W dobie ostrej konkurencji portale z ofertami pracy to nie tylko platforma do publikowania i wyszukiwania ofert pracy. Wykorzystują zaawansowane usługi i funkcje, aby utrzymać zaangażowanie swoich klientów. Zanurzmy się w niektóre zaawansowane funkcje i zbudujmy model danych, który sobie z nimi poradzi.
W poprzednim artykule wyjaśniłem podstawowe funkcje potrzebne do stworzenia portalu z ofertami pracy. Model pokazano poniżej. Potraktujemy ten model jako bazę, którą zmienimy, aby sprostać nowym wymaganiom. Najpierw zastanówmy się, jakie powinny być te wymagania (lub ulepszenia).
Co dodajemy do modelu danych internetowego portalu pracy?
Krótko mówiąc, zamierzamy dodać cztery ulepszenia do naszego poprzedniego modelu danych:
- Osobisty pulpit nawigacyjny dla osób poszukujących pracy. To śledzi wszystkie ich podania o pracę i zapewnia aktualizacje w czasie rzeczywistym o wszelkich zmianach statusu (tj. Aplikacja zmienia się od otrzymania do sprawdzenia).
- Panel profilu. Zawiera szczegółowe informacje o tym, kto odwiedza profil osoby poszukującej pracy i ile razy jej CV zostało pobrane w ciągu ostatniego dnia, tygodnia lub miesiąca.
- Zarządzanie usługami płatnymi. Portale z ofertami pracy często oferują usługi, takie jak przygotowywanie CV ekspertów, zarządzanie profilami społecznościowymi, doradztwo zawodowe itp. Nasze nowe funkcje będą w stanie obsługiwać oferty płatne.
- Zarządzanie formularzem przedzgłoszeniowym. Gdy kandydaci składają podanie o pracę, mogą zostać poproszeni o wypełnienie krótkiego kwestionariusza dotyczącego czasu pracy, lokalizacji i sprawdzenia przeszłości. Opracujemy sposoby dostosowywania tego formularza przez rekruterów oraz przechwytywania pytań i odpowiedzi przez system.
Ulepszenie nr 1:Osobisty pulpit nawigacyjny
Pytania do odpowiedzi: Jaki jest obecny status złożonego wniosku? Czy jest na krótkiej liście do rozmowy kwalifikacyjnej? Czy to w ogóle było już oglądane?
Możemy śledzić podania o pracę, umieszczając job_application_status_id kolumna w job_post_activity stół. W tej kolumnie znajduje się aktualny status podania o pracę. Musimy utworzyć kolejną tabelę, job_application_status , aby zachować wszystkie możliwe statusy aplikacji. Niektóre statusy mogą być „przesłany”, „w trakcie sprawdzania”, „zarchiwizowany”, „odrzucony”, „zakwalifikowany na rozmowę kwalifikacyjną”, „w trakcie procesu rekrutacji” i tak dalej.
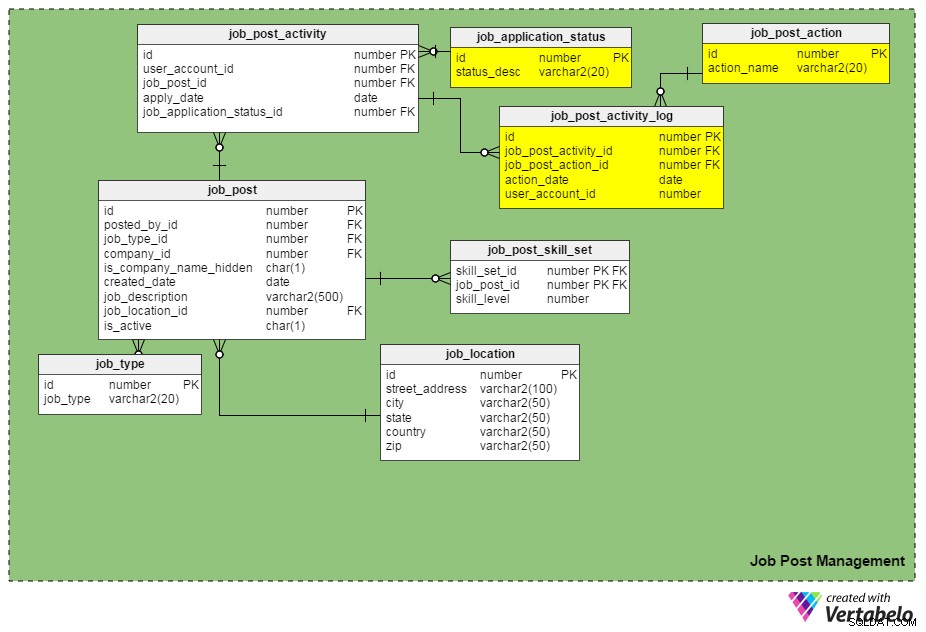
Kolejna nowa tabela, job_post_activity_log , przechowuje informacje dotyczące wszystkich akcji wykonanych na aplikacjach o pracę, kto wykonał akcję i kiedy została wykonana. Ta tabela zawiera następujące kolumny:
id– Klucz podstawowy tabeli.job_post_activity_id– Identyfikator aplikacji, na której wykonywana jest akcja.job_post_action_id– Identyfikator wykonanej akcji. To jest klucz obcy, który łączy się zjob_post_actionstół. Rodzaje działań, które możemy tutaj przechowywać, obejmują „przesłane”, „przeglądane”, „przesłuchane”, „wykonano test pisemny”, „oferta w toku”, „oferta wysłana”, „oferta przyjęta” itp.action_date– Data wykonania czynności.user_account_id– Identyfikator osoby, która wykonała czynność.
Czy „job_post_action” jest identyczne z „job_application_status”? Czym się różnią?
Na pierwszy rzut oka wydają się identyczne, ale rzeczywiście są różne. Istnieją uzasadnione powody, dla których potrzebujemy dwóch podobnych pól:
- Z kandydatem rozmawiają dwie lub więcej osób oddzielnie. W takim przypadku status podania o pracę pozostaje taki sam (tj. „w trakcie procesu rekrutacji”) do momentu zakończenia wszystkich rund rozmów kwalifikacyjnych. Jednak rekordy dla każdego indywidualnego ankietera są wstawiane do
job_post_activity_logtabeli i mają akcję „wywiad”. - Zgłoszenie może wyświetlić więcej niż jeden rekruter w tej samej firmie. Korzystając z tych dwóch atrybutów, nie stracisz informacji o kandydacie.
- Złożenie oferty wybranemu kandydatowi podlega wielokrotnym zatwierdzeniom (tj. zgoda zespołu finansowego, zgoda kierownika działu rekrutacji itd.). W takim przypadku status podania o pracę pozostaje „oferta w trakcie sprawdzania”, ale baza danych może rejestrować, które zatwierdzenia przeszły, a które nie, za pomocą
job_post_activity_logstół.
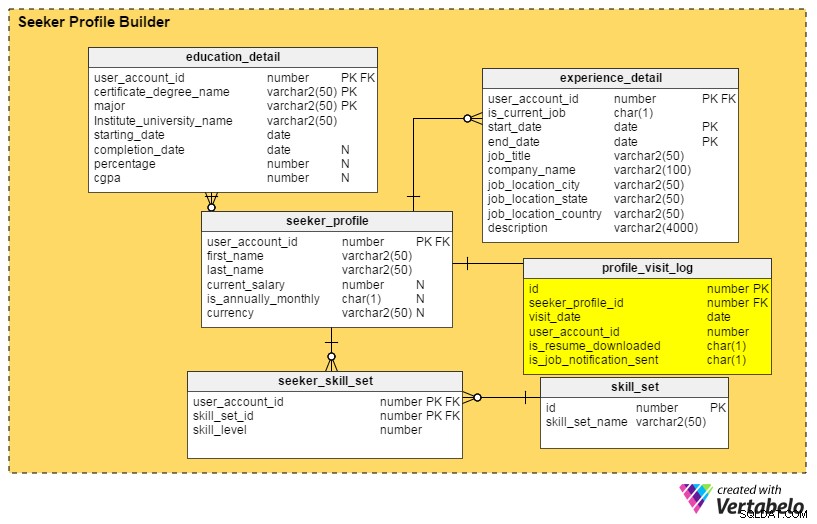
Ulepszenie nr 2:Panel profilu
Pytania do odpowiedzi: Kto ostatnio znalazł mój profil? Ile razy był oglądany przez rekruterów w ciągu ostatniego miesiąca, tygodnia lub dnia? Czy rekruterzy z czołowych firm spojrzeli na mój profil?
Odpowiedzi na wszystkie te pytania znajdują się w profile_visit_log stół. Ta tabela zawiera wszystkie dane dotyczące odwiedzin profilu, w tym kto odwiedził profil, kiedy został wyświetlony itd. Kolumny w tej tabeli to:
id– Klucz podstawowy tabeli.seeker_profile_id– Który profil był odwiedzany.visit_date– Kiedy uzyskano dostęp do profilu.user_account_id– Kto widział profil.is_resume_downloaded– Kolumna z flagą, która wskazuje, czy powiązane CV zostało pobrane podczas wizyty. Ta kolumna pomoże nam ustalić, ile razy CV jest pobierane przez rekruterów.is_job_notification_sent– Kolejna kolumna z flagą, ta informująca, czy powiadomienie o pracy zostało wysłane do właściciela profilu.
Ulepszenie nr 3:Zarządzanie płatnymi usługami
Pytanie do odpowiedzi: W jaki sposób portale internetowe mogą wykorzystać dodatkowe płatne usługi?
Oprócz platformy do publikowania i wyszukiwania ofert pracy, wiele portali internetowych oferuje inne usługi, takie jak tworzenie życiorysów eksperckich, doradztwo zawodowe itp. Oferują również produkty, które pomagają osobom poszukującym pracy znaleźć wymarzoną pracę w ich wymarzonym mieście. Na przykład jedna z wiodących witryn z ofertami pracy oferuje produkt, który utrzymuje Twój profil na szczycie list rekruterów, dzięki czemu możesz uzyskać więcej ofert na rozmowy kwalifikacyjne. Większość z tych produktów lub usług jest dostępna na zasadzie subskrypcji. Kiedy użytkownik kupuje usługę lub produkt, płaci przez określony czas (tj. miesiąc, trzy miesiące, rok) za korzystanie z tego produktu lub usługi.
Przeglądając te portale pracy, zauważyłem, że prawie żadne produkty czy usługi nie są oferowane pojedynczo. W większości wiele produktów i usług jest połączonych w jeden pakiet, który jest oferowany osobom poszukującym pracy lub rekrutującym.
Biorąc pod uwagę wszystkie te punkty, wymyśliłem następujący model danych do włączania płatnych usług i produktów do naszej istniejącej strony internetowej z ofertami pracy:
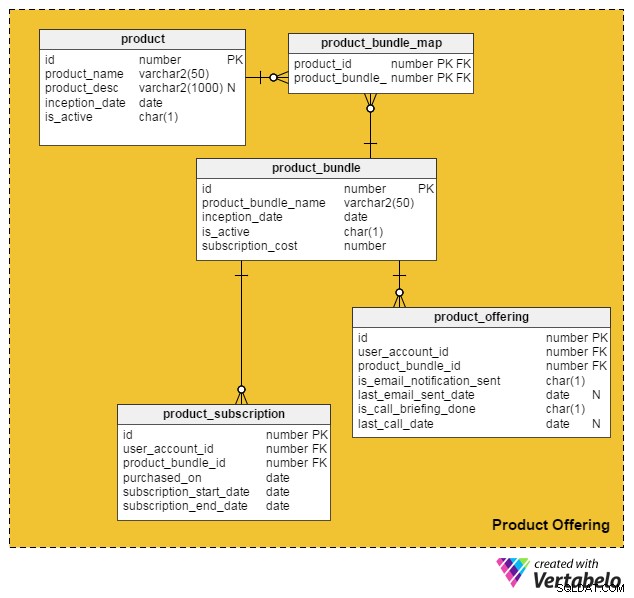
product tabela zawiera szczegółowe informacje o poszczególnych produktach. (Zarówno produkty, jak i usługi będziemy nazywać „produktami”). Kolumny w tej tabeli to:
id– Klucz podstawowy tej tabeli, który nadaje unikalny identyfikator każdemu produktowi oferowanemu na naszym portalu.product_name– Zawiera nazwę produktu.product_desc– Przechowuje krótki opis produktu.inception_date– Data wprowadzenia produktu.is_active– Czy produkt jest aktywny, czy nie.
Ponieważ produkty i usługi można łączyć w pakiet i oferować klientom, utworzyłem product_bundle tabeli do przechowywania rekordów wszystkich takich pakietów. Atrybuty to:
id– Klucz podstawowy tabeli, który zapewnia unikalny identyfikator dla każdego pakietu produktów.product_bundle_name– Przechowuje nazwę pakietu.inception_date– Data wprowadzenia pakietu.is_active– Wskazuje, czy pakiet jest aktywny, czy nie.subscription_cost– Przechowuje żądaną cenę pakietu.
Czy można zaoferować klientom jeden produkt?
Tak. W tym modelu danych pojedynczy produkt może być osobnym „pakietem”. Poniższe tabele obsługują tę i kilka innych ważnych funkcji.
product_bundle_map tabela przechowuje listę wszystkich produktów, które są częścią pakietu. Jego atrybuty są oczywiste.
Następna tabela, product_subscription , wchodzi w grę, gdy klienci subskrybują pakiety produktów. Rejestruje szczegóły, którzy klienci zapisali do jakich pakietów. Kolumny w tej tabeli to:
id– Klucz podstawowy tabeli.user_account_id– Użytkownik, który kupił pakiet.product_bundle_id– Pakiet produktów kupiony przez użytkownika.purchased_on– Data zakupu.subscription_start_date– Data rozpoczęcia subskrypcji. Pamiętaj, że data zakupu produktu i data rozpoczęcia subskrypcji mogą się różnić. Dlatego mamy dla nich dwie różne kolumny.subscription_end_date– Kiedy abonament się skończy.
Tabela finałowa, product_offering , służy głównie do celów marketingowych. Zazwyczaj portale pracy analizują ostatnie działania użytkowników (zarówno poszukujących pracy, jak i rekrutujących), a następnie decydują, które produkty będą korzystne dla których użytkowników. Następnie wykorzystują e-maile lub telefony, aby kontaktować się z klientami z wybranymi ofertami. Kolumny w tej tabeli to:
id– Klucz podstawowy tabeli.user_account_id– Użytkownik, do którego skierowany jest portal z ofertami pracy.product_bundle_id– Pakiet produktów, który marketerzy portalu dopasowali do użytkownika.is_email_notification_sent– Czy wysłano wiadomość e-mail dotyczącą oferty produktów.last_email_sent_date– Data ostatniego otrzymania przez użytkownika wiadomości e-mail dotyczącej produktu od zespołu marketingowego. Marketerzy często wysyłają wiele powiadomień do użytkownika i okresowo wysyłają inne powiadomienia. Ta kolumna przechowuje datę wysłania ostatniego powiadomienia.is_call_briefing_done– Czy klient otrzymał telefon z informacją o produkcie.last_call_date– Data ostatniej rozmowy telefonicznej. Do klientów można wykonać wiele połączeń (połączeń uzupełniających).
Ulepszenie nr 4:Zarządzanie formularzem przedzgłoszeniowym
Pytanie do odpowiedzi: W jaki sposób rekruter może uzyskać dostosowany formularz zgody wypełniony przez wszystkich potencjalnych kandydatów do pracy?
Wiele razy osoby poszukujące pracy odpowiadają na konkretne pytania, gdy ubiegają się o stanowisko. Zwykle obejmuje to takie rzeczy, jak wyrażenie zgody na sprawdzenie przeszłości kryminalnej. Istnieje jednak wiele innych rodzajów zgód, które mogą być potrzebne. Na przykład praca w marketingu może wymagać wielu podróży; Praca w outsourcingu procesów biznesowych (BPO) może wymagać od pracowników pracy na nocnych zmianach. Są one omówione w formularzach przedaplikacyjnych.
Zawsze najlepiej jest uzyskać zgodę podczas składania podania o pracę. W ten sposób kandydaci, którzy nie chcą spełnić tych wymagań, nie będą aplikować na stanowisko.
Zanim przejdę do modelu danych, chciałbym najpierw podkreślić kilka podstawowych faktów dotyczących formularzy zgody:
- Ogłoszenie o pracę może zawierać więcej niż jeden formularz zgody.
- Każdy formularz zgody zawiera różne pytania związane z różnymi sekcjami.
- Pytanie można ustawić jako obowiązkowe lub opcjonalne, w zależności od tego, jak pytanie jest oznaczone w formularzu. Pytanie może być opcjonalne w jednej formie i obowiązkowe w innej.
- Na każde pytanie można odpowiedzieć jako (1) tak, (2) nie lub (3) nie dotyczy.
- Wszystkie odpowiedzi zostaną zapisane.
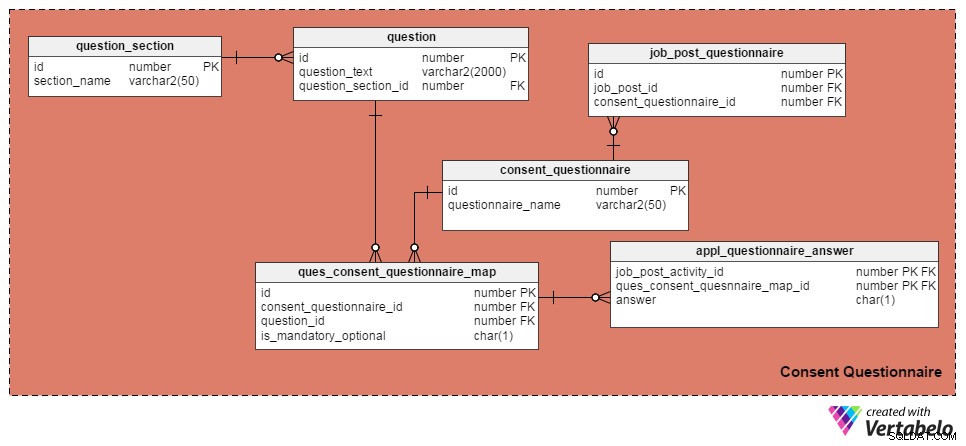
Do zarządzania pytaniami i formularzami zgody wykorzystałem poniższe cztery tabele. Pierwsze, question tabeli, zawiera listę pytań. Ma następujące atrybuty:
id– Klucz główny tabeli, który nadaje każdemu pytaniu unikalny numer identyfikacyjny.question_text– Przechowuje rzeczywisty tekst pytania.question_section_id– Sekcja, w której pojawia się pytanie. (Np. „Czy pracowałeś w tworzeniu oprogramowania przez co najmniej pięć lat?” pojawi się w sekcji „Doświadczenie zawodowe”.) To jest kolumna klucza obcego, do której odnosi sięquestion_sectionstół.
question_section tabela przechowuje informacje o sekcji. Jest to sposób na grupowanie pytań związanych z tym samym tematem. Oprócz id atrybut, który jest kluczem podstawowym dla tabeli, jedynym atrybutem jest section_name , co nie wymaga wyjaśnień.
consent_questionnaire tabela zawiera nazwy formularzy zgody. Jego dwa atrybuty są również oczywiste.
ques_consent_questionnaire_map tabela jest rdzeniem tego obszaru tematycznego. Wszystkie pozostałe tabele z tego obszaru tematycznego są z nim bezpośrednio lub pośrednio związane. Jego celem jest przechowywanie listy pytań oznaczonych do formularzy zgody. Kolumny w tej tabeli to:
id– Klucz podstawowy tej tabeli.consent_questionnaire_id– Numer identyfikacyjny formularza zgody.question_id– Numer identyfikacyjny pytania.is_mandatory_optional– oznacza, czy pytanie jest obowiązkowe czy opcjonalne dla danego formularza zgody. Pytanie może być częścią wielu formularzy zgody, ale w niektórych może być obowiązkowe, a w innych opcjonalne. To jedyny powód, dla którego trzymasz tę kolumnę tutaj, zamiast umieszczać ją wquestionstół.
W kolejnych kilku tabelach omówimy formularze zgody na tagowanie poszczególnych ogłoszeń o pracę i zapiszemy odpowiedzi kandydatów. Zacznijmy od job_post_questionnaire tabeli, w której przechowywane są informacje o tym, jakie formularze zgody są częścią oferty pracy. Może istnieć jeden lub więcej formularzy zgody oznaczonych stanowiskiem pracy. Kolumny w tej tabeli to:
id– Klucz podstawowy tabeli.job_post_id– Wskazuje, z którym ogłoszeniem o pracę jest oznaczony formularz zgody.consent_questionnaire_id– Formularz zgody oznaczony na stanowisku pracy.
Następnie appl_questionnaire_answer tabela rejestruje indywidualne odpowiedzi na każde pytanie formularza zgody wypełnione przez wnioskodawców. Kolumny w tej tabeli to:
job_post_activity_id– Kolumna klucza obcego odniesiona zjob_post_activitystół. Przechowuje informacje o kandydacie, który odpowiedział na pytanie.quest_consent_quesnnaire_map_id– Kolejna kolumna klucza obcego przywołana zquest_consent_questionnaire_mapstół. Przechowuje pytanie, z którego formularza zgody jest udzielana odpowiedź.answer– Rzeczywista odpowiedź osoby ubiegającej się o pracę. Zachowałem ją jako kolumnę CHAR (1), ponieważ na wszystkie pytania w naszym modelu można odpowiedzieć „Tak” (odpowiedź =„Y”), „Nie” (odpowiedź =„N”) lub „Nie dotyczy” (odpowiedź =„X”).
Nowy i ulepszony model danych internetowego portalu pracy
Poniżej możesz zobaczyć wypełniony model danych.
Co byś dodał?
Czy możesz pomyśleć o innych funkcjach, które możesz dodać do naszego internetowego portalu pracy? Podziel się swoimi opiniami w sekcji komentarzy.