Dawno temu odpowiedziałem na pytanie dotyczące NULL na Stack Exchange zatytułowane „Dlaczego nie powinniśmy zezwalać na NULL?” Mam swoją część domowych zirytowań i pasji, a strach przed NULLami jest dość wysoko na mojej liście. Kolega powiedział mi niedawno, po wyrażeniu preferencji, aby wymusić pusty ciąg zamiast zezwalania na NULL:
"Nie lubię zajmować się zerami w kodzie."
Przepraszam, ale to nie jest dobry powód. Sposób, w jaki warstwa prezentacji radzi sobie z pustymi ciągami lub wartościami NULL, nie powinien być sterownikiem projektu tabeli i modelu danych. A jeśli dopuszczasz „brak wartości” w jakiejś kolumnie, czy z logicznego punktu widzenia ma dla ciebie znaczenie, czy „brak wartości” jest reprezentowany przez ciąg o zerowej długości, czy przez NULL? Albo gorzej, wartość symboliczna, taka jak 0 lub -1 dla liczb całkowitych lub 1900-01-01 dla dat?
Itzik Ben-Gan napisał ostatnio całą serię na temat wartości NULL i gorąco polecam przejrzenie tego wszystkiego:
- NULL złożoności – część 1
- NULL złożoności – część 2
- Złożoność NULL – Część 3, Brakujące standardowe funkcje i alternatywy T-SQL
- Złożoność NULL – część 4, brak standardowego ograniczenia unikatowego
Ale mój cel tutaj jest trochę mniej skomplikowany, po tym, jak temat pojawił się w innym pytaniu Stack Exchange:„Dodaj pole auto teraz do istniejącej tabeli”. Tam użytkownik dodawał nową kolumnę do istniejącej tabeli z zamiarem automatycznego wypełnienia jej aktualną datą/godziną. Zastanawiali się, czy powinni zostawić w tej kolumnie wartości NULL dla wszystkich istniejących wierszy, czy ustawić wartość domyślną (jak przypuszczalnie 1900-01-01, chociaż nie były one jawne).
Ktoś, kto zna się na rzeczy, może łatwo odfiltrować stare wiersze na podstawie wartości symbolicznej — w końcu, jak ktokolwiek mógł uwierzyć, że jakiś rodzaj gadżetu Bluetooth został wyprodukowany lub zakupiony w dniu 1900-01-01? Cóż, widziałem to w obecnych systemach, w których używają arbitralnie brzmiących dat w widokach, aby działać jako magiczny filtr, prezentując tylko wiersze, w których można ufać wartości. W rzeczywistości w każdym przypadku, który do tej pory widziałem, data w klauzuli WHERE jest datą/godziną dodania kolumny (lub jej domyślnego ograniczenia). Wszystko w porządku; może nie jest to najlepszy sposób na rozwiązanie problemu, ale jest a sposób.
Jeśli jednak nie uzyskujesz dostępu do tabeli przez widok, ta implikacja znanego wartość może nadal powodować problemy logiczne i związane z wynikami. Logiczny problem polega po prostu na tym, że osoba wchodząca w interakcję z tabelą musi wiedzieć, że 1900-01-01 to fałszywa, symboliczna wartość reprezentująca „nieznane” lub „nieistotne”. Dla przykładu ze świata rzeczywistego, jaka była średnia prędkość wypuszczania w sekundach dla rozgrywającego, który grał w latach 70., zanim zmierzyliśmy lub śledziliśmy coś takiego? Czy 0 to dobra wartość tokena dla „nieznane”? A może -1? Lub 100? Wracając do dat, jeśli pacjent bez legitymacji zostanie przyjęty do szpitala i jest nieprzytomny, co należy wpisać jako datę urodzenia? Nie wydaje mi się, żeby 1900-01-01 był dobrym pomysłem i na pewno nie był to dobry pomysł, kiedy była to bardziej prawdopodobna data urodzin.
Implikacje wydajnościowe wartości tokenów
Z punktu widzenia wydajności fałszywe lub „tokenowe” wartości, takie jak 1900-01-01 lub 9999-21-31, mogą powodować problemy. Spójrzmy na kilka z nich z przykładem opartym luźno na ostatnim pytaniu wspomnianym powyżej. Mamy tabelę Widgets i po kilku zwrotach gwarancyjnych zdecydowaliśmy się dodać kolumnę EnteredService, w której wprowadzimy aktualną datę/godzinę dla nowych wierszy. W jednym przypadku zostawimy wszystkie istniejące wiersze jako NULL, a w drugim zaktualizujemy wartość do naszej magicznej daty 1900-01-01. (Na razie pominiemy w rozmowie jakąkolwiek kompresję).
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Teraz wstawimy te same 100 000 wierszy do każdej tabeli:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Następnie możemy dodać nową kolumnę i zaktualizować 10% istniejących wartości z rozkładem aktualnych dat, a pozostałe 90% do naszej daty tokena tylko w jednej z tabel:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Na koniec możemy dodać indeksy:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Zajęte miejsce
Zawsze słyszę „miejsce na dysku jest tanie”, gdy mówimy o wyborze typu danych, fragmentacji i wartościach tokenów w porównaniu z wartościami NULL. Martwię się nie tyle o miejsce na dysku, które zajmują te dodatkowe bezsensowne wartości. Co więcej, gdy ktoś pyta o tabelę, marnuje pamięć. Tutaj możemy szybko zorientować się, ile miejsca zajmują nasze wartości tokenów przed i po dodaniu kolumny i indeksu:
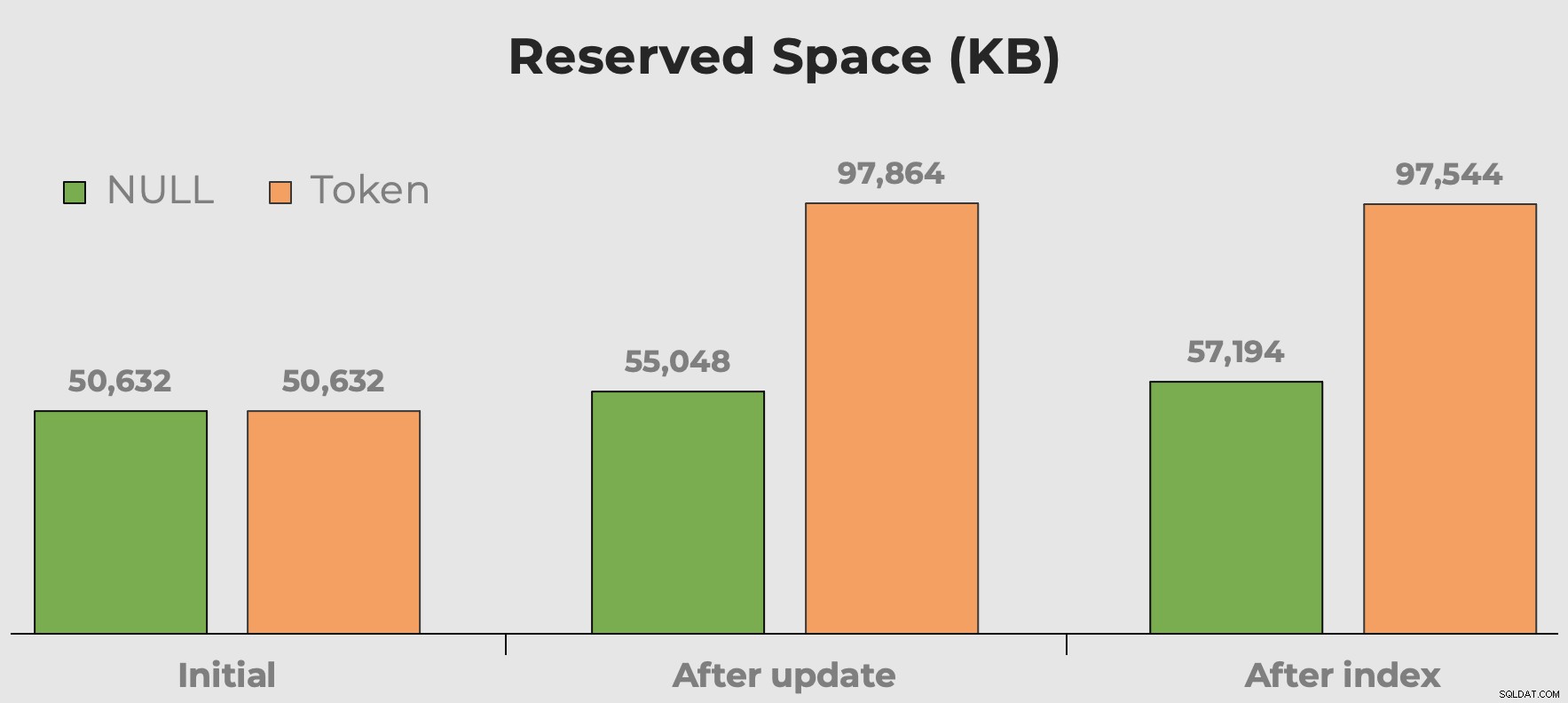 Zarezerwowane miejsce w tabeli po dodaniu kolumny i dodaniu indeksu. Spacja prawie się podwaja przy wartościach tokenów.
Zarezerwowane miejsce w tabeli po dodaniu kolumny i dodaniu indeksu. Spacja prawie się podwaja przy wartościach tokenów.
Wykonywanie zapytania
Nieuchronnie ktoś przyjmie założenia dotyczące danych w tabeli i wykona zapytanie w kolumnie EnteredService, tak jakby wszystkie wartości były uzasadnione. Na przykład:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Wartości symboliczne mogą w niektórych przypadkach zawadzać z szacunkami, ale, co ważniejsze, dadzą nieprawidłowe (lub przynajmniej nieoczekiwane) wyniki. Oto plan wykonania zapytania względem tabeli z wartościami tokenów:
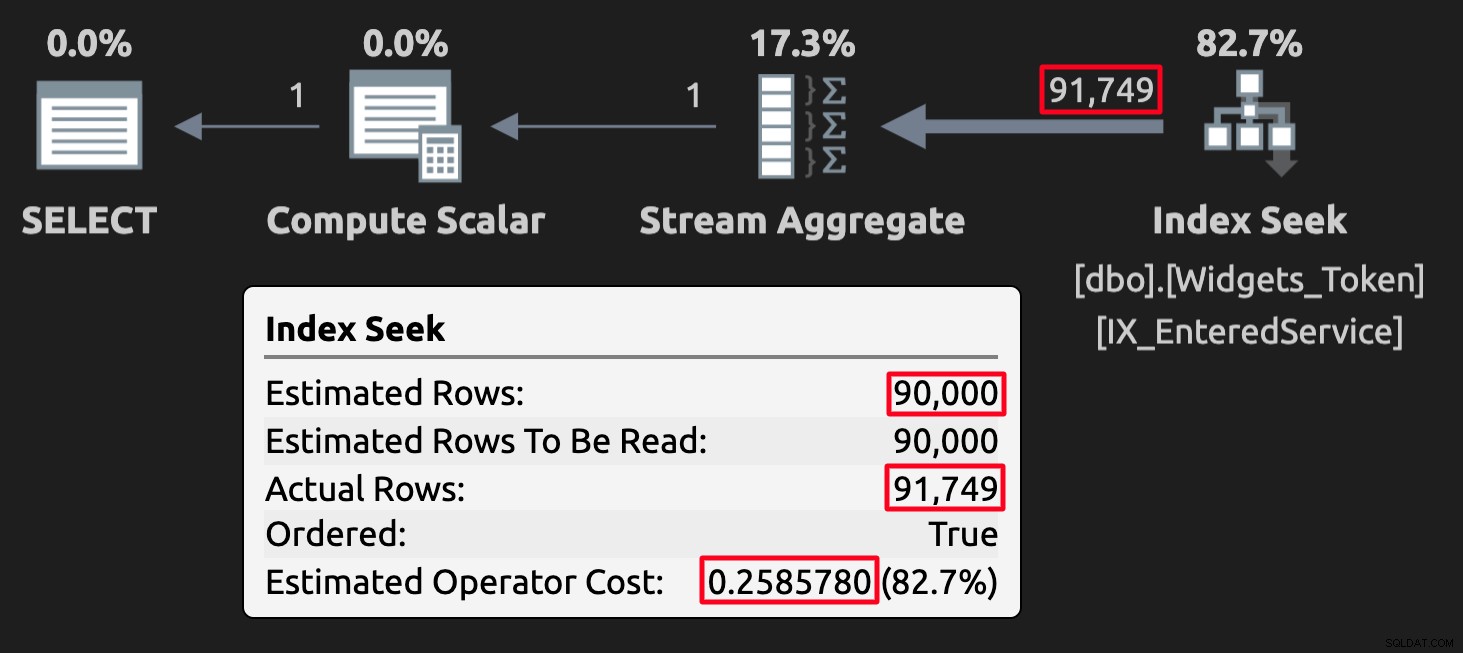 Plan wykonania dla tabeli tokenów; zwróć uwagę na wysoki koszt.
Plan wykonania dla tabeli tokenów; zwróć uwagę na wysoki koszt.
A oto plan wykonania zapytania względem tabeli z wartościami NULL:
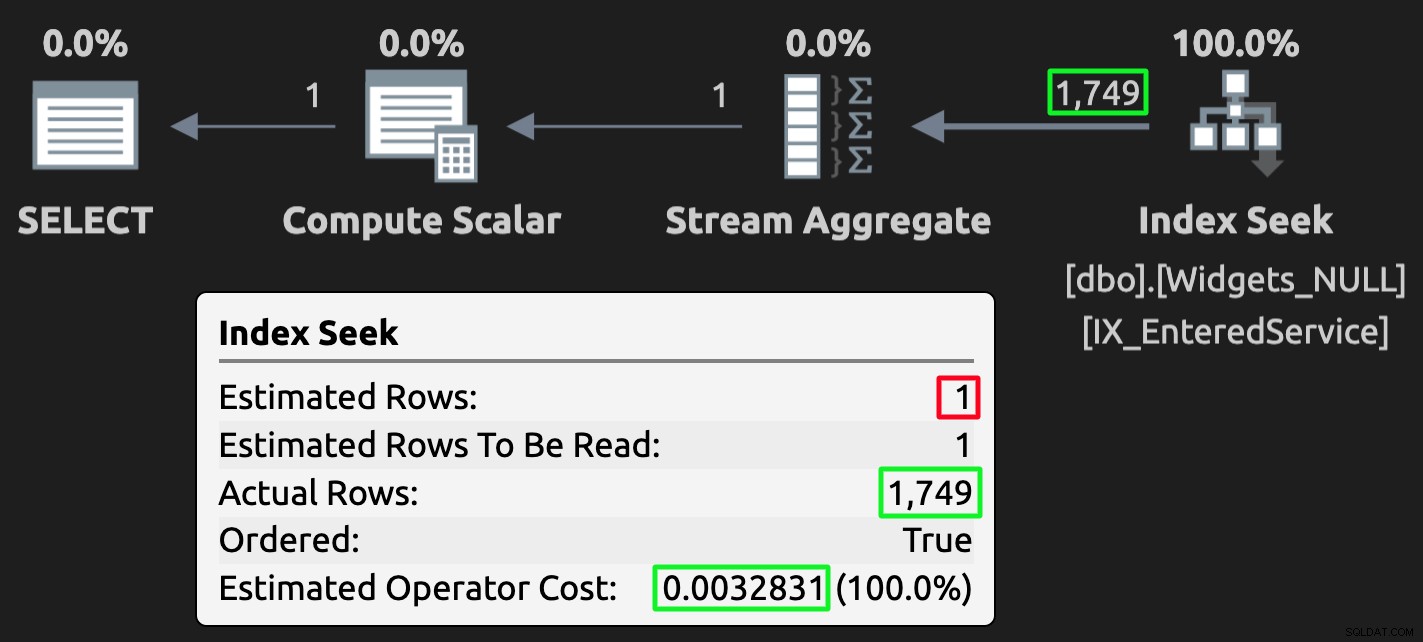 Plan wykonania dla tabeli NULL; błędne oszacowanie, ale znacznie niższy koszt.
Plan wykonania dla tabeli NULL; błędne oszacowanie, ale znacznie niższy koszt.
To samo stałoby się w drugą stronę, gdyby zapytanie poprosiło o>={jakaś data}, a 9999-12-31 użyto jako magicznej wartości reprezentującej nieznane.
Ponownie, dla osób, które wiedzą, że wyniki są błędne, szczególnie dlatego, że użyłeś wartości tokenów, nie stanowi to problemu. Ale wszyscy, którzy o tym nie wiedzą — w tym przyszli koledzy, inni spadkobiercy i opiekunowie kodu, a nawet ci, którzy mają problemy z pamięcią — prawdopodobnie się potkną.
Wniosek
Wybór zezwalania na NULL w kolumnie (lub całkowitego unikania NULL) nie powinien być sprowadzany do decyzji ideologicznej lub opartej na strachu. Istnieją rzeczywiste, namacalne wady projektowania modelu danych, aby upewnić się, że żadna wartość nie może być NULL, lub używania bezsensownych wartości do reprezentowania czegoś, co z łatwością mogłoby w ogóle nie być przechowywane. Nie sugeruję, że każda kolumna w twoim modelu powinna zezwalać na wartości NULL; po prostu nie sprzeciwiaj się pomysłowi wartości NULL.