Wdrażanie klastra baz danych nie jest nauką rakietową — istnieje wiele porad, jak to zrobić. Ale skąd wiesz, że to, co właśnie wdrożyłeś, jest gotowe do produkcji? Wdrożenia ręczne mogą być również żmudne i powtarzalne. W zależności od liczby węzłów w klastrze kroki wdrażania mogą być czasochłonne i podatne na błędy. Narzędzia do zarządzania konfiguracją, takie jak Puppet, Chef i Ansible, są popularne we wdrażaniu infrastruktury, ale w przypadku klastrów stanowych baz danych należy wykonać znaczące skrypty, aby obsłużyć wdrożenie całego stosu HA bazy danych. Co więcej, wybrany szablon/moduł/książka kucharska/rola musi zostać skrupulatnie przetestowany, zanim będzie można mu zaufać w ramach automatyzacji infrastruktury. Zmiany wersji wymagają aktualizacji i ponownego przetestowania skryptów.
Dobrą wiadomością jest to, że ClusterControl automatyzuje wdrożenia całego stosu - i to również za darmo! Wdrożyliśmy tysiące klastrów produkcyjnych i podejmujemy szereg środków ostrożności, aby zapewnić ich gotowość do produkcji Obsługiwane są różne topologie, od replikacji typu master-slave po klastry Galera, NDB i InnoDB, z różnymi serwerami proxy baz danych na górze.
Stos wysokiej dostępności, wdrażany za pośrednictwem ClusterControl, składa się z trzech warstw:
- Warstwa bazy danych (np. Galera Cluster)
- Odwrócona warstwa proxy (np. HAProxy lub ProxySQL)
- Warstwa utrzymywana, która przy użyciu Wirtualnego IP zapewnia wysoką dostępność warstwy proxy
W tym blogu pokażemy, jak wdrożyć klaster Galera klasy produkcyjnej wraz z modułami równoważenia obciążenia na potrzeby konfiguracji wysokiej dostępności. Kompletna konfiguracja składa się z 6 hostów:
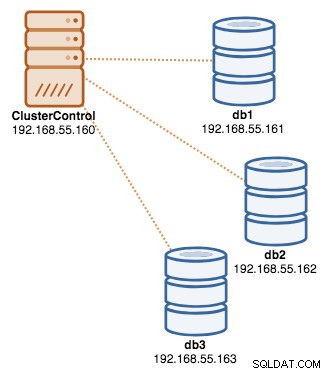
- 1 host — ClusterControl (wdrażanie, monitorowanie, serwer zarządzania)
- 3 hosty — klaster MySQL Galera
- 2 hosty — odwrotne serwery proxy działają jako systemy równoważenia obciążenia przed klastrem.
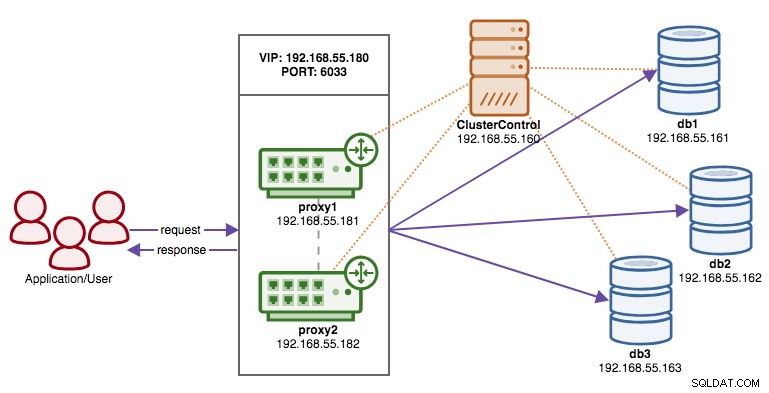
Poniższy diagram ilustruje nasz wynik końcowy po zakończeniu wdrażania:
Wymagania wstępne
ClusterControl musi znajdować się w niezależnym węźle, który nie jest częścią klastra. Pobierz ClusterControl, a strona wygeneruje unikatową licencję i pokaże kroki instalacji ClusterControl:
$ wget -O install-cc https://severalnines.com/scripts/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userPostępuj zgodnie z instrukcjami, które pomogą Ci skonfigurować serwer MySQL, hasło roota MySQL w węźle ClusterControl, hasło cmon do użycia ClusterControl i tak dalej. Po zakończeniu instalacji powinien pojawić się następujący wiersz:
Determining network interfaces. This may take a couple of minutes. Do NOT press any key.
Public/external IP => https://{public_IP}/clustercontrol
Installation successful. If you want to uninstall ClusterControl then run install-cc --uninstall.Następnie na serwerze ClusterControl wygeneruj klucz SSH, którego użyjemy do późniejszej konfiguracji bezhasłowego SSH. Możesz użyć dowolnego użytkownika w systemie, ale musi on mieć możliwość wykonywania operacji superużytkownika (sudoer). W tym przykładzie wybraliśmy użytkownika root:
$ whoami
root
$ ssh-keygen -t rsaSkonfiguruj bezhasłowe SSH dla wszystkich węzłów, które chcesz monitorować/zarządzać za pomocą ClusterControl. W tym przypadku ustawimy to na wszystkich węzłach w stosie (w tym na samym węźle ClusterControl). W węźle ClusterControl uruchom następujące polecenia i po wyświetleniu monitu podaj hasło roota:
$ ssh-copy-id example@sqldat.com # clustercontrol
$ ssh-copy-id example@sqldat.com # galera1
$ ssh-copy-id example@sqldat.com # galera2
$ ssh-copy-id example@sqldat.com # galera3
$ ssh-copy-id example@sqldat.com # proxy1
$ ssh-copy-id example@sqldat.com # proxy2Następnie możesz sprawdzić, czy działa, uruchamiając następujące polecenie w węźle ClusterControl:
$ ssh example@sqldat.com "ls /root"Upewnij się, że możesz zobaczyć wynik powyższego polecenia bez konieczności wpisywania hasła.
Wdrażanie klastra
ClusterControl obsługuje wszystkich dostawców Galera Cluster (Codership, Percona i MariaDB). Istnieje kilka drobnych różnic, które mogą wpłynąć na Twoją decyzję o wyborze dostawcy. Jeśli chcesz poznać różnice między nimi, zapoznaj się z naszym poprzednim wpisem na blogu – Porównanie klastrów Galera – Codership vs Percona vs MariaDB.
W przypadku wdrożenia produkcyjnego trzywęzłowy klaster Galera to minimum, które powinieneś mieć. Zawsze możesz go skalować później po wdrożeniu klastra, ręcznie lub za pomocą ClusterControl. Otworzymy nasz interfejs ClusterControl pod adresem https://192.168.55.160/clustercontrol i utworzymy pierwszego administratora. Następnie przejdź do górnego menu i kliknij Wdróż -> MySQL Galera i pojawi się następujące okno dialogowe:
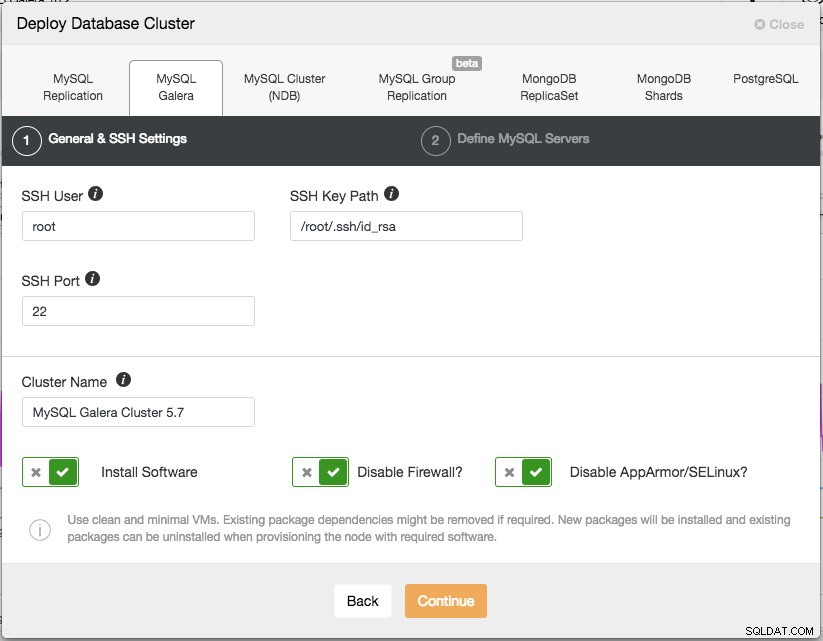
Istnieją dwa kroki, pierwszy to „Ustawienia ogólne i SSH”. Tutaj musimy skonfigurować użytkownika SSH, którego ClusterControl powinien używać do łączenia się z węzłami bazy danych, wraz ze ścieżką do klucza SSH (wygenerowaną w sekcji Wymagania wstępne) oraz portem SSH węzłów bazy danych. ClusterControl zakłada, że wszystkie węzły bazy danych są skonfigurowane z tym samym użytkownikiem SSH, kluczem i portem. Następnie nadaj klastrowi nazwę, w tym przypadku użyjemy „MySQL Galera Cluster 5.7”. Wartość tę można później zmienić. Następnie wybierz opcje, aby poinstruować ClusterControl, aby zainstalował wymagane oprogramowanie, wyłączył zaporę, a także wyłączył moduł zwiększający bezpieczeństwo w określonej dystrybucji systemu Linux. Zaleca się, aby wszystkie te elementy były włączone, aby zmaksymalizować potencjał udanego wdrożenia.
Kliknij Kontynuuj, a wyświetli się następujące okno dialogowe:
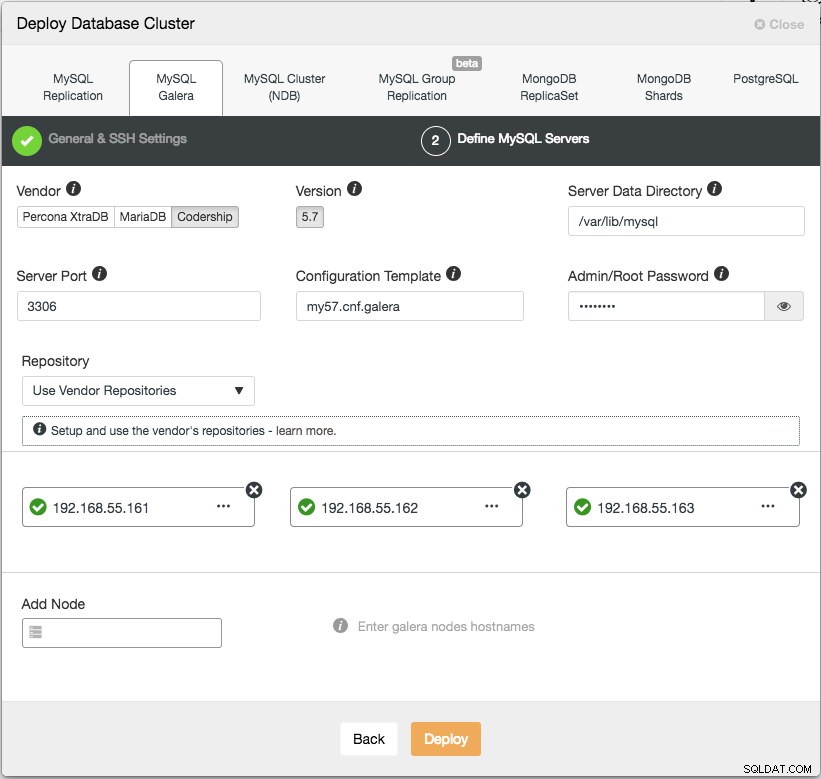
W następnym kroku musimy skonfigurować serwery bazy danych - producenta, wersję, katalog danych, port itp. - które są dość oczywiste. „Szablon konfiguracji” to nazwa pliku szablonu w /usr/share/cmon/templates węzła ClusterControl. „Repozytorium” to sposób, w jaki ClusterControl powinien konfigurować repozytorium w węźle bazy danych. Domyślnie użyje repozytorium dostawcy i zainstaluje najnowszą wersję dostarczoną przez repozytorium. Jednak w niektórych przypadkach użytkownik może mieć kopię lustrzaną istniejącego repozytorium z oryginalnego repozytorium ze względu na ograniczenia polityki bezpieczeństwa. Niemniej jednak ClusterControl obsługuje większość z nich, jak opisano w podręczniku użytkownika w sekcji Repozytorium.
Na koniec dodaj adres IP lub nazwę hosta (musi być prawidłową nazwą FQDN) węzłów bazy danych. Zobaczysz zieloną ikonę zaznaczenia po lewej stronie węzła, co oznacza, że ClusterControl mógł połączyć się z węzłem przez SSH bez hasła. Teraz możesz już iść. Kliknij Wdróż, aby rozpocząć wdrażanie. Może to potrwać od 15 do 20 minut. Postęp wdrażania możesz monitorować w sekcji Aktywność (górne menu) -> Zadania -> Utwórz klaster :
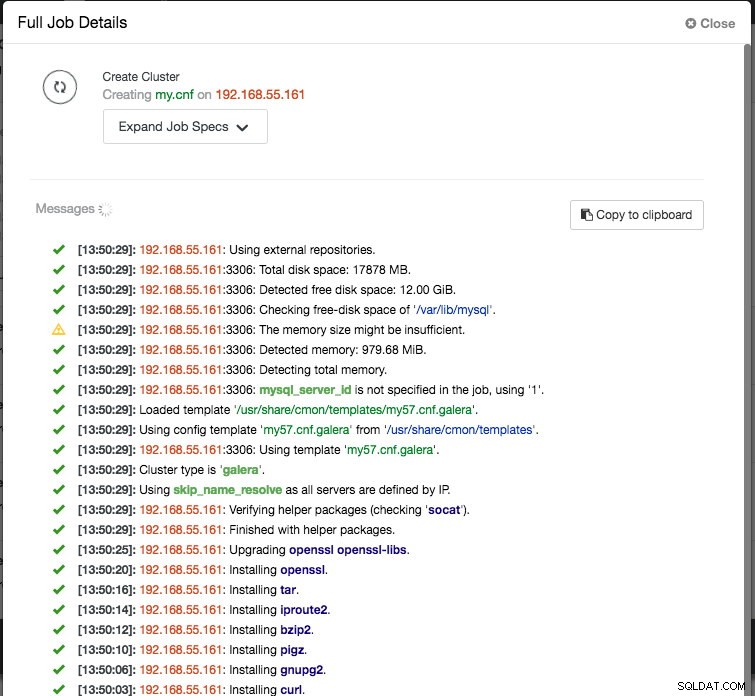
Po zakończeniu wdrożenia w tym momencie naszą architekturę można zilustrować w następujący sposób:
Wdrażanie systemów równoważenia obciążenia
W Galera Cluster wszystkie węzły są równe - każdy węzeł pełni tę samą rolę i ten sam zestaw danych. Dlatego nie ma przełączania awaryjnego w klastrze, jeśli węzeł ulegnie awarii. Tylko strona aplikacji wymaga przełączenia awaryjnego, aby pominąć niedziałające węzły podczas partycjonowania klastra. Dlatego zdecydowanie zaleca się umieszczenie systemów równoważenia obciążenia na szczycie klastra Galera, aby:
- Ujednolicenie wielu punktów końcowych bazy danych z jednym punktem końcowym (host systemu równoważenia obciążenia lub wirtualny adres IP jako punkt końcowy).
- Zrównoważ połączenia bazy danych między serwerami baz danych zaplecza.
- Przeprowadzaj kontrole stanu i przesyłaj połączenia z bazą danych tylko do zdrowych węzłów.
- Przekieruj/przepisz/blokuj obraźliwe (źle napisane) zapytania, zanim trafią na serwery baz danych.
Istnieją trzy główne opcje odwrotnych serwerów proxy dla Galera Cluster — HAProxy, MariaDB MaxScale lub ProxySQL — wszystkie mogą być instalowane i konfigurowane automatycznie przez ClusterControl. W tym wdrożeniu wybraliśmy ProxySQL, ponieważ sprawdza wszystkie powyższe oraz rozumie protokół MySQL serwerów zaplecza.
W tej architekturze chcemy użyć dwóch serwerów ProxySQL, aby wyeliminować wszelkie pojedyncze punkty awarii (SPOF) w warstwie bazy danych, które będą powiązane ze sobą za pomocą zmiennego wirtualnego adresu IP. Wyjaśnimy to w następnej sekcji. Jeden węzeł będzie działał jako aktywny serwer proxy, a drugi jako hot-standby. Węzeł, który w danym momencie przechowuje wirtualny adres IP, jest węzłem aktywnym.
Aby wdrożyć pierwszy serwer ProxySQL, po prostu przejdź do menu akcji klastra (po prawej stronie paska podsumowania) i kliknij Dodaj Load Balancer -> ProxySQL -> Wdróż ProxySQL a zobaczysz następujące:
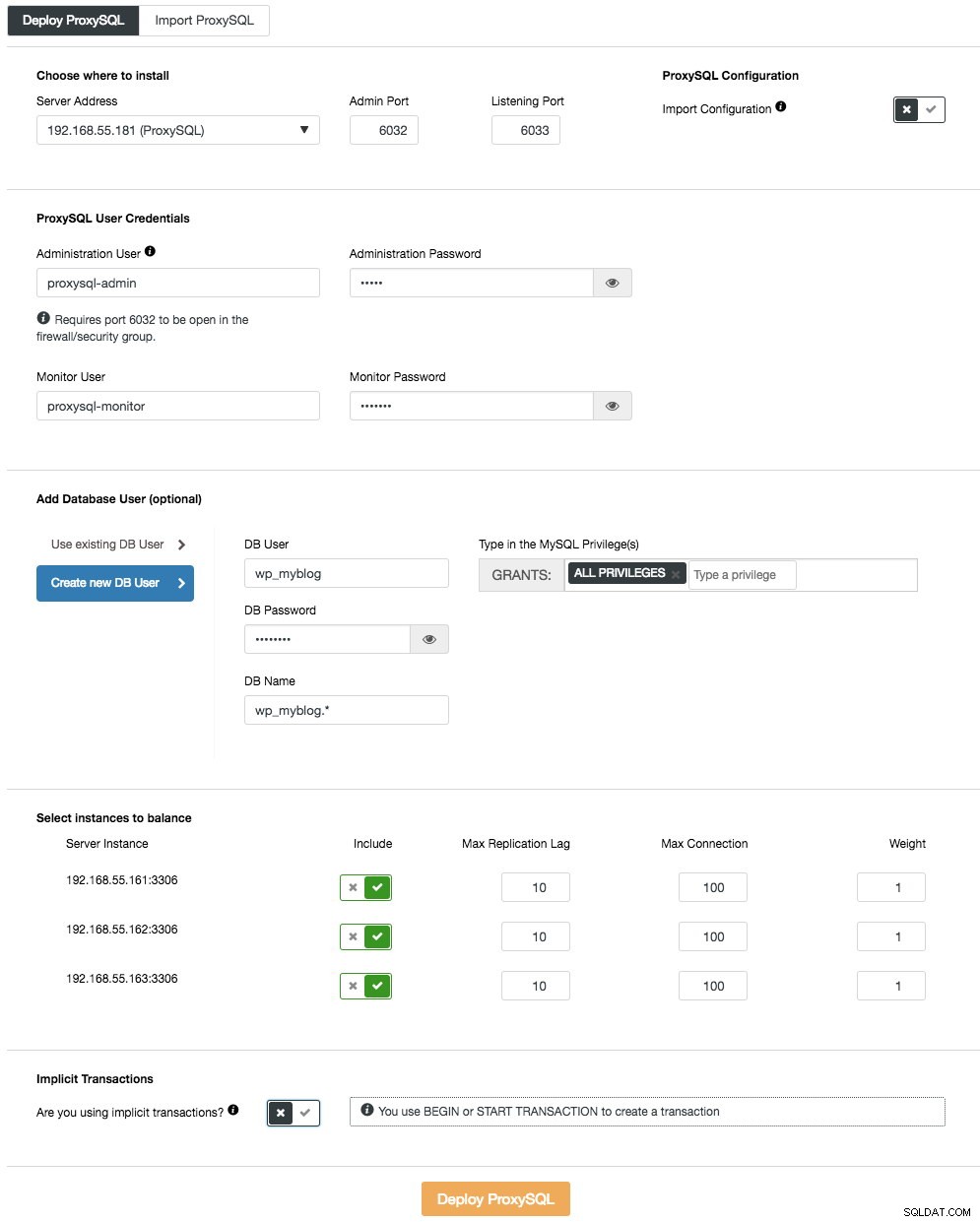
Ponownie, większość pól nie wymaga wyjaśnień. W sekcji „Użytkownik bazy danych” ProxySQL działa jako brama, przez którą Twoja aplikacja łączy się z bazą danych. Aplikacja uwierzytelnia się w ProxySQL, dlatego musisz dodać wszystkich użytkowników ze wszystkich węzłów MySQL zaplecza wraz z ich hasłami do ProxySQL. W ClusterControl możesz utworzyć nowego użytkownika do użycia przez aplikację - możesz zdecydować o jego nazwie, haśle, dostępie do jakich baz danych oraz jakie uprawnienia MySQL będzie miał ten użytkownik. Taki użytkownik zostanie utworzony zarówno po stronie MySQL, jak i ProxySQL. Drugą opcją, bardziej odpowiednią dla istniejącej infrastruktury, jest wykorzystanie istniejących użytkowników baz danych. Musisz podać nazwę użytkownika i hasło, a taki użytkownik zostanie utworzony tylko w ProxySQL.
Ostatnia sekcja, „Niejawna transakcja”, ClusterControl skonfiguruje ProxySQL, aby wysyłał cały ruch do mastera, jeśli rozpoczęliśmy transakcję z SET autocommit=0. W przeciwnym razie, jeśli użyjesz opcji ROZPOCZNIJ lub ROZPOCZNIJ TRANSAKCJĘ do utworzenia transakcji, ClusterControl skonfiguruje podział odczytu/zapisu w regułach zapytania. Ma to na celu zapewnienie, że ProxySQL będzie poprawnie obsługiwał transakcje. Jeśli nie masz pojęcia, jak robi to Twoja aplikacja, możesz wybrać to drugie.
Powtórz tę samą konfigurację dla drugiego węzła ProxySQL, z wyjątkiem wartości „Server Address”, która wynosi 192.168.55.182. Po zakończeniu oba węzły zostaną wyświetlone w zakładce „Węzły” -> ProxySQL, gdzie można je monitorować i zarządzać nimi bezpośrednio z interfejsu użytkownika:
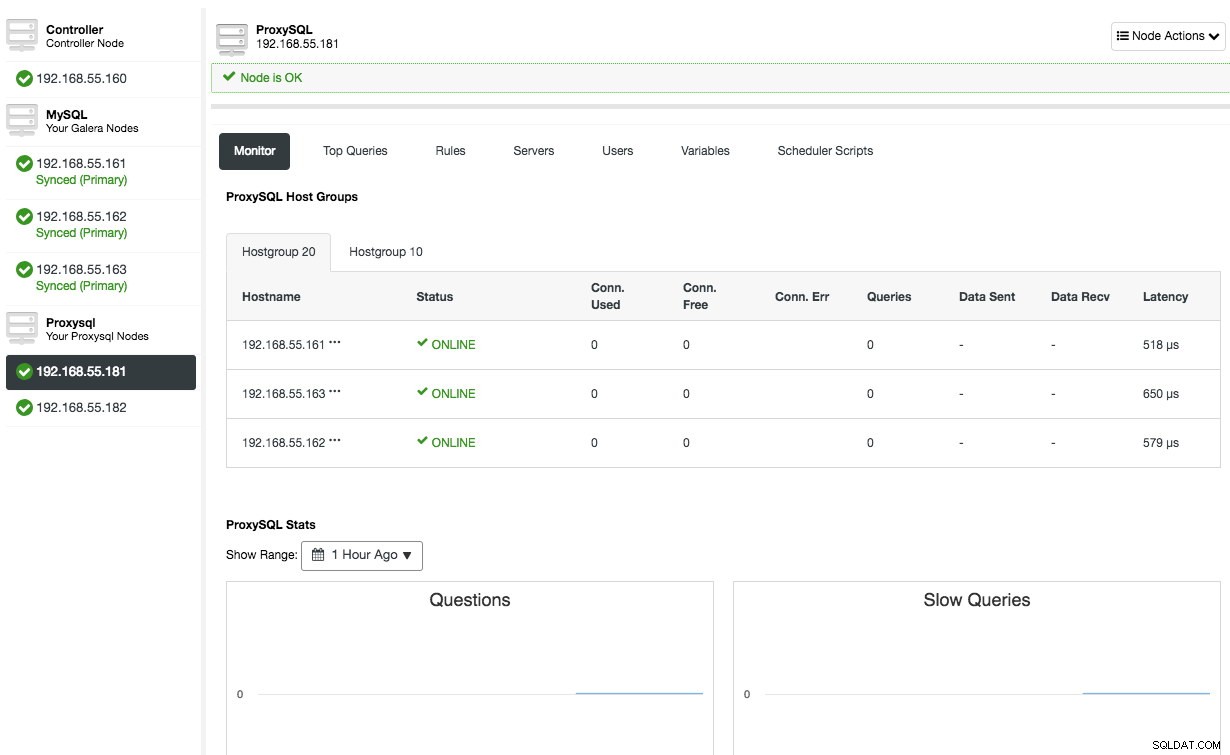
W tym momencie nasza architektura wygląda teraz tak:
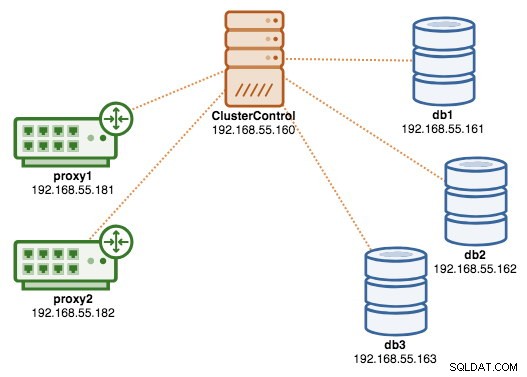
Jeśli chcesz dowiedzieć się więcej o ProxySQL, zapoznaj się z tym samouczkiem — Równoważenie obciążenia bazy danych dla MySQL i MariaDB z ProxySQL — samouczek.
Wdrażanie wirtualnego adresu IP
Ostatnią częścią jest wirtualny adres IP. Bez tego nasze load balancery (reverse proxy) byłyby słabym ogniwem, ponieważ byłyby pojedynczym punktem awarii - chyba że aplikacja ma możliwość automatycznego przekierowywania nieudanych połączeń z bazą danych do innego load balancera. Niemniej jednak dobrą praktyką jest ujednolicenie ich zarówno przy użyciu wirtualnego adresu IP, jak i uproszczenie punktu końcowego połączenia z warstwą bazy danych.
Z Interfejsu ClusterControl -> Dodaj Load Balancer -> Keepalved -> Wdróż funkcję Keepalive i wybierz dwa hosty ProxySQL, które wdrożyliśmy:
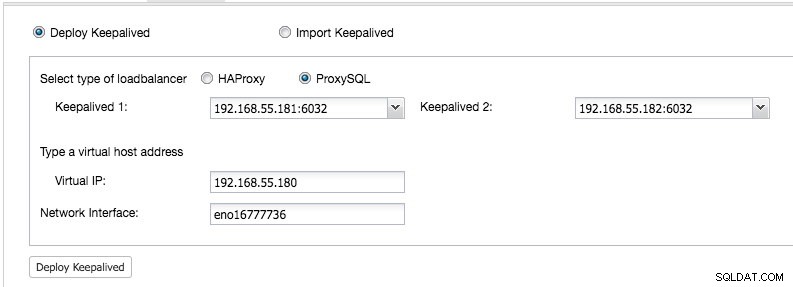
Określ również wirtualny adres IP i interfejs sieciowy, aby powiązać adres IP. Interfejs sieciowy musi istnieć na obu węzłach ProxySQL. Po wdrożeniu na pasku podsumowania klastra powinny pojawić się następujące zielone znaczniki:

W tym momencie naszą architekturę można zilustrować jak poniżej:
Nasz klaster baz danych jest teraz gotowy do użytku produkcyjnego. Możesz zaimportować do niego swoją istniejącą bazę danych lub utworzyć nową, świeżą bazę danych. Możesz użyć funkcji Zarządzanie schematami i użytkownikami, jeśli licencja próbna nie wygasła.
Aby zrozumieć, jak ClusterControl konfiguruje Keepalive, zapoznaj się z tym wpisem na blogu, Jak ClusterControl konfiguruje wirtualny adres IP i czego można się spodziewać podczas przełączania awaryjnego.
Łączenie z klastrem baz danych
Z punktu widzenia aplikacji i klienta, muszą połączyć się z 192.168.55.180 na porcie 6033, który jest wirtualnym adresem IP umieszczonym nad modułami równoważenia obciążenia. Na przykład konfiguracja bazy danych Wordpress będzie wyglądać mniej więcej tak:
/** The name of the database for WordPress */
define( 'DB_NAME', 'wp_myblog' );
/** MySQL database username */
define( 'DB_USER', 'wp_myblog' );
/** MySQL database password */
define( 'DB_PASSWORD', 'mysecr3t' );
/** MySQL hostname - virtual IP address with ProxySQL load-balanced port*/
define( 'DB_HOST', '192.168.55.180:6033' );Jeśli chcesz uzyskać bezpośredni dostęp do klastra bazy danych, z pominięciem modułu równoważenia obciążenia, możesz po prostu połączyć się z portem 3306 hostów bazy danych. Jest to zwykle wymagane przez personel DBA w celu administrowania, zarządzania i rozwiązywania problemów. Dzięki ClusterControl większość tych operacji można wykonać bezpośrednio z interfejsu użytkownika.
Ostateczne myśli
Jak pokazano powyżej, wdrożenie klastra bazy danych nie jest już trudnym zadaniem. Po wdrożeniu dostępny jest pełny zestaw bezpłatnych funkcji monitorowania, a także funkcje komercyjne do zarządzania kopiami zapasowymi, przełączania awaryjnego/odzyskiwania i innych. Szybkie wdrażanie różnych typów topologii klastrów/replikacji może być przydatne podczas oceny rozwiązań baz danych o wysokiej dostępności oraz ich dopasowania do konkretnego środowiska.