
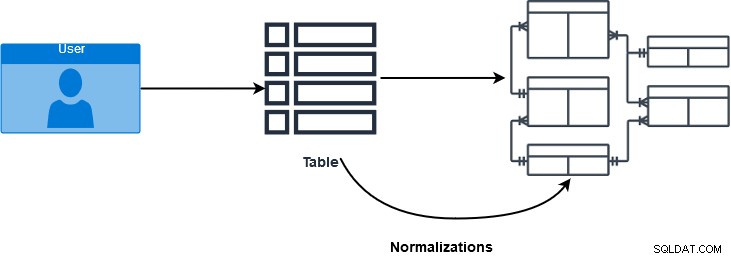
SQL JOIN to klauzula używana do łączenia wielu tabel i pobierania danych na podstawie wspólnego pola w relacyjnych bazach danych. Specjaliści od baz danych stosują normalizacje w celu zapewnienia i poprawy integralności danych. W różnych formach normalizacji dane są rozdzielane na wiele tabel logicznych. Tabele te wykorzystują ograniczenia referencyjne — klucz podstawowy i klucze obce — w celu wymuszenia integralności danych w tabelach programu SQL Server. Na poniższym obrazku mamy wgląd w proces normalizacji bazy danych.
Zrozumienie różnych typów SQL JOIN
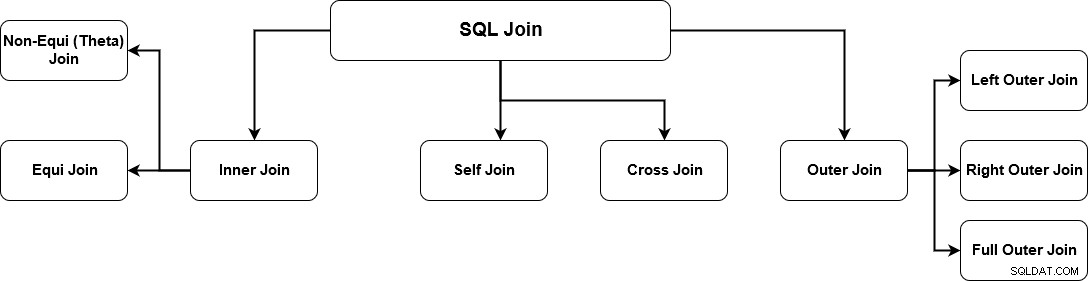
SQL JOIN generuje znaczące dane, łącząc wiele tabel relacyjnych. Te tabele są powiązane za pomocą klucza i mają relacje jeden do jednego lub jeden do wielu. Aby pobrać poprawne dane, musisz znać wymagania dotyczące danych i poprawne mechanizmy łączenia. SQL Server obsługuje wiele sprzężeń, a każda metoda ma określony sposób pobierania danych z wielu tabel. Poniższy obraz określa obsługiwane przyłącza SQL Server.
Złączenie wewnętrzne SQL
Sprzężenie wewnętrzne SQL zawiera wiersze z tabel, w których spełnione są warunki sprzężenia. Na przykład na poniższym diagramie Venna sprzężenie wewnętrzne zwraca pasujące wiersze z Tabeli A i Tabeli B.
W poniższym przykładzie zwróć uwagę na następujące rzeczy:
- Mamy dwie tabele – [Pracownicy] i [Adres].
- Zapytanie SQL jest połączone w kolumnie [Pracownicy].[Identyfikator stanowiska] i [Adres].[ID].
Dane wyjściowe zapytania zwracają rekordy pracowników dla EmpID, które istnieją w obu tabelach.
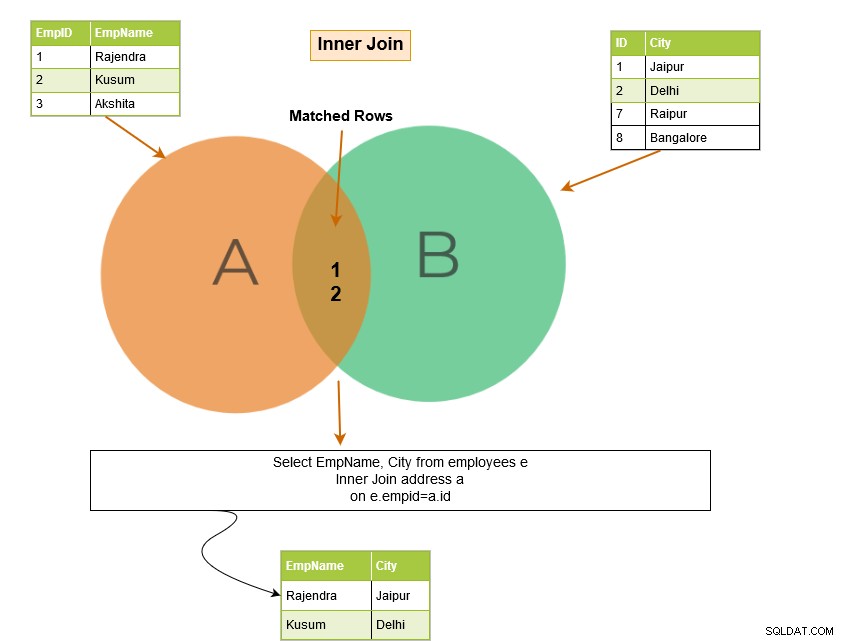
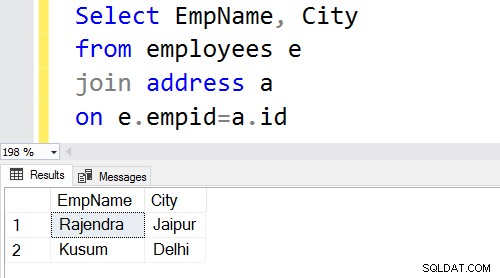
Sprzężenie wewnętrzne zwraca pasujące wiersze z obu tabel; dlatego jest również znany jako sprzężenie Equi. Jeśli nie określimy słowa kluczowego inner, SQL Server wykona operację sprzężenia wewnętrznego.
W innym typie sprzężenia wewnętrznego, sprzężeniu theta, nie używamy operatora równości (=) w klauzuli ON. Zamiast tego używamy operatorów nierówności, takich jak .
SELECT * FROM Tabela1 T1, Tabela2 T2 WHERE T1.Cena
W przypadku samodzielnego łączenia SQL Server łączy ze sobą tabelę. Oznacza to, że nazwa tabeli pojawia się dwukrotnie w klauzuli from.
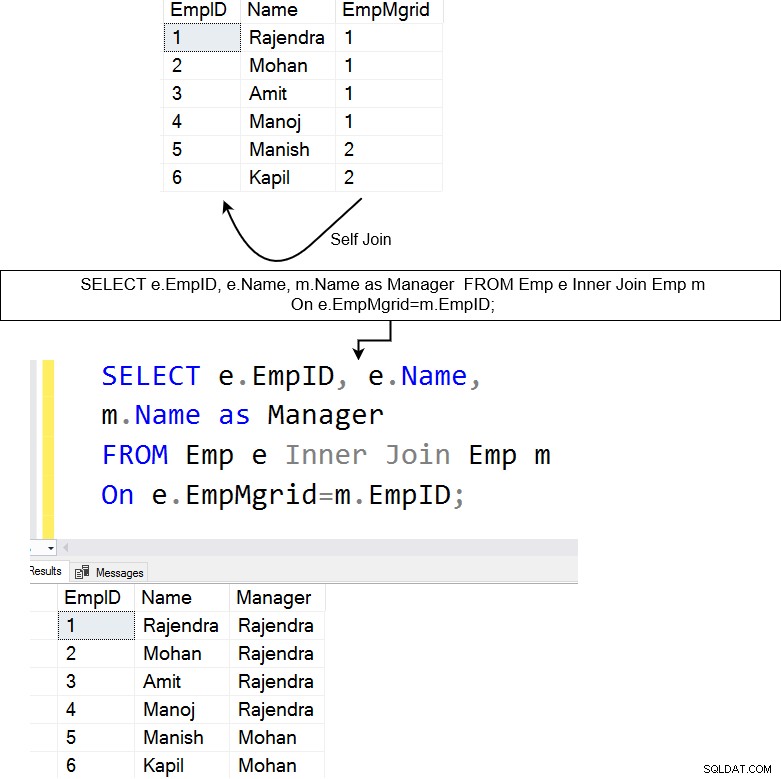
Poniżej mamy tabelę [Emp], która zawiera dane pracowników oraz ich menedżerów. Samosprzężenie jest przydatne do wykonywania zapytań dotyczących danych hierarchicznych. Na przykład w tabeli pracowników możemy użyć funkcji samodzielnego łączenia, aby poznać każdego pracownika i imię i nazwisko jego kierownika raportującego.
Powyższe zapytanie umieszcza samozłączanie w tabeli [Emp]. Łączy kolumnę EmpMgrID z kolumną EmpID i zwraca pasujące wiersze.
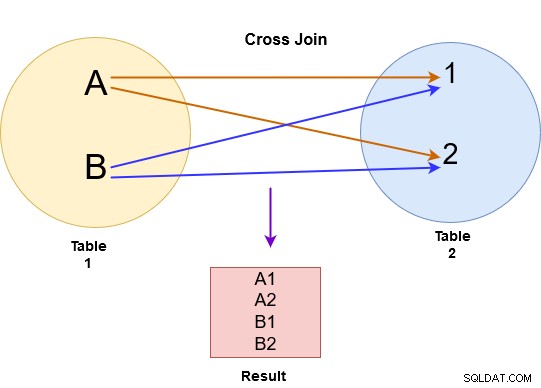
W połączeniu krzyżowym SQL Server zwraca produkt kartezjański z obu tabel. Na przykład na poniższym obrazku wykonaliśmy połączenie krzyżowe dla tabel A i B.
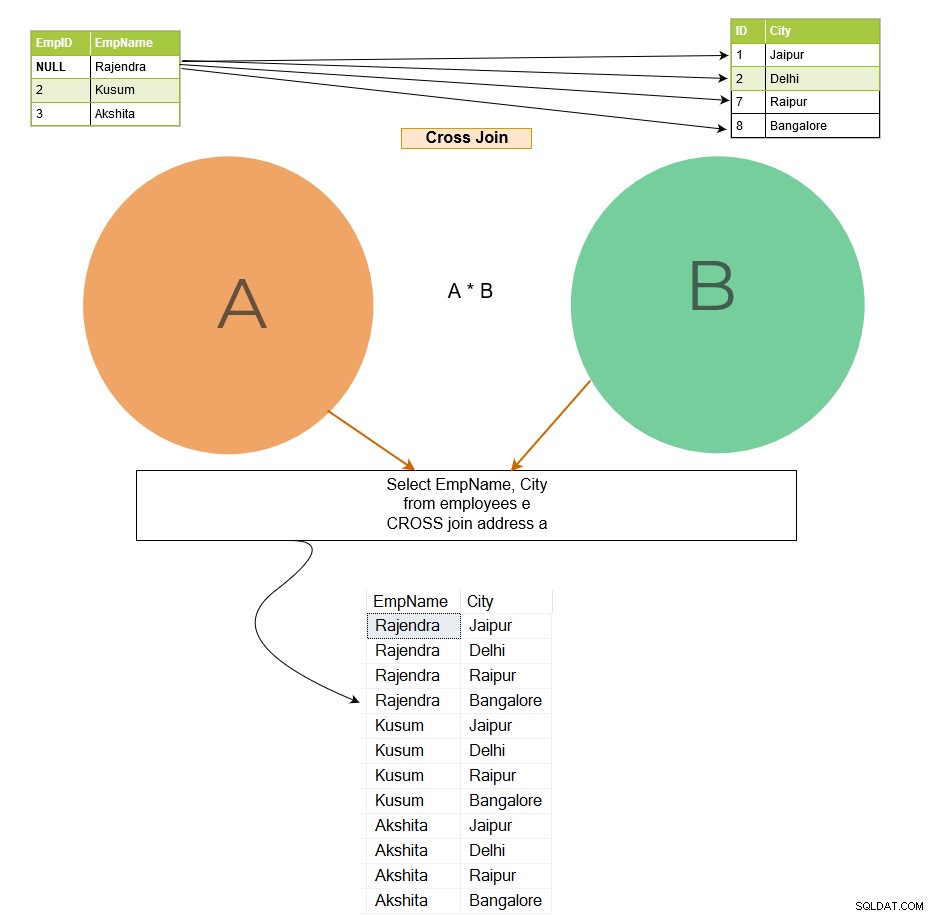
Sprzężenie krzyżowe łączy każdy wiersz z tabeli A z każdym wierszem dostępnym w tabeli B. Dlatego wynik jest również znany jako iloczyn kartezjański obu tabel. Na poniższym obrazku zwróć uwagę na następujące kwestie:
W danych wyjściowych łączenia krzyżowego wiersz 1 tabeli [Employee] łączy się ze wszystkimi wierszami tabeli [Adres] i stosuje ten sam wzorzec dla pozostałych wierszy.
Jeśli pierwsza tabela ma liczbę x wierszy, a druga tabela ma liczbę n wierszy, łączenie krzyżowe daje w wyniku x*n liczbę wierszy. Należy unikać łączenia krzyżowego w większych tabelach, ponieważ może to zwrócić ogromną liczbę rekordów, a SQL Server wymaga dużej mocy obliczeniowej (procesora, pamięci i IO) do obsługi tak obszernych danych.
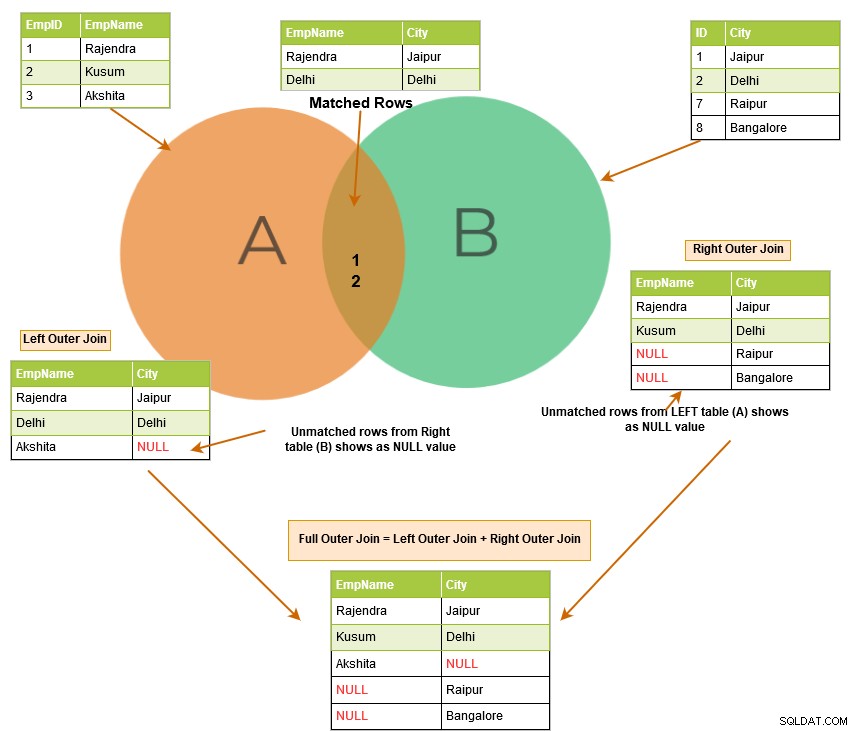
Jak wyjaśniliśmy wcześniej, sprzężenie wewnętrzne zwraca pasujące wiersze z obu tabel. Podczas korzystania z zewnętrznego sprzężenia SQL nie tylko wyświetla pasujące wiersze, ale także zwraca niedopasowane wiersze z innych tabel. Niedopasowany wiersz zależy od lewego, prawego lub pełnego słowa kluczowego.
Poniższy obraz przedstawia na wysokim poziomie lewe, prawe i pełne sprzężenie zewnętrzne.
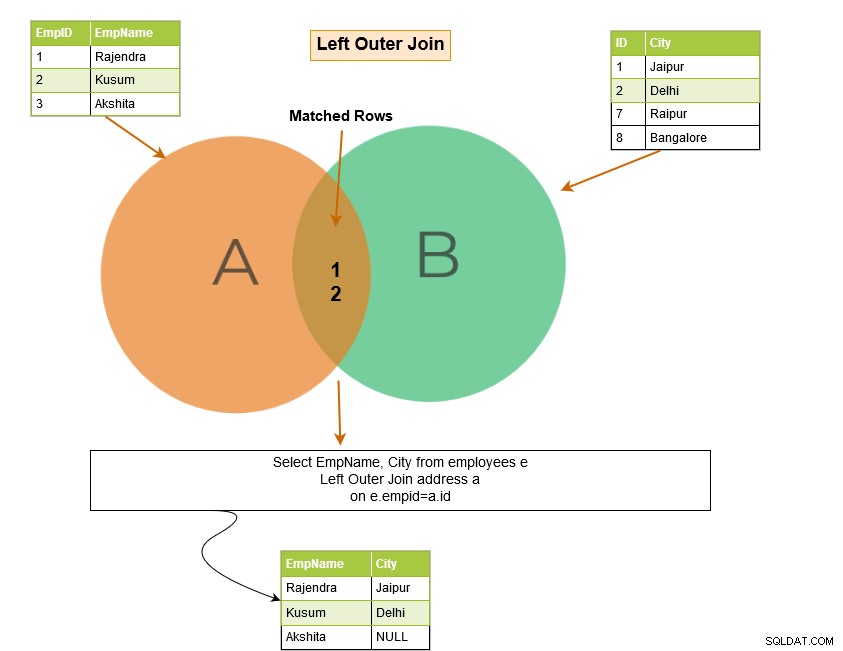
Lewe sprzężenie zewnętrzne SQL zwraca pasujące wiersze obu tabel wraz z niedopasowanymi wierszami z lewej tabeli. Jeśli rekord z lewej tabeli nie ma pasujących wierszy w prawej tabeli, wyświetla rekord z wartościami NULL.
W poniższym przykładzie lewe sprzężenie zewnętrzne zwraca następujące wiersze:
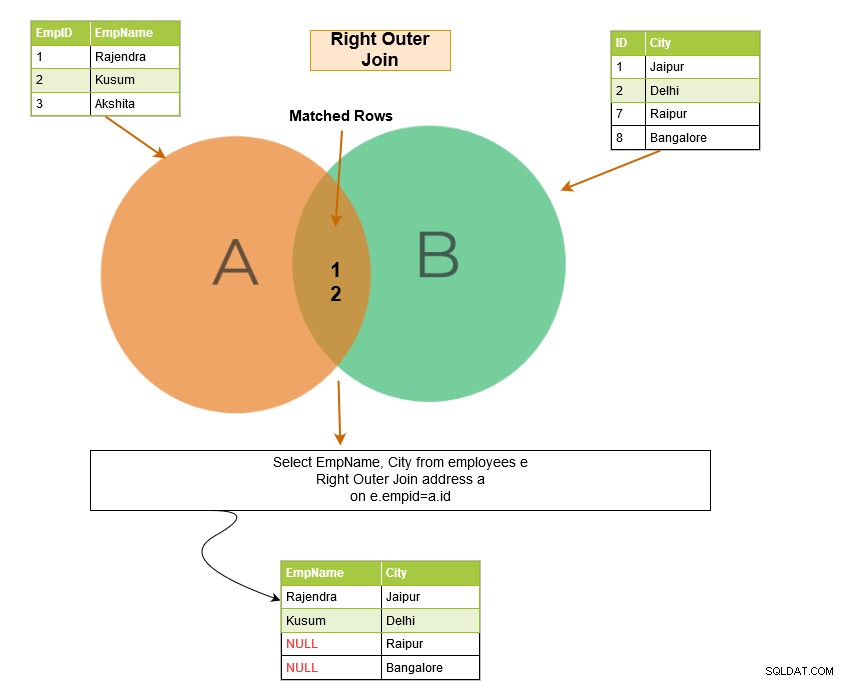
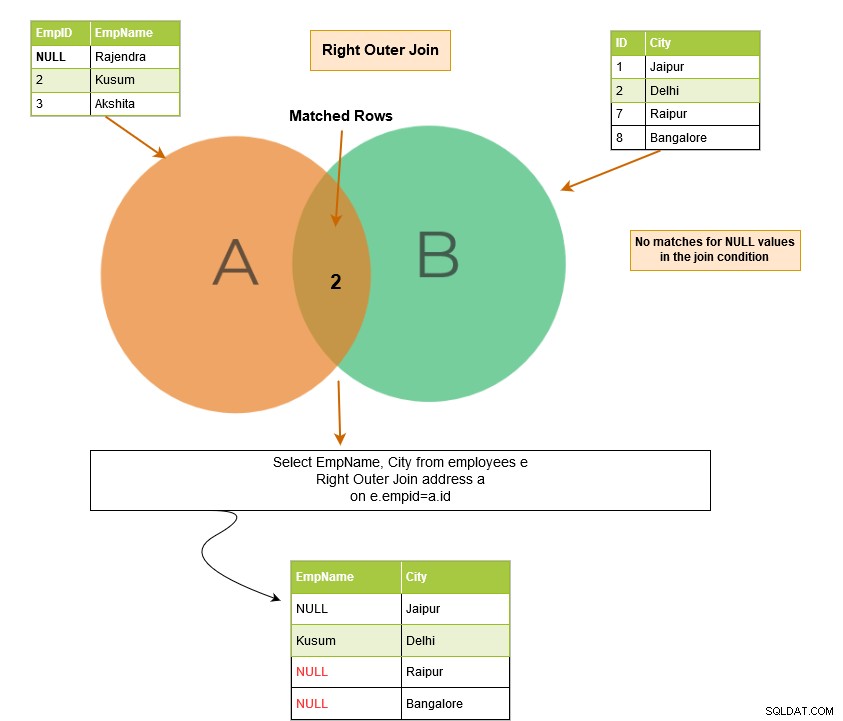
Prawe sprzężenie zewnętrzne SQL zwraca pasujące wiersze obu tabel wraz z niedopasowanymi wierszami z prawej tabeli. Jeśli rekord z prawej tabeli nie ma pasujących wierszy w lewej tabeli, wyświetla rekord z wartościami NULL.
W poniższym przykładzie mamy następujące wiersze wyjściowe:
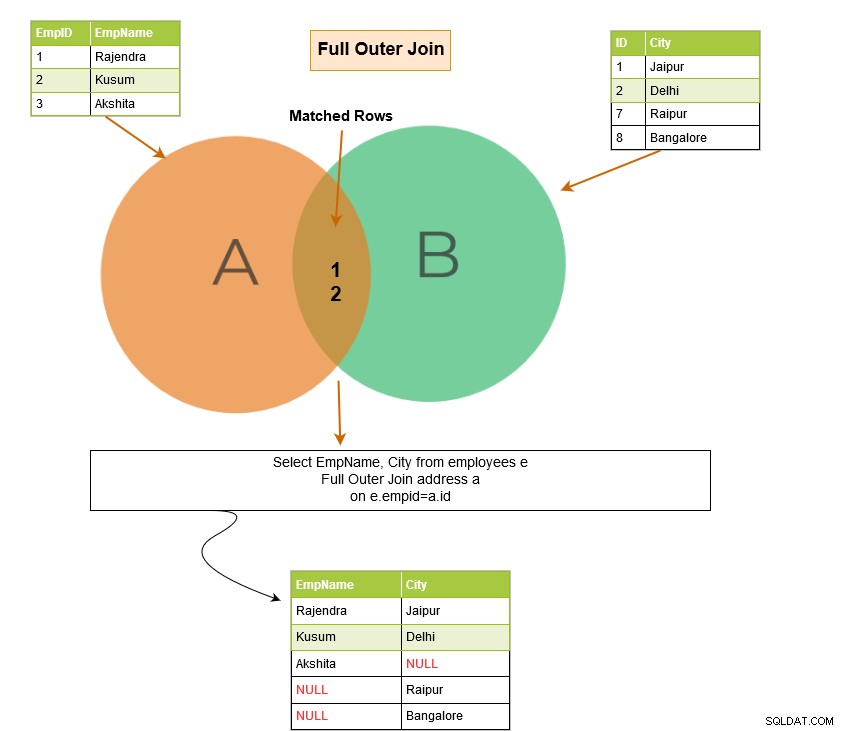
Pełne sprzężenie zewnętrzne zwraca w danych wyjściowych następujące wiersze:
W poprzednich przykładach używamy dwóch tabel w zapytaniu SQL do wykonywania operacji złączenia. Przeważnie łączymy wiele tabel razem i zwracamy odpowiednie dane.
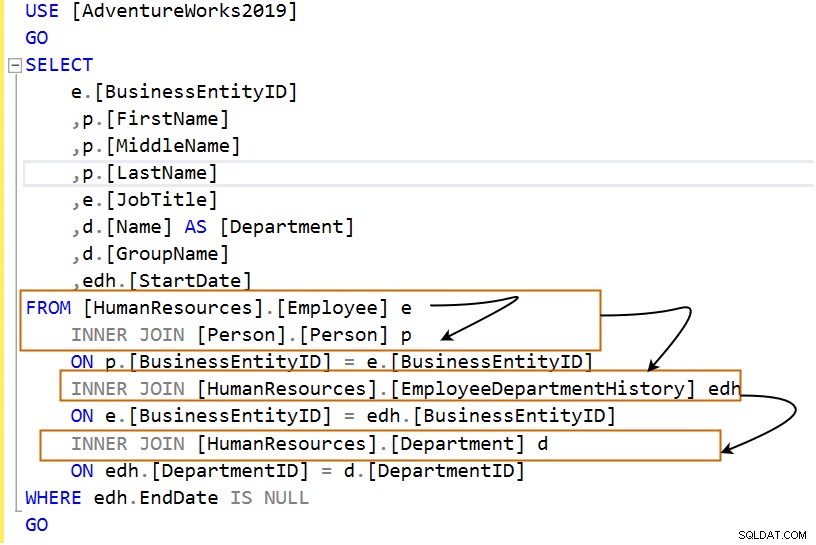
Poniższe zapytanie używa wielu sprzężeń wewnętrznych.
Przeanalizujmy zapytanie w następujących krokach:
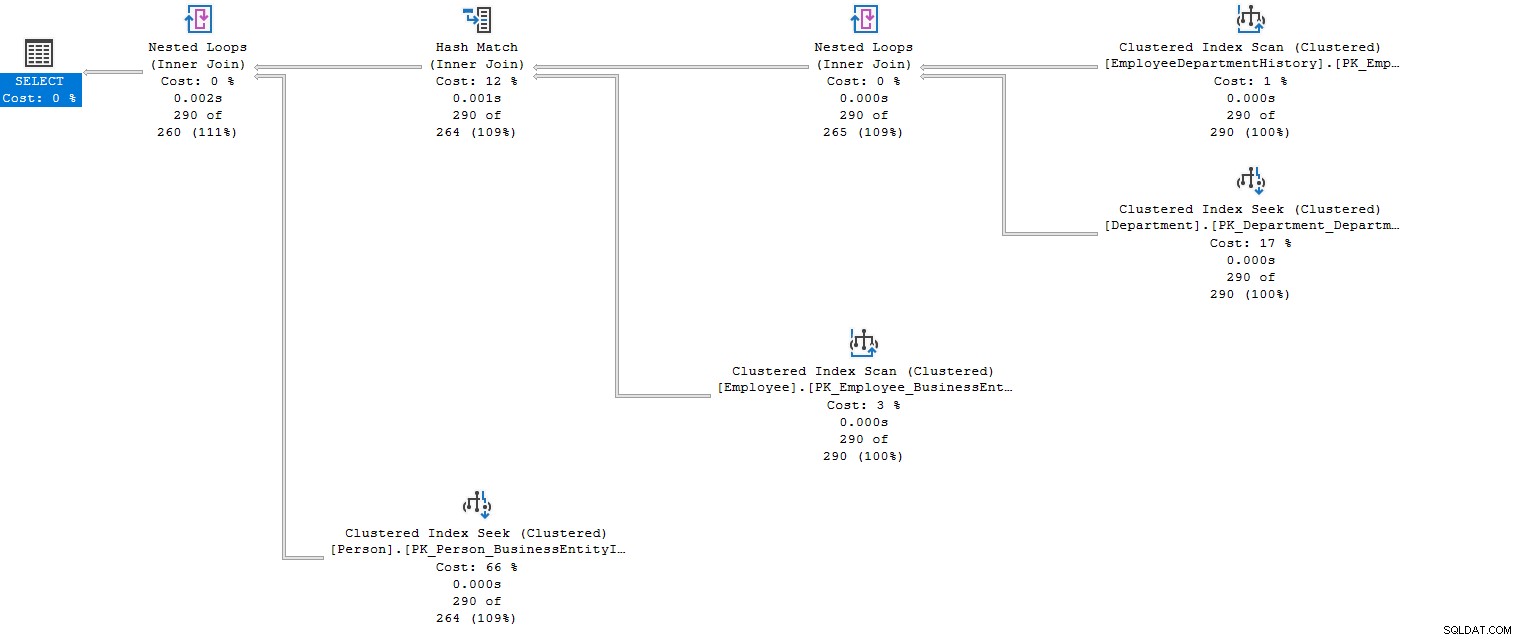
Po wykonaniu zapytania z wieloma sprzężeniami optymalizator zapytań przygotowuje plan wykonania. Przygotowuje zoptymalizowany pod względem kosztów plan wykonania spełniający warunki łączenia z wykorzystaniem zasobów — na przykład w poniższym rzeczywistym planie wykonania możemy przyjrzeć się wielu zagnieżdżonym pętlom (sprzężenie wewnętrzne) i hash match (sprzężenie wewnętrzne) łączącym dane z wielu tabel łączących .
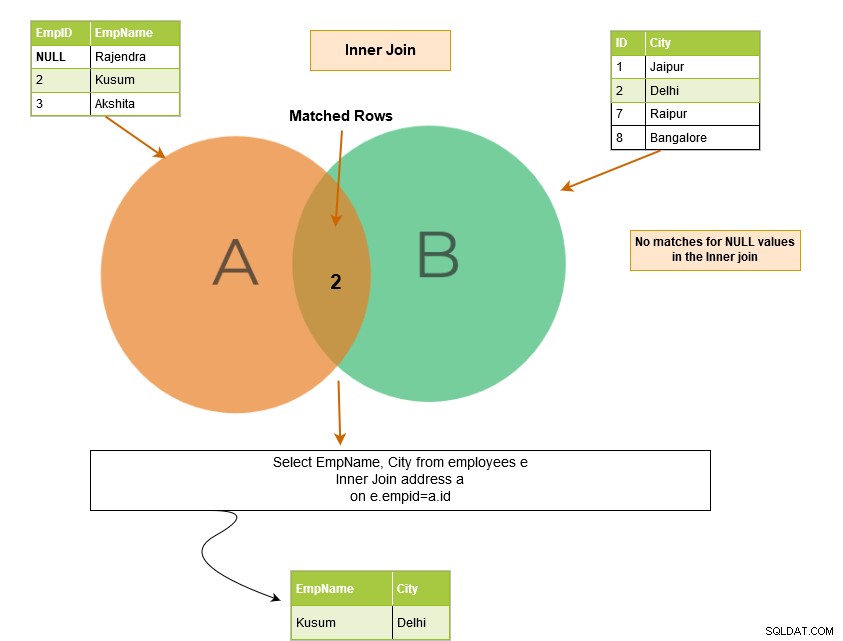
Załóżmy, że w kolumnach tabeli mamy wartości NULL i łączymy tabele w tych kolumnach. Czy SQL Server pasuje do wartości NULL?
Wartości NULL nie pasują do siebie. Dlatego SQL Server nie może zwrócić pasującego wiersza. W poniższym przykładzie mamy NULL w kolumnie EmpID tabeli [Employees]. Dlatego na wyjściu zwraca pasujący wiersz tylko dla [EmpID] 2.
Możemy uzyskać ten wiersz NULL w danych wyjściowych w przypadku zewnętrznego sprzężenia SQL, ponieważ zwraca on również niedopasowane wiersze.
W tym artykule omówiliśmy różne typy złączeń SQL. Oto kilka ważnych najlepszych praktyk, które należy zapamiętać i zastosować podczas korzystania z łączeń SQL.Samodzielne łączenie SQL
Połączenie krzyżowe SQL
Zewnętrzne sprzężenie SQL
Lewe sprzężenie zewnętrzne
Prawe sprzężenie zewnętrzne
Pełne sprzężenie zewnętrzne
Łączenia SQL z wieloma tabelami
USE [AdventureWorks2019]
GO
SELECT
e.[BusinessEntityID]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
GO
Wartości NULL i łączenia SQL
Najlepsze praktyki łączenia SQL



