Podstawowe zmiany wprowadzone w funkcji Cardinality Estimation, począwszy od wersji SQL Server 2014, zostały opisane w dokumencie Microsoft White Paper Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator autorstwa Joe Sack, Yi Fang i Vassilis Papadimos.
Jedna z tych zmian dotyczy szacowania prostych złączeń z pojedynczym predykatem równości lub nierówności za pomocą histogramów statystycznych. W sekcji zatytułowanej „Dołączanie do zmian algorytmu szacowania” w artykule przedstawiono koncepcję „zgrubnego wyrównania” przy użyciu minimalnych i maksymalnych granic histogramu:
Dla złączeń z pojedynczym predykatem równości lub nierówności, starszy CE łączy histogramy w kolumnach złączenia, wyrównując dwa histogramy krok po kroku za pomocą interpolacji liniowej. Ta metoda może skutkować niespójnymi szacunkami kardynalności. Dlatego nowa CE używa teraz prostszego algorytmu szacowania złączeń, który wyrównuje histogramy używając tylko minimalnych i maksymalnych granic histogramu.Chociaż potencjalnie mniej spójny, starszy CE może generować nieco lepsze oszacowania warunku prostego łączenia ze względu na stopniowe wyrównanie histogramu. Nowa CE wykorzystuje zgrubne wyrównanie. Jednak różnica w szacunkach może być na tyle mała, że będzie mniej prawdopodobne, że spowoduje problem z jakością planu.
Jako jeden z recenzentów technicznych artykułu, uważałem, że przydałoby się trochę więcej szczegółów na temat tej zmiany, ale to nie zostało uwzględnione w ostatecznej wersji. Ten artykuł zawiera niektóre z tych szczegółów.
Przykład wyrównania zgrubnego histogramu
zgrubne wyrównanie przykład w białej księdze używa wersji przykładowej bazy danych AdventureWorks w hurtowni danych. Mimo nazwy baza danych jest raczej niewielka; kopia zapasowa ma tylko 22,3 MB i rozszerza się do około 200 MB. Można go pobrać za pośrednictwem łączy na stronie dokumentacji instalacji i konfiguracji AdventureWorks.
Zapytanie, które nas interesuje, dołącza do FactResellerSales i FactCurrencyRate tabele.
SELECT
FRS.ProductKey,
FRS.OrderDateKey,
FRS.DueDateKey,
FRS.ShipDateKey,
FCR.DateKey,
FCR.AverageRate,
FCR.EndOfDayRate,
FCR.[Date]
FROM dbo.FactResellerSales AS FRS
JOIN dbo.FactCurrencyRate AS FCR
ON FCR.CurrencyKey = FRS.CurrencyKey; To jest proste equijoin na jednej kolumnie więc kwalifikuje się do szacowania kardynalności i selektywności łączenia przy użyciu zgrubnego wyrównania histogramu.
Histogramy
Potrzebne nam histogramy są powiązane z CurrencyKey kolumna na każdej połączonej tabeli. W nowej kopii bazy danych AdventureWorksDW istniejące statystyki dla większej FactResellerSales tabele oparte są na próbie. Aby zmaksymalizować odtwarzalność i uczynić szczegółowe obliczenia tak prostymi, jak to tylko możliwe (unikając skalowania), pierwszą rzeczą, którą zrobimy, jest odświeżenie statystyk za pomocą pełnego skanowania:
UPDATE STATISTICS dbo.FactCurrencyRate WITH FULLSCAN; UPDATE STATISTICS dbo.FactResellerSales WITH FULLSCAN;
Te tabele mają tę zaletę, że można w wersji demonstracyjnej tworzyć małe i proste maxdiff histogramy:
DBCC SHOW_STATISTICS
(FactResellerSales, CurrencyKey)
WITH HISTOGRAM;
DBCC SHOW_STATISTICS
(FactCurrencyRate, [PK_FactCurrencyRate_CurrencyKey_DateKey])
WITH HISTOGRAM;
Łączenie minimalnych pasujących kroków histogramu
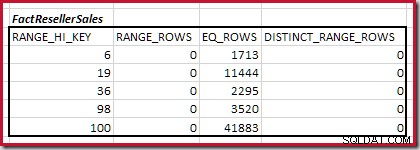
Pierwszy krok zgrubnego wyrównania Obliczenie polega na znalezieniu udziału w liczności łączenia zapewnianej przez najniższy pasujący krok histogramu. W naszych przykładowych histogramach minimalna pasująca wartość kroku to RANGE_HI_KEY = 6 :
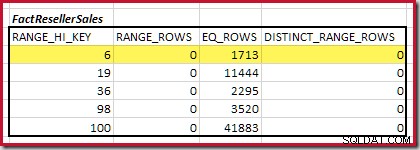
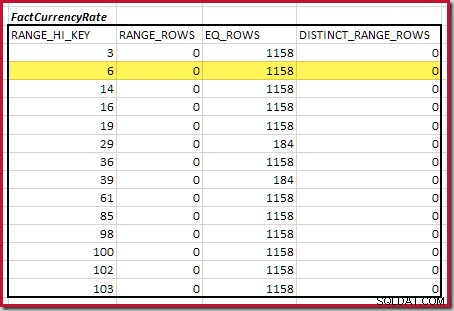
Szacowana kardynalność equijoin tylko dla tego wyróżnionego kroku wynosi 1713 * 1158 =1983654 wierszy .
Pozostałe dopasowane kroki
Następnie musimy określić zakres histogramu RANGE_HI_KEY kroki do maksimum dla możliwych meczów equijoin. Wiąże się to z przejściem od wcześniej znalezionego minimum, aż do momentu, gdy na jednym z danych wejściowych histogramu zabraknie wierszy. Pasujące zakresy equijoin dla bieżącego przykładu są podświetlone poniżej:
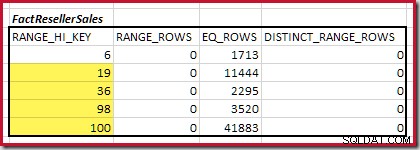
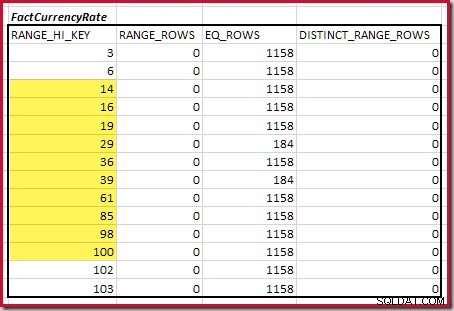
Te dwa zakresy reprezentują pozostałe rzędy, co do których można się spodziewać, że przyczynią się do kardynalności połączenia równorzędnego.
Szacowanie zgrubne na podstawie częstotliwości
Pytanie brzmi teraz, jak wykonać zgrubne oszacowanie kardynalności equijoin wyróżnionych kroków, z wykorzystaniem dostępnych informacji.
Pierwotny estymator kardynalności wykonałby drobnoziarniste wyrównanie histogramu krok po kroku przy użyciu interpolacji liniowej, oceniłby udział łączenia każdego kroku (podobnie jak zrobiliśmy wcześniej dla minimalnej wartości kroku) i zsumował udział każdego kroku w celu uzyskania pełne oszacowanie dołączenia. Chociaż ta procedura ma dużo intuicyjnego sensu, z praktycznego doświadczenia wynika, że to drobnoziarniste podejście zwiększało obciążenie obliczeniowe i mogło dawać wyniki o zmiennej jakości.
Pierwotny estymator miał inny sposób oszacowania kardynalności łączenia, gdy informacje histogramu były albo niedostępne, albo ocenione heurystycznie jako gorsze. Jest to znane jako oszacowanie oparte na częstotliwości i wykorzystuje następujące definicje:
- C – kardynalność (liczba rzędów)
- D – liczba odrębnych wartości
- F – częstotliwość (liczba wierszy) dla każdej odrębnej wartości
- Uwaga C =D * F z definicji
Efekt połączenia równorzędnego relacji R1 i R2 na każdą z tych właściwości jest przedstawiony poniżej:
- F' =F1 * F2
- D' =MIN(D1; D2) – przy założeniu powstrzymywania
- C' =D' * F' (ponownie, z definicji)
Jesteśmy po C', liczności połączenia równorzędnego. Zastępując D' i F' we wzorze i rozwijając:
- C' =D' * F'
- C' =MIN(D1; D2) * F1 * F2
- C' =MIN(D1 * F1 * F2; D2 * F1 * F2)
- teraz, ponieważ C1 =D1 * F1 i C2 =D2 * F2:
- C' =MIN(C1 * F2, C2 * F1)
- w końcu, ponieważ F =C/D (również z definicji):
- C' =MIN(C1 * C2 / D2; C2 * C1 / D1)
Zauważając, że C1 * C2 jest iloczynem dwóch liczności wejściowych (złączenie kartezjańskie), jasne jest, że minimum tych wyrażeń będzie tym, które ma większą liczbę odrębnych wartości:
- C' =(C1 * C2) / MAX(D1; D2)
W przypadku, gdy to wszystko wydaje się trochę abstrakcyjne, intuicyjnym sposobem myślenia o estymacji equijoin opartej na częstotliwości jest rozważenie, że każda odrębna wartość z jednej relacji połączy się z liczbą wierszy (średnia częstotliwość) w drugiej relacji. Jeśli mamy 5 różnych wartości po jednej stronie, a każda odrębna wartość po drugiej stronie pojawia się średnio 3 razy, rozsądna (ale gruba) szacunkowa wartość equijoin wynosi 5 * 3 =15.
To nie jest tak szeroki pędzel, jak mogłoby się wydawać. Pamiętaj, że powyższe liczby dotyczące kardynalności i odrębnych wartości pochodzą nie z całej relacji, ale tylko z pasujących kroków powyżej minimum. Stąd zgrubne oszacowanie między wartościami minimalnymi i maksymalnymi.
Obliczanie częstotliwości
Każdy z tych parametrów możemy uzyskać z podświetlonych kroków histogramu.
- Kardynalność C to suma
EQ_ROWSiRANGE_ROWS. - Liczba odrębnych wartości D to suma
DISTINCT_RANGE_ROWSplus jeden na każdy krok.
Liczność C1 dopasowania FactResellerSales kroki to suma podświetlonych komórek:
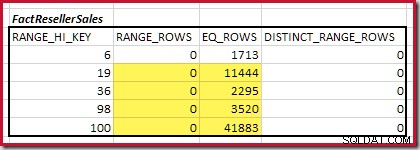
Daje to C1 =59 142 wiersze.
Nie ma odrębnych wierszy zakresu, więc jedyne odrębne wartości pochodzą z samych granic czterech kroków, co daje D1 =4 .
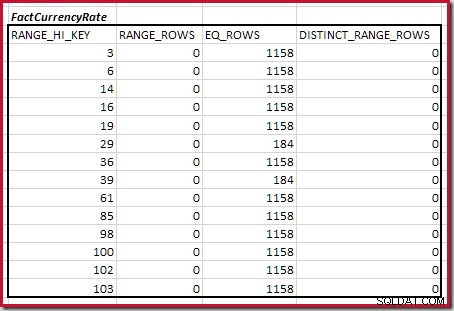
Dla drugiej tabeli:
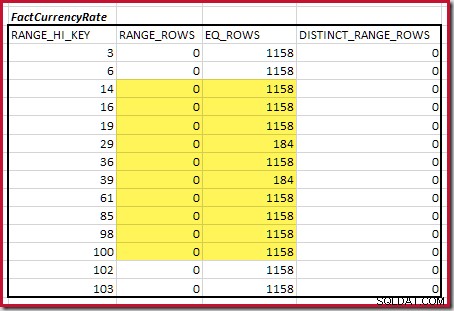
Daje to C2 =9632 . Ponownie nie ma wyraźnych wierszy zakresu, więc różne wartości pochodzą z granic dziesięciu kroków, D2 =10.
Uzupełnianie oszacowania Equijoin
Mamy teraz wszystkie liczby potrzebne do wzoru na equijoin:
- C' =(C1 * C2) / MAKS(D1; D2)
- C' =(59142 * 9632) / MAX(4; 10)
- C' =569655744 / 10
- C' =56 965 74.4
Pamiętaj, że jest to udział kroków histogramu powyżej minimalnej dopasowanej granicy. Aby ukończyć szacowanie liczności łączenia, musimy dodać wkład z minimalnych wartości kroku dopasowania, który wynosił 1713 * 1158 =1983654 wierszy.
Ostateczne oszacowanie equijoin wynosi zatem 56 965 574,4 + 1 983 654 =58 949 228,4 wierszy lub 58 949 200 do sześciu cyfr znaczących.
Ten wynik jest potwierdzony w szacowanym planie wykonania dla zapytania źródłowego:
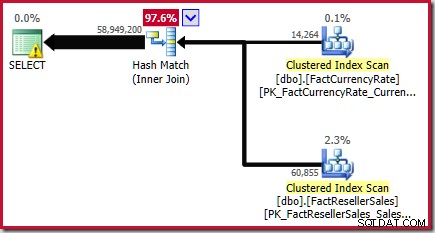
Jak zauważono w Białej Księdze, nie jest to dobre oszacowanie. Rzeczywista liczba wierszy zwróconych przez to zapytanie to 70 470 090 . Oszacowanie uzyskane przez oryginalny („starszy”) estymator liczności – przy użyciu wyrównania histogramu krok po kroku – wynosi 70 470 100 wierszy.
Lepsze wyniki są często możliwe dzięki dokładniejszej metodzie, ale tylko wtedy, gdy statystyki są bardzo dobrą reprezentacją podstawowej dystrybucji danych. Nie jest to po prostu kwestia aktualizowania statystyk lub korzystania z pełnej populacji skanów. Algorytm używany do pakowania informacji do maksymalnie 201 kroków histogramu nie jest doskonały, aw każdym razie wiele rzeczywistych dystrybucji danych po prostu nie jest w stanie zapewnić takiej wierności histogramu. Przeciętnie ludzie powinni uznać, że metoda zgrubna zapewnia doskonale odpowiednie oszacowania i większą stabilność w nowym CE.
Drugi przykład
To trochę opiera się na poprzednim przykładzie i nie wymaga pobierania przykładowej bazy danych.
DROP TABLE IF EXISTS
dbo.R1,
dbo.R2;
CREATE TABLE dbo.R1 (n integer NOT NULL);
CREATE TABLE dbo.R2 (n integer NOT NULL);
INSERT dbo.R1
(n)
VALUES
(1), (2), (3), (4), (5), (6), (7), (8), (9), (10),
(6), (6), (6), (6), (6), (6), (6), (6), (6), (6),
(6), (6), (6), (6), (6), (6), (6), (6), (6);
INSERT dbo.R2
(n)
VALUES
(5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15),
(10), (10);
CREATE STATISTICS stats_n ON dbo.R1 (n) WITH FULLSCAN;
CREATE STATISTICS stats_n ON dbo.R2 (n) WITH FULLSCAN; Histogramy pokazujące dopasowane minimalne kroki to:
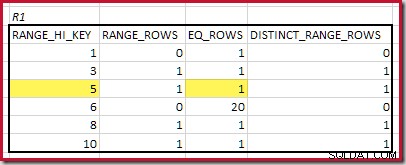
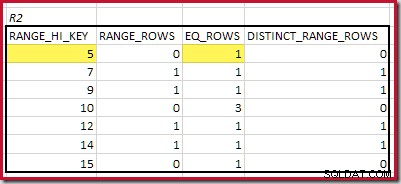
Najniższy RANGE_HI_KEY pasująca wartość to 5. Wartość EQ_ROWS wynosi 1 w obu, więc szacowana kardynalność equijoin wynosi 1 * 1 =1 wiersz .
Najwyżej pasujący RANGE_HI_KEY wynosi 10. Podświetlanie wierszy histogramu R1 w celu zgrubnego oszacowania opartego na częstotliwości:
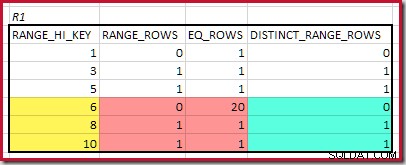
Sumowanie EQ_ROWS i RANGE_ROWS daje C1 =24 . Liczba odrębnych wierszy to 2 DISTINCT_RANGE_ROWS (różne wartości między krokami) plus 3 dla różnych wartości skojarzonych z każdą granicą kroku, co daje D1 =5 .
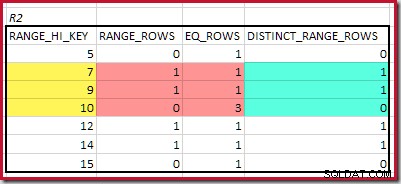
Dla R2 sumowanie EQ_ROWS i RANGE_ROWS daje C2 =7 . Liczba odrębnych wierszy to 2 DISTINCT_RANGE_ROWS (różne wartości między krokami) plus 3 dla różnych wartości skojarzonych z każdą granicą kroku, co daje D2 =5 .
Estymator equijoin C' wynosi:
- C' =(C1 * C2) / MAKS(D1; D2)
- C' =(24 * 7) / 5
- C' =33,6
Dodawanie w 1 wierszu z dopasowania minimalnego kroku daje łączne oszacowanie 34,6 wierszy dla equijoin:
SELECT
R1.n,
R2.n
FROM dbo.R1 AS R1
JOIN dbo.R2 AS R2
ON R2.n = R1.n; Szacunkowy plan wykonania pokazuje oszacowanie zgodne z naszymi obliczeniami:

To nie do końca prawda, ale estymator „starej” liczności nie działa lepiej, szacując 15,25 wierszy w porównaniu z 27 rzeczywistymi:

Aby uzyskać pełne leczenie, musielibyśmy również dodać końcowy wkład z pasujących kroków zerowych histogramu, ale jest to rzadkie w przypadku equijoin (które są zwykle pisane w celu odrzucenia wartości zerowych) i stosunkowo prostego rozszerzenia dla zainteresowanego czytelnika.
Ostateczne myśli
Mam nadzieję, że szczegóły zawarte w artykule wypełnią kilka luk dla każdego, kto kiedykolwiek zastanawiał się nad „zgrubnym wyrównaniem”. Zauważ, że jest to tylko jeden mały składnik w estymatorze kardynalności. Istnieje kilka innych ważnych koncepcji i algorytmów używanych do szacowania złączeń, w szczególności sposób, w jaki oceniane są predykaty bez złączenia, oraz sposób obsługi bardziej złożonych złączeń. Wiele naprawdę ważnych fragmentów jest dość dobrze omówionych w białej księdze.