Chociaż SQL Server w systemie Linux ukradł prawie wszystkie nagłówki na temat v.Next, w kolejnej wersji naszej ulubionej platformy bazodanowej pojawi się kilka innych interesujących postępów. Na froncie T-SQL mamy wreszcie wbudowany sposób wykonywania zgrupowanych konkatenacji ciągów:STRING_AGG() .
Załóżmy, że mamy następującą prostą strukturę tabeli:
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);
W przypadku testów wydajności wypełnimy to za pomocą sys.all_objects i sys.all_columns . Ale najpierw dla prostej demonstracji dodajmy następujące wiersze:
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID'); Jeśli fora są jakąkolwiek wskazówką, bardzo powszechnym wymogiem jest zwrócenie wiersza dla każdego obiektu wraz z rozdzieloną przecinkami listą nazw kolumn. (Ekstrapoluj to na dowolne typy jednostek, które modelujesz w ten sposób – nazwy produktów powiązane z zamówieniem, nazwy części biorących udział w montażu produktu, podwładni zgłaszający się do kierownika itp.) Tak więc na przykład z powyższymi danymi będziemy chcesz uzyskać taki wynik:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
Sposób, w jaki moglibyśmy to osiągnąć w obecnych wersjach SQL Server, to prawdopodobnie użycie FOR XML PATH , jak pokazałem, że jest najbardziej wydajny poza CLR w tym wcześniejszym poście. W tym przykładzie wyglądałoby to tak:
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Jak można się było spodziewać, otrzymujemy ten sam wynik, co pokazano powyżej. W SQL Server v.Next będziemy mogli wyrazić to prościej:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Ponownie daje to dokładnie takie same dane wyjściowe. Udało nam się to zrobić za pomocą funkcji natywnej, unikając kosztownego FOR XML PATH rusztowanie i STUFF() funkcja używana do usunięcia pierwszego przecinka (odbywa się to automatycznie).
A co z zamówieniem?
Jednym z problemów związanych z wieloma rozwiązaniami grupowych konkatenacji jest to, że kolejność listy oddzielonej przecinkami powinna być uważana za arbitralną i niedeterministyczną.
Dla XML PATH rozwiązanie, które pokazałem w innym wcześniejszym poście, że dodanie ORDER BY jest trywialne i gwarantowane. Tak więc w tym przykładzie możemy uporządkować listę kolumn według nazwy kolumny alfabetycznie, zamiast pozostawiać ją do sortowania SQL Server (lub nie):
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Wyjście:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
CTP 1.1 dodaje WITHIN GROUP do STRING_AGG() , więc korzystając z nowego podejścia, możemy powiedzieć:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Teraz otrzymujemy te same wyniki. Zwróć uwagę, że tak jak w normalnym ORDER BY klauzuli, możesz dodać wiele kolumn porządkowych lub wyrażeń wewnątrz WITHIN GROUP () .
W porządku, już wydajność!
Używając czterordzeniowych procesorów 2,6 GHz, 8 GB pamięci i SQL Server CTP1.1 (14.0.100.187), stworzyłem nową bazę danych, odtworzyłem te tabele i dodałem wiersze z sys.all_objects i sys.all_columns . Upewniłem się, że uwzględniam tylko obiekty, które mają co najmniej jedną kolumnę:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
); W moim systemie dało to 656 obiektów i 8085 kolumn (Twój system może dać nieco inne liczby).
Plany
Najpierw porównajmy plany i karty we/wy tabeli dla naszych dwóch nieuporządkowanych zapytań, używając Eksploratora planów. Oto ogólne dane dotyczące czasu działania:
 Wskaźniki środowiska wykonawczego dla ścieżki XML PATH (na górze) i STRING_AGG() (na dole)
Wskaźniki środowiska wykonawczego dla ścieżki XML PATH (na górze) i STRING_AGG() (na dole)
Plan graficzny i tabela I/O z FOR XML PATH zapytanie:
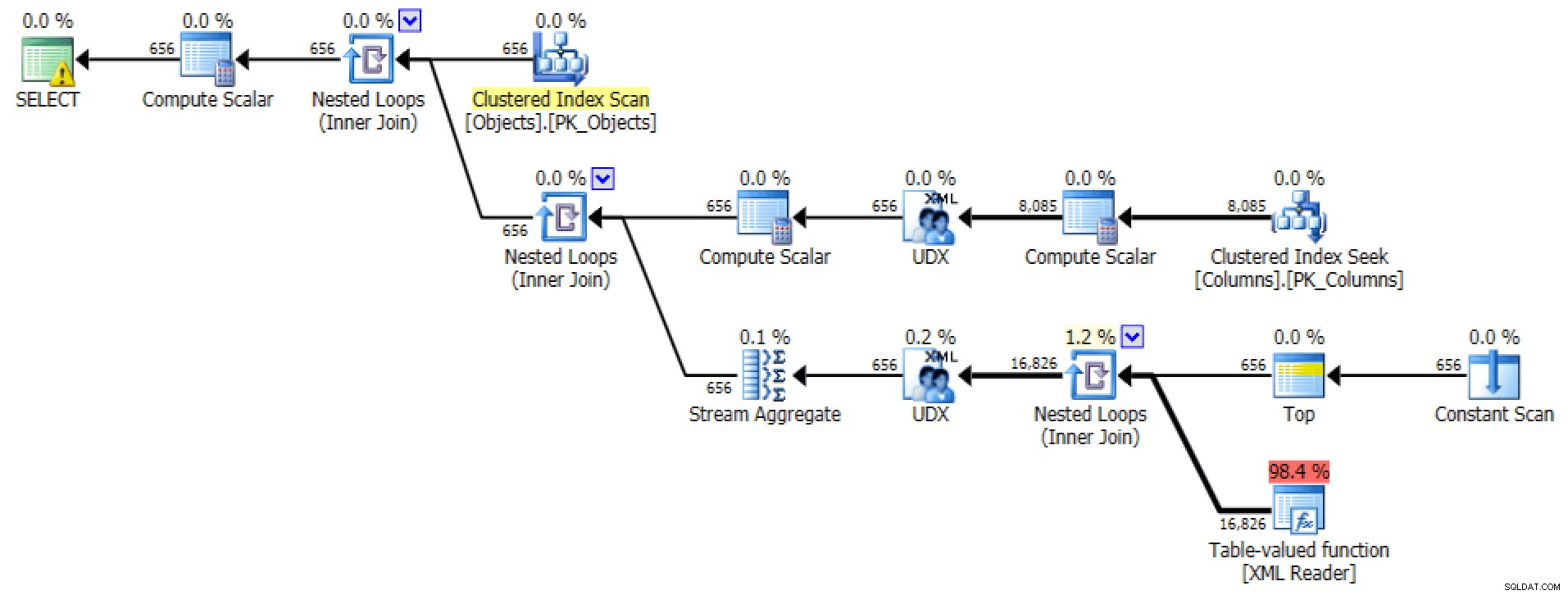
 I/O planu i tabeli dla ścieżki XML PATH, bez kolejności
I/O planu i tabeli dla ścieżki XML PATH, bez kolejności
I z STRING_AGG wersja:
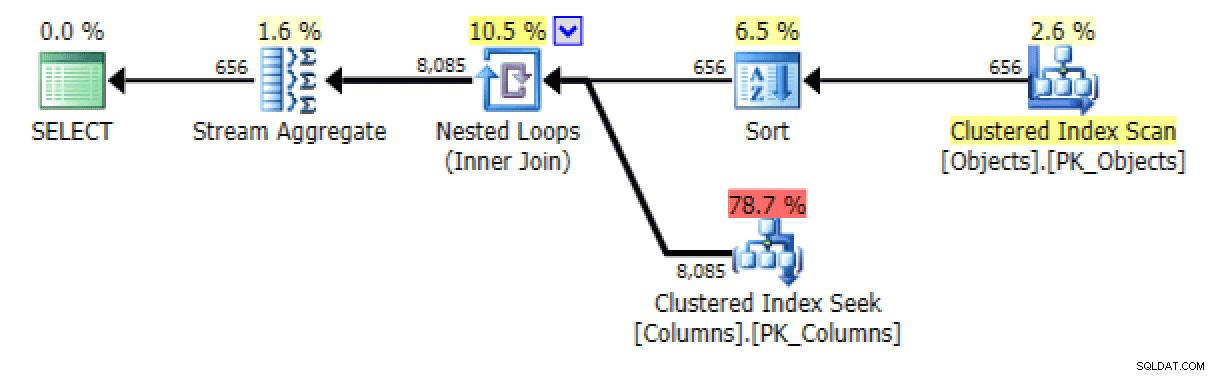
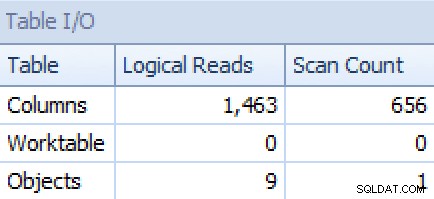 I/O planu i tabeli dla STRING_AGG, brak zamawiania
I/O planu i tabeli dla STRING_AGG, brak zamawiania
W przypadku tych ostatnich wyszukiwanie indeksu klastrowego wydaje mi się trochę kłopotliwe. Wydawało się, że to dobry przypadek do przetestowania rzadko używanego FORCESCAN wskazówka (i nie, to z pewnością nie pomogłoby w FOR XML PATH zapytanie):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name]; Teraz plan i karta I/O tabeli wyglądają dużo lepiej, przynajmniej na pierwszy rzut oka:
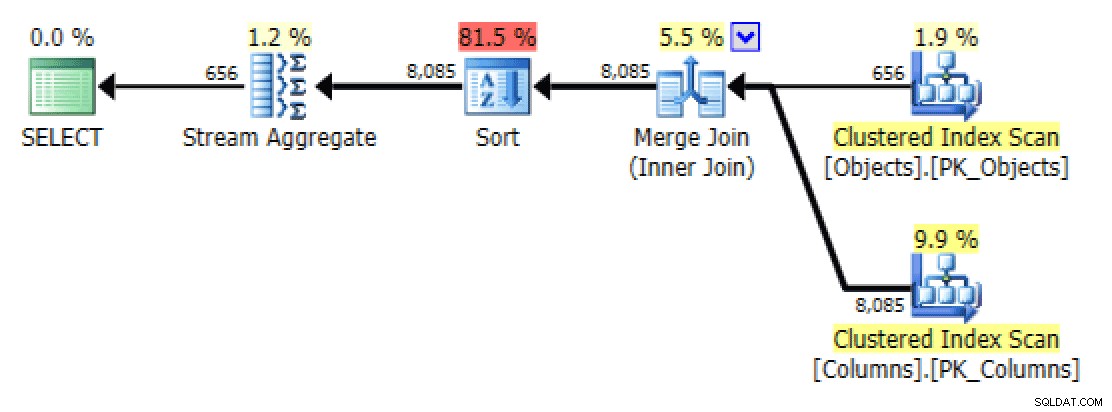
 I/O planu i tabeli dla STRING_AGG(), bez porządkowania, z FORCESCAN
I/O planu i tabeli dla STRING_AGG(), bez porządkowania, z FORCESCAN
Uporządkowane wersje zapytań generują mniej więcej te same plany. Dla FOR XML PATH wersji, dodaje się sortowanie:
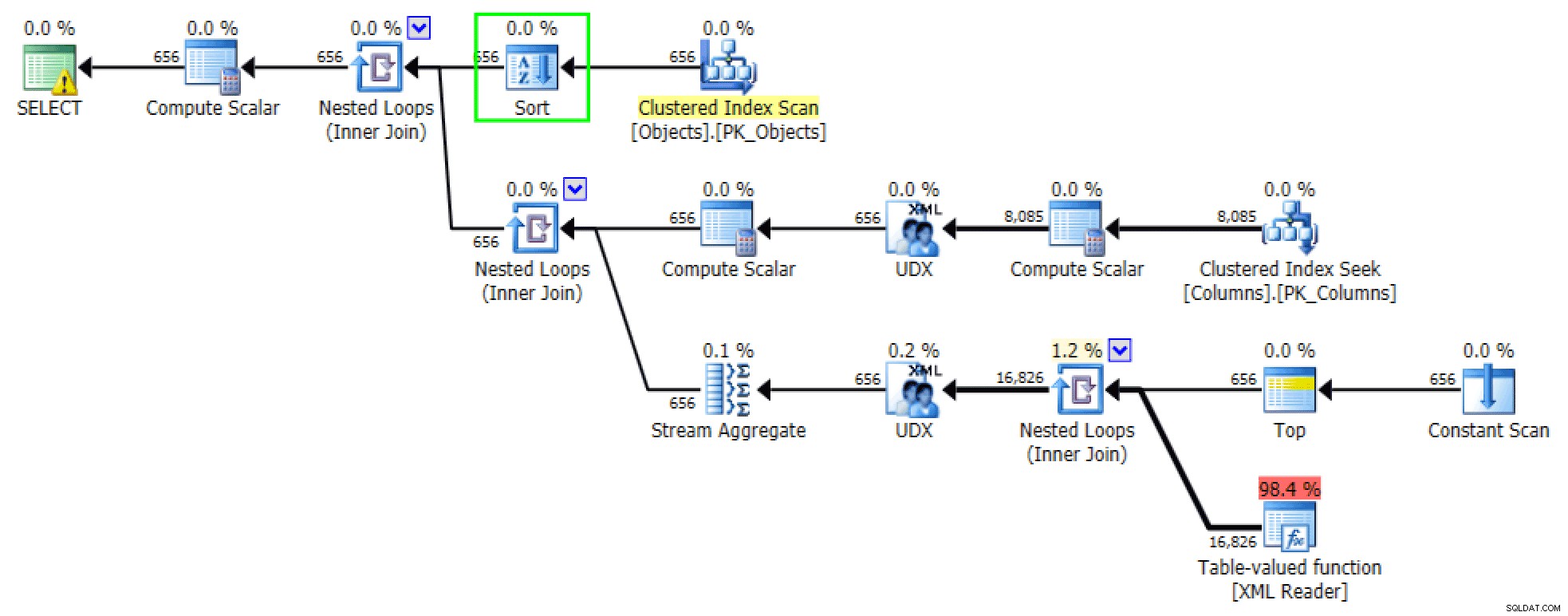 Dodano sortowanie w wersji FOR XML PATH
Dodano sortowanie w wersji FOR XML PATH
Dla STRING_AGG() , w tym przypadku wybierane jest skanowanie, nawet bez FORCESCAN podpowiedź i nie jest wymagana dodatkowa operacja sortowania – więc plan wygląda identycznie jak FORCESCAN wersja.
W skali
Spojrzenie na plan i jednorazowe metryki środowiska wykonawczego może dać nam pewne wyobrażenie o tym, czy STRING_AGG() działa lepiej niż istniejący FOR XML PATH rozwiązanie, ale większy test może mieć więcej sensu. Co się stanie, gdy wykonamy zgrupowaną konkatenację 5000 razy?
SELECT SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered, forcescan] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o; GO 5000 SELECT [for xml path, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, ordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] ORDER BY c.column_name FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o ORDER BY o.[object_name]; GO 5000 SELECT [for xml path, ordered] = SYSDATETIME();
Po pięciokrotnym uruchomieniu tego skryptu uśredniłem liczby czasu trwania i oto wyniki:
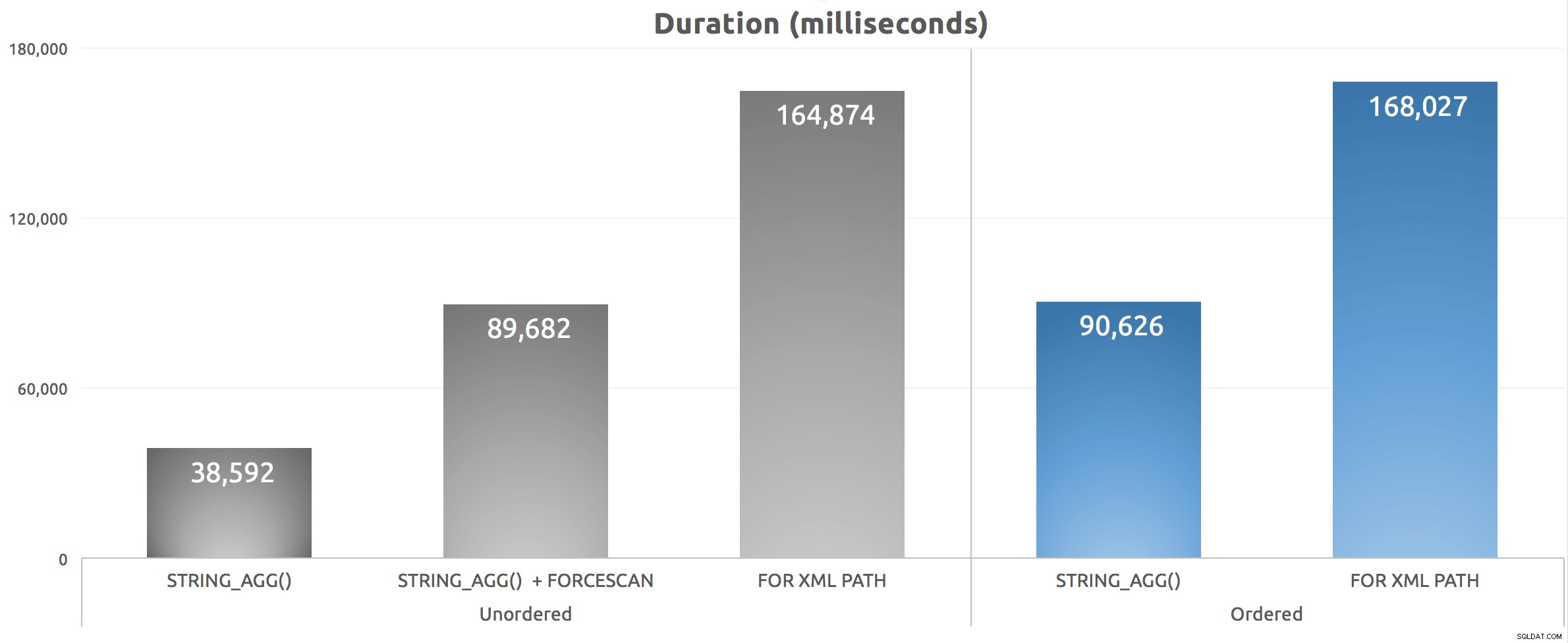 Czas trwania (milisekundy) dla różnych metod łączenia grupowego
Czas trwania (milisekundy) dla różnych metod łączenia grupowego
Widzimy, że nasz FORCESCAN wskazówka naprawdę pogorszyła sprawę – podczas gdy przesunęliśmy koszt z wyszukiwania indeksu klastrowego, sortowanie było w rzeczywistości znacznie gorsze, mimo że szacunkowe koszty uznawały je za stosunkowo równoważne. Co ważniejsze, widzimy, że STRING_AGG() oferuje korzyści związane z wydajnością, niezależnie od tego, czy połączone ciągi muszą być uporządkowane w określony sposób. Tak jak w przypadku STRING_SPLIT() , który przeglądałem w marcu, jestem pod wrażeniem, że ta funkcja skaluje się dobrze przed wersją „v1”.
Mam zaplanowane dalsze testy, być może w przyszłym poście:
- Kiedy wszystkie dane pochodzą z jednej tabeli, z indeksem obsługującym porządkowanie lub bez niego
- Podobne testy wydajności w systemie Linux
W międzyczasie, jeśli masz konkretne przypadki użycia grupowej konkatenacji, udostępnij je poniżej (lub napisz do mnie na adres abertrand@sentryone.com). Zawsze jestem otwarty na upewnienie się, że moje testy są jak najbardziej rzeczywiste.