Optymalizator SQL Server zawiera logikę usuwania nadmiarowych złączeń, ale istnieją ograniczenia, a złączenia muszą być o udowodnionej redundancji . Podsumowując, sprzężenie może mieć cztery efekty:
- Może dodawać dodatkowe kolumny (z połączonej tabeli)
- Może dodawać dodatkowe wiersze (połączona tabela może odpowiadać wierszowi źródłowemu więcej niż raz)
- Może usuwać wiersze (połączony stół może nie pasować)
- Może wprowadzić
NULLs (dlaRIGHTlubFULL JOIN)
Aby pomyślnie usunąć sprzężenie nadmiarowe, zapytanie (lub widok) musi uwzględniać wszystkie cztery możliwości. Kiedy zrobisz to poprawnie, efekt może być zdumiewający. Na przykład:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Optymalizator może z powodzeniem uprościć następujące zapytanie:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Do:

Rob Farley szczegółowo opisał te pomysły w oryginalnej książce MVP Deep Dives i istnieje nagranie jego prezentacji na ten temat w SQLBits.
Główne ograniczenia polegają na tym, że relacje klucza obcego musi opierać się na jednym kluczu przyczyni się do procesu uproszczenia, a czas kompilacji zapytań z takim widokiem może się wydłużyć, szczególnie w miarę wzrostu liczby złączeń. Napisanie 100-tabelowego widoku, w którym wszystkie semantyki są dokładnie poprawne, może być nie lada wyzwaniem. Skłonny byłbym znaleźć alternatywne rozwiązanie, być może przy użyciu dynamicznego SQL .
To powiedziawszy, szczególne cechy twojej zdenormalizowanej tabeli mogą oznaczać, że widok jest dość prosty w montażu, wymagający tylko wymuszonych FOREIGN KEYs non-NULL w stanie odwołać kolumny i odpowiednie UNIQUE ograniczenia, aby to rozwiązanie działało zgodnie z oczekiwaniami, bez narzutu 100 fizycznych operatorów łączenia w planie.
Przykład
Używając dziesięciu tabel zamiast stu:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Definicja tabeli nadrzędnej (z kompresją strony):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Widok:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Zhakuj statystyki, aby optymalizator uznał, że tabela jest bardzo duża:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Przykładowe zapytanie użytkownika:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Daje nam ten plan wykonania:
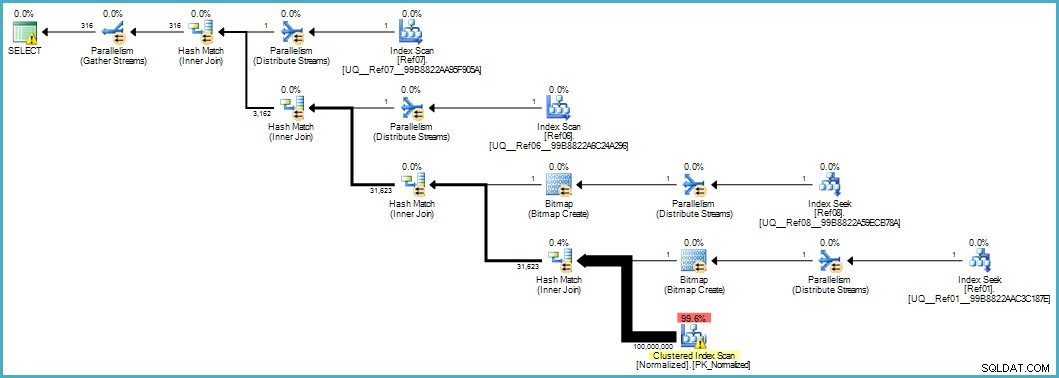
Skanowanie tabeli znormalizowanej wygląda źle, ale obie mapy bitowe z filtrem Blooma są stosowane podczas skanowania przez aparat pamięci masowej (więc wiersze, które nie są zgodne, nie pojawiają się nawet na powierzchni procesora zapytań). Może to wystarczyć, aby zapewnić akceptowalną wydajność w Twoim przypadku, a na pewno lepsze niż skanowanie oryginalnej tabeli z jej przepełnionymi kolumnami.
Jeśli jesteś w stanie uaktualnić do SQL Server 2012 Enterprise na pewnym etapie, masz inną opcję:utworzenie indeksu magazynu kolumn w tabeli Normalized:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Plan wykonania to:
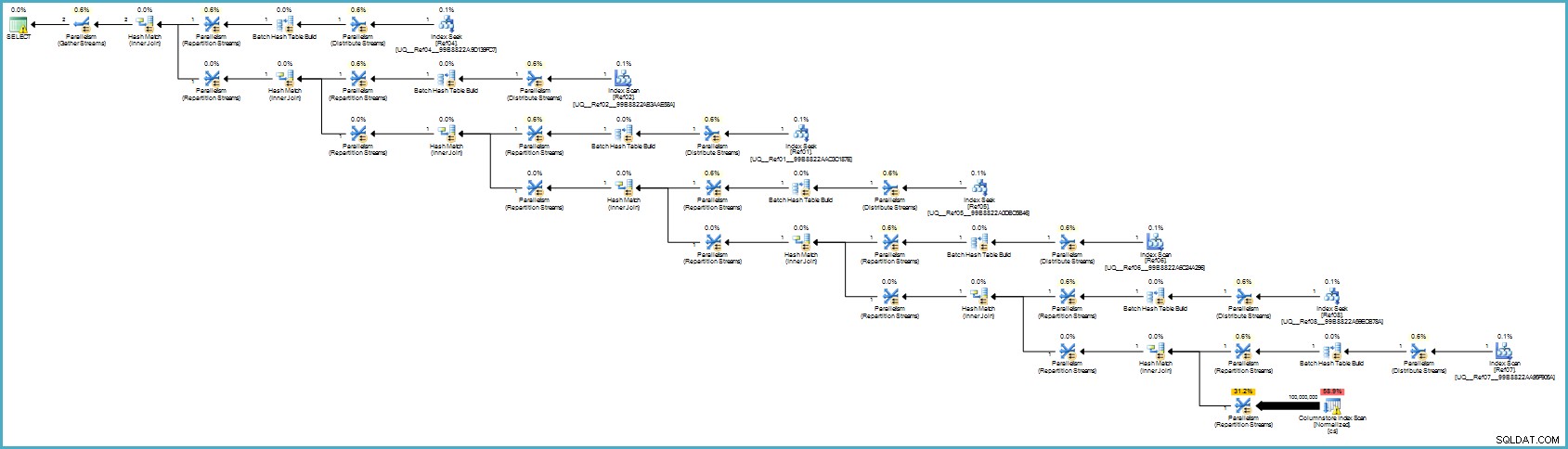
To prawdopodobnie wygląda gorzej, ale przechowywanie kolumn zapewnia wyjątkową kompresję, a cały plan wykonania działa w trybie wsadowym z filtrami dla wszystkich współpracujących kolumn. Jeśli serwer ma dostępną odpowiednią ilość wątków i pamięci, ta alternatywa może naprawdę latać.
Ostatecznie nie jestem pewien, czy ta normalizacja jest właściwym podejściem, biorąc pod uwagę liczbę tabel i szanse na uzyskanie słabego planu wykonania lub wymagającego zbyt długiego czasu kompilacji. Prawdopodobnie najpierw poprawiłbym schemat zdenormalizowanej tabeli (odpowiednie typy danych itd.), ewentualnie zastosowałbym kompresję danych... zwykłe rzeczy.
Jeśli dane naprawdę należą do schematu gwiazdy, prawdopodobnie wymaga to więcej pracy projektowej niż tylko dzielenie powtarzających się elementów danych na osobne tabele.