Ten wpis na blogu jest trzecią częścią serii blogów o indeksach w MySQL . W drugiej części serii wpisów na blogu dotyczących indeksów MySQL omówiliśmy indeksy i silniki pamięci masowej oraz poruszyliśmy niektóre kwestie związane z KLUCZEM PODSTAWOWYM. Dyskusja dotyczyła sposobu dopasowywania prefiksu kolumny, niektórych kwestii dotyczących indeksów FULLTEXT oraz sposobu używania indeksów B-Tree z symbolami wieloznacznymi i używania ClusterControl do monitorowania wydajności zapytań, a następnie indeksów.
W tym poście na blogu omówimy więcej szczegółów na temat indeksów w MySQL :omówimy indeksy haszowe, kardynalność indeksów, selektywność indeksów, opowiemy ciekawe szczegóły dotyczące indeksowania, a także omówimy kilka strategii indeksowania. I oczywiście dotkniemy ClusterControl. Zacznijmy, dobrze?
Indeksy haszujące w MySQL
Administratorzy baz danych MySQL i programiści zajmujący się MySQL również mają w zanadrzu jeszcze jedną sztuczkę, jeśli chodzi o MySQL - indeksy mieszające są również opcją. Indeksy haszujące są często używane w silniku MEMORY MySQL - podobnie jak prawie wszystko w MySQL, tego rodzaju indeksy mają swoje zalety i wady. Główną wadą tego rodzaju indeksów jest to, że są one używane tylko do porównywania równości, które używają operatorów =lub <=>, co oznacza, że nie są one naprawdę przydatne, jeśli chcesz wyszukać zakres wartości, ale główną zaletą jest że wyszukiwania są bardzo szybkie. Kilka innych wad to fakt, że programiści nie mogą używać żadnego lewego przedrostka klucza do znajdowania wierszy (jeśli chcesz to zrobić, użyj zamiast tego indeksów B-Tree), fakt, że MySQL nie może w przybliżeniu określić, ile jest wierszy między dwiema wartościami - jeśli używane są indeksy mieszające, optymalizator nie może również użyć indeksu mieszającego do przyspieszenia operacji ORDER BY. Pamiętaj, że indeksy mieszające to nie jedyna rzecz, którą obsługuje silnik MEMORY — silniki MEMORY mogą również mieć indeksy B-Tree.
Wielkość indeksu w MySQL
Jeśli chodzi o indeksy MySQL, być może słyszeliście również inny termin - ten termin nazywa się kardynalnością indeksu. Mówiąc bardzo prosto, kardynalność indeksu odnosi się do niepowtarzalności wartości przechowywanych w kolumnie, która korzysta z indeksu. Aby wyświetlić liczność indeksu określonego indeksu, możesz po prostu przejść do zakładki Struktura w phpMyAdmin i obserwować znajdujące się tam informacje lub wykonać zapytanie POKAŻ INDEKSY:
mysql> SHOW INDEXES FROM demo_table;
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| demo_table | 1 | demo | 1 | demo | A | 494573 | NULL | NULL | | BTREE | | |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)Wyjście zapytania SHOW INDEXES, które można zobaczyć powyżej, jak widać, zawiera wiele pól, z których jedno przedstawia liczność indeksu:to pole zwraca szacunkową liczbę unikalnych wartości w indeksie - im wyższa kardynalność, tym większa szansa, że optymalizator zapytań użyje indeksu do wyszukiwania. Mając to na uwadze, kardynalność indeksu ma również brata - nazywa się selektywność indeksu.
Selektywność indeksowania w MySQL
Selektywność indeksu to liczba odrębnych wartości w stosunku do liczby rekordów w tabeli. Mówiąc prościej, selektywność indeksu określa, jak ściśle indeks bazy danych pomaga MySQL zawęzić wyszukiwanie wartości. Idealna selektywność indeksu to wartość 1. Selektywność indeksu jest obliczana poprzez podzielenie odrębnych wartości w tabeli przez całkowitą liczbę rekordów, na przykład, jeśli w tabeli jest 1 000 000 rekordów, ale tylko 100 000 z nich to wartości odrębne , twoja selektywność indeksu wyniesie 0,1. Jeśli masz w tabeli 10 000 rekordów, a 8500 z nich to odrębne wartości, selektywność indeksu wyniesie 0,85. Tak jest dużo lepiej. Dostajesz punkt. Im wyższa selektywność indeksu, tym lepiej.
Pokrywanie indeksów w MySQL
Indeks pokrywający to specjalny rodzaj indeksu w InnoDB. Gdy używany jest indeks pokrywający, wszystkie wymagane pola dla zapytania są uwzględniane lub „pokrywane” przez indeks, co oznacza, że można również czerpać korzyści z odczytywania tylko indeksu zamiast danych. Jeśli nic więcej nie pomoże, indeks pokrycia może być biletem do poprawy wydajności. Niektóre z korzyści wynikających z używania indeksów pokrywających obejmują:
-
Jeden z głównych scenariuszy, w których indeks pokrywający może być przydatny, obejmuje obsługę zapytań bez dodatkowych odczytów we/wy na dużych stołach.
-
MySQL może również uzyskać dostęp do mniejszej ilości danych, ponieważ wpisy indeksu są mniejsze niż rozmiar wierszy.
-
Większość silników pamięci masowej buforuje indeksy lepiej niż dane.
Tworzenie indeksów pokrywających w tabeli jest dość proste — wystarczy pokryć pola dostępne za pomocą klauzul SELECT, WHERE i GROUP BY:
ALTER TABLE demo_table ADD INDEX index_name(column_1, column_2, column_3);Pamiętaj, że mając do czynienia z pokrywaniem indeksów, bardzo ważne jest, aby wybrać właściwą kolejność kolumn w indeksie. Aby indeksy pokrywające były skuteczne, najpierw umieść kolumny używane z klauzulą WHERE, następnie ORDER BY i GROUP BY, a na końcu kolumny używane z klauzulą SELECT.
Strategie indeksowania w MySQL
Zastosowanie się do rad zawartych w tych trzech częściach wpisów na blogu dotyczących indeksów w MySQL może zapewnić naprawdę dobrą podstawę, ale istnieje również kilka strategii indeksowania, które możesz chcieć zastosować, jeśli chcesz naprawdę wykorzystaj moc indeksów w swojej architekturze MySQL. Aby indeksy były zgodne z najlepszymi praktykami MySQL, rozważ:
-
Izolowanie kolumny, w której używasz indeksu - ogólnie MySQL nie używa indeksów, jeśli są używane na nie są izolowane. Na przykład takie zapytanie nie użyje indeksu, ponieważ nie jest izolowane:
SELECT demo_column FROM demo_table WHERE demo_id + 1 = 10;
Takie zapytanie jednak:
SELECT demo_column FROM demo_table WHERE demo_id = 10; -
Nie używaj indeksów w indeksowanych kolumnach. Na przykład użycie takiego zapytania nie przyniesie wiele dobrego, więc lepiej unikać takich zapytań, jeśli możesz:
SELECT demo_column FROM demo_table WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(column_date) <= 10; -
Jeśli używasz zapytań LIKE wraz z indeksowanymi kolumnami, unikaj umieszczania symbolu wieloznacznego na początku zapytania, ponieważ w ten sposób MySQL również nie będzie używał indeksu. To znaczy zamiast pisać takie zapytania:
SELECT * FROM demo_table WHERE demo_column LIKE ‘%search query%’;
Rozważ napisanie ich w ten sposób:SELECT * FROM demo_table WHERE demo_column LIKE ‘search_query%’;
Drugie zapytanie jest lepsze, ponieważ MySQL wie, od czego zaczyna się kolumna i może efektywniej wykorzystywać indeksy. Jak ze wszystkim, instrukcja EXPLAIN może być bardzo pomocna, jeśli chcesz się upewnić, że Twoje indeksy są rzeczywiście używane przez MySQL.
Korzystanie z ClusterControl do utrzymania wydajności zapytań
Jeśli chcesz poprawić wydajność MySQL, powyższe porady powinny skierować Cię na właściwą drogę. Jeśli czujesz, że potrzebujesz czegoś więcej, rozważ ClusterControl dla MySQL. Jedną z rzeczy, w których ClusterControl może pomóc, jest zarządzanie wydajnością — jak już wspomniano w poprzednich wpisach na blogu, ClusterControl może również pomóc w utrzymywaniu wydajności zapytań przez cały czas — to dlatego, że ClusterControl zawiera również zapytanie monitor, który pozwala monitorować wydajność zapytań, widzieć powolne, długotrwałe zapytania, a także wartości odstające zapytań, ostrzegające o możliwych wąskich gardłach w wydajności bazy danych, zanim będziesz mógł je zauważyć samodzielnie:
Możesz nawet filtrować zapytania, co pozwala na założenie, że indeks zostało użyte przez indywidualne zapytanie, czy nie:
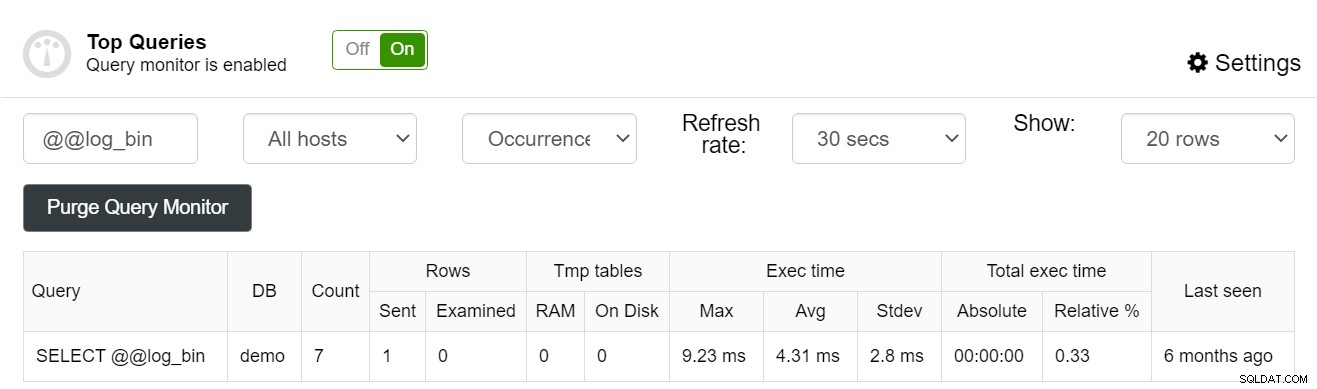
ClusterControl może być świetnym narzędziem do poprawy wydajności bazy danych, jednocześnie zdejmując z rąk kłopoty związane z konserwacją. Aby dowiedzieć się więcej o tym, co ClusterControl może zrobić, aby poprawić wydajność Twoich instancji MySQL, rozważ zajrzenie na stronę ClusterControl for MySQL.
Podsumowanie
Jak już zapewne wiesz, indeksy w MySQL to bardzo złożona bestia. Aby wybrać najlepszy indeks dla Twojej instancji MySQL, dowiedz się, czym są indeksy i co robią, poznaj typy indeksów MySQL, poznaj ich zalety i wady, dowiedz się, jak indeksy MySQL współdziałają z silnikami pamięci masowej, zajrzyj również do ClusterControl, aby uzyskać MySQL, jeśli uważasz, że automatyzacja niektórych zadań związanych z indeksami w MySQL może ułatwić Ci dzień.