Organizacja wydarzenia to dużo pracy! W tym artykule przyjrzymy się modelowi danych stojącemu za aplikacją do organizacji wydarzeń.
Jeśli kiedykolwiek próbowałeś zorganizować wydarzenie dla więcej niż dziesięciu osób (i nie liczmy tutaj przyjęć ani spotkań biznesowych), wiesz, jak skomplikowane może być zarządzanie wydarzeniem! Czy zaprosiliśmy wszystkich? Czy potwierdzili, czy przyjdą? Czy miejsce jest zarezerwowane i przygotowane? Kto poprowadzi wydarzenie? Kto weźmie udział w poszczególnych częściach? Jest wiele innych pytań, na które należy odpowiedzieć, a sprawy mogą łatwo pójść nie tak.
Możesz wszystko zaplanować za pomocą papieru i długopisu, ale dlaczego nie skorzystać z aplikacji? To wygodniejsze! Każda aplikacja będzie potrzebować miejsca do przechowywania wszystkich niezbędnych informacji o wydarzeniach. W tym miejscu w tę historię wkracza nasz model danych zarządzania zdarzeniami. Napij się kawy, usiądź na swoim ulubionym krześle, a my przyjrzymy się, jak zbudować model danych zarządzania zdarzeniami.
Najczęstsze pytania dotyczące zarządzania wydarzeniami
Zanim wyjaśnimy model i opiszemy, jak będziemy przechowywać dane, przyjrzyjmy się najpierw podstawom zarządzania zdarzeniami:
-
Co można uznać za wydarzenie?
W tym kontekście wydarzenie jest okazją, w której wiele osób, często nieznających się nawzajem, zbiera się, aby czegoś się dowiedzieć lub w czymś uczestniczyć. Niektóre popularne wydarzenia to festiwale muzyczne lub koncerty, konferencje IT, wydarzenia sportowe, takie jak mecze piłki nożnej, konferencje zdrowotne i medyczne itp.
-
Co mają wspólnego wszystkie wydarzenia?
Wspomniane wcześniej przykłady wydarzeń są bardzo różne pod względem treści, celu i grupy docelowej. Mimo to łączy ich wiele podobieństw, zwłaszcza w ich organizacji.
Najpierw rozważ treść wydarzenia. Niektóre wydarzenia (np. koncert czy mecz piłki nożnej) będą dostarczać tylko jednego rodzaju treści i odbywać się będą w jednym miejscu. Inne wydarzenia obejmują wiele różnych, ale powiązanych ze sobą „zdarzeń podrzędnych”, które mogą mieć miejsce w różnych miejscach.
Weźmy konferencję IT jako przykład drugiego rodzaju wydarzenia. Są wykłady, prezentacje, warsztaty i konkursy. Uczestnicy prawdopodobnie będą chodzić z pokoju do pokoju, a nawet podróżować między różnymi budynkami, przechodząc na różne wydarzenia podrzędne. Niektóre z tych zdarzeń podrzędnych będą działać w tym samym czasie, ale każde zdarzenie podrzędne nadal dotyczy działu IT i ma co najmniej jednego hosta.
-
Co jest potrzebne, aby wydarzenie zakończyło się sukcesem?
Przede wszystkim w tle ciężko pracuje personel miejsca wydarzenia:technicy audiowizualni, sprzedawcy biletów, woźni, pracownicy sprzątający i konserwatorzy oraz personel administracyjny. Wiele osób w wielu różnych rolach spędzi wiele godzin ciężko pracując, aby przygotować scenę dla „gwiazd” i innych uczestników, ale żaden z nich nie zdobędzie dużego uznania.
Oczywiście wszystkie wydarzenia wymagają jakiejś infrastruktury. Jeśli zorganizujemy konferencję w fizycznej lokalizacji, będziemy rozmawiać o salach i miejscach siedzących, nagłośnieniu, oświetleniu, może wideo itp. Nawet wydarzenie online, takie jak webinar, musi mieć miejsce na produkcję treści i Konfiguracja IT potrzebna do połączenia z wirtualnymi uczestnikami.
Imprezy zwykle mają sponsorów medialnych i partnerów, którzy pomagają w ich organizacji i promocji. Sponsorami tymi są głównie firmy i stowarzyszenia związane z tematyką wydarzenia; czasami są to inne firmy szukające dobrej reklamy; rzadziej osoba prywatna będzie pełnić rolę sponsora lub partnera.
-
Co to jest zarządzanie wydarzeniami?
Event management to proces służący do efektywnego zarządzania wydarzeniami i wszystkim, co z nimi związane. Można to uznać za rodzaj zarządzania projektami. W tym artykule omówiliśmy model danych zarządzania projektami. Używanie wykresu Gantta do pokazania postępu wydarzenia, aktualnego stanu i przyszłych działań nie jest złym pomysłem.
Jeśli to możliwe, prawdopodobnie będziemy chcieli, aby nasza aplikacja do zarządzania wydarzeniami mieściła się na jednym ekranie. Większość czynności – takich jak tworzenie nowego spektaklu, przypisywanie pracowników i zasobów do zadania lub szacowanie kosztów – należy przeciągać i upuszczać.
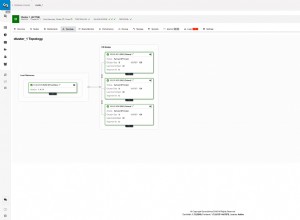
Model danych
Model danych składa się z trzech głównych obszarów tematycznych:
Events and PartnersShows, Performers and EquipmentEmployees
Przyjrzymy się bliżej każdemu obszarowi tematycznemu w kolejności, w jakiej są wymienione.
Sekcja 1:Wydarzenia i partnerzy
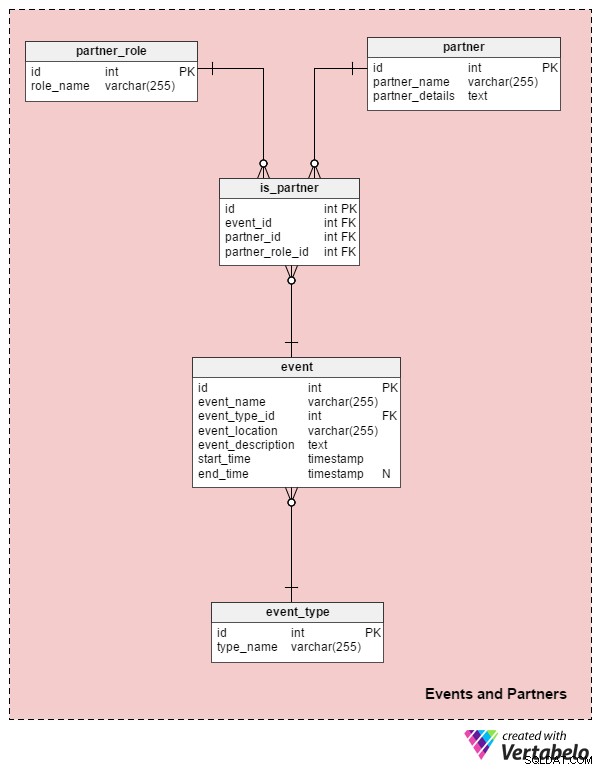
Events and Partners obszar tematyczny jest centralną częścią naszego modelu. W tych pięciu tabelach przechowujemy najważniejsze szczegóły dotyczące naszych wydarzeń. Będziemy również relacjonować wydarzenia z partnerami.
Zacznijmy od event stół. Zawiera listę wszystkich wydarzeń, które zorganizowaliśmy i każdego wydarzenia, które planujemy zorganizować. Atrybuty w tej tabeli to:
event_name– Nazwa wydarzenia. To nie jest UNIKATOWE, ponieważ możemy mieć dwa lub więcej wydarzeń o tej samej nazwie – np. koncert tego samego zespołu miałby taką samą nazwę wydarzenia. Jednakevent_name–start_timepara powinna być WYJĄTKOWA.event_type_id– Odwołuje się doevent_typesłownik.event_location– Opisuje lokalizację, w której odbędzie się wydarzenie. Użycie atrybutu opisowego pozwala nam uniknąć budowania bardziej złożonego modelu z tabelami takimi jak „kraj” i „miasto” oraz atrybutami takimi jak „adres” i „opis”.event_description– Szczegółowy opis wydarzenia i wszystkich pokazów lub działań z nim związanych. W przypadku koncertu przechowujemy informacje o akcie otwierającym, głównym akcie, wszelkich dodatkowych artystach i kolejności występów.start_time– Kiedy wydarzenie się rozpocznie. Jest to obowiązkowe, ponieważ powinniśmy o tym wiedzieć w fazie planowania.end_time– Kiedy wydarzenie się kończy. Możemy użyć tego atrybutu do przechowywania oczekiwanego lub rzeczywistego czasu zakończenia wydarzenia. Ponieważ możemy nie znać dokładnej godziny z góry (np. jeśli w meczu sportowym rozpoczyna się dogrywka), ten atrybut jest opcjonalny.
event_type słownik klasyfikuje zdarzenia, które obsługujemy. Będziemy przechowywać wszystkie możliwe typy wydarzeń zgodnie z ich niszą:koncert, mecz piłki nożnej, mecz koszykówki, konferencja IT itp. Każdy typ wydarzenia jest jednoznacznie zdefiniowany przez jego type_name .
Jak już wcześniej wspomnieliśmy, wydarzenia zazwyczaj mają partnerów. Większość wydarzeń będzie miała co najmniej partnera medialnego, podczas gdy niektóre będą miały również sponsorów i innych partnerów. Ten sam partner może mieć kilka różnych „roli partnerskich” na tym samym wydarzeniu. Na przykład nadawca telewizyjny może być jednocześnie partnerem medialnym i generalnym sponsorem wydarzenia. Dlatego użyjemy trzech tabel do powiązania wydarzeń z partnerami.
Ważne jest, aby móc dodawać partnerów w fazie planowania, aby wszyscy interesariusze wydarzeń mieli na czas dostęp do tych informacji. Ponadto możemy wykorzystać dane z przeszłości, gdy planujemy nowe wydarzenia – np. możemy skontaktować się z tym samym partnerem, gdy organizujemy wydarzenie cykliczne lub nowe wydarzenie tego samego typu. Jeśli firma była generalnym sponsorem konferencji technologicznej w zeszłym roku, może być zainteresowana zrobieniem tego ponownie w tym roku.
Przyjrzyjmy się teraz trzem tabelom partnerstwa. Pierwszy to partner katalog. Dla każdego partnera przechowujemy partner_name oraz ich adres, dane kontaktowe i inne partner_details . Zauważ, że partner_name atrybut nie jest unikalny. Możemy mieć dwóch partnerów o tej samej nazwie, na przykład dwie osoby prywatne o tym samym imieniu i nazwisku lub dwie firmy o tej samej nazwie firmy. W tym przypadku rozróżnimy je na podstawie informacji przechowywanych w partner_details atrybut.
Druga tabela to partner_role słownik, który zawiera listę wszystkich ról, jakie może pełnić partner. role_name atrybut będzie zawierał tylko wartości UNIQUE. Niektóre oczekiwane role to „partner medialny”, „sponsor generalny” i „sponsor”.
Ostatnia tabela w tym obszarze tematycznym dotyczy partnerów z wydarzeniami. is_partner tabela zawiera tylko klucze obce, które wiążą partnerów ze zdarzeniami i definiują role lub typy partnerstwa. Kombinacja tych kluczy obcych tworzy UNIKATOWY klucz tabeli. Gdybyśmy chcieli, moglibyśmy dodać datę rozpoczęcia i datę zakończenia na wypadek, gdyby jakiś partner wypełnił swoją rolę tylko dla części wydarzenia. Moglibyśmy również powiązać partnerów z pojedynczymi zdarzeniami podrzędnymi, a nie z całymi zdarzeniami. Mimo to są to stosunkowo rzadkie sytuacje, więc zostawimy tę część modelu bez zmian.
Sekcja 2:Pokazy, wykonawcy i sprzęt
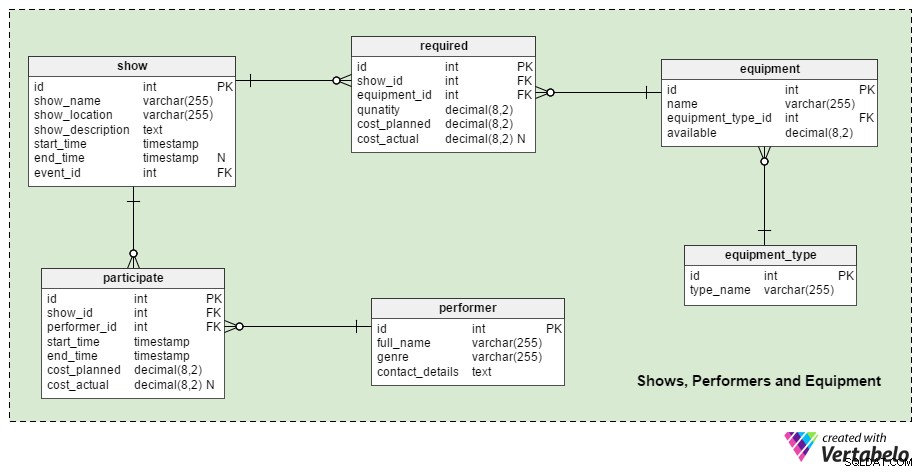
Jak wspomniano we wstępie, każde wydarzenie może mieć kilka wydarzeń podrzędnych. W tym modelu postanowiłem nazwać wydarzenia podrzędne „pokazami”. Pokaz jest pojedynczym wydarzeniem podrzędnym, skupionym na jednym temacie, z przynajmniej jednym wykonawcą itp. W przypadku konferencji IT jeden pokaz może być wykładem na temat zasad zarządzania projektami; innym pokazem może być panelowa dyskusja na temat najlepszych praktyk hurtowni danych. Oba mogą odbywać się w tym samym czasie, w różnych lokalizacjach i być prowadzone przez różnych prezenterów. Zdefiniujemy również wszystko, co jest potrzebne do uruchomienia pokazu, ponieważ pokaz musi trwać (w każdym razie ☺ ).
Centralną tabelą tej sekcji jest show stół. Pozwoli to na zapisanie wszelkich programów związanych z przeszłymi, obecnymi i przyszłymi wydarzeniami. Planując wydarzenie, musimy dodać nowe programy, gdy tylko wykonawca (tj. wykładowca, mówca, prezenter, gwiazda rocka) zgodzi się wziąć udział w wydarzeniu. Spojrzenie na opis atrybutów tabeli pomoże nam zrozumieć, jak to działa:
show_name– Nazwa programu.show_location– Opisuje, gdzie odbędzie się pokaz.show_description– Szczegółowy opis tego programu.start_time– Przewidywany czas rozpoczęcia.end_time– Oczekiwany czas zakończenia. Może być NULL, ponieważ możemy wprowadzić rzeczywisty czas zakończenia (po zakończeniu pokazu) zamiast oczekiwanego czasu zakończenia.event_id– Jakie wydarzenie jest częścią programu.
W większości przypadków pokazy będą wymagały sprzętu i wykonawców. (Teoretycznie moglibyśmy mieć pokaz bez wykonawcy, ale tutaj nie będziemy się tym zawracać.) Ponieważ sprzęt jest ograniczony, ważne jest, aby zarezerwować wszystko, co jest potrzebne w fazie planowania imprezy. Aby zrobić to właściwie, musimy wiedzieć, co się wydarzy w jakim czasie. Na przykład, jeśli mamy dwa projektory i dwa pokazy wymagające projektorów zaplanowanych na ten sam czas, nie możemy dodać trzeciego programu wymagającego projektora na ten czas, chyba że otrzymamy więcej sprzętu. To jest rodzaj informacji, które musimy mieć w fazie planowania.
Idąc dalej, mamy performer stół. Jest to prosty katalog wszystkich wykonawców, z którymi współpracowaliśmy lub będziemy pracować na dowolnym wydarzeniu. Dla każdego wykonawcy przechowamy jego full_name . Może to być nazwa zespołu, wykładowca itp. genre atrybutem jest tutaj wyróżnienie różnych typów wykonawców – m.in. zespoły rockowe od rzeźbiarzy. Ostatni atrybut w tej tabeli przechowuje contact_details wykonawców . Do przechowywania partii użyjemy typu danych tekstowych, ale możemy również podzielić dane kontaktowe na kilka oddzielnych pól.
Będziemy relacjonować pokazy i wykonawców za pośrednictwem participate stół. Atrybuty w tej tabeli to:
show_idiperformer_id– Nawiązania do powiązanego spektaklu i wykonawcy. Ta para może być alternatywnym (unikalnym) kluczem tabeli, ale postanowiłem jej nie używać; możemy mieć jednego wykonawcę, który będzie częścią tego samego programu w dwóch różnych momentach.start_timeiend_time– Dokładne czasy określające, kiedy wykonawca był częścią tego programu.cost_plannedicost_actual– Koszty/opłaty, które spodziewamy się zapłacić wykonawcy i ile im faktycznie zapłaciliśmy.
Pozostałe trzy tabele służą do zdefiniowania całego sprzętu potrzebnego do pokazu.
equipment_type słownik kategoryzuje sprzęt. W przypadku koncertu kategoriami tymi mogą być „sprzęt oświetleniowy”, „instrumenty muzyczne”, „konstrukcja sceniczna” itp. type_name atrybut zawiera tylko UNIKALNE wartości.
equipment tabela opisuje pozycje i ilości wyposażenia. Jego name atrybut definiuje sprzęt bardziej szczegółowo niż equipment_type .type_name . W przypadku kuli dyskotekowej jej wartością „sprzętu”.”nazwa” byłaby „kula dyskotekowa”, ale jej „typ_sprzętu”.”nazwa_typu” byłaby „sprzętem oświetleniowym”. available atrybut określa jaka ilość towaru jest dla nas dostępna. To liczba dziesiętna, ponieważ być może użyjemy pewnych „elementów”, których nie można zliczyć, takich jak woda i elektryczność.
Ostatnia tabela w tej sekcji dotyczy sprzętu i pokazów. Pomoże nam to zorganizować sprzęt w fazie planowania; umożliwia nam również późniejsze tworzenie raportów o kosztach sprzętu. Kiedy planujemy wykorzystanie sprzętu i koszty, informacje te mogą być bardzo przydatne, zwłaszcza w przypadku powtarzających się (lub bardzo podobnych) wydarzeń. Atrybuty w required tabela to:
show_idiequipment_id– Odnosi się do odpowiedniego pokazu i sprzętu. Ta para tworzy UNIKALNY klucz tabeli.quantity– Ilość potrzebnego sprzętu.cost_plannedicost_actual– ile spodziewamy się zapłacić za instalację lub wypożyczenie sprzętu i co faktycznie zapłaciliśmy.
Sekcja 3:Pracownicy
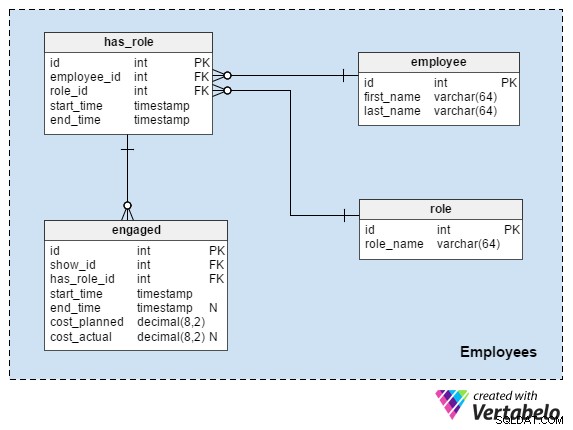
Tematyka tego modelu dotyczy pracowników i ich ról. Zawsze lubię podkreślać, że ludzie i ich czas są najważniejszą częścią każdego projektu. Wszystko inne jest tylko narzędziem do wykonania pracy. (I to narzędzie zostało również stworzone przez ludzi, wykorzystując swój czas. ☺ )
Nie wyjaśnię employee , role i has_role tabele tutaj. Robiłem to już wielokrotnie, na przykład w tym artykule. Jeśli potrzebujesz, przejrzyj to.
Ostatni stół w naszym modelu dotyczy pracowników i ról z pokazami. Możemy spodziewać się ograniczonej liczby wykwalifikowanych pracowników i musimy mieć pewność, że będą oni dostępni w razie potrzeby. Oczywiście ta sama osoba nie może być jednocześnie w dwóch różnych miejscach. Atrybuty w engaged tabela to:
show_idihas_role_id– Odwołuje się do powiązanego programu i roli pracownika.start_time– Kiedy oczekujemy, że pracownik rozpocznie tę rolę.end_time– Kiedy ta rola się skończy. Jest to wartość null, ponieważ w większości przypadków przypisujemy wartość po zakończeniu przez pracownika swojej roli. Możemy jednak wprowadzić tutaj oczekiwany czas zakończenia.cost_plannedicost_actual– Czego oczekujemy od pracownika za pełnienie tej roli i ile faktycznie zapłaciliśmy.
Jeszcze raz zaznaczę, że te dane historyczne mogą być bardzo pomocne, gdy organizujesz wydarzenie cykliczne lub podobne do wydarzenia z przeszłości.
Dzisiaj omówiliśmy możliwy model danych dla bazy danych zarządzania zdarzeniami. Omówiliśmy naprawdę ważne rzeczy, takie jak opisywanie wydarzenia, planowanie wykonawców oraz przypisywanie pracowników i zasobów do wydarzenia. Obsługa kosztów w tym modelu jest uproszczona, ale nadal daje nam możliwość kalkulacji planowanych i rzeczywistych kosztów według kategorii, wydarzenia, pokazu czy typu sprzętu.
Nie jestem organizatorem wydarzeń. Jeśli tak, mam nadzieję, że ten artykuł okazał się bardzo pomocny. Ale chciałbym usłyszeć Wasze opinie na temat tego, jakie dodatki lub zmiany mogą być przydatne w rzeczywistych sytuacjach.
Oczywiście każdy może zgłaszać swoje sugestie i pomysły w sekcji komentarzy.