Jednym z najpopularniejszych sposobów osiągnięcia wysokiej dostępności MySQL jest replikacja. Replikacja istnieje od wielu lat i stała się znacznie bardziej stabilna wraz z wprowadzeniem identyfikatorów GTID. Jednak nawet przy tych ulepszeniach proces replikacji może ulec przerwaniu z różnych powodów – na przykład, gdy urządzenia nadrzędne i podrzędne nie są zsynchronizowane, ponieważ zapisy zostały wysłane bezpośrednio do urządzenia podrzędnego. Jak rozwiązywać problemy z replikacją i jak je naprawiać?
W tym poście na blogu omówimy niektóre z typowych problemów z replikacją oraz sposoby ich naprawienia za pomocą ClusterControl. Zacznijmy od pierwszego.
Replikacja zatrzymana z pewnym błędem
Większość administratorów baz danych MySQL zazwyczaj widzi tego rodzaju problem przynajmniej raz w swojej karierze. Z różnych powodów slave może zostać uszkodzony lub może przestać synchronizować się z masterem. W takim przypadku pierwszą rzeczą, którą należy zrobić, aby rozpocząć rozwiązywanie problemów, jest sprawdzenie dziennika błędów pod kątem komunikatów. W większości przypadków komunikat o błędzie można łatwo prześledzić w dzienniku błędów lub uruchamiając zapytanie SHOW SLAVE STATUS.
Rzućmy okiem na następujący przykład z SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Wyraźnie widać, że błąd jest powiązany z błędem krytycznym 1236 od urządzenia głównego podczas odczytu danych z dziennika binarnego:„Nie można znaleźć stanu GTID żądanego przez urządzenie podrzędne w żadnych plikach dziennika binarnego. Prawdopodobnie stan slave jest zbyt stary i wymagane pliki binlog zostały usunięte.'. Innymi słowy, błąd mówi nam zasadniczo, że istnieje niespójność danych i wymagane pliki dziennika binarnego zostały już usunięte.
To dobry przykład, w którym proces replikacji przestaje działać. Oprócz POKAŻ STATUS SLAVE, możesz również śledzić status w zakładce „Przegląd” klastra w ClusterControl. Jak więc to naprawić za pomocą ClusterControl? Masz dwie opcje do wypróbowania:
-
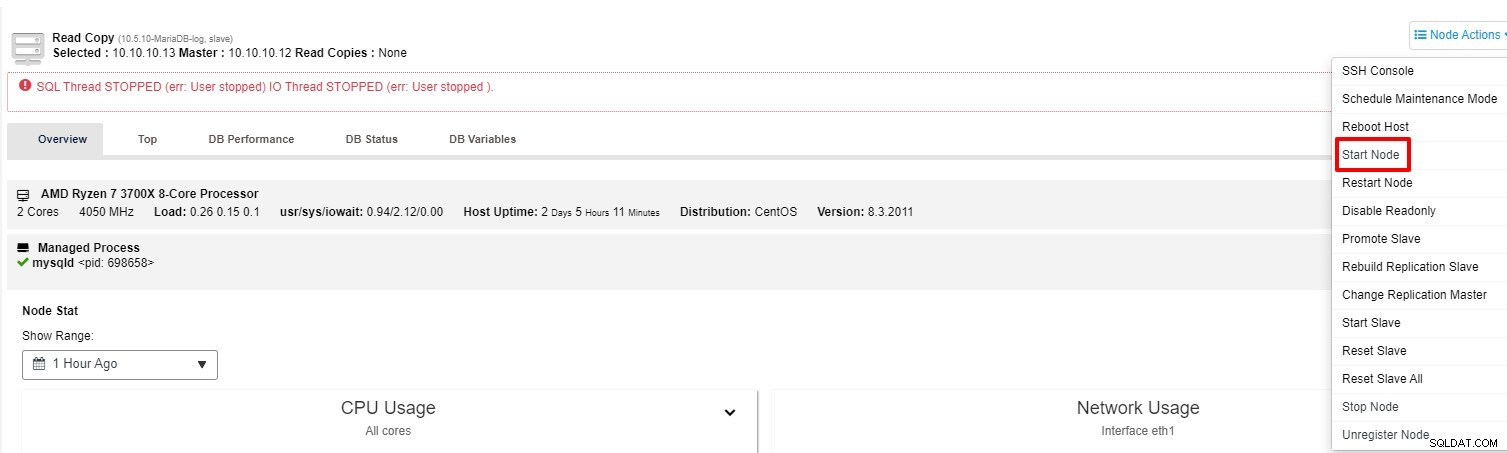
Możesz spróbować ponownie uruchomić urządzenie podrzędne z „Akcji węzła”
-
Jeśli urządzenie podrzędne nadal nie działa, możesz uruchomić zadanie „Odbuduj urządzenie podrzędne replikacji” z „Akcji węzła”
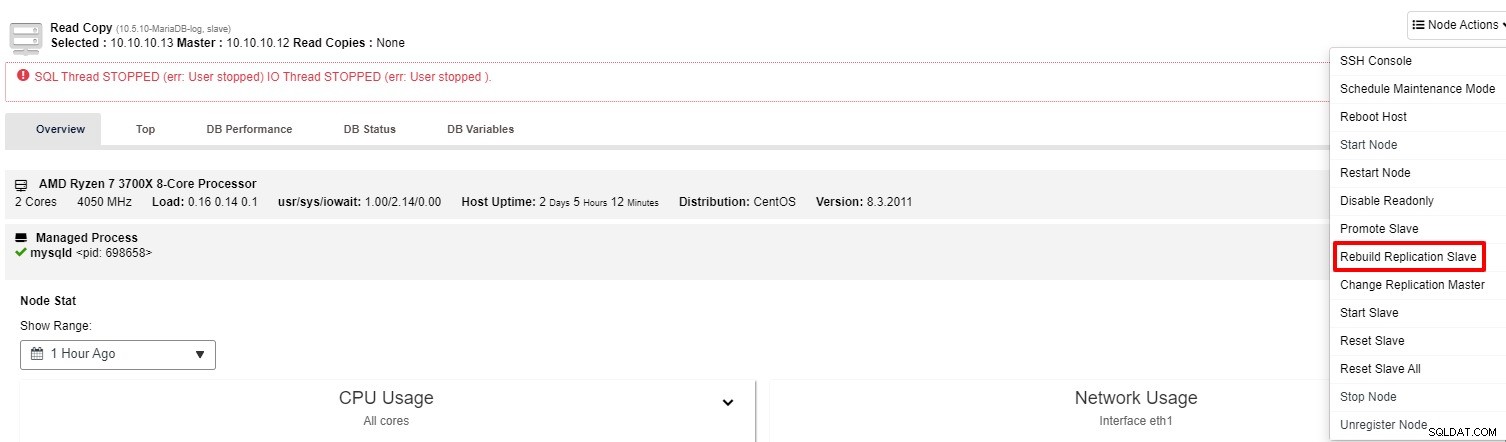
W większości przypadków druga opcja rozwiązuje problem. ClusterControl wykona kopię zapasową urządzenia nadrzędnego i odbuduje uszkodzone urządzenie podrzędne, przywracając dane. Po przywróceniu danych urządzenie podrzędne jest połączone z urządzeniem nadrzędnym, aby mogło nadrobić zaległości.
Istnieje również wiele ręcznych sposobów odbudowy urządzenia podrzędnego, jak wymieniono poniżej, możesz również skorzystać z tego linku, aby uzyskać więcej informacji:
-
Korzystanie z Mysqldump do odbudowania niespójnego modułu MySQL Slave
-
Korzystanie z Mydumper do odbudowania niespójnego serwera MySQL Slave
-
Korzystanie z migawki do odbudowania niespójnego modułu MySQL Slave
-
Korzystanie z Xtrabackup lub Mariabackup do odbudowania niespójnego serwera MySQL Slave
Promuj niewolnika na mistrza
Z biegiem czasu system operacyjny lub baza danych wymagają poprawek lub aktualizacji, aby zachować stabilność i bezpieczeństwo. Jedną z najlepszych praktyk, aby zminimalizować przestoje, szczególnie w przypadku poważnej aktualizacji, jest promowanie jednego z urządzeń podrzędnych do mastera po pomyślnym przeprowadzeniu aktualizacji na tym konkretnym węźle.
Wykonując to, możesz skierować swoją aplikację do nowego mastera, a replikacja master-slave będzie nadal działać. W międzyczasie możesz spokojnie kontynuować aktualizację starego mistrza. Dzięki ClusterControl można to wykonać za pomocą kilku kliknięć tylko przy założeniu, że replikacja jest skonfigurowana jako oparta na globalnym identyfikatorze transakcji lub w skrócie na podstawie GTID. Aby uniknąć utraty danych, warto zatrzymać wszelkie zapytania aplikacji na wypadek, gdyby stary master działał poprawnie. To nie jedyna sytuacja, w której możesz awansować niewolnika. W przypadku awarii głównego węzła możesz również wykonać tę akcję.
Bez ClusterControl istnieje kilka kroków do promocji urządzenia podrzędnego. Każdy z kroków wymaga również wykonania kilku zapytań:
-
Ręcznie zdejmij mistrza
-
Wybierz najbardziej zaawansowanego niewolnika na mistrza i przygotuj go
-
Połącz ponownie inne urządzenia podrzędne z nowym urządzeniem głównym
-
Zmiana starego pana na niewolnika
Niemniej jednak, kroki w celu promowania Slave za pomocą ClusterControl to tylko kilka kliknięć:Cluster> Nodes> wybierz węzeł slave> Promuj Slave jak na poniższym zrzucie ekranu:
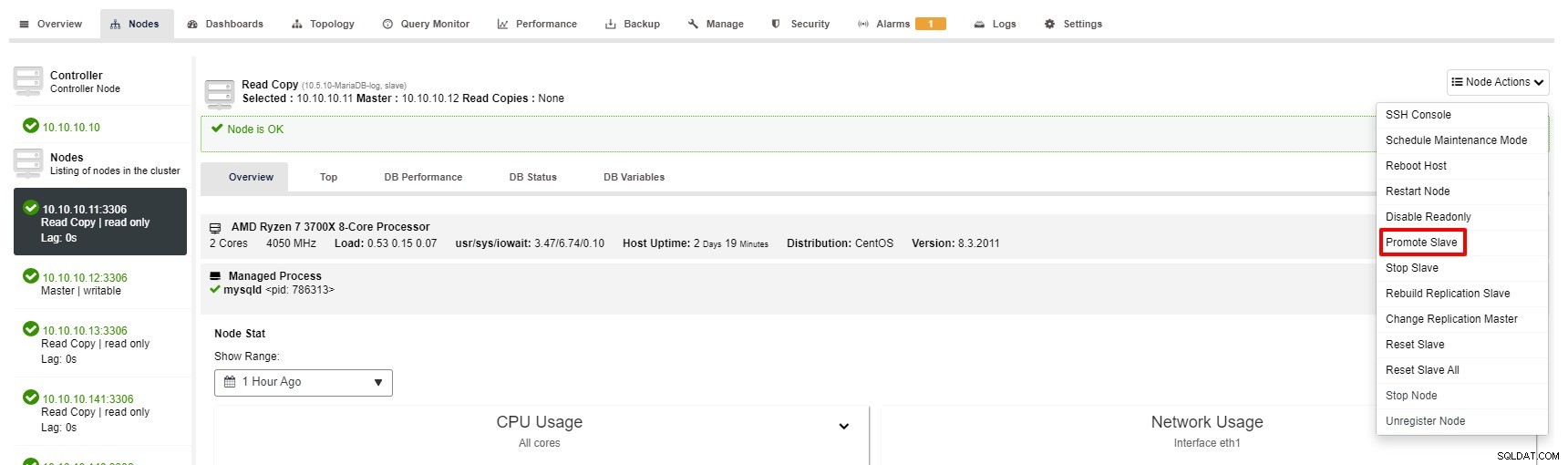
Mistrz staje się niedostępny
Wyobraź sobie, że masz duże transakcje do wykonania, ale baza danych nie działa. Nie ma znaczenia, jak bardzo jesteś ostrożny, jest to prawdopodobnie najpoważniejsza lub najważniejsza sytuacja dla konfiguracji replikacji. Kiedy tak się dzieje, Twoja baza danych nie jest w stanie przyjąć pojedynczego zapisu, co jest złe. Poza tym Twoja aplikacja (y) oczywiście nie będzie działać poprawnie.
Istnieje kilka przyczyn lub przyczyn, które prowadzą do tego problemu. Niektóre przykłady to awaria sprzętu, uszkodzenie systemu operacyjnego, uszkodzenie bazy danych i tak dalej. Jako administrator baz danych musisz działać szybko, aby przywrócić główną bazę danych.
Dzięki funkcji klastra „Auto Recovery” dostępnej w ClusterControl, proces przełączania awaryjnego można zautomatyzować. Można go włączyć lub wyłączyć jednym kliknięciem. Jak sama nazwa wskazuje, w razie potrzeby wyświetli całą topologię klastra. Na przykład replikacja master-slave musi mieć przynajmniej jednego mastera przy życiu w danym momencie, niezależnie od liczby dostępnych slave'ów. Gdy master jest niedostępny, automatycznie promuje jednego z slave'ów.
Rzućmy okiem na zrzut ekranu poniżej:
Na powyższym zrzucie ekranu widzimy, że „Automatyczne odzyskiwanie” jest włączone zarówno dla klastra, jak i węzła. W topologii zwróć uwagę, że aktualny główny adres IP to 10.10.10.11. Co się stanie, jeśli wyłączymy węzeł główny do celów testowych?
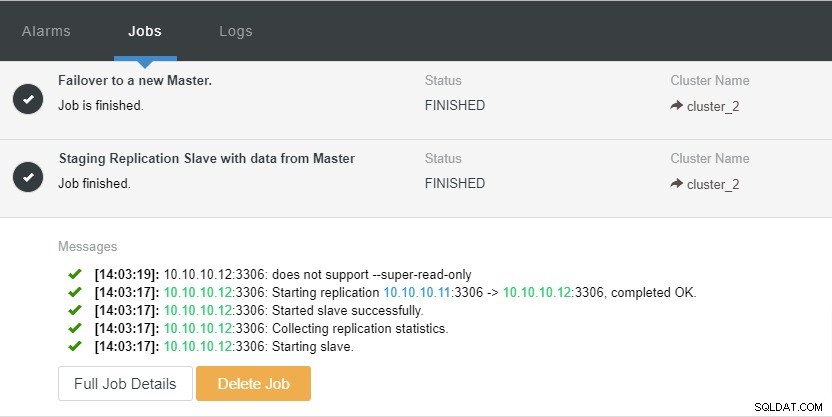
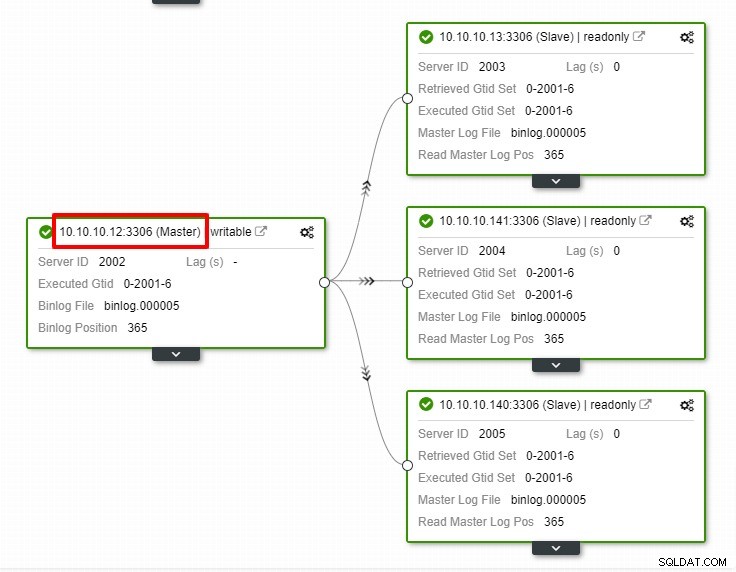
Jak widać, węzeł podrzędny z IP 10.10.10.12 jest automatycznie awansowany na mastera, aby ponownie skonfigurować topologię replikacji. Zamiast robić to ręcznie, co oczywiście będzie wymagało wielu kroków, ClusterControl pomaga w utrzymaniu konfiguracji replikacji, odciążając ręce.
Wnioski
W każdym niefortunnym przypadku z replikacją poprawka jest bardzo prosta i mniej kłopotliwa dzięki ClusterControl. ClusterControl pomaga szybko odzyskać problemy z replikacją, co zwiększa czas pracy baz danych.