W poprzednim wpisie na blogu omówiliśmy podstawy skalowania - co to jest, jakie są typy, co jest niezbędne, jeśli chcemy skalować. Ten post na blogu skupi się na wyzwaniach i sposobach skalowania.
Wyzwanie związane ze skalowaniem
Skalowanie baz danych nie jest najłatwiejszym zadaniem z wielu powodów. Skoncentrujmy się trochę na wyzwaniach związanych ze skalowaniem infrastruktury bazy danych.
Usługa stanowa
Możemy wyróżnić dwa różne typy usług:bezstanowe i stanowe. Usługi bezstanowe to te, które nie opierają się na żadnych istniejących danych. Możesz po prostu śmiało uruchomić taką usługę i szczęśliwie po prostu zadziała. Nie musisz się martwić o stan danych ani usługi. Jeśli tak się stanie, będzie działać poprawnie i możesz łatwo rozłożyć ruch na wiele instancji usług, dodając więcej klonów lub kopii istniejących maszyn wirtualnych, kontenerów lub podobnych. Przykładem takiej usługi może być aplikacja webowa - wdrożona z repozytorium, posiadająca odpowiednio skonfigurowany serwer sieciowy, taka usługa po prostu uruchomi się i będzie działać poprawnie.
Problem z bazami danych polega na tym, że baza danych jest całkowicie bezstanowa. Dane muszą być wprowadzone do bazy danych, muszą być przetwarzane i utrwalane. Obraz bazy danych to nic innego jak tylko kilka pakietów zainstalowanych na obrazie systemu operacyjnego i bez danych i odpowiedniej konfiguracji jest raczej bezużyteczny. Zwiększa to złożoność skalowania bazy danych. W przypadku usług bezstanowych wystarczy je wdrożyć i skonfigurować niektóre moduły równoważenia obciążenia, aby uwzględnić nowe instancje w obciążeniu. W przypadku baz danych wdrażających bazę danych instancja jest tylko punktem wyjścia. Dalej na torze jest zarządzanie danymi - musisz przenieść dane z istniejącej instancji bazy danych do nowej. Może to stanowić znaczną część problemu i czasu potrzebnego na rozpoczęcie obsługi ruchu przez nowe instancje. Dopiero po przeniesieniu danych możemy skonfigurować nowe węzły tak, aby stały się częścią istniejącej topologii replikacji - dane muszą być na nich aktualizowane w czasie rzeczywistym, na podstawie ruchu docierającego do innych węzłów.
Czas wymagany do skalowania
Fakt, że bazy danych są usługami stanowymi, jest bezpośrednim powodem drugiego wyzwania, przed którym stajemy, gdy chcemy skalować infrastrukturę bazy danych w górę. Usługi bezstanowe — po prostu je uruchamiasz i to wszystko. To dość szybki proces. W przypadku baz danych musisz przenieść dane. Jak długo to potrwa, zależy to od wielu czynników. Jak duży jest zestaw danych? Jak szybkie jest przechowywanie? Jak szybka jest sieć? Jakie są inne kroki wymagane do udostępnienia nowemu węzłowi świeżych danych? Czy dane są w tym procesie skompresowane/dekompresowane czy zaszyfrowane/odszyfrowane? W prawdziwym świecie udostępnienie danych w nowym węźle może zająć od kilku minut do kilku godzin. To poważnie ogranicza przypadki, w których można skalować środowisko bazy danych. Nagłe, tymczasowe skoki obciążenia? Niezupełnie, mogą już dawno zniknąć, zanim będzie można uruchomić dodatkowe węzły bazy danych. Nagły i stały wzrost obciążenia? Tak, będzie można sobie z tym poradzić poprzez dodanie większej liczby węzłów, ale uruchomienie ich i umożliwienie przejęcia ruchu z istniejących węzłów bazy danych może zająć nawet godziny.
Dodatkowe obciążenie spowodowane procesem skalowania
Bardzo ważne jest, aby pamiętać, że czas potrzebny na zwiększenie skali to tylko jedna strona problemu. Drugą stroną jest obciążenie spowodowane procesem skalowania. Jak wspomnieliśmy wcześniej, musisz przenieść cały zestaw danych do nowo dodanych węzłów. To nie jest coś, co można zignorować, w końcu może to być wielogodzinny proces odczytywania danych z dysku, przesyłania ich przez sieć i przechowywania w nowej lokalizacji. Jeśli dawca, czyli węzeł, z którego odczytujesz dane, jest przeciążony, musisz zastanowić się, jak będzie się zachowywał, gdyby został zmuszony do wykonania dodatkowej, ciężkiej aktywności I/O? Czy Twój klaster będzie w stanie przejąć dodatkowe obciążenie pracą, jeśli jest już pod dużą presją i jest rozłożony na cienkie? Odpowiedź może nie być łatwa do uzyskania, ponieważ obciążenie węzłów może przybierać różne formy. Obciążenie związane z procesorem będzie najlepszym scenariuszem, ponieważ aktywność we/wy powinna być niska, a dodatkowe operacje dyskowe będą możliwe do zarządzania. Z drugiej strony obciążenie związane z we/wy może znacznie spowolnić transfer danych, poważnie wpływając na zdolność klastra do skalowania.
Skalowanie zapisu
Wspomniany wcześniej proces skalowania w poziomie ogranicza się do skalowania odczytów. Najważniejsze jest, aby zrozumieć, że skalowanie zapisów to zupełnie inna historia. Możesz skalować odczyty, po prostu dodając więcej węzłów i rozkładając odczyty na więcej węzłów zaplecza. Pisma nie są tak łatwe do skalowania. Na początek nie można skalować tak po prostu zapisów. Każdy węzeł, który zawiera cały zestaw danych, jest oczywiście zobowiązany do obsługi wszystkich zapisów wykonywanych gdzieś w klastrze, ponieważ tylko stosując wszystkie modyfikacje zestawu danych, można zachować spójność. Jeśli więc o tym pomyślisz, bez względu na to, jak projektujesz klaster i jakiej technologii używasz, każdy element klastra musi wykonać każdy zapis. Niezależnie od tego, czy jest to replika, replikująca wszystkie zapisy ze swojego mastera lub węzła w klastrze z wieloma masterami, takim jak Galera lub InnoDB Cluster, wykonująca wszystkie zmiany w zestawie danych na wszystkich innych węzłach klastra, wynik jest taki sam. Zapisy nie skalują się po prostu przez dodanie większej liczby węzłów do klastra.
Jak możemy skalować bazę danych?
Więc wiemy, przed jakimi wyzwaniami stoimy. Jakie mamy opcje? Jak możemy przeskalować bazę danych?
Dodając repliki
Przede wszystkim będziemy skalować po prostu dodając więcej węzłów. Jasne, zajmie to trochę czasu i na pewno nie jest to proces, którego można oczekiwać natychmiast. Jasne, nie będziesz w stanie skalować zapisów w ten sposób. Z drugiej strony, najbardziej typowym problemem, z jakim będziesz się zmagać, jest obciążenie procesora spowodowane zapytaniami SELECT i, jak wspomnieliśmy, odczyty można po prostu skalować, dodając więcej węzłów do klastra. Więcej węzłów do odczytania oznacza zmniejszenie obciążenia każdego z nich. Kiedy jesteś na początku swojej podróży w cykl życia swojej aplikacji, załóż po prostu, że właśnie z tym będziesz miał do czynienia. Obciążenie procesora, a nie wydajne zapytania. Jest bardzo mało prawdopodobne, że będziesz musiał skalować zapisy do dalszej części cyklu życia, kiedy Twoja aplikacja już dojrzała i musisz poradzić sobie z liczbą klientów.
Przez fragmentowanie
Dodanie węzłów nie rozwiąże problemu z zapisem, to właśnie ustaliliśmy. Zamiast tego musisz sharding — podzielić zestaw danych w klastrze. W tym przypadku każdy węzeł zawiera tylko część danych, a nie wszystko. To pozwala nam wreszcie rozpocząć skalowanie zapisów. Załóżmy, że mamy cztery węzły, z których każdy zawiera połowę zbioru danych.
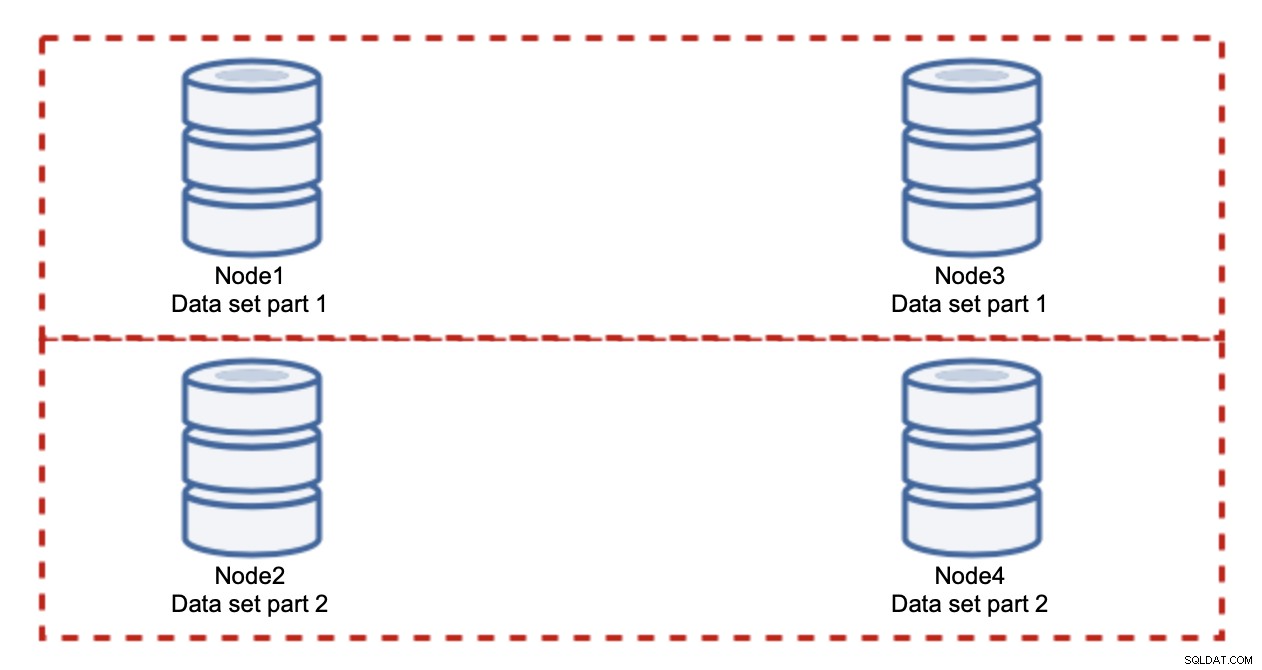
Jak widać, pomysł jest prosty. Jeśli zapis dotyczy części 1 zbioru danych, zostanie wykonany na węźle 1 i węźle 3. Jeśli jest to związane z częścią 2 zbioru danych, zostanie wykonane na węźle2 i węźle4. Możesz myśleć o węzłach bazy danych jak o dyskach w macierzy RAID. Tutaj mamy przykład RAID10, dwie pary luster dla redundancji. W rzeczywistym wdrożeniu może to być bardziej złożone, możesz mieć więcej niż jedną replikę danych w celu poprawy wysokiej dostępności. Istota jest taka, zakładając idealnie sprawiedliwy podział danych, połowa zapisów trafi w węzły 1 i 3, a druga połowa w węzły 2 i 4. Jeśli chcesz jeszcze bardziej podzielić obciążenie, możesz wprowadzić trzecią parę węzłów:
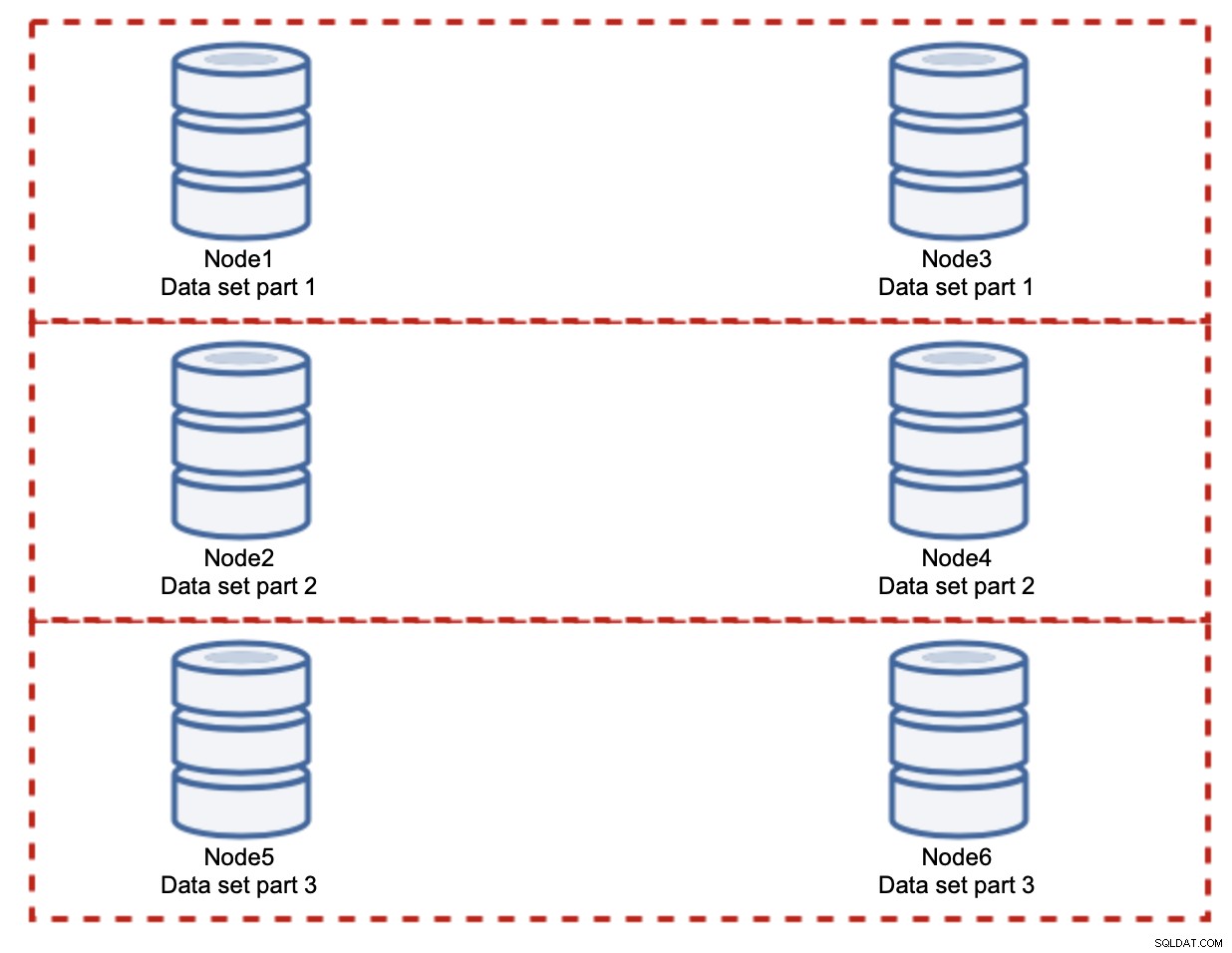
W tym przypadku ponownie, zakładając idealnie sprawiedliwy podział, każda para odpowiadać za 33% wszystkich zapisów w klastrze.
To właściwie podsumowuje ideę shardingu. W naszym przykładzie, dodając więcej fragmentów, możemy zmniejszyć aktywność zapisu w węzłach bazy danych do 33% pierwotnego obciążenia we/wy. Jak możesz sobie wyobrazić, nie jest to pozbawione wad.
Jak znajdę fragment, na którym znajdują się moje dane? Szczegóły są poza zakresem tego wywołania, ale w skrócie, możesz albo zaimplementować jakąś funkcję w danej kolumnie (modulo lub hash w kolumnie „id”), albo możesz zbudować oddzielną metabazę, w której będziesz przechowywać szczegóły sposobu dystrybucji danych.
Mamy nadzieję, że ta krótka seria blogów okazała się dla Ciebie pouczająca i że lepiej zrozumiałeś różne wyzwania, przed którymi stoimy, gdy chcemy skalować środowisko bazy danych. Jeśli masz jakieś uwagi lub sugestie na ten temat, możesz skomentować pod tym postem i podzielić się swoimi doświadczeniami