Benchmarki to jedna z czynności wykonywanych przez administratorów baz danych. Uruchamiasz je, aby zobaczyć, jak zachowuje się Twój sprzęt, uruchamiasz je, aby zobaczyć, jak Twoja aplikacja i baza danych współpracują ze sobą pod presją. Prowadzisz je w wielu różnych sytuacjach. Porozmawiajmy trochę o nich, jakie wyzwania masz przed sobą, jakich problemów powinieneś unikać.
Rodzaje testów porównawczych
Każdy test porównawczy jest inny. Służą one różnym celom i należy to wziąć pod uwagę planując jeden z nich. Ogólnie można zdefiniować dwa główne typy benchmarków:benchmark syntetyczny i, nazwijmy to, benchmark „w świecie rzeczywistym”.
Syntetyczne testy porównawcze to zazwyczaj narzędzia symulujące pewien rodzaj obciążenia. Może to być obciążenie OLTP, jak w przypadku Sysbench, może to być jakiś „standardowy” benchmark, jak w TPC-C lub TPC-H. Zwykle pomysł polega na tym, że taki test porównawczy symuluje jakieś obciążenie pracą i może być przydatny, jeśli obciążenie pracą w świecie rzeczywistym będzie przebiegać według tego samego wzorca. Można go również użyć do określenia, w jaki sposób połączenie konfiguracji sprzętu i bazy danych działa razem przy danym typie obciążenia. Zalety syntetycznych benchmarków są dość jasne. Możesz je uruchamiać wszędzie, nie zależą od konkretnej konfiguracji lub projektu schematu. Cóż, robią, ale wymyślają narzędzia do konfiguracji wszystkiego z pustego serwera bazy danych. Główną wadą jest to, że nie jest to twoje obciążenie pracą. Jeśli zamierzasz uruchamiać testy OLTP przy użyciu Sysbench, musisz pamiętać, że Twoja aplikacja nigdy nie będzie Sysbench. Może również uruchamiać obciążenie OLTP, ale kombinacja zapytań będzie inna. Nigdy, pod żadnym pozorem, syntetyczny benchmark nie powie dokładnie, jak Twoja aplikacja będzie się zachowywać na danym zestawie sprzętu/konfiguracji.
Na drugim końcu spektrum mamy tak zwane testy porównawcze z „rzeczywistego świata”. Rozumiemy przez to benchmark, który wykorzystuje zestaw danych i zapytania związane z Twoją aplikacją. Nie zawsze ma pełny zestaw danych i pełną mieszankę zapytań. Możesz skoncentrować się na niektórych częściach swojej aplikacji, ale głównym założeniem jest zrozumienie dokładnych interakcji między aplikacją, sprzętem i konfiguracją bazy danych, ogólnie lub w jakimś szczególnym aspekcie.
Jak wspomnieliśmy powyżej, mamy dwa główne, różne typy testów porównawczych, ale mimo to mają one kilka wspólnych rzeczy, które należy wziąć pod uwagę podczas próby uruchomienia testów.
-
Zdecyduj, co chcesz przetestować
Po pierwsze, benchmarking dla samego przeprowadzania benchmarków jest bezcelowy. Musi być zaprojektowany tak, aby coś osiągnąć. Co chcesz uzyskać z testu porównawczego? Czy chcesz dostroić zapytania? Czy chcesz poprawić konfigurację? Czy chcesz ocenić skalowalność swojego stosu? Chcesz przygotować stos na wyższy ładunek? Czy chcesz dokonać ogólnej modyfikacji konfiguracji dla nowego projektu? Czy chcesz określić najlepsze ustawienia dla swojego sprzętu? To są przykłady celów, które możesz chcieć osiągnąć. Każdy z nich będzie wymagał innego podejścia i innej konfiguracji testu porównawczego.
-
Wprowadzaj jedną zmianę na raz
Cokolwiek testujesz i modyfikujesz, niezwykle ważne jest, aby naraz dokonywać tylko jednej zmiany konfiguracji. To jest naprawdę krytyczne. Test porównawczy ma na celu dać pewne pojęcie o wydajności. Zapytania na sekundę, opóźnienie, 99 percentyl, wszystko to mówi Ci, jak szybko możesz wykonać zapytania oraz jak stabilne i przewidywalne jest obciążenie. Łatwo jest stwierdzić, czy zmiana dokonana w konfiguracji, sprzęcie lub zestawie zapytań cokolwiek zmieni:metryki z testu porównawczego będą wyglądać inaczej. Chodzi o to, że jeśli wprowadzisz kilka zmian jednocześnie, nie ma sposobu, aby stwierdzić, która z nich odpowiada za ogólny wynik. Może pójść nawet dalej. Załóżmy, że zmieniłeś dwie wartości w konfiguracji bazy danych. Wartość A i B. Ogólna poprawa wynosi 20%, co jest całkiem dobre przy zmianie konfiguracji. Jednak pod maską zmiana na wartość A przyniosła poprawę o 30%, podczas gdy dodatkowa zmiana na wartość B przywróciła ją do 20%. Przy wielu zmianach w tym samym czasie można zaobserwować tylko ich wspólny wpływ, nie jest to sposób na prawidłowe określenie wyniku każdej wprowadzonej zmiany. Jasne, to znacznie wydłuża czas, który spędzisz na przeprowadzaniu testu porównawczego, ale tak właśnie jest.
-
Wykonywanie wielu testów porównawczych
Komputery same w sobie są złożonymi systemami. Mają wiele komponentów, które współdziałają ze sobą:pamięć, procesor, dysk, sieć. Następnie dodajmy do tej wirtualizacji konteneryzację. Następnie oprogramowanie - system operacyjny, aplikacja, baza danych. Warstwa za warstwą za warstwą za warstwą elementów, które w jakiś sposób oddziałują. Nie jest łatwo przewidzieć jego zachowanie. Cóż, można powiedzieć, że precyzyjne przewidzenie zachowania tak złożonych systemów jest prawie niemożliwe. To jest powód, dla którego uruchomienie jednego testu nie wystarczy do wyciągnięcia wniosków. Co jeśli nieświadomie dla ciebie jakiś element, całkowicie niezwiązany z tym, co chcesz przetestować, wpływa na ogólną wydajność? Duże obciążenie innej maszyny wirtualnej znajdującej się na tym samym hoście. Jakiś inny serwer przesyła strumieniowo kopię zapasową przez sieć. Może to tymczasowo wpłynąć na wydajność i pochylić wyniki testu porównawczego. Jeśli wykonasz tylko jeden test porównawczy, otrzymasz nieprawidłowe wyniki. Dlatego najlepszą praktyką jest wykonanie kilku przebiegów testu porównawczego, a następnie usunięcie najwolniejszego i najszybszego, uśredniając pozostałe.
-
Obraz jest wart tysiące słów
Cóż, jest to bardzo dokładny opis benchmarkingu. Jeśli to tylko możliwe, zawsze generuj wykresy. W idealnym przypadku śledź metryki podczas testu porównawczego tak często, jak to możliwe. W większości przypadków powinna wystarczyć jedna sekunda ziarnistości. Aby uniknąć pisania tysięcy słów, uwzględnimy ten przykład. Jak myślisz, co jest bardziej przydatne? Ten zestaw wyników testów, które reprezentują średni QPS dla każdego z 10 przebiegów, każde przejście zajmuje 600 sekund
11650.52
11237.97
11550.16
11247.08
11177,78
11163,76
11131,47
11235.06
11235,59
11277.25
Lub ta fabuła:
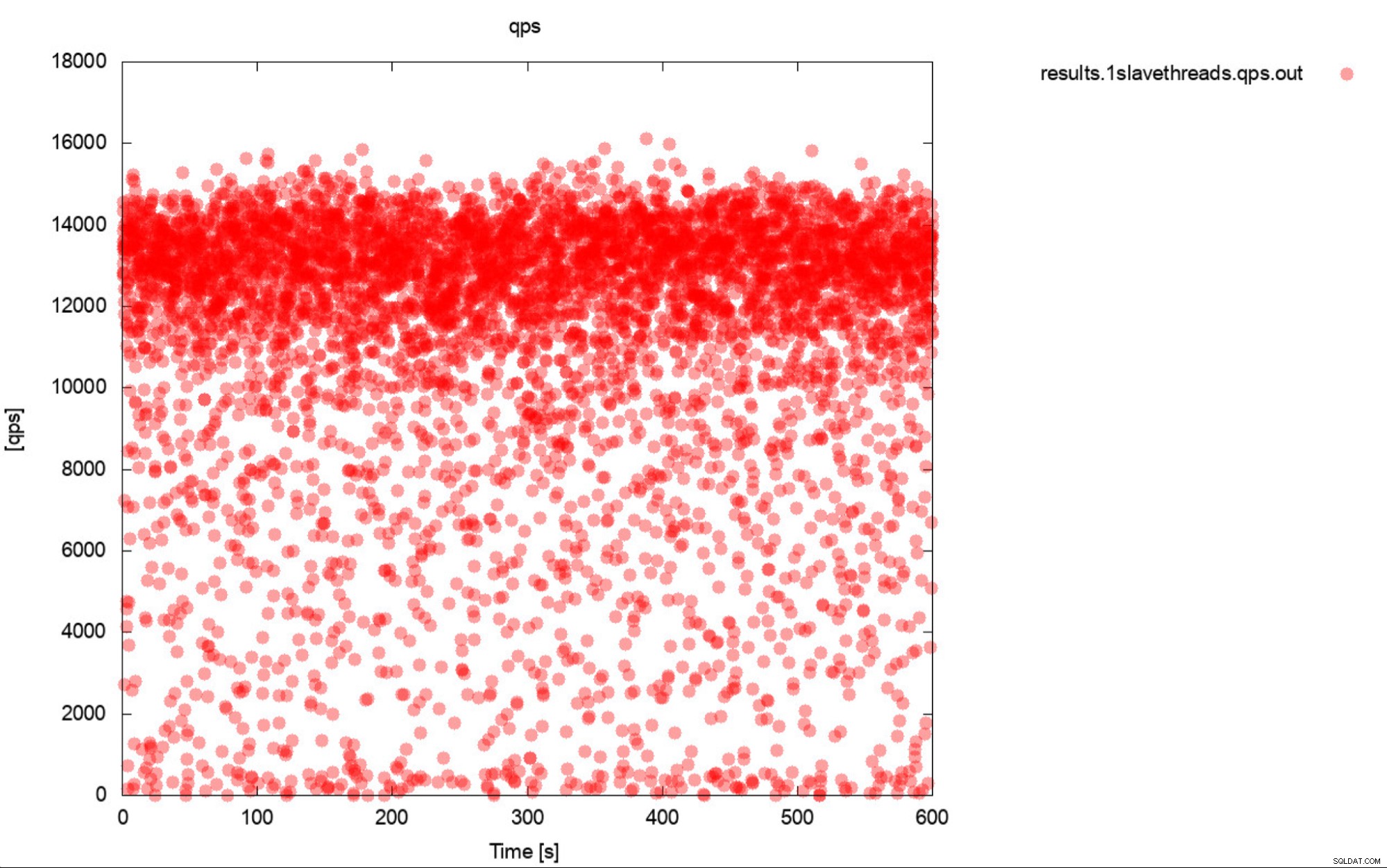
Średni QPS to 11 tys. miejsce, w tym spadki do 0 zapytań wykonywanych w ciągu sekundy, i jest to zdecydowanie coś, nad czym chcesz pracować i ulepszać systemy produkcyjne.
-
Zapytania na sekundę nie są najważniejszym wskaźnikiem
Możesz pomyśleć, że zapytanie na sekundę jest świętym Graalem wydajności, ponieważ reprezentuje liczbę zapytań, które baza danych może wykonać w ciągu jednej sekundy. Prawda jest taka, że nie jest to najważniejsza metryka, zwłaszcza jeśli mówimy o uśrednionym wyniku z benchmarku. QPS reprezentuje przepustowość, ale ignoruje opóźnienie. Możesz próbować wypchnąć dużą liczbę zapytań, ale w końcu czekasz, aż zwrócą wyniki. Nie tego użytkownicy oczekują od aplikacji. Użytkownicy oczekują stabilnej wydajności. To nie musi być błyskawiczne, ale gdy wykonanie jakiejś czynności zajmuje sekundę, zwykle oczekujemy, że wykonanie tej czynności zajmie zawsze tę 1 sekundę. Jeśli z jakiegoś powodu zaczyna to trwać dłużej, ludzie mają tendencję do niepokoju. Jest to główny powód, dla którego preferujemy opóźnienie, zwłaszcza jego P99 (99. percentyl) jako bardziej wiarygodną metrykę. Opóźnienie mówi nam, jak długo aplikacja musiała czekać na wynik z bazy danych. P99 mówi nam o opóźnieniu, że 99% zapytań ma mniej niż. Powiedzmy, że mamy P99 równy 100ms, co oznacza, że 99% zapytań zwraca wyniki nie wolniejsze niż 100ms. Jeśli widzimy niskie opóźnienie P99, oznacza to, że prawie wszystkie zapytania zwracają się szybko i działają w stabilny, przewidywalny sposób. To jest coś, co nasi użytkownicy chcą zobaczyć.
-
Zrozum, co się dzieje, zanim wyciągniesz wnioski
Ostatnia uwaga, którą mamy w tym krótkim blogu, ale powiedzielibyśmy, że jest najważniejsza. Podczas testów porównawczych zobaczysz różne dziwne i nieoczekiwane wyniki i zachowania. Co gorsza, możesz zobaczyć dość standardowe, powtarzalne, ale wciąż wadliwe wyniki. Większość z nich można śledzić po zachowaniu bazy danych lub sprzętu. Jest to naprawdę kluczowe – zanim uznasz wynik za pewnik, powinieneś być w stanie wyjaśnić zachowanie i opisać, co się stało. Wiemy, że nie jest to łatwe i wiemy, że naprawdę wymaga wiedzy specyficznej dla bazy danych, zwłaszcza wiedzy związanej z wewnętrznymi elementami bazy danych. Wiemy, że w prawdziwym świecie ludzie zazwyczaj nie przejmują się tym, chcą tylko uzyskać pewne wyniki. Chodzi o to, zwłaszcza w przypadkach, gdy próbujesz poprawić wydajność poprzez konfigurację lub poprawki sprzętowe, zrozumienie tego, co wydarzyło się pod maską, pozwala wybrać właściwy sposób, w jaki powinno przebiegać tuning. Pozwala również stwierdzić, czy wykonany benchmark może mieć sens. Czy rzeczywiście testujemy właściwy element? Przykładem może być test wykonywany przez sieć (ponieważ nie chcesz używać lokalnych rdzeni procesora węzła bazy danych do narzędzia porównawczego). Jest całkiem prawdopodobne, że sama sieć i obciążenie procesora softirq będą czynnikiem ograniczającym, znacznie wcześniej niż natrafisz na „oczekiwane” wąskie gardła, takie jak nasycenie procesora. Jeśli nie jesteś świadomy swojego środowiska i jego zachowania, będziesz mierzyć wydajność sieci w celu przesyłania dużych ilości danych, a nie wydajność procesora.
Jak widać, benchmarking nie jest najłatwiejszą rzeczą do zrobienia, musisz mieć pewien poziom świadomości tego, co się dzieje, powinieneś mieć odpowiedni plan tego, co zamierzasz zrobić i co chcesz przetestować? W następnej części tego bloga omówimy niektóre z rzeczywistych przypadków testowych. Co może się nie udać, jakie problemy napotkamy i jak sobie z nimi poradzić.