Na całym świecie portal z ofertami pracy jest dobrze znaną cechą krajobrazu internetowego. Wielcy gracze, tacy jak Indeed i Monster, przekształcili poszukiwanie pracy i rekrutację w prawdziwą branżę online. Zagłębmy się w podstawowe funkcje wykorzystywane przez portale pracy i zbudujmy model danych, który może je wspierać.
Ludzie uwielbiają oszczędzać czas dzięki innowacjom technologicznym; internetowy portal pracy to kolejna wersja pracy mądrzej, a nie ciężej. Zarówno osoby poszukujące pracy, jak i firmy zdają sobie sprawę z wartości wyszukiwania w Internecie:uzyskują lepszy zasięg przy wyższych prędkościach i niższych kosztach.
Branża portali pracy jest obecnie dość ustabilizowana, przynajmniej jeśli chodzi o natężenie ruchu. Osoby poszukujące pracy korzystają z tych portali, aby znaleźć stanowiska w wielu branżach, wykraczając poza IT do sektorów takich jak inżynieria, sprzedaż, produkcja i usługi finansowe. Jednak dostają silną konkurencję ze strony mediów społecznościowych i profesjonalnych serwisów sieciowych, takich jak LinkedIn. Ale nadal istnieją możliwości do zbadania, takie jak rozszerzenie ich penetracji na obszary wiejskie i mniejsze miasta.
Tak jak powiedzieliśmy, zamierzamy zbadać ten temat z perspektywy projektowania baz danych. Zacznijmy od wyliczenia podstawowych oczekiwań wobec portalu pracy.
Czego ludzie oczekują od internetowego portalu pracy?
Zarówno pracodawcy, jak i osoby poszukujące pracy oczekują następujących funkcji od strony internetowej z ofertami pracy:
- Ludzie mogą rejestrować się jako osoby poszukujące pracy, tworzyć swoje profile i szukać pracy pasującej do ich umiejętności.
- Użytkownicy mogą przesyłać swoje istniejące CV. Jeśli go nie mają, powinni być w stanie wypełnić formularz i przygotować dla nich CV.
- Ludzie mogą aplikować bezpośrednio na opublikowane oferty pracy.
- Firmy mogą się rejestrować, publikować oferty pracy i wyszukiwać profile osób poszukujących pracy.
- Wielu przedstawicieli firmy powinno mieć możliwość rejestracji i zamieszczania ofert pracy.
- Przedstawiciele firmy mogą przeglądać listę kandydatów do pracy i mogą się z nimi kontaktować, prowadzić rozmowę kwalifikacyjną lub wykonywać inne czynności związane z ich stanowiskiem.
- Zarejestrowani użytkownicy powinni mieć możliwość wyszukiwania ofert pracy i filtrowania wyników na podstawie lokalizacji, wymaganych umiejętności, wynagrodzenia, poziomu doświadczenia itp.
Budowanie modelu danych
Po rozważeniu powyższych wymagań wymyśliłem trzy szerokie kategorie funkcjonalne:
- Zarządzanie użytkownikami – Jak portal zarządza użytkownikami, tj. osobami poszukującymi pracy, personelem HR oraz rekruterami niezależnymi lub konsultingowymi. (Na potrzeby tego modelu indywidualni przedstawiciele HR oraz niezależni lub konsultingowi rekruterzy są traktowani jak firmy, przynajmniej w zakresie tego, w jaki sposób korzystają z portalu.)
- Profile budynków – W jaki sposób portal umożliwia osobom poszukującym pracy i organizacjom tworzenie profili i życiorysów.
- Publikowanie i wyszukiwanie ofert pracy – Jak portal ułatwia proces publikowania, wyszukiwania i ubiegania się o pracę.
Przyjrzyjmy się każdemu z tych obszarów osobno.
1. Zarządzanie użytkownikami
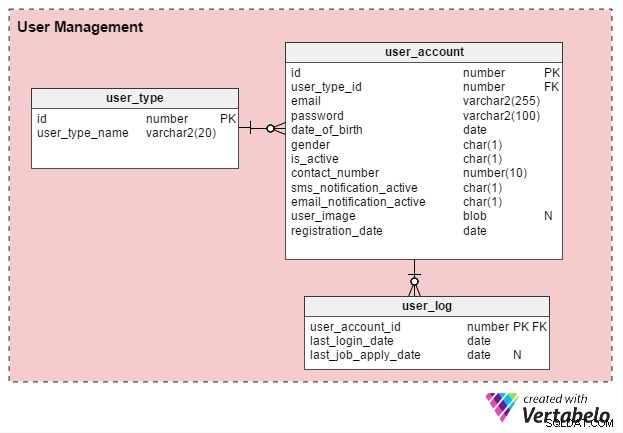
Istnieją przede wszystkim dwa rodzaje użytkowników internetowych portali pracy:osoby poszukujące pracy indywidualne oraz osoby zajmujące się rekrutacją HR (lub niezależni konsultanci ds. rekrutacji). Stwórzmy tabelę o nazwie user_type do przechowywania tych zapisów. Na początek będzie miał dwa rekordy – jeden dla osób poszukujących pracy, a drugi dla rekrutujących. (W razie potrzeby zawsze możemy utworzyć dodatkowe typy rekordów).
Użytkownicy muszą się zarejestrować, zanim będą mogli korzystać z portalu. user_account tabela przechowuje podstawowe dane konta. Wcześniej rozważałem nazwanie tej tabeli „użytkownik”, ale ponieważ użytkownik jest słowem kluczowym zdefiniowanym przez system w prawie wszystkich bazach danych, wolę pozostać przy „koncie_użytkownika”.
user_account tabela ma następujące kolumny:
- identyfikator – Jest to zarówno klucz podstawowy tabeli, jak i unikalny identyfikator dla każdego użytkownika. Do tego identyfikatora będą odnosić się inne tabele w modelu danych.
- user_type_id – Oznacza to, czy użytkownik jest osobą poszukującą pracy, czy rekruterem.
- e-mail – Ta kolumna zawiera adres e-mail użytkownika. Działa jako kolejny identyfikator użytkownika portalu.
- hasło – To przechowuje zaszyfrowane hasło do konta (utworzone przez użytkowników podczas rejestracji).
- data_urodzenia i płeć – Jak sugerują ich nazwy, kolumny te zawierają datę urodzenia i płeć użytkowników.
- jest_aktywny – Początkowo ta kolumna będzie miała wartość „Y”, ale użytkownicy mogą ustawić swój profil na nieaktywny lub „N”. Ta kolumna przechowuje ich wybór.
- numer_kontaktu – Jest to numer telefonu (zazwyczaj komórkowego) podany podczas rejestracji. Na ten numer użytkownicy mogą otrzymywać powiadomienia SMS (sms). Może to być ten sam numer (lub nie), co osoba poszukująca pracy na liście w swoim profilu lub życiorysie.
- sms_notification_active i email_notification_active – Te kolumny przechowują preferencje użytkowników dotyczące otrzymywania powiadomień SMS-em i/lub e-mailem.
- obraz_użytkownika – Jest to atrybut typu BLOB, który przechowuje zdjęcie profilowe każdego użytkownika. Ponieważ ten portal pozwala tylko na jedno zdjęcie profilowe na użytkownika, sensowne jest zapisanie go tutaj.
- data_rejestracji – Ta kolumna zawiera zapis, kiedy użytkownik zarejestrował się w portalu.
Utworzymy jeszcze jedną tabelę, user_log , który przechowuje zapis daty ostatniego logowania użytkownika i daty ostatniego podania o pracę. Istnieje wiele funkcji, które można zbudować na tej wiedzy. Na przykład możemy wykorzystać te informacje, aby odpowiedzieć na pytanie Czy użytkownik X aktywnie szuka pracy ? Jeśli tak, można im zaproponować produkt do stworzenia efektywnego CV. Użytkownicy, którzy nie szukają aktywnie pracy, nie otrzymaliby takiej oferty.
2. Profile budynków
Możemy dalej podzielić tę sekcję na dwa obszary:profile firmy lub organizacji oraz profile osób poszukujących pracy.
Profile firm
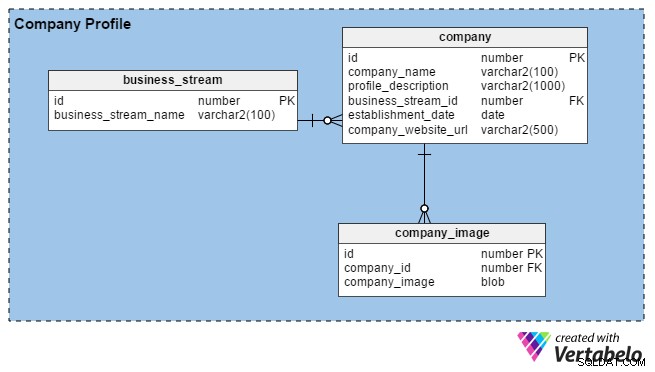
Zazwyczaj zespoły HR budują profile firmy, wprowadzając szczegóły dotyczące ich organizacji oraz wizerunki swoich biur, budynków itp. Ich głównym celem jest przyciągnięcie dobrych talentów. Kiedy rekruterzy rejestrują się w portalu, oni również mogą tworzyć profile swoich firm (lub ich marki osobistej, jeśli są niezależni), podając podstawowe informacje, takie jak czas prowadzenia działalności, lokalizacja i główny strumień biznesowy ( np. produkcja, usługi IT, finanse itp.
Portal umożliwia rekruterom HR i konsultingu przesłanie dowolnej liczby zdjęć (w przeciwieństwie do osób poszukujących pracy, które mogą przesłać tylko jedno). Dlatego stworzyliśmy company_image tabela do przechowywania wielu obrazów dla każdego konta rekrutującego. identyfikator firmy kolumna w tej tabeli jest kluczem obcym, który odnosi się do unikalnego identyfikatora używanego w company tabela.
W company tabeli mamy następujące kolumny:
- identyfikator – Klucz podstawowy tej tabeli jest również używany do jednoznacznej identyfikacji firm.
- nazwa_firmy – Jak sugeruje nazwa kolumny, zawiera ona prawną nazwę firmy.
- profile_description – Zawiera krótki opis każdej firmy.
- business_stream_id – Ta kolumna pokazuje, do jakiego strumienia biznesowego należy firma. Na przykład firma zajmująca się poszukiwaniem ropy i gazu może zatrudnić inżynierów IT , ale ich głównym nurtem biznesowym pozostaje „Ropa i Gaz”.
- data_zakładu – W tej kolumnie dowiesz się, ile lat ma firma.
- company_website_url – To jest obowiązkowa (nie dopuszczająca wartości null) kolumna. Zawiera wskaźnik do oficjalnej strony internetowej firmy, dzięki czemu osoby poszukujące pracy mogą znaleźć więcej informacji.
Wreszcie business_stream tabela ma tylko dwa atrybuty, identyfikator, który jest kluczem podstawowym dla tej tabeli, oraz opis głównego strumienia biznesowego firmy (business_stream_name ).
Profile osób poszukujących pracy
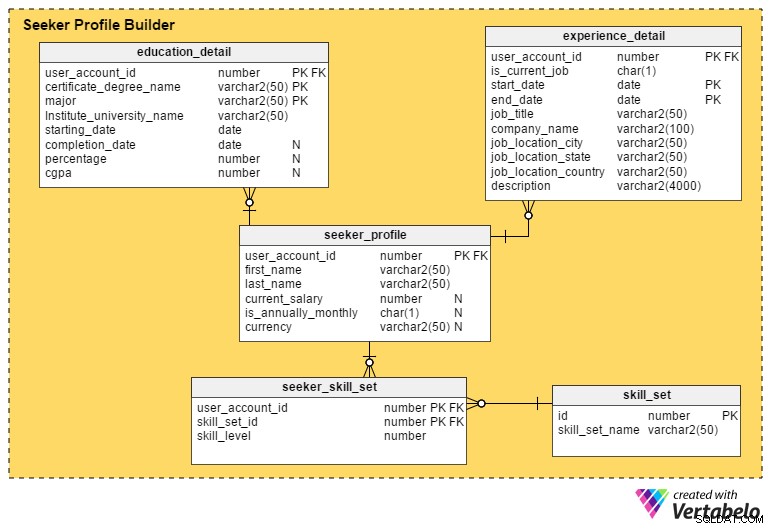
To jest najbardziej krytyczna sekcja portalu pracy. O ile portal nie przechwyci jak największej liczby szczegółów od osób poszukujących pracy, rekruterom trudno będzie umieścić na krótkiej liście profile lub kandydatów.
seeker_profile tabela zawiera dodatkowe szczegóły, które nie zostały przechwycone podczas procesu rejestracji. Zawiera te pola:
- user_account_id – Ta kolumna pochodzi z
user_accounttabeli i działa jako klucz podstawowy dla tej tabeli. Gwarantuje, że na osobę poszukującą pracy przypada maksymalnie jeden profil. - imię i nazwisko – Jak sugerują nazwy, te kolumny zawierają imię i nazwisko osoby poszukującej pracy.
- bieżąca_wynagrodzenie – Ten atrybut zawiera aktualną pensję osoby poszukującej pracy. Jest nieważny, ponieważ ludzie mogą nie chcieć go ujawniać.
- is_annually_monthly – To określa, czy ich wysokość wynagrodzenia jest roczna czy miesięczna.
- waluta – To przechowuje walutę wynagrodzenia.
education_detail tabela przechowuje dostarczoną przez nich historię edukacyjną każdej osoby poszukującej pracy. Ma złożony klucz podstawowy składający się z user_account_id , certificate_degree_name i główne kolumny. Dzięki temu użytkownicy wprowadzą tylko jeden rekord dla każdego stopnia lub świadectwa. Tabela zawiera następujące atrybuty:
- user_account_id – Ta kolumna pochodzi z
user_accounttabeli i służy jako klucz podstawowy dla tej tabeli. - certificate_degree_name – To jest rodzaj świadectwa lub stopnia; np. świadectwo ukończenia szkoły średniej, średniej, absolwenta, podyplomowego lub zawodowego.
- główne – W tej kolumnie znajduje się główny kierunek studiów na świadectwo lub stopień – m.in. licencjat ze specjalizacją informatyka.
- institute_university_name – To jest instytut, szkoła lub uniwersytet, który przyznał stopień lub certyfikat.
- data_początkowa – Ten atrybut przechowuje datę przyjęcia użytkownika do programu edukacyjnego.
- data_ukończenia – To data przyznania stopnia lub certyfikatu. Jednak ten atrybut może mieć wartość null; ludzie mogą nadal kończyć swój program, gdy szukają pracy lub całkowicie z niego zrezygnowali.
- procent i cgpa – Te kolumny przechowują procent ocen lub CGPA (skumulowaną średnią ocen) uzyskaną przez użytkowników na ich dyplomach lub kursach certyfikacyjnych.
experience_detail tabela prowadzi ewidencję przeszłych i obecnych doświadczeń zawodowych użytkowników. Zawiera następujące ważne kolumny:
- user_account_id – Ta kolumna pochodzi z
user_accounttabeli i jest kluczem podstawowym dla tej tabeli. - is_current_job – Jest to kolumna wskaźnika, która wskazuje aktualne zadanie użytkownika. Ta kolumna odgrywa również ważną rolę w określaniu bieżącej lokalizacji użytkowników i tego, jak długo utrzymują swoją obecną pozycję.
- data_początkowa – Przechowuje, gdy użytkownik rozpoczyna pracę.
- data_końcowa – Przechowuje, gdy użytkownik kończy pracę.
- job_title – Zawiera informacje o roli zawodowej użytkownika.
- nazwa_firmy – Ten atrybut zawiera odpowiednią nazwę firmy powiązaną z pracą.
- miejsce_pracy_miejsce_pracy – Oznacza to miasto, w którym znajdowała się praca.
- stan_lokalizacji_pracy – Oznacza to stan, w którym znajdowała się praca.
- miejsce_pracy_kraj – Oznacza to kraj, w którym znajdowała się praca.
- opis – Ta kolumna zawiera szczegółowe informacje na temat ról zawodowych i obowiązków, wyzwań i osiągnięć.
Osoby poszukujące pracy mogą posiadać wiele umiejętności. Aby prowadzić rejestr wszystkich tych zestawów umiejętności, utworzymy tabelę seeker_skill_set . Kolumny to:
- user_account_id – Ta kolumna pochodzi z
user_accounttabeli i jest kluczem podstawowym dla tej tabeli. - skill_set_id – Ten identyfikator wskazuje, jaki zestaw umiejętności posiada użytkownik.
- poziom_umiejętności – Ten atrybut liczbowy określa ilościowo wiedzę osób poszukujących pracy w zakresie określonej umiejętności. Liczba od 1 (początkujący) do 10 (ekspert) wskazuje ich poziom doświadczenia.
Wreszcie skill_set tabela zawiera opisy wszystkich umiejętności, o których mowa w powyższej tabeli skill_set_id atrybut. Zawiera tylko dwie kolumny, skill_set_name i powiązany z nim id .
3. Publikowanie i wyszukiwanie ofert pracy
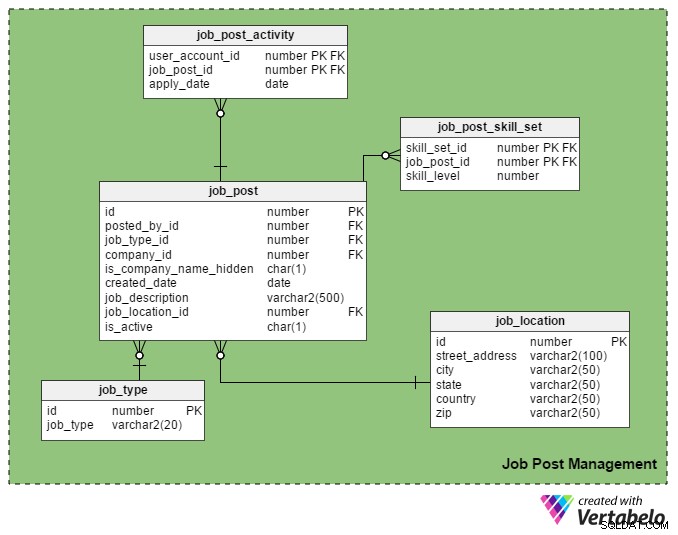
To jest główny USP (Unique Selling Point) portalu pracy. Tylko zarejestrowani rekruterzy mogą zamieszczać oferty pracy na portalu i tylko zarejestrowane osoby poszukujące pracy mogą do nich aplikować.
job_post tabela jest główną tabelą w tym obszarze tematycznym. Jak można się domyślić, zawiera szczegółowe informacje o ofertach pracy. Wszystkie inne tabele w tej sekcji są tworzone wokół niego i połączone z nim.
- identyfikator – To jest klucz podstawowy tej tabeli. Każdemu stanowisku pracy nadawany jest unikalny numer, a numer ten znajduje się w innych tabelach.
- posted_by_id – Ta kolumna zawiera register_user_id osoby rekrutującej, która opublikowała ofertę pracy.
- job_type_id – Ta kolumna wskazuje, czy czas pracy jest stały czy tymczasowy (umowa).
- identyfikator_firmy – W tej kolumnie przechowywany jest identyfikator firmy związany ze stanowiskiem pracy. Jest to odniesienie do
companystół. - is_company_name_hidden – To jest kolumna z flagą, która pokazuje, czy nazwa firmy powinna być pokazywana osobom poszukującym pracy. Rekruterzy mogą chcieć nie pokazywać nazw firm w swoich postach. Zamiast tego używają terminów takich jak „Global Automobile Company”, „California-Based IT Company” i tak dalej.
- data_utworzenia – Przechowuje datę opublikowania pracy.
- opis_pracy – Zawiera krótki opis pracy.
- job_location_id – Odnosi się to do atrybutu w
job_locationtabela, która przechowuje rzeczywistą lokalizację pracy:adres, miasto, województwo, kraj i kod pocztowy. - jest_aktywny – Oznacza to, że zlecenie jest nadal otwarte. Rekruterzy mogą oznaczać swoje posty jako nieaktywne, gdy tylko pozycje zostaną obsadzone.
job_post_skill_set tabela przechowuje szczegółowe informacje o zestawach umiejętności wymaganych do pracy. Struktura tabeli jest taka sama jak seeker_skill_set stół.
I ostatnia tabela w tej sekcji, job_post_activity zawiera szczegółowe informacje o tym, które osoby poszukujące pracy ubiegają się o pracę i kiedy.
Co dodałbyś do tego modelu danych internetowego portalu pracy?
Dzisiejsze internetowe portale pracy to coś więcej niż tylko platforma do zamieszczania i aplikowania o pracę. Często obejmują inne profesjonalne usługi, takie jak:
- Osobisty pulpit nawigacyjny do śledzenia podań o pracę
- Aktualizacje aplikacji w czasie rzeczywistym
- Kreatorzy CV wideo
- Eksperckie usługi pisania CV
- LinkedIn lub inne narzędzia do tworzenia profili w mediach społecznościowych
- Raporty wynagrodzeń w różnych stanowiskach pracy, firmach, branżach lub lokalizacjach geograficznych
Gdybyśmy chcieli wbudować te funkcje w nasz system, jakie dodatkowe zmiany musielibyśmy wprowadzić? Czy przychodzą Ci do głowy jakieś inne must-have w portalu pracy?
Poinformuj nas o swoich poglądach w sekcji komentarzy.