Te testy (baza danych AdventureWorks2008R2) pokazują, co się dzieje:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Wyniki:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Wyniki z SET STATISTICS IO pokazuje, że LIO są takie same .Ale plany wykonania są zupełnie inne: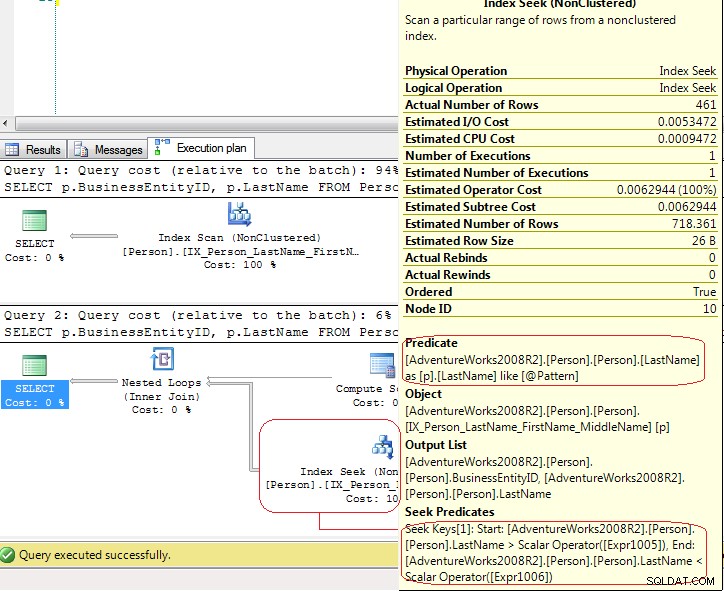
W pierwszym teście SQL Server używa Index Scan jawne, ale w drugim teście SQL Server używa Index Seek który jest Index Seek - range scan . W ostatnim przypadku SQL Server używa Compute Scalar operator do generowania tych wartości
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
i Index Seek operator używa Seek Predicate (zoptymalizowany) dla range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) plus inny niezoptymalizowany Predicate (LastName LIKE @pattern ).
Moja odpowiedź:to nie jest „prawdziwe” Index Seek . Jest to Index Seek - range scan który w tym przypadku ma taką samą wydajność jak Index Scan .
Zobacz także różnicę między Index Seek i Index Scan (podobna debata):Więc… czy to szukanie czy skanowanie?
.
Edytuj 1: Plan wykonania dla OPTION(RECOMPILE) (patrz rekomendacja Aarona) pokazuje również Index Scan (zamiast Index Seek ):