Wprowadzenie
Przewinięcia są specyficzne dla operatorów po wewnętrznej stronie sprzężenia lub zastosowania zagnieżdżonych pętli. Pomysł polega na ponownym wykorzystaniu wcześniej obliczonych wyników z części planu wykonania, gdzie jest to bezpieczne.
Kanonicznym przykładem operatora planu, który może przewijać do tyłu, jest leniwy Bufor tabeli . Jego raison d’être jest buforowanie wierszy wynikowych z poddrzewa planu, a następnie odtwarzanie tych wierszy w kolejnych iteracjach, jeśli jakiekolwiek skorelowane parametry pętli pozostają niezmienione. Ponowne odtwarzanie wierszy może być tańsze niż ponowne wykonanie poddrzewa, które je wygenerowało. Więcej informacji o tych szpulach wydajności zobacz mój poprzedni artykuł.
Dokumentacja mówi, że tylko następujący operatorzy mogą przewijać:
- Szpula stołu
- Buforowa liczba wierszy
- Nieklastrowana szpula indeksu
- Funkcja o wartościach tabelarycznych
- Sortuj
- Zdalne zapytanie
- Zatwierdź i Filtr operatorzy z wyrażeniem startowym
Pierwsze trzy elementy to najczęściej szpule wyników, chociaż można je wprowadzić z innych powodów (kiedy mogą być chętni lub leniwi).
Funkcje o wartościach tabelarycznych użyj zmiennej tabeli, która może być używana do buforowania i odtwarzania wyników w odpowiednich okolicznościach. Jeśli interesują Cię przewijania funkcji wycenianych w tabeli, zapoznaj się z moimi pytaniami i odpowiedziami na temat wymiany stosów administratorów baz danych.
Pomijając tych, ten artykuł dotyczy wyłącznie sortowania i kiedy mogą przewinąć.
Sortuj przewinięcia
Sorty wykorzystują pamięć masową (pamięć i być może dysk, jeśli się rozleją), więc mają możliwość możliwości przechowywania wierszy między iteracjami pętli. W szczególności posortowane wyjście można zasadniczo odtworzyć (przewinąć).
Mimo to krótka odpowiedź na tytułowe pytanie:„Czy sortuje się wstecz?” jest:
Tak, ale nie zobaczysz tego zbyt często.
Typy sortowania
Wewnętrznie sortowania występują w wielu różnych typach, ale dla naszych obecnych celów są tylko dwa:
- Sortowanie w pamięci (
CQScanInMemSortNew).- Zawsze w pamięci; nie można rozlać na dysk.
- Używa szybkiego sortowania w standardowej bibliotece.
- Maksymalnie 500 wierszy i dwie strony 8 KB w sumie.
- Wszystkie dane wejściowe muszą być stałymi czasu wykonywania. Zazwyczaj oznacza to, że całe poddrzewo sortowania musi składać się z tylko Skanowanie ciągłe i/lub Compute Scalar operatorów.
- Wyraźnie rozróżnialne w planach wykonania tylko wtedy, gdy szczegółowy plan pokazowy jest włączona (flaga śledzenia 8666). Dodaje to dodatkowe właściwości do Sortowania operator, z których jednym jest „InMemory=[0|1]”.
- Wszystkie inne rodzaje.
(Oba typy Sortowania operator uwzględnia ich Top N Sort i różne sortowanie warianty).
Zachowania podczas przewijania
-
Sortowanie w pamięci zawsze można przewinąć kiedy jest bezpiecznie. Jeśli nie ma skorelowanych parametrów pętli lub wartości parametrów pozostają niezmienione w stosunku do bezpośrednio poprzedzającej iteracji, ten typ sortowania może odtworzyć swoje zapisane dane zamiast ponownie wykonywać operatory znajdujące się poniżej w planie wykonania.
-
Niew pamięci sortuje może przewinąć kiedy jest bezpiecznie, ale tylko wtedy, gdy Sortuj operator zawiera co najwyżej jeden wiersz . Zwróć uwagę na sortowanie input może dostarczyć jeden wiersz w niektórych iteracjach, ale nie w innych. Zachowanie środowiska wykonawczego może zatem być złożoną mieszanką przewijania i ponownego wiązania. Zależy to całkowicie od liczby wierszy dostarczonych do Sortowania w każdej iteracji w czasie wykonywania. Generalnie nie można przewidzieć, co sortuje zrobi w każdej iteracji, sprawdzając plan wykonania.
Słowo „bezpieczny” w powyższych opisach oznacza:albo nie nastąpiła zmiana parametru, albo nie ma operatorów poniżej Sortuj mają zależność od zmienionej wartości.
Ważna uwaga na temat planów wykonania
Plany wykonania nie zawsze poprawnie zgłaszają przewinięcia (i powiązania) dla Sortowania operatorów. Operator zgłosi przewinięcie do tyłu, jeśli jakiekolwiek skorelowane parametry są niezmienione, i ponowne powiązanie w przeciwnym razie.
W przypadku sortowań innych niż w pamięci (najczęściej spotykane na dużą odległość) raportowane przewijanie do tyłu spowoduje odtworzenie zapisanych wyników sortowania tylko wtedy, gdy w buforze wyjściowym sortowania znajduje się co najwyżej jeden wiersz. W przeciwnym razie sortowanie zgłosi przewinięcie do tyłu, ale poddrzewo będzie nadal w pełni ponownie wykonane (ponowne wiązanie).
Aby sprawdzić, ile zgłoszonych przewinień było rzeczywistymi przewinięciami, sprawdź Liczbę wykonań właściwość na operatorach poniżej Sortuj .
Historia i moje wyjaśnienie
Sortuj zachowanie operatora cofania może wydawać się dziwne, ale tak było od (przynajmniej) SQL Server 2000 do SQL Server 2019 włącznie (a także Azure SQL Database). Nie udało mi się znaleźć żadnych oficjalnych wyjaśnień ani dokumentacji na ten temat.
Osobiście uważam, że Sortuj przewijania są dość drogie ze względu na leżące u ich podstaw maszyny sortujące, w tym urządzenia do rozlewania i wykorzystanie transakcji systemowych w tempdb .
W większości przypadków optymalizator zrobi lepiej, wprowadzając jawny bufor wydajności gdy wykryje możliwość zduplikowanych parametrów pętli skorelowanych. Buforowanie to najmniej kosztowny sposób przechowywania częściowych wyników w pamięci podręcznej.
To możliwe że powtarzanie sortowania wynik byłby tylko bardziej opłacalny niż szpula kiedy Sortuj zawiera co najwyżej jeden wiersz. W końcu sortowanie jednego wiersza (lub brak wierszy!) w rzeczywistości nie obejmuje żadnego sortowania, więc można uniknąć wielu kosztów ogólnych.
Czysta spekulacja, ale ktoś musiał zapytać, więc tak jest.
Demo 1:niedokładne przewijanie
Ten pierwszy przykład zawiera dwie zmienne tabeli. Pierwsza zawiera trzy wartości zduplikowane trzy razy w kolumnie c1 . Druga tabela zawiera dwa wiersze dla każdego dopasowania c2 = c1 . Dwa pasujące wiersze są rozróżniane wartością w kolumnie c3 .
Zadanie polega na zwróceniu wiersza z drugiej tabeli z najwyższym c3 wartość dla każdego dopasowania w c1 = c2 . Kod jest prawdopodobnie jaśniejszy niż moje wyjaśnienie:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
NO_PERFORMANCE_SPOOL wskazówka ma zapobiec wprowadzeniu przez optymalizator bufora wydajności. Może się to zdarzyć w przypadku zmiennych tabeli, gdy np. flaga śledzenia 2453 jest włączona lub dostępna jest odroczona kompilacja zmiennej tabeli, więc optymalizator może zobaczyć prawdziwą liczność zmiennej tabeli (ale nie rozkład wartości).
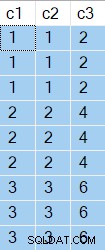
Wyniki zapytania pokazują c2 i c3 zwracane wartości są takie same dla każdego odrębnego c1 wartość:
Rzeczywisty plan wykonania zapytania to:
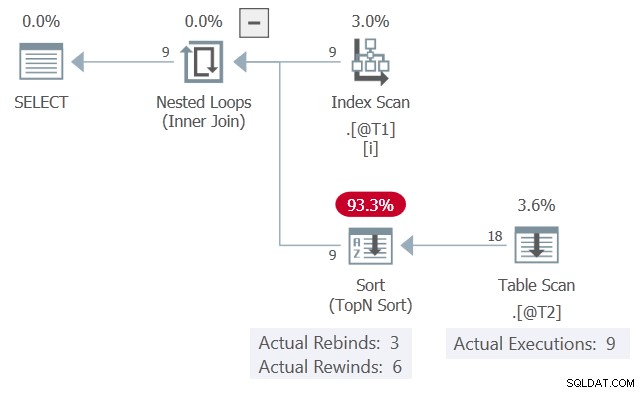
c1 wartości, przedstawione w kolejności, pasują do poprzedniej iteracji 6 razy i zmieniają się 3 razy. Sortuj zgłasza to jako 6 powrotów i 3 ponownych wiązań.
Jeśli to prawda, Skanowanie tabeli wykonałby tylko 3 razy. Sortuj powtórzy (przewinie) swoje wyniki przy pozostałych 6 okazjach.
Obecnie widzimy Skanowanie tabeli został wykonany 9 razy, raz dla każdego wiersza z tabeli @T1 . Nie było tu przewijania .
Demo 2:Sortuj przewinięcia
Poprzedni przykład nie pozwalał na Sortowanie do przewijania, ponieważ (a) nie jest to sortowanie w pamięci; oraz (b) w każdej iteracji pętli Sort zawierał dwa rzędy. Eksplorator planów pokazuje łącznie 18 wierszy z Skanowania tabeli , dwa rzędy w każdej z 9 iteracji.
Poprawmy teraz przykład, aby był tylko jeden wiersz w tabeli @T2 dla każdego pasującego wiersza z @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Wyniki są takie same, jak poprzednio pokazane, ponieważ zachowaliśmy pasujący wiersz posortowany najwyżej w kolumnie c3 . Plan wykonania jest również pozornie podobny, ale z istotną różnicą:
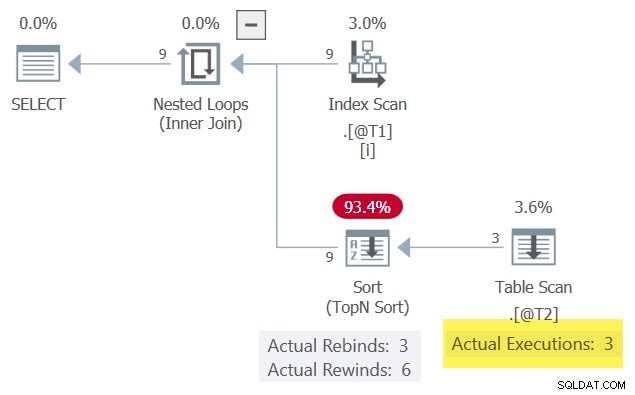
Z jednym wierszem w Sortuj w dowolnym momencie jest w stanie przewinąć, gdy skorelowany parametr c1 nie zmienia. Skanowanie tabeli w rezultacie jest wykonywany tylko 3 razy.
Zwróć uwagę na Sortuj produkuje więcej wierszy (9) niż otrzymuje (3). Jest to dobra wskazówka, że Sortuj zdołał buforować zestaw wyników raz lub więcej razy – pomyślne przewinięcie.
Demo 3:Przewijanie niczego
Wspomniałem wcześniej, że Sortowanie nie w pamięci można przewinąć, gdy zawiera co najwyżej jeden rząd.
Aby zobaczyć to w akcji z zero wierszy , zmieniamy na OUTER APPLY i nie umieszczaj żadnych wierszy w tabeli @T2 . Z powodów, które wkrótce staną się oczywiste, przestaniemy również wyświetlać kolumnę c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Wyniki mają teraz NULL w kolumnie c3 zgodnie z oczekiwaniami:
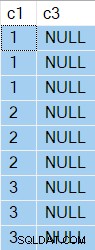
Plan wykonania to:
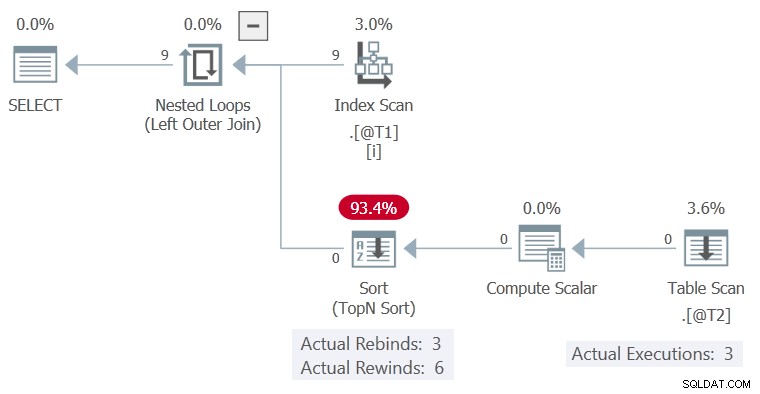
Sortuj był w stanie przewinąć bez wierszy w swoim buforze, więc Skanowanie tabeli został wykonany tylko 3 razy, za każdym razem kolumna c1 zmieniona wartość.
Demo 4:maksymalne przewijanie!
Podobnie jak w przypadku innych operatorów obsługujących przewijanie, Sortuj tylko ponownie powiąże jego poddrzewo, jeśli skorelowany parametr uległ zmianie i poddrzewo w jakiś sposób zależy od tej wartości.
Przywracanie kolumny c2 projekcja do demo 3 pokaże to w akcji:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Wyniki pokazują teraz dwa NULL kolumny oczywiście:
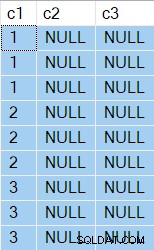
Plan wykonania jest zupełnie inny:
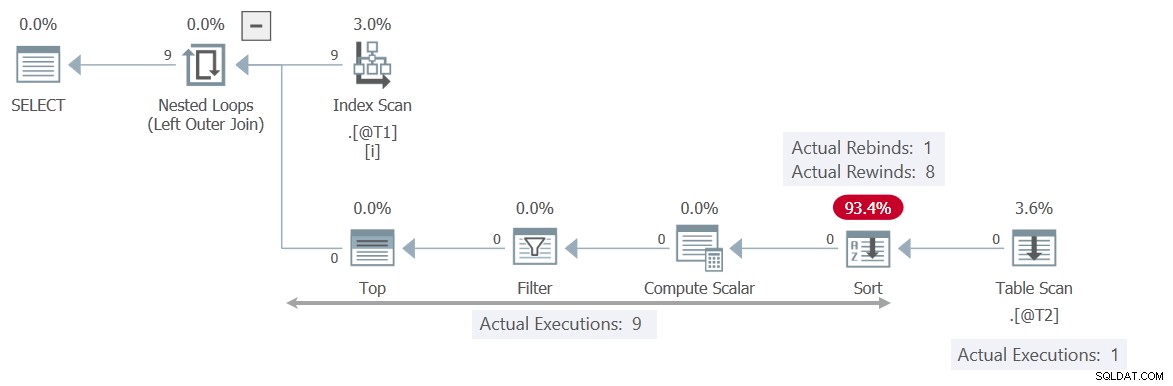
Tym razem Filtr zawiera czek T2.c2 = T1.c1 , wykonując Skanowanie tabeli niezależny aktualnej wartości skorelowanego parametru c1 . Sortuj można bezpiecznie przewinąć 8 razy, co oznacza, że skanowanie jest wykonywane tylko raz .
Demo 5:Sortowanie w pamięci
Następny przykład pokazuje Sortowanie w pamięci operator:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Otrzymane wyniki będą się różnić w zależności od wykonania, ale oto przykład:
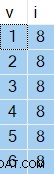
Ciekawą rzeczą są wartości w kolumnie i zawsze będzie taka sama — pomimo ORDER BY NEWID() klauzula.
Prawdopodobnie już zgadłeś, że przyczyną tego jest Sortowanie buforowanie wyników (przewijanie). Plan wykonania pokazuje Stałe skanowanie wykonanie tylko raz, dając w sumie 11 wierszy:
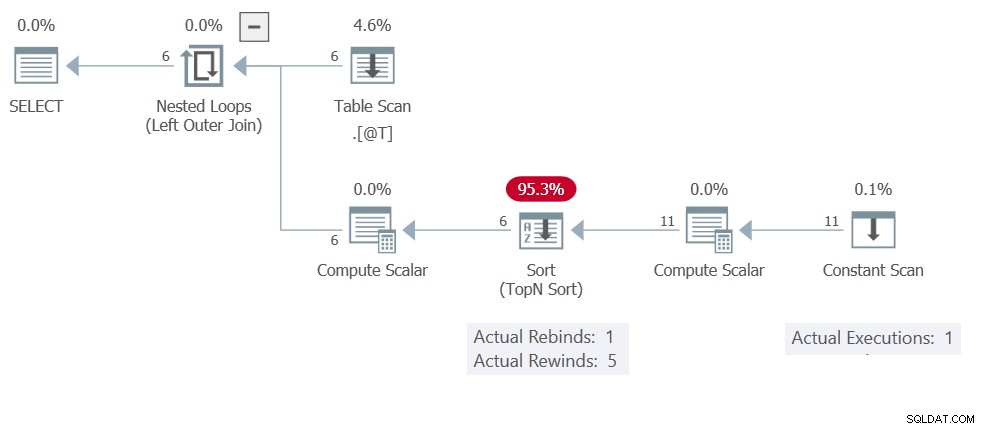
To sortowanie ma tylko Compute Scalar i Stałe skanowanie operatorów na jego danych wejściowych, więc jest to Sortowanie w pamięci . Pamiętaj, że nie ograniczają się one do co najwyżej jednego wiersza — mogą pomieścić 500 wierszy i 16 KB.
Jak wspomniano wcześniej, nie jest możliwe jednoznaczne sprawdzenie, czy Sortuj jest w pamięci lub nie, sprawdzając regularny plan wykonania. Potrzebujemy pełnego wyjścia planu pokazu , włączone z nieudokumentowaną flagą śledzenia 8666. Po włączeniu tej opcji pojawiają się dodatkowe właściwości operatora:
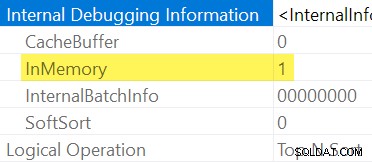
Gdy użycie nieudokumentowanych flag śledzenia nie jest praktyczne, można wywnioskować, że Sortuj to „InMemory” według jego ułamka pamięci wejściowej wartość zero i wykorzystanie pamięci elementy niedostępne w powykonawczym showplanie (w wersjach SQL Server obsługujących te informacje).
Powrót do planu wykonania:nie ma skorelowanych parametrów, więc Sortuj można przewinąć 5 razy, co oznacza Stałe skanowanie jest wykonywany tylko raz. Zapraszam do zmiany TOP (1) do TOP (3) lub cokolwiek chcesz. Przewijanie oznacza, że wyniki będą takie same (buforowane/przewinięte) dla każdego wiersza wejściowego.
Możesz być zaniepokojony ORDER BY NEWID() klauzula nie uniemożliwiająca przewijania. Jest to rzeczywiście kwestia kontrowersyjna, ale nie ogranicza się do pewnego rodzaju. Aby uzyskać pełniejszą dyskusję (ostrzeżenie:możliwa królicza nora), zapoznaj się z tym pytaniem i odpowiedzią. Krótka wersja mówi, że jest to świadoma decyzja dotycząca projektowania produktu, optymalizująca wydajność, ale są plany, aby z czasem zachowanie było bardziej intuicyjne.
Demo 6:Brak sortowania w pamięci
Jest to to samo co demo 5, z tą różnicą, że zreplikowany ciąg jest o jeden znak dłuższy:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Ponownie, wyniki będą się różnić w zależności od wykonania, ale oto przykład. Zwróć uwagę na i wartości nie są teraz takie same:

Dodatkowy znak wystarczy, aby przesunąć szacowany rozmiar posortowanych danych ponad 16 KB. Oznacza to sortowanie w pamięci nie można użyć, a przewijania znikają.
Plan wykonania to:
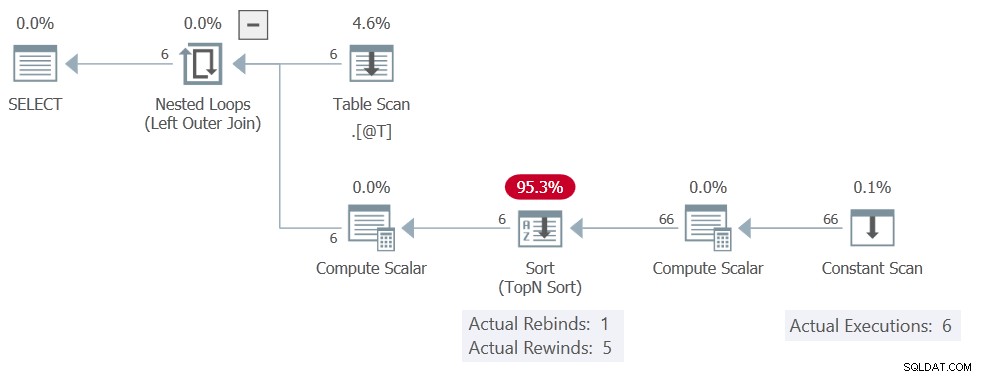
Sortuj nadal raporty 5 przewinięć, ale Stałe skanowanie jest wykonywany 6 razy, co oznacza, że tak naprawdę nie wystąpiły żadne przewinięcia. Daje wszystkie 11 rzędów w każdym z 6 wykonań, co daje w sumie 66 rzędów.
Podsumowanie i końcowe przemyślenia
Nie zobaczysz Sortowania operator naprawdę przewijanie bardzo często, choć zobaczysz, że mówiąc, że tak całkiem sporo.
Pamiętaj, regularne sortowanie można przewijać tylko wtedy, gdy jest to bezpieczne i w danym momencie w sortowaniu znajduje się maksymalnie jeden wiersz. Bycie „bezpiecznym” oznacza albo brak zmian w parametrach korelacji pętli, albo nic poniżej Sortowania ma wpływ zmiany parametrów.
Sortowanie w pamięci może działać na maksymalnie 500 wierszach i 16 KB danych pochodzących z Stałego skanowania i Compute Scalar tylko operatorzy. Przewija się również tylko wtedy, gdy jest bezpieczny (pomijając błędy produktu!), ale nie jest ograniczony do maksymalnie jednego wiersza.
Mogą się to wydawać ezoteryczne szczegóły i przypuszczam, że tak jest. Mówiąc więc, pomogli mi zrozumieć plan wykonania i znaleźć dobre ulepszenia wydajności więcej niż raz. Być może pewnego dnia te informacje okażą się przydatne.
Zwróć uwagę na sortowane które produkują więcej wierszy niż mają na wejściu!
Jeśli chcesz zobaczyć bardziej realistyczny przykład Sortuj przewijanie na podstawie demonstracji, którą Itzik Ben-Gan udostępnił w pierwszej części swojego Najbliższego meczu seria, zobacz Najbliższy mecz z sortowaniem przewijania.