Kilka tygodni temu zacząłem konfigurować środowisko demonstracyjne z wieloma konfiguracjami grup dostępności AlwaysOn. Miałem 5-węzłowy klaster WSFC — każdy węzeł miał samodzielną nazwaną instancję SQL Server 2012, a na tych węzłach skonfigurowano również dwie instancje klastra pracy awaryjnej (FCI). Szybki diagram:
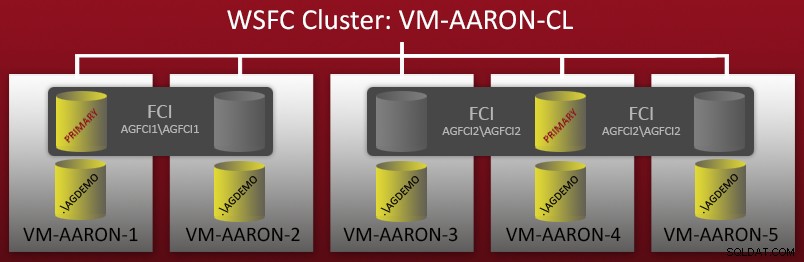
Widać więc, że istnieje 5 samodzielnych nazwanych instancji (.\AGDEMO na każdym węźle), a następnie dwa FCI – jeden z możliwymi właścicielami VM-AARON-1 i VM-AARON-2 (AGFCI1\AGFCI1 ), a następnie jeden z możliwymi właścicielami VM-AARON-3, VM-AARON-4 i VM-AARON-5 (AGFCI2\AGFCI2 ). Teraz ręczne tworzenie diagramów musiałoby być znacznie bardziej złożone (więcej o tym później), więc zamierzam tego uniknąć z oczywistych powodów. Zasadniczym wymaganiem było posiadanie wielu typów konfiguracji AG:
- Podstawowy w FCI z repliką w jednej lub kilku samodzielnych instancjach
- Podstawowy na FCI z repliką na innym FCI
- Główna w samodzielnej instancji z repliką w jednym lub więcej FCI
- Główna w samodzielnej instancji z repliką w co najmniej jednej samodzielnej instancji
- Główna w samodzielnej instancji z replikami zarówno w autonomicznych instancjach, jak i FCI
A następnie kombinacje (tam, gdzie to możliwe) zatwierdzania synchronicznego i asynchronicznego, ręcznego i automatycznego przełączania awaryjnego oraz plików pomocniczych tylko do odczytu. Istnieją pewne ograniczenia techniczne, które ograniczają możliwe tutaj permutacje, na przykład:
- Ręczne przełączanie awaryjne jest konieczne w przypadku każdej repliki znajdującej się w FCI
- Żaden węzeł WSFC nie może obsługiwać – ani nawet być potencjalnymi właścicielami – wielu wystąpień, zarówno samodzielnych, jak i klastrowych, które są zaangażowane w tę samą grupę dostępności. Pojawia się ten komunikat o błędzie:nie można utworzyć, dołączyć lub dodać repliki do grupy dostępności „MojaGrupa”, ponieważ węzeł „VM-AARON-1” jest możliwym właścicielem zarówno repliki „AGFCI1\AGFCI1”, jak i „VM-AARON-1\ AGDEMO”. Jeśli jedna replika jest instancją klastra pracy awaryjnej, usuń nakładający się węzeł od jego możliwych właścicieli i spróbuj ponownie. (Microsoft SQL Server, błąd:19405)
Większość scenariuszy, które próbowałem przedstawić, nie jest praktycznych w rzeczywistych scenariuszach, ale są one w dużej mierze i teoretycznie możliwe . Jeśli do tej pory nie zgadłeś, to środowisko jest konfigurowane w sposób jawny, aby przetestować nowe funkcje związane z grupami dostępności, które planujemy oferować w przyszłej wersji SQL Sentry. Rzuciliśmy okiem na niektóre z tych technologii podczas naszego przemówienia z Fusion-io na niedawnej konferencji SQL Intersection w Las Vegas.
Przeszkoda nr 1
Konfigurowanie grup dostępności za pomocą kreatora w SSMS jest dość łatwe. Chyba że na przykład masz heterogeniczne ścieżki plików. Kreator posiada weryfikację, która zapewnia, że we wszystkich replikach istnieją te same ścieżki danych i dzienników. Może to być uciążliwe, jeśli używasz domyślnej ścieżki danych dla dwóch różnych nazwanych wystąpień lub jeśli masz różne konfiguracje liter dysków (co często zdarza się, gdy zaangażowane są FCI).
Sprawdzanie zgodności lokalizacji pliku bazy danych w replice pomocniczej spowodowało błąd. (Microsoft.SqlServer.Management.HadrTasks)Następujące lokalizacje folderów nie istnieją w instancji serwera obsługującej replikę pomocniczą VM-AARON-1\AGDEMO:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Teraz powinno być oczywiste, że nie chcesz konfigurować tego scenariusza w żadnym środowisku, które musi wytrzymać próbę czasu. Sprawy potoczą się bardzo szybko, jeśli na przykład później dodasz nowy plik do jednej z baz danych. Ale w przypadku środowiska testowego/demo, dowodu koncepcji lub środowiska, które ma być stabilne przez dłuższy czas, nie martw się:nadal możesz to zrobić bez kreatora.
Niestety, aby dodać zniewagę do kontuzji, kreator nie pozwala ci tego napisać. Nie możesz przejść poza błąd walidacji i nie ma Script przycisk:
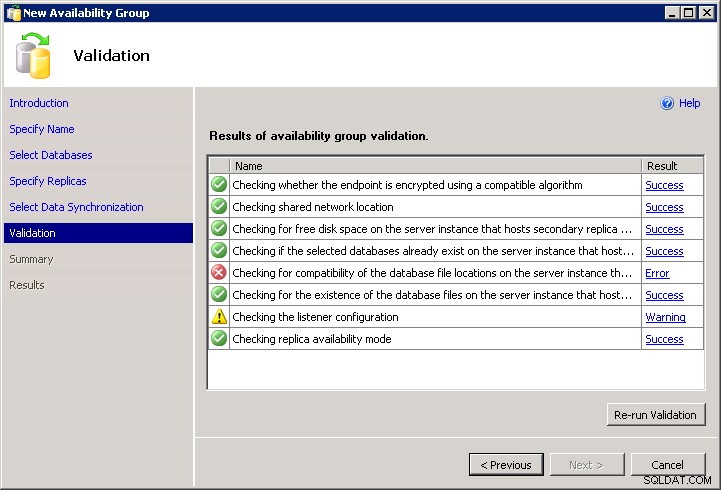
Oznacza to, że musisz sam go zakodować (ponieważ DDL nie wykonuje dla Ciebie żadnej „pomocnej” walidacji). Jeśli masz inne instancje, w których istnieją te same ścieżki, możesz to zrobić, postępując zgodnie z tym samym kreatorem, przechodząc przez ekran sprawdzania poprawności, a następnie klikając Script zamiast Finish i zmień nazwy serwerów i dodaj za pomocą WITH MOVE opcje do początkowego przywracania. Możesz też po prostu napisać własny od zera, coś takiego (skrypt zakłada, że masz już skonfigurowane punkty końcowe i uprawnienia, a wszystkie instancje mają włączoną funkcję Grupy dostępności):
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Przeszkoda #2
Jeśli masz wiele wystąpień na tym samym serwerze, może się okazać, że oba wystąpienia nie mogą współużytkować portu 5022 dla ich punktu końcowego dublowania bazy danych (który jest tym samym punktem końcowym, który jest używany przez grupy dostępności). Oznacza to, że będziesz musiał usunąć i ponownie utworzyć punkt końcowy, aby zamiast tego ustawić go na dostępny port.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);
Teraz mogę określić instancję z punktem końcowym na ServerName:5023 .
Przeszkoda #3
Jednak kiedy już to zrobiłem, kiedy doszedłem do ostatniego kroku w powyższym skrypcie, po dokładnie 48 sekundach – za każdym razem – otrzymywałem ten nieprzydatny komunikat o błędzie:
Msg 35250, poziom 16, stan 7, wiersz 2Połączenie z repliką podstawową nie jest aktywne. Nie można przetworzyć polecenia.
To sprawiło, że zacząłem ścigać wszelkiego rodzaju potencjalne problemy – na przykład sprawdzać zapory i SQL Server Configuration Manager pod kątem wszystkiego, co mogłoby blokować porty między instancjami. Nada. Znalazłem różne błędy w dzienniku błędów SQL Server:
Próba logowania dublowania bazy danych nie powiodła się z powodu błędu:„Uzgadnianie połączenia nie powiodło się. Nie ma kompatybilnego algorytmu szyfrowania. Stan 22.”.Próba logowania dublowania bazy danych nie powiodła się z powodu błędu:„Uzgadnianie połączenia nie powiodło się. Wywołanie systemu operacyjnego nie powiodło się:(80090303) 0x80090303 (określony cel jest nieznany lub nieosiągalny). Stan 66”.
Wystąpił limit czasu połączenia podczas próby nawiązania połączenia z repliką dostępności 'VM-AARON-1\AGDEMO' o identyfikatorze [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Albo występuje problem z siecią lub zaporą sieciową, albo adres punktu końcowego podany dla repliki nie jest punktem końcowym dublującym bazę danych instancji serwera hosta.
Okazuje się (i dzięki Thomasowi Stringerowi (@SQLife)), że przyczyną tego problemu była kombinacja symptomów:(a) Kerberos nie został poprawnie skonfigurowany, oraz (b) algorytm szyfrowania dla utworzonego przeze mnie hadr_endpoint jest domyślny do RC4. Byłoby w porządku, gdyby wszystkie samodzielne instancje również używały RC4, ale tak nie było. Krótko mówiąc, upuściłem i ponownie utworzyłem punkty końcowe ponownie , we wszystkich instancjach. Ponieważ było to środowisko laboratoryjne i tak naprawdę nie potrzebowałem wsparcia Kerberos (i ponieważ zainwestowałem już wystarczająco dużo czasu w te problemy, że nie chciałem też gonić problemów Kerberos), skonfigurowałem wszystkie punkty końcowe do korzystania z Negotiate z AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); ROLE =(Ted Krueger (@onpnt) ostatnio pisał na blogu o podobnym problemie.)
Teraz wreszcie mogłem tworzyć grupy dostępności ze wszystkimi różnymi wymaganiami, jakie miałem, między węzłami o heterogenicznych ścieżkach plików i wykorzystując wiele wystąpień w tym samym węźle (ale nie w tej samej grupie). Oto rzut oka na to, jak będzie wyglądał jeden z naszych widoków AlwaysOn Management (kliknij, aby powiększyć, aby uzyskać znacznie lepszy przegląd):
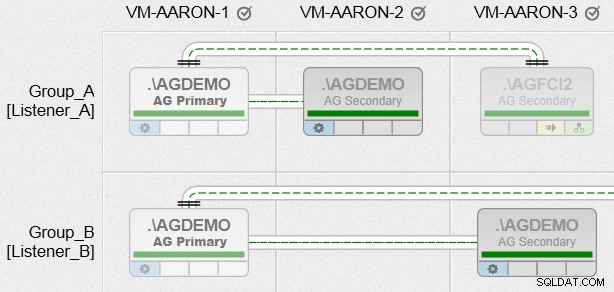
To tylko trochę droczenie i jest to w pełni zamierzone. W nadchodzących tygodniach będę blogować więcej o tej funkcji!
Wniosek
Kiedy spędzisz wystarczająco dużo czasu, patrząc na problem, możesz przeoczyć kilka dość oczywistych rzeczy. W tym przypadku pojawiły się oczywiste problemy ukryte przez niektóre wręcz nieintuicyjne komunikaty o błędach. Chcę podziękować Joe Sack (@JosephSack), Allanowi Hirtowi (@SQLHA) i Thomasowi Stringerowi (@SQLife) za porzucenie wszystkiego, aby pomóc potrzebującemu członkowi społeczności.