Znaczenie przełączania awaryjnego
Przełączanie awaryjne jest jedną z najważniejszych praktyk baz danych w zarządzaniu bazą danych. Jest to przydatne nie tylko podczas zarządzania dużymi bazami danych w środowisku produkcyjnym, ale także wtedy, gdy chcesz mieć pewność, że Twój system jest zawsze dostępny, gdy tylko uzyskasz do niego dostęp – zwłaszcza na poziomie aplikacji.
Zanim nastąpi przełączenie awaryjne, instancje bazy danych muszą spełniać określone wymagania. Te wymagania są w rzeczywistości bardzo ważne dla wysokiej dostępności. Jednym z wymagań, które muszą spełnić Twoje instancje bazy danych, jest nadmiarowość. Nadmiarowość umożliwia kontynuację przełączania awaryjnego, w którym nadmiarowość jest skonfigurowana tak, aby mieć kandydata do przełączania awaryjnego, który może być węzłem repliki (drugorzędnym) lub z puli replik działających jako węzły rezerwowe lub węzły aktywnej gotowości. Kandydat wybierany jest ręcznie lub automatycznie na podstawie najbardziej zaawansowanego lub aktualnego węzła. Zwykle potrzebna jest replika w trybie gorącej gotowości, ponieważ może ona uratować bazę danych przed ściąganiem indeksów z dysku, ponieważ tryb gotowości często wypełnia indeksy w puli buforów bazy danych.
Przełączenie awaryjne to termin używany do opisania, że wystąpił proces odzyskiwania. Przed procesem odzyskiwania dzieje się tak, gdy podstawowy (lub nadrzędny) węzeł bazy danych ulegnie awarii po awarii, w wyniku klęsk żywiołowych, awarii sprzętu lub może ulec partycjonowaniu sieci; są to najczęstsze przypadki, w których może nastąpić przełączenie awaryjne. Proces odzyskiwania zwykle przebiega automatycznie, a następnie wyszukuje najbardziej pożądane i aktualne wtórne (repliki), jak wspomniano wcześniej.
Zaawansowane przełączanie awaryjne
Chociaż proces odzyskiwania podczas przełączania awaryjnego jest automatyczny, w pewnych sytuacjach automatyzacja procesu nie jest konieczna i musi przejąć kontrolę nad procesem ręcznym. Złożoność jest często głównym czynnikiem związanym z technologiami składającymi się na cały stos bazy danych - automatyczne przełączanie awaryjne można również mieszać z ręcznym przełączaniem awaryjnym.
W większości codziennych rozważań związanych z zarządzaniem bazami danych większość obaw związanych z automatycznym przełączaniem awaryjnym naprawdę nie jest trywialna. Często przydatne jest zaimplementowanie i skonfigurowanie automatycznego przełączania awaryjnego w przypadku wystąpienia problemów. Choć brzmi to obiecująco, ponieważ obejmuje złożoność, pojawiają się zaawansowane mechanizmy przełączania awaryjnego, które obejmują zdarzenia „przed” i zdarzenia „po”, które są powiązane jako zaczepy w oprogramowaniu lub technologii przełączania awaryjnego.
Te zdarzenia przed i po przychodzą z kontrolami lub pewnymi działaniami do wykonania, zanim będzie można w końcu przejść do przełączenia awaryjnego, a po wykonaniu przełączenia awaryjnego, kilka porządków, aby upewnić się, że przełączenie awaryjne zakończyło się pomyślnie jeden. Na szczęście dostępne są narzędzia, które pozwalają nie tylko na automatyczne przełączanie awaryjne, ale także umożliwiają zastosowanie przechwytów przed i po skrypcie.
W tym blogu użyjemy automatycznego przełączania awaryjnego ClusterControl (CC) i wyjaśnimy, jak używać zaczepów skryptu pre i post oraz do jakiego klastra mają one zastosowanie.
Przełączanie awaryjne replikacji ClusterControl
Mechanizm przełączania awaryjnego ClusterControl jest efektywnie stosowany w replikacji asynchronicznej, która ma zastosowanie do wariantów MySQL (MySQL/Percona Server/MariaDB). Dotyczy to również klastrów PostgreSQL/TimescaleDB — ClusterControl obsługuje replikację strumieniową. Klastry MongoDB i Galera mają własny mechanizm automatycznego przełączania awaryjnego wbudowany we własną technologię bazy danych. Przeczytaj więcej o tym, jak ClusterControl wykonuje automatyczne odzyskiwanie bazy danych i przełączanie awaryjne.
Przełączanie awaryjne ClusterControl nie działa, jeśli nie jest włączone odzyskiwanie węzła i klastra (automatyczne odzyskiwanie). Oznacza to, że te przyciski powinny być zielone.

Dokumentacja stwierdza, że tych opcji konfiguracyjnych można również użyć do włączenia / wyłącz następujące elementy:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
W tym blogu skupiamy się głównie na tym, jak używać przechwytów skryptu pre/post, co jest zasadniczo wielką zaletą w przypadku przełączania awaryjnego zaawansowanej replikacji.
Obsługa skryptów przed/po pracy awaryjnej replikacji klastra
Jak wspomniano wcześniej, warianty MySQL, które wykorzystują replikację asynchroniczną (w tym półsynchroniczną) i replikację strumieniową dla PostgreSQL/TimescaleDB, obsługują ten mechanizm. ClusterControl posiada następujące opcje konfiguracyjne, których można użyć do przechwycenia przed i po skrypcie. Zasadniczo te opcje konfiguracji można ustawić za pomocą ich plików konfiguracyjnych lub można je ustawić za pomocą internetowego interfejsu użytkownika (zajmiemy się tym później).
Nasza dokumentacja stwierdza, że są to następujące opcje konfiguracyjne, które mogą zmienić mechanizm przełączania awaryjnego za pomocą zaczepów skryptu pre/post:
| replication_pre_failover_script=<ścieżka> |
|
| replication_post_failover_script=<ścieżka> |
|
| replication_post_unsuccessful_failover_script=<ścieżka> |
|
Technicznie rzecz biorąc, po ustawieniu następujących opcji konfiguracyjnych w pliku konfiguracyjnym /etc/cmon.d/cmon_
$ systemctl restart cmonAlternatywnie możesz również ustawić opcje konfiguracji, przechodząc do
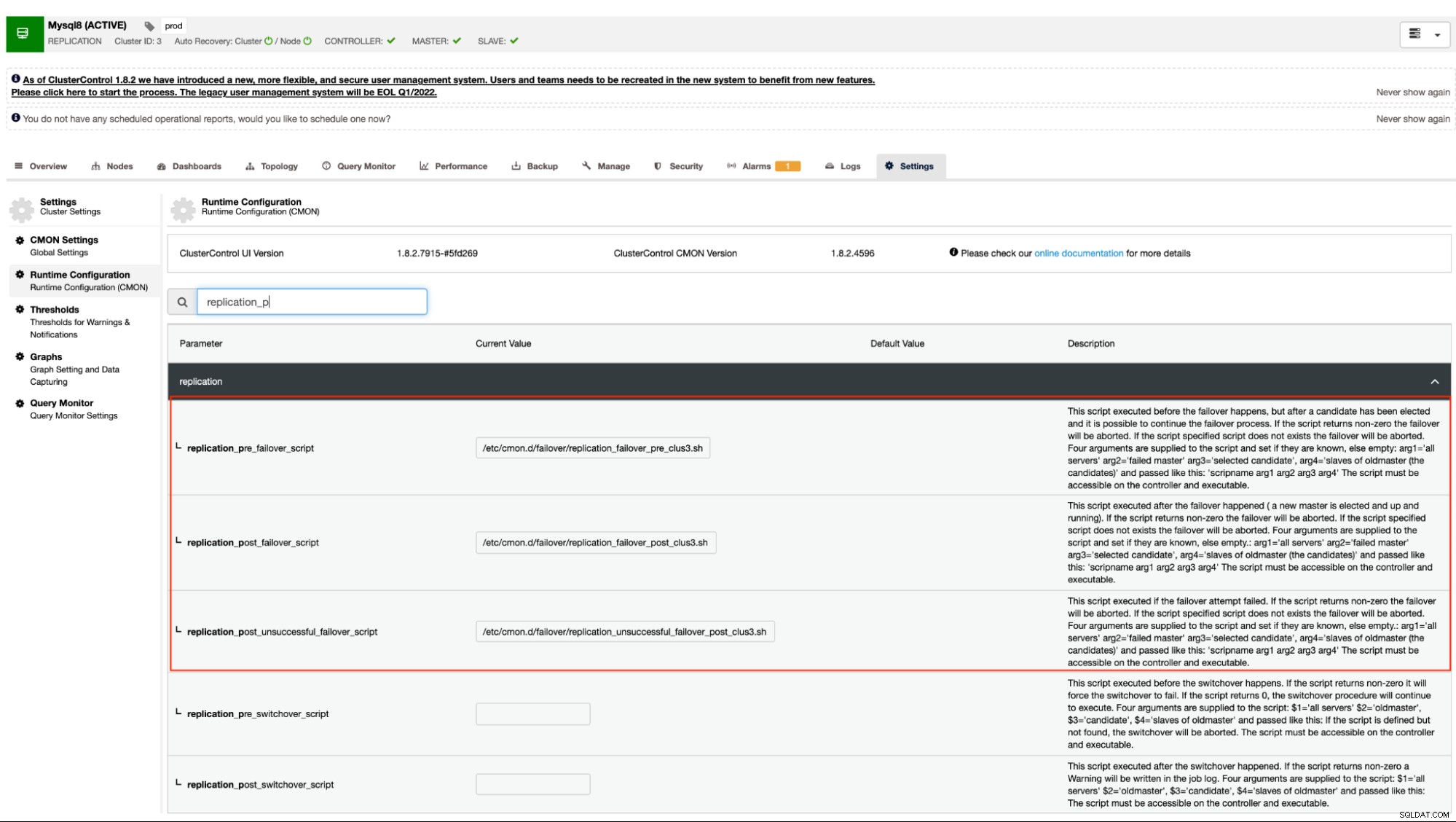
To podejście nadal wymagałoby ponownego uruchomienia usługi cmon, zanim będzie mogło odzwierciedlać zmiany wprowadzone dla tych opcji konfiguracji dla przechwytów pre/post script.
Przykład haków pre/post
Idealnie, podpięcia skryptu pre/post są dedykowane, gdy potrzebne jest zaawansowane przełączanie awaryjne, w przypadku którego ClusterControl nie jest w stanie poradzić sobie ze złożonością konfiguracji bazy danych. Na przykład, jeśli korzystasz z różnych centrów danych z zaostrzonymi zabezpieczeniami i chcesz określić, czy alert o nieosiągalnej sieci nie jest fałszywym alarmem pozytywnym. Musi sprawdzić, czy główny i podrzędny mogą połączyć się ze sobą i na odwrót, a także może połączyć się z węzłami bazy danych przechodzącymi do hosta ClusterControl.
Zróbmy to w naszym przykładzie i zademonstrujmy, jak możesz z tego skorzystać.
Szczegóły serwera i skrypty
W tym przykładzie używam klastra replikacji MariaDB z tylko podstawowym i repliką. Zarządzane przez ClusterControl w celu zarządzania przełączaniem awaryjnym.
ClusterControl =192.168.40.110
podstawowy (debnode5) =192.168.30.50
replika (debnode9) =192.168.30.90
W głównym węźle utwórz skrypt zgodnie z poniższym opisem,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Upewnij się, że plik /opt/pre_failover.sh jest wykonywalny, tj.
$ chmod +x /opt/pre_failover.shNastępnie użyj tego skryptu, aby zaangażować się za pośrednictwem crona. W tym przykładzie utworzyłem plik /etc/cron.d/ccfailover i mam następującą zawartość:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shW replice wykonaj następujące czynności, które wykonaliśmy dla podstawowej, z wyjątkiem zmiany nazwy hosta. Zobacz, co mam poniżej w mojej replice:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"i upewnij się, że skrypt wywoływany w naszym cronie jest wykonywalny,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shSkrypty przed i po ClusterControl
W tej demonstracji mój identyfikator klastra to 3. Jak wspomniano wcześniej w naszej dokumentacji, wymaga to, aby te skrypty znajdowały się na hoście kontrolera CC. Tak więc w moim /etc/cmon.d/cmon_3.cnf mam:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shNastępujący skrypt przełączania awaryjnego „pre” określa, czy oba węzły były w stanie połączyć się z hostem kontrolera CC. Zobacz:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demonstracja przełączania awaryjnego
Teraz spróbujmy zasymulować awarię sieci w węźle podstawowym i zobaczmy, jak zareaguje. W moim węźle głównym wyłączam interfejs sieciowy używany do komunikacji z repliką i kontrolerem CC.
example@sqldat.com:~# ip link set enp0s8 downPodczas pierwszej próby przełączania awaryjnego CC był w stanie uruchomić mój skrypt pre, który znajduje się w /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Zobacz poniżej, jak to działa:
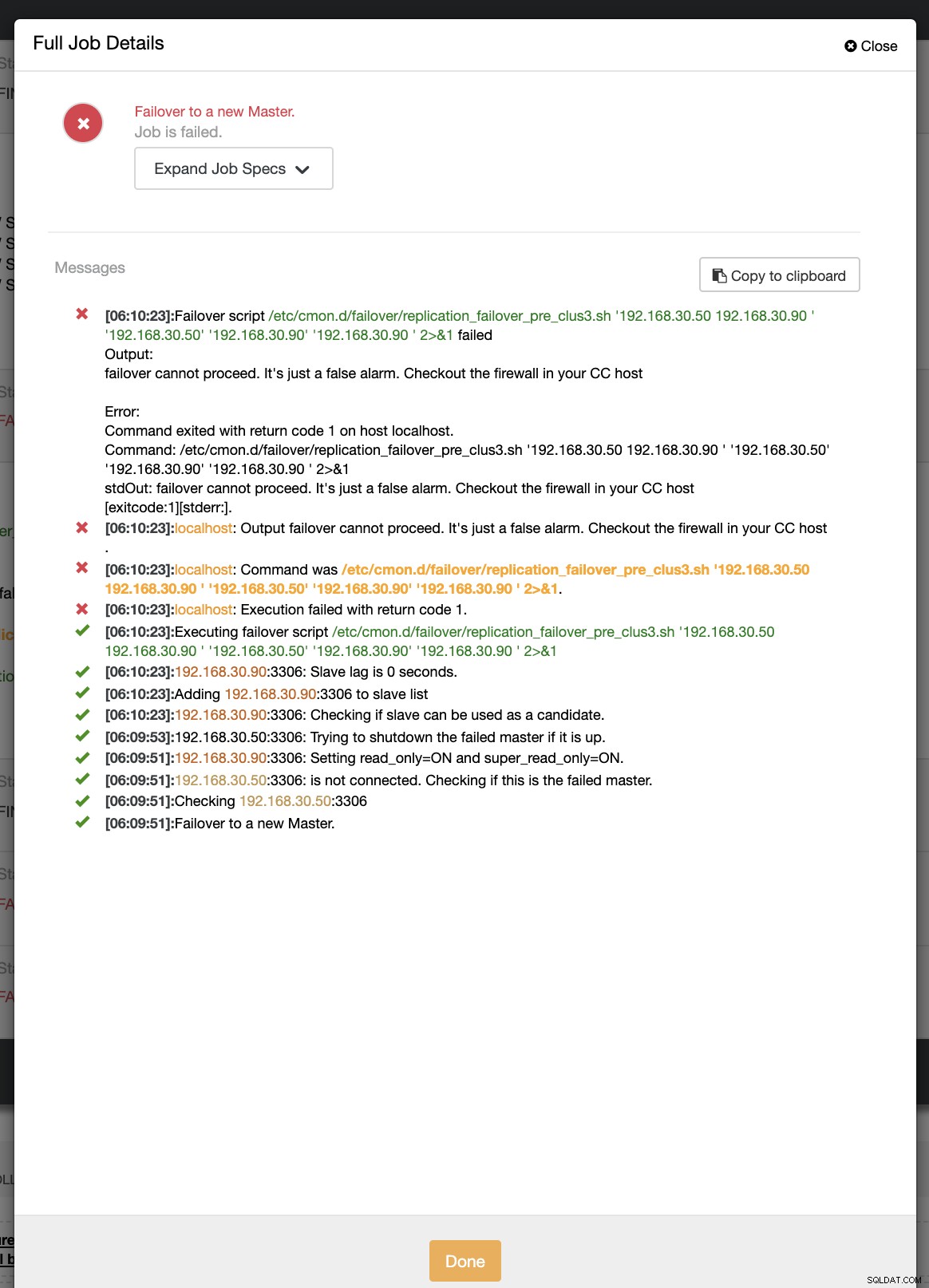
Oczywiście kończy się niepowodzeniem, ponieważ zarejestrowany znacznik czasu nie jest jeszcze dłuższy niż minuta lub zaledwie kilka sekund temu podstawowy nadal był w stanie połączyć się z kontrolerem CC. Oczywiście nie jest to idealne podejście, gdy masz do czynienia z prawdziwym scenariuszem. Jednak ClusterControl był w stanie wywołać i wykonać skrypt idealnie zgodnie z oczekiwaniami. A co powiesz na to, że rzeczywiście trwa dłużej niż minutę (tj.> 60 sekund)?
W naszej drugiej próbie przełączania awaryjnego, ponieważ znacznik czasu przekracza 60 sekund, uznaje się, że jest to prawdziwy pozytyw, a to oznacza, że musimy przełączyć się w tryb awaryjny zgodnie z zamierzeniami. CC był w stanie doskonale go wykonać, a nawet wykonać postscript zgodnie z przeznaczeniem. Można to zobaczyć w dzienniku pracy. Zobacz zrzut ekranu poniżej:
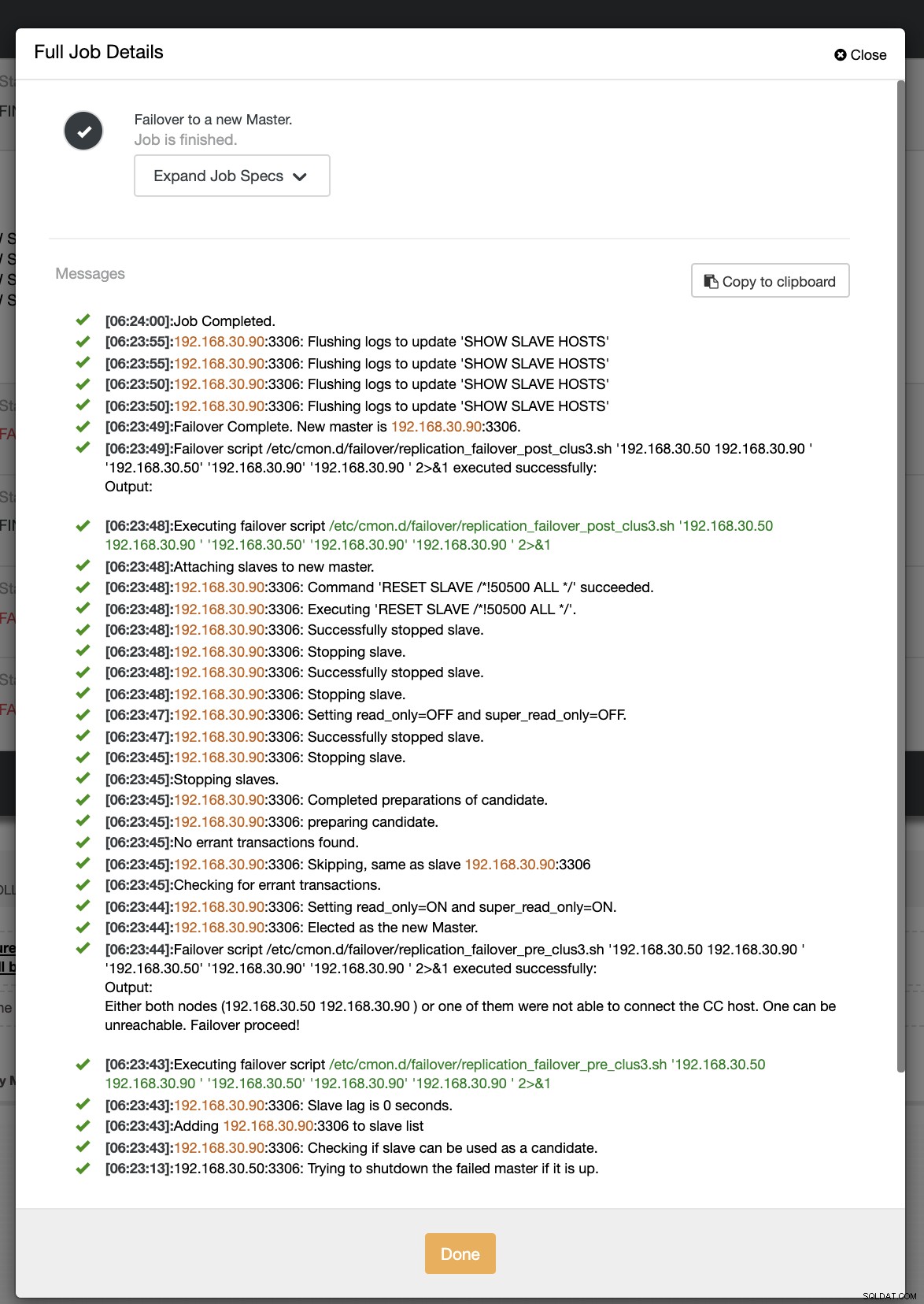
Weryfikowanie, czy mój skrypt posta został uruchomiony, udało się utworzyć dziennik plik w katalogu CC /tmp zgodnie z oczekiwaniami,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtopublikuj skrypt przełączania awaryjnego w klastrze 3 z argumentami:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
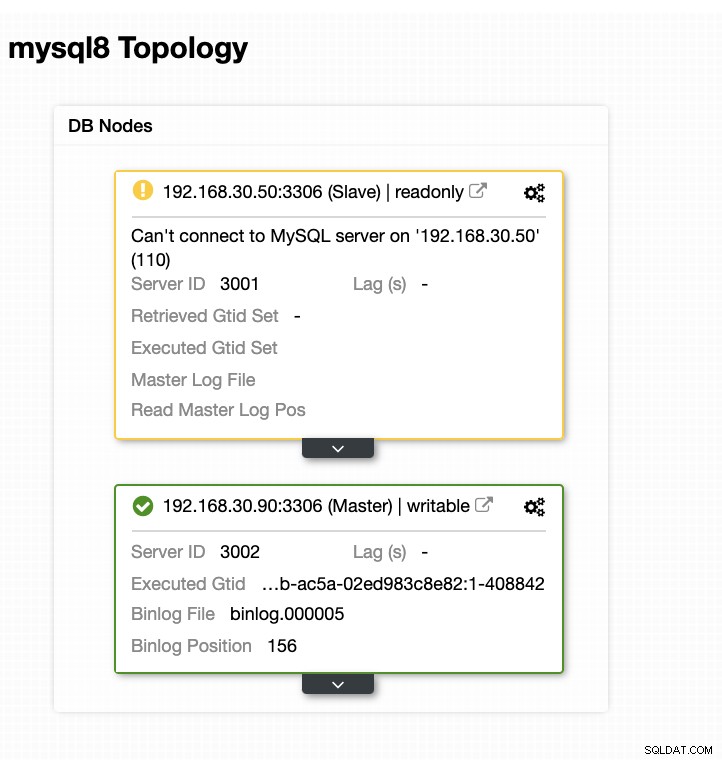
Teraz moja topologia została zmieniona i przełączanie awaryjne powiodło się!
Wnioski
W przypadku każdej skomplikowanej konfiguracji bazy danych, gdy wymagane jest zaawansowane przełączanie awaryjne, skrypty pre/post mogą być bardzo pomocne, aby wszystko było osiągalne. Ponieważ ClusterControl obsługuje te funkcje, pokazaliśmy, jak potężny i pomocny jest. Nawet przy jego ograniczeniach zawsze istnieją sposoby, aby rzeczy były osiągalne i użyteczne, zwłaszcza w środowiskach produkcyjnych.