W naszym poprzednim blogu poświęconym pulpitom nawigacyjnym SCUMM przyjrzeliśmy się pulpitowi nawigacyjnemu przeglądu MySQL. Nowa wersja ClusterControl (wersja 1.7) oferuje szereg wykresów o wysokiej rozdzielczości przydatnych metryk, a my przeanalizowaliśmy znaczenie każdej z metryk oraz sposób, w jaki pomagają one w rozwiązywaniu problemów z bazą danych. W tym blogu przyjrzymy się pulpitowi nawigacyjnemu MySQL Replication. Przejdźmy do szczegółów tego pulpitu nawigacyjnego na temat tego, co ma do zaoferowania.
Panel replikacji MySQL
Pulpit nawigacyjny replikacji MySQL oferuje bardzo proste zestawy wykresów, które ułatwiają monitorowanie głównego i repliki MySQL. Zaczynając od góry, pokazuje najważniejsze zmienne i informacje, które pozwalają określić kondycję replik, a nawet mastera. Ta deska rozdzielcza stanowi bardzo przydatną część podczas sprawdzania stanu zdrowia niewolników lub mastera w konfiguracji master-master. Na tym panelu można również sprawdzić tworzenie dziennika binarnego przez mistrza i określić ogólny wymiar pod względem wygenerowanego rozmiaru w określonym czasie.
Pierwszą rzeczą na tym pulpicie nawigacyjnym są najważniejsze informacje, których możesz potrzebować, dotyczące kondycji Twojej repliki. Zobacz poniższy wykres:

Zasadniczo pokaże ci błąd IO_Thread, SQL_Thread, błąd replikacji wątku Slave i czy ma włączoną zmienną tylko do odczytu. Z przykładowego zrzutu ekranu powyżej wszystkie informacje pokazują, że mój slave 192.168.70.20 jest zdrowy i działa normalnie.
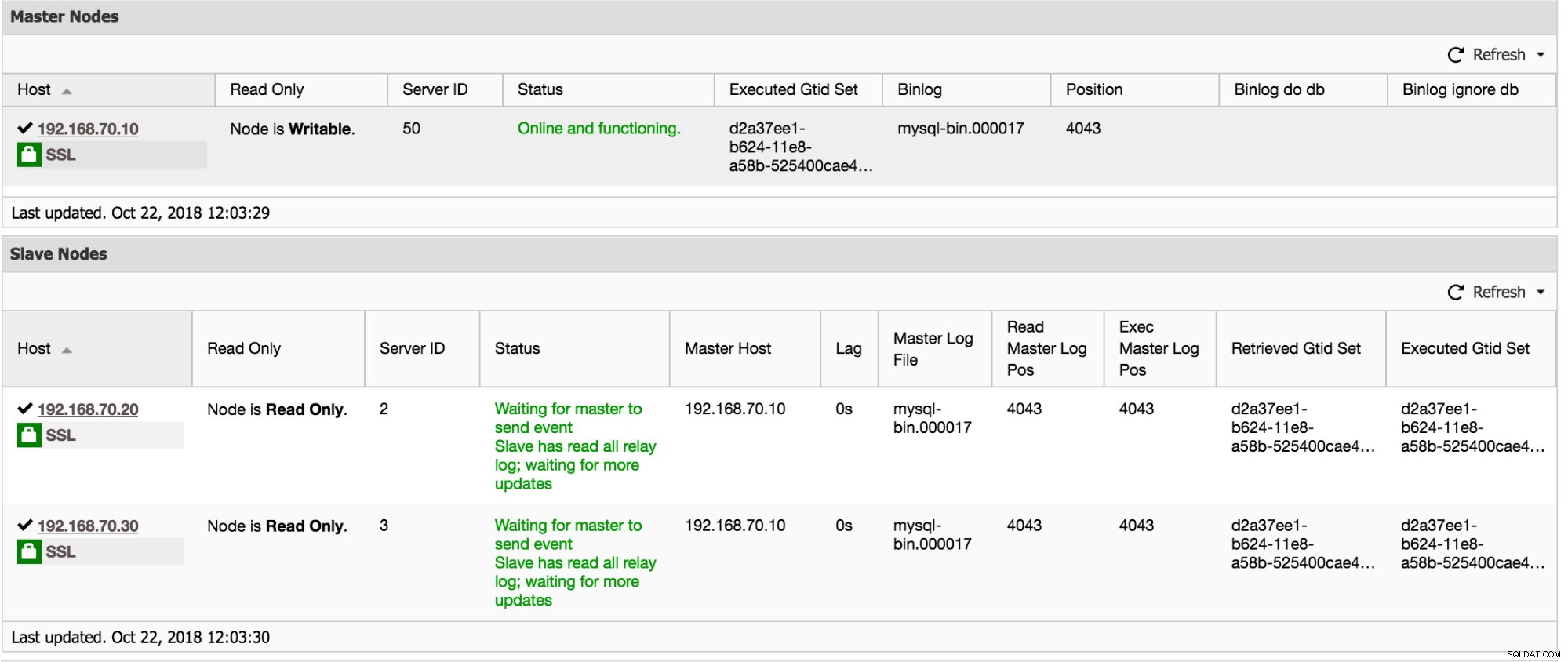
Ponadto ClusterControl ma również informacje do zebrania, jeśli przejdziesz do Cluster -> Przegląd. Przewiń w dół i zobaczysz poniższy wykres:
Innym miejscem, w którym można zobaczyć konfigurację replikacji, jest widok topologii konfiguracji replikacji, dostępny w Klaster -> Topologia. Daje szybki podgląd różnych węzłów w konfiguracji, ich ról, opóźnień replikacji, pobranych identyfikatorów GTID i nie tylko. Zobacz poniższy wykres:
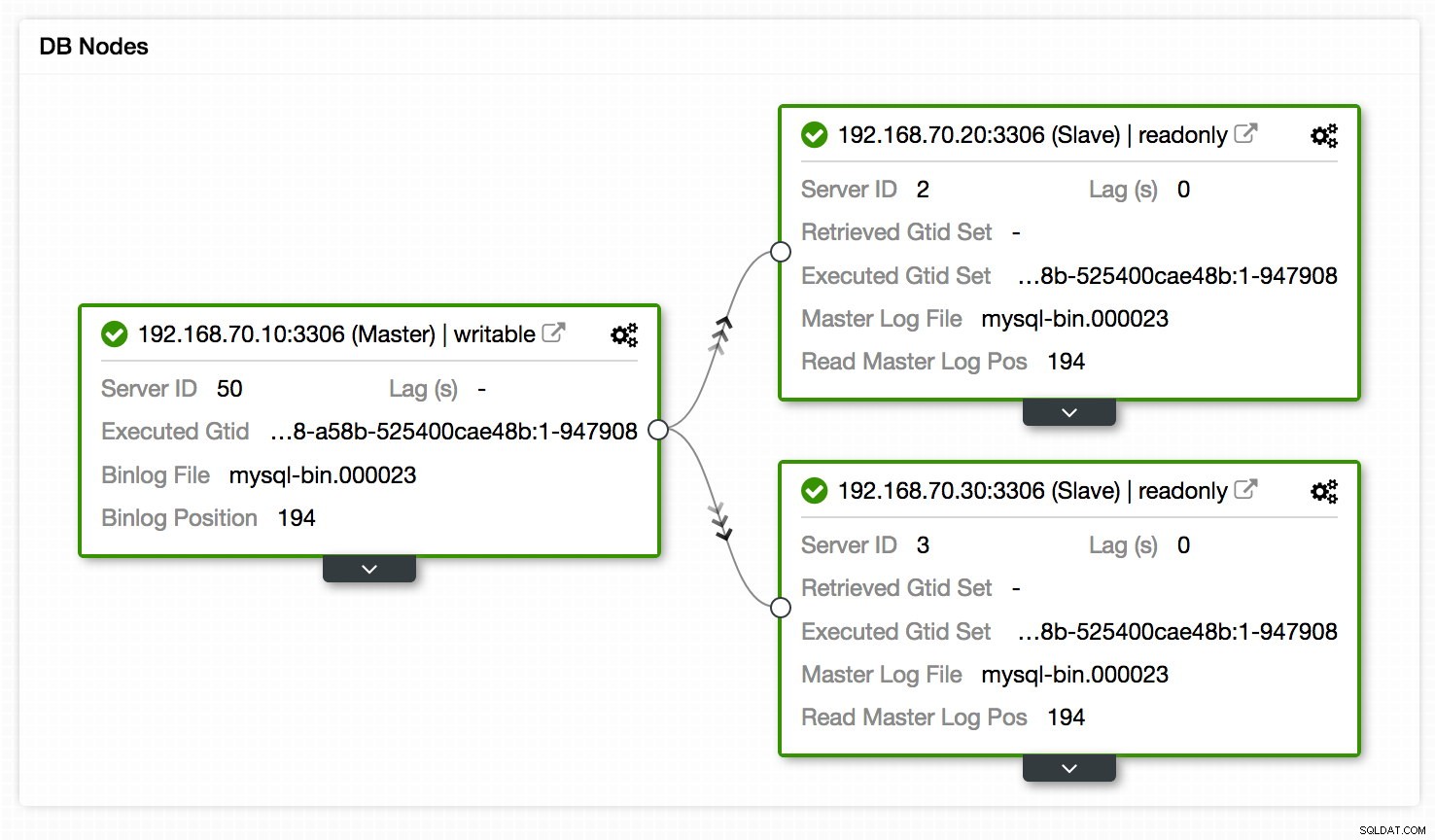
Oprócz tego widok topologii pokazuje również wszystkie różne węzły, które tworzą część klastra bazy danych, niezależnie od tego, czy są to węzły bazy danych, systemy równoważenia obciążenia (ProxySQL/MaxScale/HaProxy) czy arbitrzy (garbd), a także połączenia między nimi. Węzły, połączenia i ich stany są wykrywane przez ClusterControl. Ponieważ ClusterControl stale monitoruje węzły i przechowuje informacje o stanie, wszelkie zmiany w topologii są odzwierciedlane w interfejsie sieciowym. W przypadku zgłoszenia awarii węzłów, możesz użyć tego widoku wraz z pulpitami nawigacyjnymi SCUMM i zobaczyć, jaki wpływ może to spowodować.
Widok topologii ma pewne podobieństwo do programu Orchestrator, w którym można zarządzać węzłami, zmieniać obiekty nadrzędne poprzez przeciąganie i upuszczanie obiektu na żądany obiekt nadrzędny, restartować węzły i synchronizować dane. Aby dowiedzieć się więcej o naszym widoku topologii, zalecamy przeczytanie naszego poprzedniego bloga „Wizualizacja topologii klastra w ClusterControl”.
Przejdźmy teraz do wykresów.
-
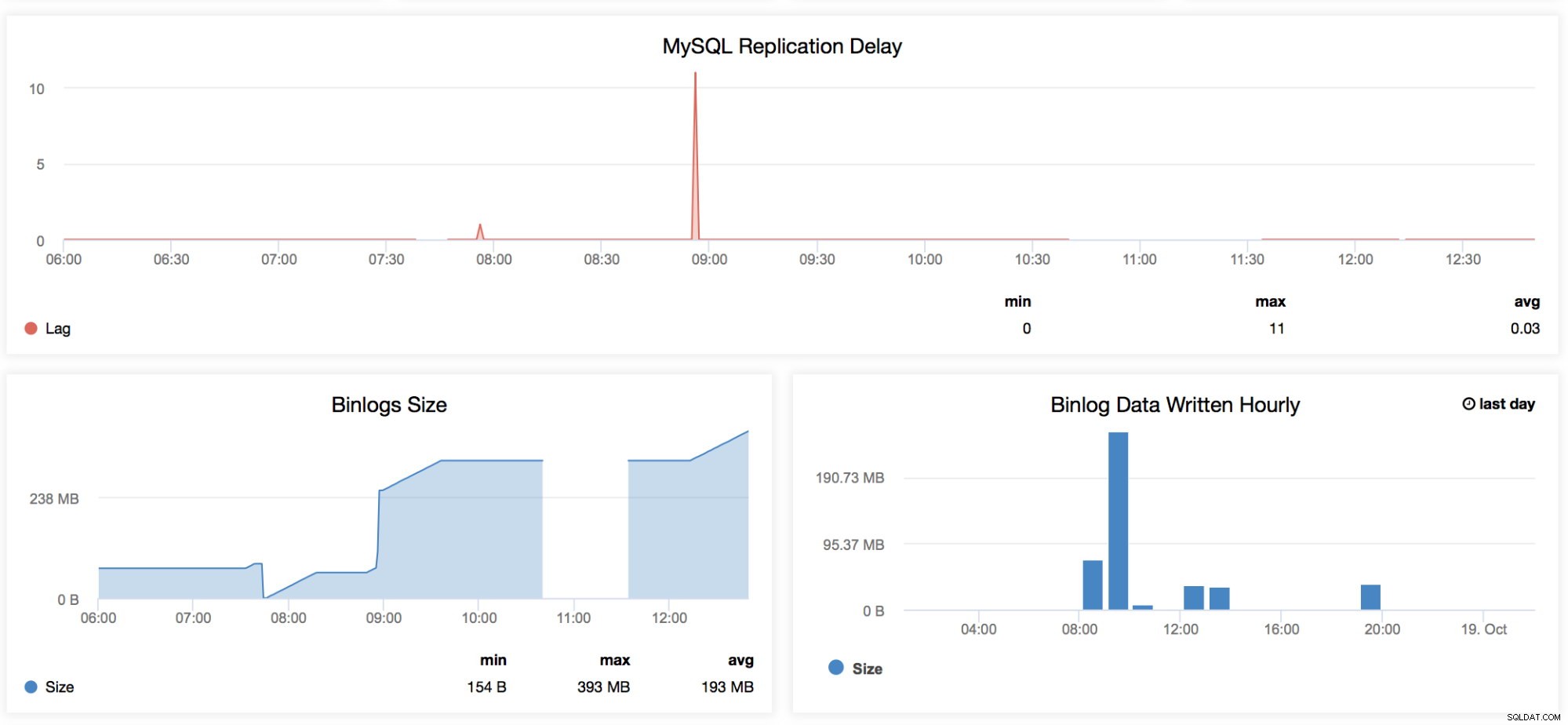
Opóźnienie replikacji MySQL
Ten wykres jest dobrze znany każdemu, kto zarządza MySQL, zwłaszcza tym, którzy na co dzień pracują nad konfiguracją master-slave. Ten wykres zawiera trendy dla wszystkich opóźnień zarejestrowanych w określonym przedziale czasu określonym w tym panelu. Ilekroć chcemy sprawdzić czas opadania okresowego, jaki ma nasza replika, to warto spojrzeć na ten wykres. Istnieją pewne sytuacje, w których replika może się opóźniać z dziwnych powodów, takich jak dysk RAID zdegradowany BBU i wymaga wymiany, tabela nie ma unikalnego klucza, ale nie ma klucza głównego, niechciane pełne skanowanie tabeli lub pełne skanowanie indeksu lub złe zapytanie został uruchomiony przez programistę. Jest to również dobry wskaźnik do określenia, czy opóźnienie podrzędne jest kluczowym problemem, więc możesz skorzystać z replikacji równoległej. -
Binlog Size
Te wykresy są ze sobą powiązane. Wykres Binlog Size pokazuje, w jaki sposób Twój węzeł generuje dziennik binarny i pomaga określić jego wymiar w oparciu o czas skanowania. -
Godzinowe zapisy danych Binlog
Godzinowe zapisy danych Binlog to wykres oparty na zapisanym bieżącym i poprzednim dniu. Może to być przydatne, gdy chcesz określić, jak duży jest twój węzeł, który akceptuje zapisy, co możesz później wykorzystać do planowania pojemności.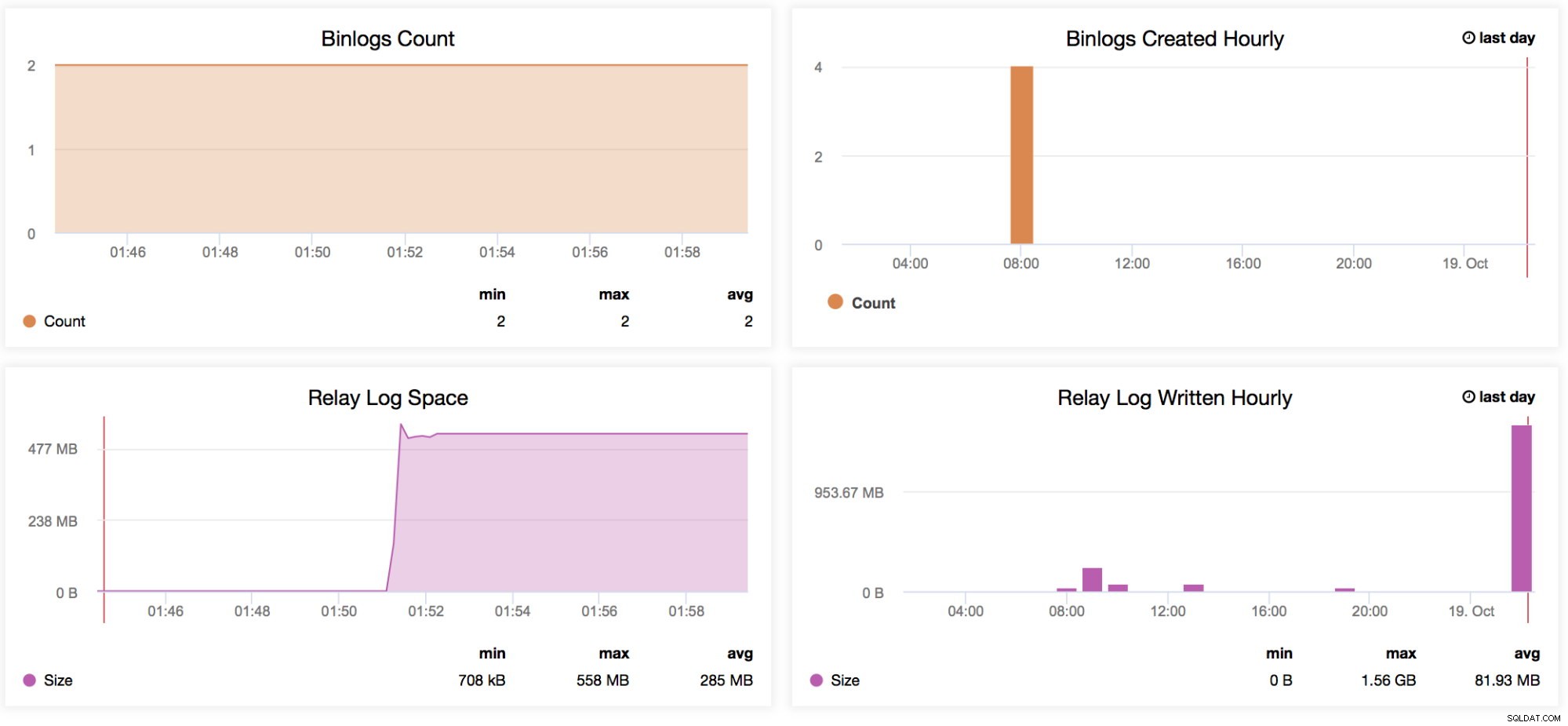
-
Liczba Binlogów
Załóżmy, że spodziewasz się dużego ruchu w danym tygodniu. Chcesz porównać, jak duże zapisy przechodzą przez twojego pana i niewolników z poprzednim tygodniem. Ten wykres jest bardzo przydatny w tego rodzaju sytuacji - aby określić, jak wysoko wygenerowane logi binarne znajdowały się na samym urządzeniu głównym lub nawet na urządzeniach podrzędnych, jeśli włączona jest zmienna log_slave_updates. Możesz również użyć tego wskaźnika, aby określić wygenerowane dane dziennika binarnego nadrzędnego i podrzędnego, zwłaszcza jeśli filtrujesz niektóre tabele lub schematy (replicate_ignore_db, replicate_ignore_table, replicate_wild_do_table) na urządzeniach podrzędnych, które zostały wygenerowane, gdy włączona jest funkcja log_slave_updates. -
Binlogs utworzony co godzinę
Ten wykres jest szybkim przeglądem pozwalającym porównać Twoje binlogi co godzinę od wczoraj do dzisiejszej daty. -
Przestrzeń dziennika przekazywania
Ten wykres służy jako podstawa wygenerowanych dzienników przekazywania z repliki. W połączeniu z wykresem Opóźnienia replikacji MySQL pomaga określić, jak duża jest liczba generowanych dzienników przekaźników, co administrator musi wziąć pod uwagę pod kątem dostępności dysku dla bieżącej repliki. Może to powodować problemy, gdy twój slave jest rygorystycznie opóźniony i generuje dużą liczbę dzienników przekaźników. Może to szybko zająć miejsce na dysku. Istnieją pewne sytuacje, w których ze względu na dużą liczbę zapisów z mastera, slave/replika będzie opóźniać się ogromnie, przez co generowanie dużej liczby logów może spowodować poważne problemy w tej replice. Może to pomóc zespołowi operacyjnemu w rozmowach z kierownictwem na temat planowania wydajności. -
Dziennik przekaźnika pisany co godzinę
To samo, co obszar dziennika przekaźnika, ale dodaje szybki przegląd w celu porównania dzienników przekaźnika zapisanych od wczoraj do dzisiejszej daty.
Wniosek
Dowiedziałeś się, że używanie SCUMM do monitorowania replikacji MySQL zwiększa produktywność i wydajność zespołu operacyjnego. Korzystanie z funkcji, które mamy z poprzednich wersji, w połączeniu z wykresami dostarczonymi z SCUMM, jest jak pójście na siłownię i zobaczenie ogromnej poprawy wydajności. Oto, co może zaoferować SCUMM:monitorowanie na sterydach! (teraz nie zalecamy przyjmowania sterydów podczas chodzenia na siłownię!)
W części 3 tego bloga omówię wskaźniki InnoDB i tablice wskaźników wydajności MySQL.