Biodro>
Korzystanie z indeksu w bazie danych SQL Server ma miejsce w środowiskach, które wymagają największej wydajności, szybkości i oszczędności pamięci.
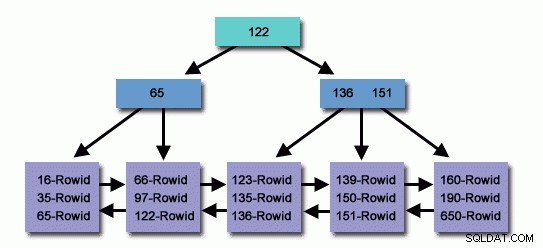
W tabeli zawierającej miliony lub miliardy rekordów możemy użyć indeksu, aby odczytać mniej rekordów i mniej wyszukiwać, aby znaleźć powiązany rekord.
Precyzyjnie stworzony Indeks, miliony rekordów w bazie przeszukaliśmy w bardzo krótkim czasie, aby wydobyć zapis z wygody dzwoniącego, a jednocześnie mniej czytać rekord docierając do docelowego rekordu, efektywnie wykorzystujemy zasoby systemu operacyjnego.
Powinieneś utworzyć indeks dla zapytań głównie do odczytu dotyczących tabeli. Jeśli operacje Delete,update to więcej niż zapytania tylko do odczytu, nie należy tworzyć indeksu tej tabeli.
Możesz spojrzeć na brakującą rekomendację indeksu SQL Server za pomocą następującego skryptu. Możesz utworzyć brakujący indeks, ale powinieneś monitorować te indeksy. Jeśli nie są przydatne, powinieneś je usunąć.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;



