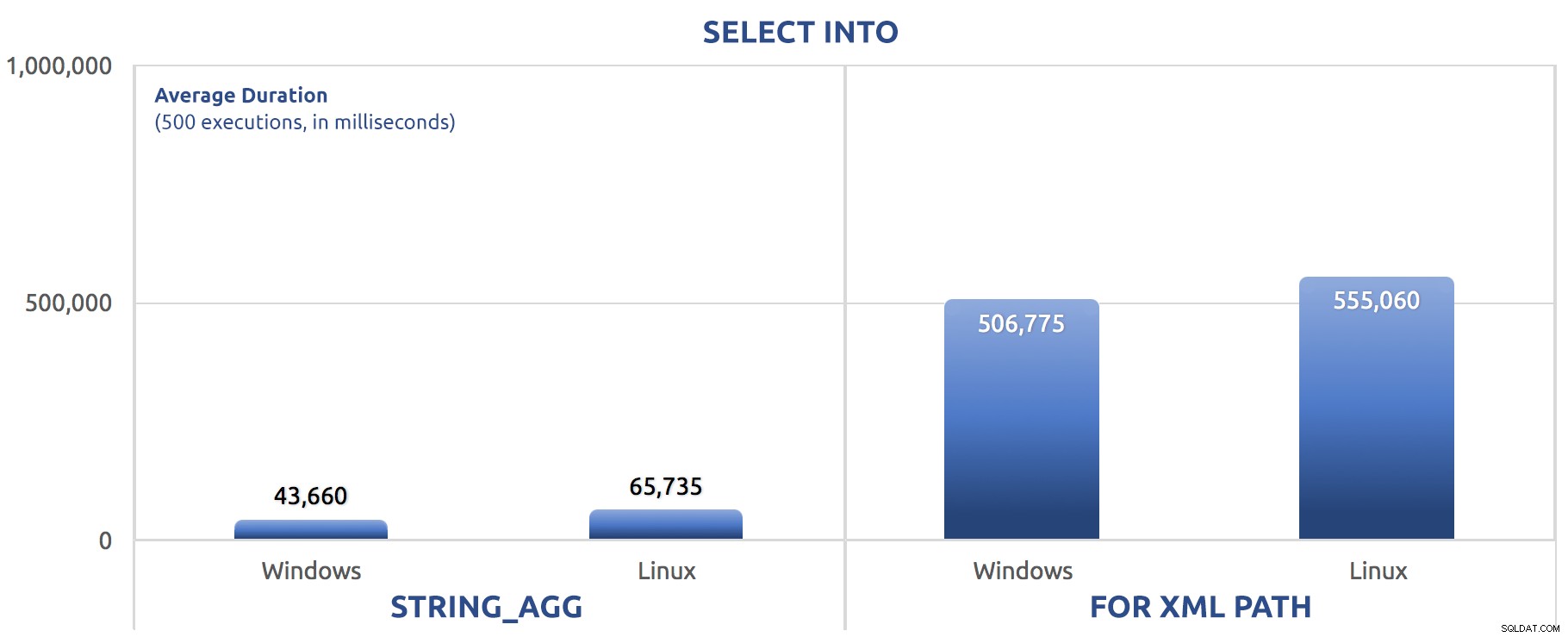 500 wykonań SELECT INTO
500 wykonań SELECT INTO
Zamówione testy
Przeprowadziłem te same testy przy użyciu uporządkowanej składni, np.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Miało to bardzo niewielki wpływ na wszystko — ten sam zestaw czterech platform testowych wykazał prawie identyczne metryki i wzorce na całej planszy.
Będę ciekaw, czy jest inaczej, gdy połączone wyjście jest w trybie innym niż LOB lub gdy konkatenacja wymaga uporządkowania ciągów (z indeksem pomocniczym lub bez).
Wniosek
Dla ciągów innych niż LOB , jasne jest dla mnie, że STRING_AGG ma zdecydowaną przewagę wydajności nad FOR XML PATH , zarówno w systemie Windows, jak i Linux. Zauważ, że aby uniknąć wymagania varchar(max) lub nvarchar(max) , nie użyłem niczego podobnego do testów przeprowadzonych przez Grzegorza, co oznaczałoby po prostu połączenie wszystkich wartości z kolumny, w całej tabeli, w jeden ciąg. W następnym poście przyjrzę się przypadkowi użycia, w którym dane wyjściowe połączonego ciągu mogą być większe niż 8000 bajtów, a zatem musiałyby zostać użyte typy LOB i konwersje.