System Zarządzania Bazą Danych to skarbnica informacji. Postaramy się zaprojektować system zarządzania bazą danych tak, aby baza danych była dobrze zarządzana i zapewniała cele.
W tym artykule omówimy projektowanie i administrowanie wielkogabarytowymi systemami baz danych. Użyjemy wielu konstytucji, które będą obejmować technologie baz danych, pamięć masową, dystrybucję danych, zasoby serwerowe, wzorzec architektury i kilka innych.
Najlepiej szukać dużej bazy danych w domenie Telco, platformach eCommerce, domenie ubezpieczeniowej, systemie bankowym, służbie zdrowia, systemie energetycznym itp. Przed wyborem odpowiedniej technologii bazodanowej musimy mieć na uwadze kilka parametrów. tj. ruch, TPS (transakcje na sekundę), szacowane przechowywanie na dzień, HA i DR.
Projektowanie dużej bazy danych
Konstruując naszą bazę danych musimy zwrócić uwagę na kilka parametrów, ponieważ często bardzo problematyczna jest zmiana bazy na zamiennik. Rozważmy je teraz.
Technologia baz danych
Technologia baz danych jest głównym czynnikiem. Jeśli wybierzesz odpowiedni system zarządzania bazą danych, pomoże to Twojej firmie działać wydajnie i bez wysiłku.
Istnieją różne technologie baz danych z wieloma funkcjami. Jednak podczas pracy z technologiami baz danych typu open source możesz nie uzyskać dostępu do niektórych jawnych funkcji predefiniowanych rozwiązań. Zapewnią je technologie baz danych korporacyjnych, takie jak Microsoft SQL Server, Oracle itp.
Wiele technologii baz danych korporacyjnych wdraża HA (wysoka dostępność), DR (odzyskiwanie po awarii), dublowanie, replikację danych, replikę odczytu wtórnego oraz znacznie wygodniejsze i gotowe do konfiguracji rozwiązania biznesowe. Mogą, ale nie muszą być obecne w bazach danych o otwartym kodzie źródłowym.
Powodów jest wiele. Na przykład czasami stwierdzamy, że istniejąca architektura jest zaburzona, ponieważ wymienione powyżej czynniki nie są funkcjonalne tak, jak ich potrzebujemy.
Pamięć
Pamięć masowa drastycznie wpływa na wydajność rozwiązania biznesowego. Rozwiązania biznesowe wymagają pierwszorzędnej pamięci masowej lub dysku SSD z określoną liczbą IOPS. Czy jednak tak jest? Lokalnie lub w chmurze rozmiar i typ pamięci określają koszty infrastruktury.
Rozważając wydajność pamięci, należy zwrócić uwagę na rodzaj danych i zachowanie przetwarzania danych. Musimy zdecydować się na wybór przechowywania zgodnie z danymi użytkownika i ich przetwarzaniem. Jeśli użytkownik zamierza korzystać z wielu baz danych, musimy zapewnić wybór pamięci masowej zamiast sieci SAN dla różnych baz danych dla typów danych i sposobu przetwarzania danych.
Inżynier baz danych zapewni lepszą retrospekcję różnych baz danych potrzebnych do obliczenia IOPS, jeśli użytkownicy w ogóle nie potrzebują pamięci premium.
Dystrybucja danych
Większość najnowszych technologii baz danych (SQL lub NoSQL) oferuje funkcje partycjonowania lub shardingu.
- Partycja redystrybuuje dane w systemie plików, który jest oparty na kluczu partycji.
- Sharding dystrybuuje informacje w węzłach bazy danych, a dane będą przechowywane na tej samej lub innej maszynie.
Zasadniczo żadna usługa bazy danych ani tabela bazy danych nie będą wymagały funkcji partycjonowania/fragmentowania danych. Wymagają jedynie zastosowania w bazach danych zawierających obiekty o większych rozmiarach. To poprawi wydajność.
Zasoby serwera
Różne maszyny wymagają różnych typów i rozmiarów pamięci i procesora. Musisz wziąć pod uwagę zasoby sprzętowe, takie jak pamięć, procesor itp. Na przykład maszyna, która musi obsługiwać większe bazy danych lub wiele baz danych, będzie potrzebować więcej pamięci i procesorów. Dlatego jakość pamięci i procesora jest znacząca. Będzie obsługiwać różne typy procesorów dostępnych na rynku z różnymi pamięciami podręcznymi procesorów.
Wiele razy napotykamy problemy, których możemy nie być świadomi. Nie zwracaliśmy uwagi na wykorzystanie i rolę pamięci podręcznej procesora sprzętu. Jest to jednak kluczowe dla wyboru i spełnienia wymagań sprzętowych w przypadku większych systemów baz danych.
Wzorzec architektury
W projektowaniu baz danych wzorzec Architektura ma zawsze przykładową rolę. Wcześniej systemy bazodanowe projektowano w sposób niezwykle monolityczny. Teraz używamy mikroserwisów lub hybryd (monolitycznych + mikro).
Wydajność, możliwości rozbudowy i zero przestojów zależą w dużej mierze od wzorca architektury i projektu bazy danych. Każda aplikacja może mieć osobną bazę danych, a wszystkie bazy danych mogą być ze sobą luźno połączone. W przypadku awarii jakiejkolwiek aplikacji lub bazy danych, inna część produktu nie zostanie zakłócona. Wszystkie mikrousługi byłyby niezależne i luźno powiązane.
Mikrousługa
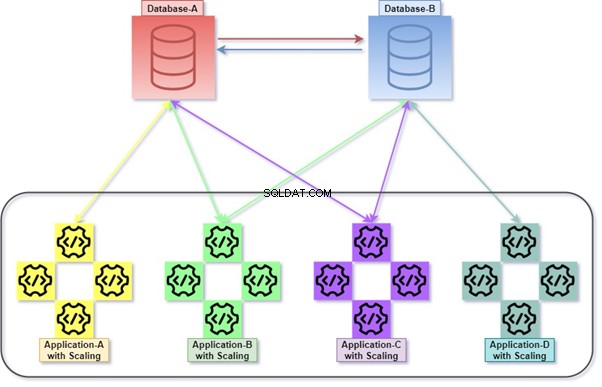
Poniższy diagram wyjaśnia, w jaki sposób wszystkie aplikacje wdrażają i komunikują się za pomocą swoich baz danych, które są jednocześnie luźno powiązane. Możemy manipulować danymi za pomocą T-SQL. Informacje będą gromadzone lub gromadzone przez różne aplikacje, a klient będzie mógł uzyskać dostęp do danych. Zapoznaj się z diagramem z liczbą skalowanych aplikacji i ich zintegrowaną bazą danych.
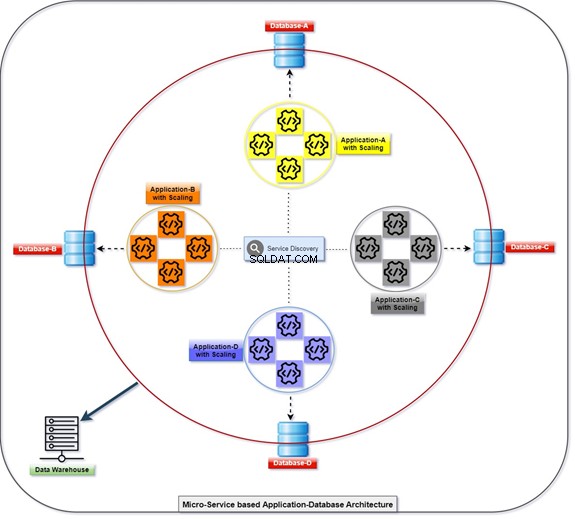
Monolityczny
Którego RDBMS powinniśmy użyć? Może to być Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB lub dowolna inna baza danych. Konwencjonalny sposób radzenia sobie ze wszystkimi tabelami lub obiektami zarządzanymi w jednej lub wielu bazach danych na jednym serwerze jest znany jako monolityczny.
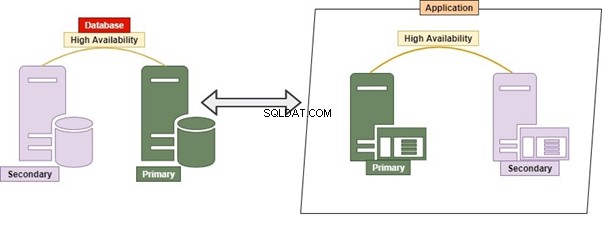
Hybrydowy
Hybrid to połączenie usług monolitycznych i mikro. Jest to dość powszechna praktyka, ponieważ pozwala na wiele aplikacji, liczne bazy danych i serwery baz danych. Liczne bazy danych i serwery baz danych mogą być ze sobą ściśle powiązane.
Na przykład wysyłanie zapytań za pomocą JOIN między tabelami należącymi do co najmniej dwóch baz danych na tym samym lub innym serwerze bazy danych. Zdalne zapytanie używane do pobierania/manipulowania danymi z innym serwerem bazy danych.
Wszystko dotyczy architektury SQL Server. Mówimy jednak o manipulacji danymi między różnymi tabelami w tej samej bazie danych lub różnymi bazami danych, które mogą znajdować się na tym samym serwerze lub na różnych serwerach.
Zarówno w architekturze hybrydowej, jak i monolitycznej używamy JOIN między różnymi tabelami w tej samej lub różnych bazach danych. Jest to dość skomplikowane, gdy postępujemy zgodnie z podstawowymi standardami mikrousług, ponieważ rozkład tabel może odbywać się między usługami bazy danych (Dbas).
W technologiach baz danych Enterprise, takich jak Microsoft SQL Server, Oracle, itp., użytkownik może przeszukiwać tabele rozproszonej bazy danych za pomocą łączeń połączonych serwerów. Ale nie jest dostępny we wszystkich technologiach baz danych o otwartym kodzie źródłowym. Jest to znane jako podejście Tight-Coupled, które może nie działać, gdy usługa zdalnej bazy danych nie jest dostępna.
Omówmy teraz, jak to jest luźno połączone. Dlaczego potrzebujemy manipulacji danymi między zdalnymi bazami danych?
Dlaczego wymagamy manipulacji danymi między zdalnymi bazami danych?
Użytkownicy będą wymagać, aby dane były pobierane z więcej niż jednej usługi bazy danych, gdy system jest projektowany za pomocą usług Micro lub Hybrid. Cały proces jest widoczny z poziomu zaplecza, które może obsługiwać ilości danych manipulowanych przez aplikację.
Kiedy patrzymy na zapytania między bazami danych w czasie rzeczywistym, zawsze dołączamy tabele jednostek głównych, a nie tabele metadanych. Tabele główne nie będą większe niż tabele metadanych. Do celów raportowania zawsze korzystamy z hurtowni danych, aby zebrać wszystkie informacje razem. Ale nie jest to łatwe w zarządzaniu i utrzymaniu dla każdego produktu. Jeśli projektujemy rozwiązanie dla przedsiębiorstw, stać nas na magazyn. Ale nie stać nas na to dla małych lub średnich produktów.
Na przykład potrzebujemy raportu z danymi z kilku tabel znajdujących się w różnych bazach danych. Nie jest to łatwe zadanie, ponieważ zestawia dane przy użyciu różnych mikrousług i łączy je w celu wygenerowania raportu. Dlatego niezbędne dane muszą zostać zsynchronizowane.
Czego możemy użyć jako rozwiązania standardowego zrobić luźną synchronizację danych tabeli między dwiema bazami danych?
Replikacja tabel powinna być używana do prostej synchronizacji danych między wieloma bazami danych. Przykładem jest replikacja transakcji dla synchronizacji danych w trybie Simplex oraz replikacja łączenia dla synchronizacji danych w trybie Duplex dostarczana przez SQL Server.
Istnieje kilka płatnych rozwiązań innych firm i rozwiązań typu open source, które mogą synchronizować dane między wieloma bazami danych. Nawet luźne rozwiązania z pomocą kolejek wiadomości, takie jak SQL Server Transaction Replication, mogą być opracowywane przez użytkowników samodzielnie.
Wniosek
DBA projektują bazy danych na swój sposób. Przy projektowaniu bazy danych i wyborze systemu zarządzania bazą danych muszą mieć na uwadze wiele aspektów. Przedstawiliśmy najistotniejsze czynniki przy projektowaniu baz danych, szczególnie dla baz danych o większych rozmiarach. Czekajcie na kolejne materiały!