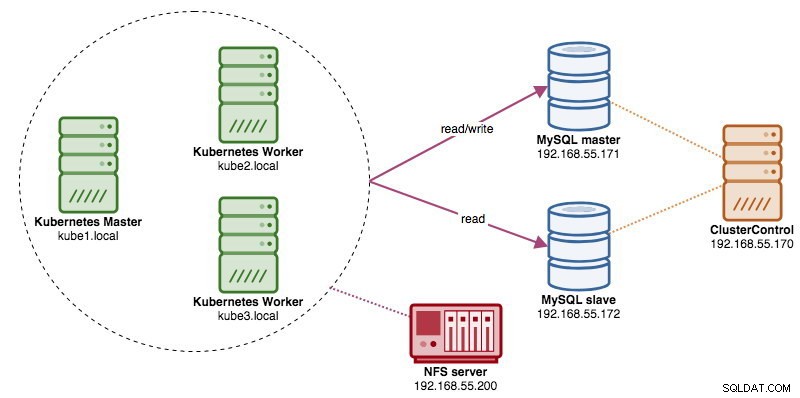
Podczas uruchamiania rozproszonych klastrów baz danych dość często stosuje się do nich mechanizmy równoważenia obciążenia. Korzyści są oczywiste — równoważenie obciążenia, przełączanie awaryjne połączeń i oddzielenie warstwy aplikacji od bazowych topologii baz danych. Aby uzyskać bardziej inteligentne równoważenie obciążenia, najlepszym rozwiązaniem byłby serwer proxy obsługujący bazę danych, taki jak ProxySQL lub MaxScale. W naszym poprzednim blogu pokazaliśmy, jak uruchomić ProxySQL jako kontener pomocniczy w Kubernetes. W tym poście na blogu pokażemy, jak wdrożyć ProxySQL jako usługę Kubernetes. Użyjemy Wordpressa jako przykładowej aplikacji, a zaplecze bazy danych działa na dwuwęzłowej replikacji MySQL wdrożonej przy użyciu ClusterControl. Poniższy diagram ilustruje naszą infrastrukturę:
Ponieważ zamierzamy wdrożyć podobną konfigurację, jak w poprzednim poście na blogu, należy się spodziewać powielania niektórych części wpisu na blogu, aby post był bardziej czytelny.
ProxySQL na Kubernetes
Zacznijmy od krótkiego podsumowania. Projektowanie architektury ProxySQL jest tematem subiektywnym i silnie uzależnionym od umiejscowienia aplikacji, kontenerów bazy danych oraz roli samego ProxySQL. W idealnej sytuacji możemy skonfigurować ProxySQL do zarządzania przez Kubernetes w dwóch konfiguracjach:
- ProxySQL jako usługa Kubernetes (scentralizowane wdrażanie)
- ProxySQL jako kontener pomocniczy w pod (rozproszone wdrożenie)
Oba wdrożenia można łatwo odróżnić, patrząc na następujący diagram:
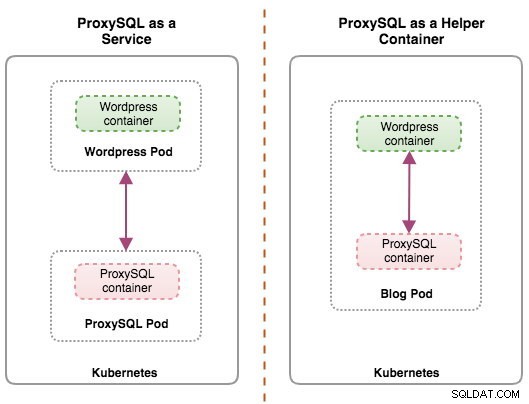
W tym poście na blogu omówimy pierwszą konfigurację — uruchamianie ProxySQL jako usługi Kubernetes. Druga konfiguracja została już omówiona tutaj. W przeciwieństwie do podejścia kontenera pomocnika, uruchamianie jako usługa sprawia, że pody ProxySQL działają niezależnie od aplikacji i mogą być łatwo skalowane i klastrowane razem za pomocą Kubernetes ConfigMap. Jest to zdecydowanie inne podejście do klastrowania niż natywna obsługa klastrów ProxySQL, która opiera się na sumie kontrolnej konfiguracji w instancjach ProxySQL (tzw. proxysql_servers). Sprawdź ten wpis na blogu, jeśli chcesz dowiedzieć się więcej o klastrowaniu ProxySQL, które jest łatwe dzięki ClusterControl.
W Kubernetes wielowarstwowy system konfiguracji ProxySQL umożliwia klastrowanie pod za pomocą programu ConfigMap. Istnieje jednak wiele niedociągnięć i obejść, które sprawiają, że działa płynnie, tak jak robi to natywna funkcja klastrowania ProxySQL. W tej chwili sygnalizowanie poda po aktualizacji ConfigMap jest funkcją, nad którą pracujemy. Ten temat omówimy bardziej szczegółowo w nadchodzącym poście na blogu.
Zasadniczo musimy utworzyć pody ProxySQL i dołączyć usługę Kubernetes, aby uzyskać dostęp do innych podów w sieci Kubernetes lub zewnętrznie. Aplikacje będą wówczas łączyć się z usługą ProxySQL za pośrednictwem sieci TCP/IP na skonfigurowanych portach. Domyślnie 6033 dla połączeń z równoważeniem obciążenia MySQL i 6032 dla konsoli administracyjnej ProxySQL. W przypadku więcej niż jednej repliki połączenia z podem będą równoważone automatycznie przez komponent Kubernetes kube-proxy działający na każdym węźle Kubernetes.
ProxySQL jako usługa Kubernetes
W tej konfiguracji uruchamiamy zarówno ProxySQL, jak i Wordpress jako pody i usługi. Poniższy diagram ilustruje naszą architekturę wysokiego poziomu:
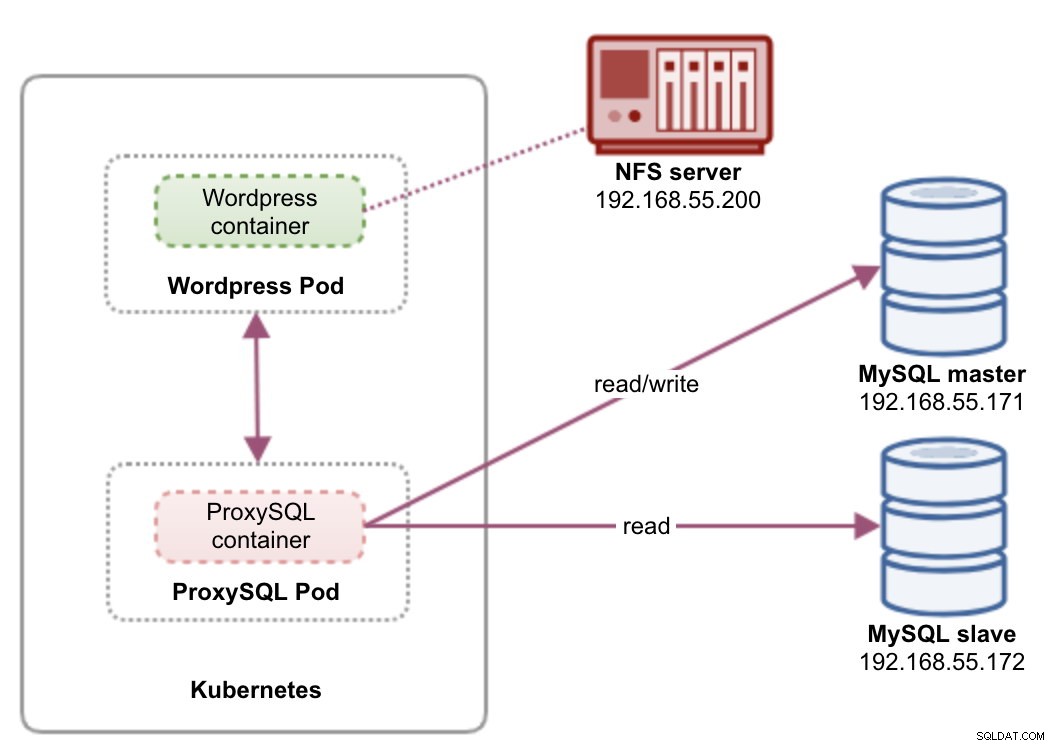
W tej konfiguracji wdrożymy dwa pody i usługi — „wordpress” i „proxysql”. Połączymy deklaracje wdrażania i usług w jednym pliku YAML na aplikację i będziemy zarządzać nimi jako jedną jednostką. Aby zawartość kontenerów aplikacji była trwała w wielu węzłach, musimy użyć klastrowego lub zdalnego systemu plików, którym w tym przypadku jest NFS.
Wdrożenie ProxySQL jako usługi przynosi kilka dobrych rzeczy w stosunku do podejścia kontenera pomocniczego:
- Korzystając z podejścia Kubernetes ConfigMap, ProxySQL można łączyć w klastry z niezmienną konfiguracją.
- Kubernetes obsługuje odzyskiwanie ProxySQL i automatycznie równoważy połączenia z instancjami.
- Pojedynczy punkt końcowy z implementacją wirtualnego adresu IP Kubernetes o nazwie ClusterIP.
- Scentralizowana warstwa zwrotnego proxy z architekturą niczego nie współdzielonego.
- Może być używany z aplikacjami zewnętrznymi poza Kubernetes.
Rozpoczniemy wdrażanie jako dwie repliki dla ProxySQL i trzy dla Wordpress, aby zademonstrować działanie na dużą skalę i możliwości równoważenia obciążenia, które oferuje Kubernetes.
Przygotowywanie bazy danych
Utwórz bazę danych wordpress i użytkownika na urządzeniu głównym i przypisz z odpowiednimi uprawnieniami:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Utwórz także użytkownika monitorującego ProxySQL:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Następnie ponownie załaduj tabelę grantów:
mysql-master> FLUSH PRIVILEGES;Pod ProxySQL i definicja usługi
Następnym krokiem jest przygotowanie naszego wdrożenia ProxySQL. Utwórz plik o nazwie proxysql-rs-svc.yml i dodaj następujące wiersze:
apiVersion: v1
kind: Deployment
metadata:
name: proxysql
labels:
app: proxysql
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: proxysql
tier: frontend
spec:
restartPolicy: Always
containers:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap
---
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendZobaczmy, o co chodzi w tych definicjach. YAML składa się z dwóch zasobów połączonych w plik, oddzielonych separatorem „---”. Pierwszym zasobem jest wdrożenie, które definiujemy w następującej specyfikacji:
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdatePowyższe oznacza, że chcielibyśmy wdrożyć dwa pody ProxySQL jako zestaw replik, który pasuje do kontenerów oznaczonych etykietą „app=proxysql,tier=frontend”. Strategia wdrażania określa strategię używaną do zastępowania starych zasobników nowymi. W tym wdrożeniu wybraliśmy RollingUpdate, co oznacza, że pody będą aktualizowane w sposób ciągły, po jednym pod na raz.
Kolejna część to szablon kontenera:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmapW spec.templates.spec.container.* w sekcji, mówimy Kubernetesowi, aby wdrożył ProxySQL przy użyciu severalnines/proxysql wersja obrazu 1.4.12. Chcemy również, aby Kubernetes zamontował nasz niestandardowy, wstępnie skonfigurowany plik konfiguracyjny i zmapował go do /etc/proxysql.cnf wewnątrz kontenera. Działające zasobniki opublikują dwa porty — 6033 i 6032. Zdefiniujemy również sekcję „wolumy”, w której poinstruujemy Kubernetes, aby zamontował ConfigMap jako wolumin wewnątrz zasobników ProxySQL, które mają być montowane przez volumeMounts.
Drugim zasobem jest usługa. Usługa Kubernetes to warstwa abstrakcji, która definiuje logiczny zestaw podów i zasady dostępu do nich. W tej sekcji definiujemy:
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendW tym przypadku chcemy, aby dostęp do naszego ProxySQL był możliwy z sieci zewnętrznej, dlatego wybranym typem jest typ NodePort. Spowoduje to opublikowanie nodePort na wszystkich węzłach Kubernetes w klastrze. Zakres prawidłowych portów dla zasobu NodePort to 30000-32767. Wybraliśmy port 30033 dla połączeń z równoważeniem obciążenia MySQL, który jest zmapowany na port 6033 w kapsułach ProxySQL i port 30032 dla portu administracyjnego ProxySQL zmapowanego na 6032.
Dlatego, w oparciu o naszą definicję YAML powyżej, musimy przygotować następujący zasób Kubernetes, zanim będziemy mogli rozpocząć wdrażanie pod „proxysql”:
- ConfigMap — do przechowywania pliku konfiguracyjnego ProxySQL jako woluminu, aby można go było zamontować w wielu zasobnikach i ponownie zamontować, jeśli zasobnik zostanie przeniesiony do innego węzła Kubernetes.
Przygotowywanie ConfigMap dla ProxySQL
Podobnie jak w poprzednim poście w blogu, zamierzamy użyć podejścia ConfigMap do oddzielenia pliku konfiguracyjnego od kontenera, a także do celów skalowalności. Zwróć uwagę, że w tej konfiguracji uważamy, że nasza konfiguracja ProxySQL jest niezmienna.
Najpierw utwórz plik konfiguracyjny ProxySQL, proxysql.cnf i dodaj następujące wiersze:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="proxysql-admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)Zwróć uwagę na admin_variables.admin_credentials zmienna, w której użyliśmy użytkownika innego niż domyślny, którym jest „proxysql-admin”. ProxySQL rezerwuje domyślnego użytkownika „admin” tylko do połączenia lokalnego przez localhost. Dlatego musimy użyć innych użytkowników, aby uzyskać zdalny dostęp do instancji ProxySQL. W przeciwnym razie otrzymasz następujący błąd:
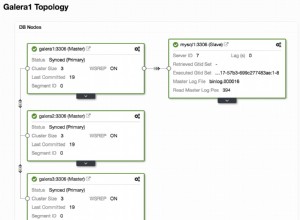
ERROR 1040 (42000): User 'admin' can only connect locallyNasza konfiguracja ProxySQL opiera się na naszych dwóch serwerach baz danych działających w replikacji MySQL, jak podsumowano na poniższym zrzucie ekranu topologii zaczerpniętym z ClusterControl:
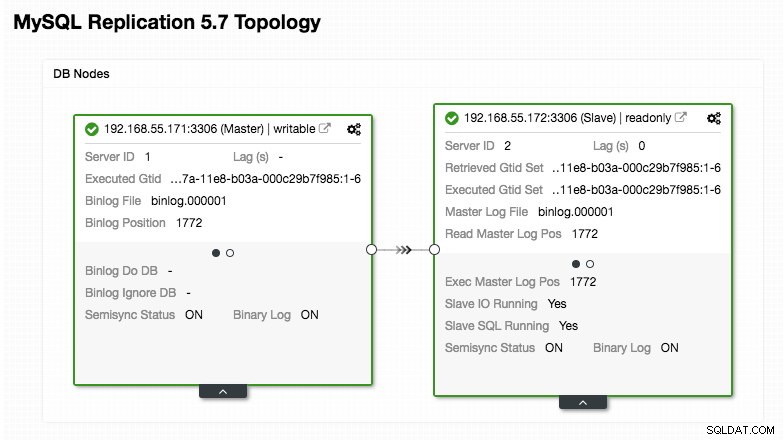
Wszystkie zapisy powinny iść do węzła głównego, podczas gdy odczyty są przekazywane do grupy hostów 20, zgodnie z definicją w sekcji „mysql_query_rules”. To podstawa dzielenia odczytu/zapisu i chcemy je całkowicie wykorzystać.
Następnie zaimportuj plik konfiguracyjny do ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdSprawdź, czy ConfigMap jest załadowany do Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sDefinicja poda i usługi Wordpress
Teraz wklej następujące wiersze do pliku o nazwie wordpress-rs-svc.yml na hoście, na którym skonfigurowano kubectl:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033 # proxysql.default.svc.cluster.local:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_DATABASE
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendPodobnie do naszej definicji ProxySQL, YAML składa się z dwóch zasobów oddzielonych ogranicznikiem „---” połączonych w pliku. Pierwszym z nich jest zasób Deployment, który zostanie wdrożony jako ReplicaSet, jak pokazano w sekcji „spec.*”:
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdateTa sekcja zawiera specyfikację wdrożenia — 3 pody na początek, które odpowiadają etykiecie „app=wordpress,tier=backend”. Strategia wdrażania to RollingUpdate, co oznacza, że sposób, w jaki Kubernetes zastąpi pod, polega na użyciu sposobu aktualizacji kroczących, tak samo jak w przypadku wdrożenia ProxySQL.
Następna część to sekcja „spec.template.spec.*”:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
W tej sekcji mówimy Kubernetes, aby wdrożył Wordpress 4.9 przy użyciu serwera WWW Apache, a kontenerowi nadaliśmy nazwę "wordpress". Kontener będzie uruchamiany ponownie za każdym razem, gdy zostanie wyłączony, niezależnie od stanu. Chcemy również, aby Kubernetes przekazywał szereg zmiennych środowiskowych:
- WORDPRESS_DB_HOST - Host bazy danych MySQL. Ponieważ używamy ProxySQL jako usługi, nazwa usługi będzie wartością metadata.name czyli "proxysql". ProxySQL nasłuchuje na porcie 6033 dla połączeń MySQL ze zrównoważonym obciążeniem, podczas gdy konsola administracyjna ProxySQL jest na 6032.
- WORDPRESS_DB_USER - Określ użytkownika bazy danych Wordpress, który został utworzony w sekcji „Przygotowywanie bazy danych”.
- WORDPRESS_DB_PASSWORD - Hasło dla WORDPRESS_DB_USER . Ponieważ nie chcemy ujawniać hasła w tym pliku, możemy je ukryć za pomocą Kubernetes Secrets. Tutaj instruujemy Kubernetes, aby zamiast tego przeczytał zasób tajny "mysql-pass". Sekrety muszą zostać utworzone na zaawansowanym etapie przed wdrożeniem pod, jak wyjaśniono poniżej.
Chcemy również opublikować port 80 poda dla użytkownika końcowego. Zawartość Wordpress przechowywana w /var/www/html w kontenerze zostanie zamontowana w naszym trwałym magazynie działającym na NFS. W tym celu użyjemy zasobów PersistentVolume i PersistentVolumeClaim, jak pokazano w sekcji „Przygotowywanie trwałego magazynu dla Wordpress”.
Po linii przerwania „---” definiujemy kolejny zasób o nazwie Usługa:
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendW tej konfiguracji chcielibyśmy, aby Kubernetes utworzył usługę o nazwie „wordpress”, nasłuchiwał na porcie 30088 na wszystkich węzłach (aka NodePort) do sieci zewnętrznej i przekazywał go do portu 80 we wszystkich podach oznaczonych „app=wordpress,tier=nakładka”.
Dlatego, w oparciu o naszą definicję YAML powyżej, musimy przygotować szereg zasobów Kubernetes, zanim będziemy mogli rozpocząć wdrażanie poda i usługi „wordpress”:
- Stała głośność i PersistentVolumeClaim - Aby przechowywać zawartość sieciową naszej aplikacji Wordpress, więc gdy pod zostanie przeniesiony do innego węzła roboczego, nie stracimy ostatnich zmian.
- Sekrety - Aby ukryć hasło użytkownika bazy danych Wordpress w pliku YAML.
Przygotowywanie pamięci trwałej dla Wordpress
Dobry magazyn trwały dla Kubernetes powinien być dostępny dla wszystkich węzłów Kubernetes w klastrze. Na potrzeby tego wpisu na blogu użyliśmy NFS jako dostawcy PersistentVolume (PV), ponieważ jest łatwy i obsługiwany od razu po zainstalowaniu. Serwer NFS znajduje się gdzieś poza naszą siecią Kubernetes (jak pokazano na pierwszym schemacie architektury) i skonfigurowaliśmy go tak, aby zezwalał na wszystkie węzły Kubernetes z następującym wierszem w /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Zwróć uwagę, że pakiet klienta NFS musi być zainstalowany na wszystkich węzłach Kubernetes. W przeciwnym razie Kubernetes nie byłby w stanie poprawnie zamontować NFS. Na wszystkich węzłach:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSUpewnij się również, że na serwerze NFS istnieje katalog docelowy:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressNastępnie utwórz plik o nazwie wordpress-pv-pvc.yml i dodaj następujące wiersze:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: wordpress
tier: frontendW powyższej definicji mówimy Kubernetesowi, aby przydzielił 3 GB przestrzeni woluminu na serwerze NFS dla naszego kontenera Wordpress. Zwróć uwagę na użycie produkcyjne, NFS powinien być skonfigurowany z automatycznym udostępnianiem i klasą pamięci.
Utwórz zasoby PV i PVC:
$ kubectl create -f wordpress-pv-pvc.ymlSprawdź, czy te zasoby zostały utworzone i czy musi mieć status „Związany”:
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hPrzygotowywanie sekretów dla Wordpressa
Utwórz klucz tajny, który będzie używany przez kontener Wordpress dla WORDPRESS_DB_PASSWORD Zmienna środowiskowa. Powodem jest to, że nie chcemy ujawniać hasła w postaci zwykłego tekstu w pliku YAML.
Utwórz tajny zasób o nazwie mysql-pass i odpowiednio przekaż hasło:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdSprawdź, czy nasz sekret został utworzony:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mWdrażanie ProxySQL i Wordpress
Wreszcie możemy rozpocząć wdrażanie. Najpierw wdróż ProxySQL, a następnie Wordpress:
$ kubectl create -f proxysql-rs-svc.yml
$ kubectl create -f wordpress-rs-svc.ymlNastępnie możemy wyświetlić listę wszystkich podów i usług, które zostały utworzone w warstwie „frontend”:
$ kubectl get pods,services -l tier=frontend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
pod/proxysql-95b8d8446-qfbf2 1/1 Running 0 12m 10.36.0.2 kube2.local <none>
pod/proxysql-95b8d8446-vljlr 1/1 Running 0 12m 10.44.0.6 kube3.local <none>
pod/wordpress-59489d57b9-4dzvk 1/1 Running 0 37m 10.36.0.1 kube2.local <none>
pod/wordpress-59489d57b9-7d2jb 1/1 Running 0 30m 10.44.0.4 kube3.local <none>
pod/wordpress-59489d57b9-gw4p9 1/1 Running 0 30m 10.36.0.3 kube2.local <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/proxysql NodePort 10.108.195.54 <none> 6033:30033/TCP,6032:30032/TCP 10m app=proxysql,tier=frontend
service/wordpress NodePort 10.109.144.234 <none> 80:30088/TCP 37m app=wordpress,tier=frontend
kube2.local <none>Powyższe dane wyjściowe weryfikują naszą architekturę wdrożeniową, w której obecnie mamy trzy pody Wordpress, udostępnione publicznie na porcie 30088, a także naszą instancję ProxySQL, która jest uwidoczniona na portach 30033 i 30032 zewnętrznie oraz 6033 i 6032 wewnętrznie.
W tym momencie nasza architektura wygląda mniej więcej tak:
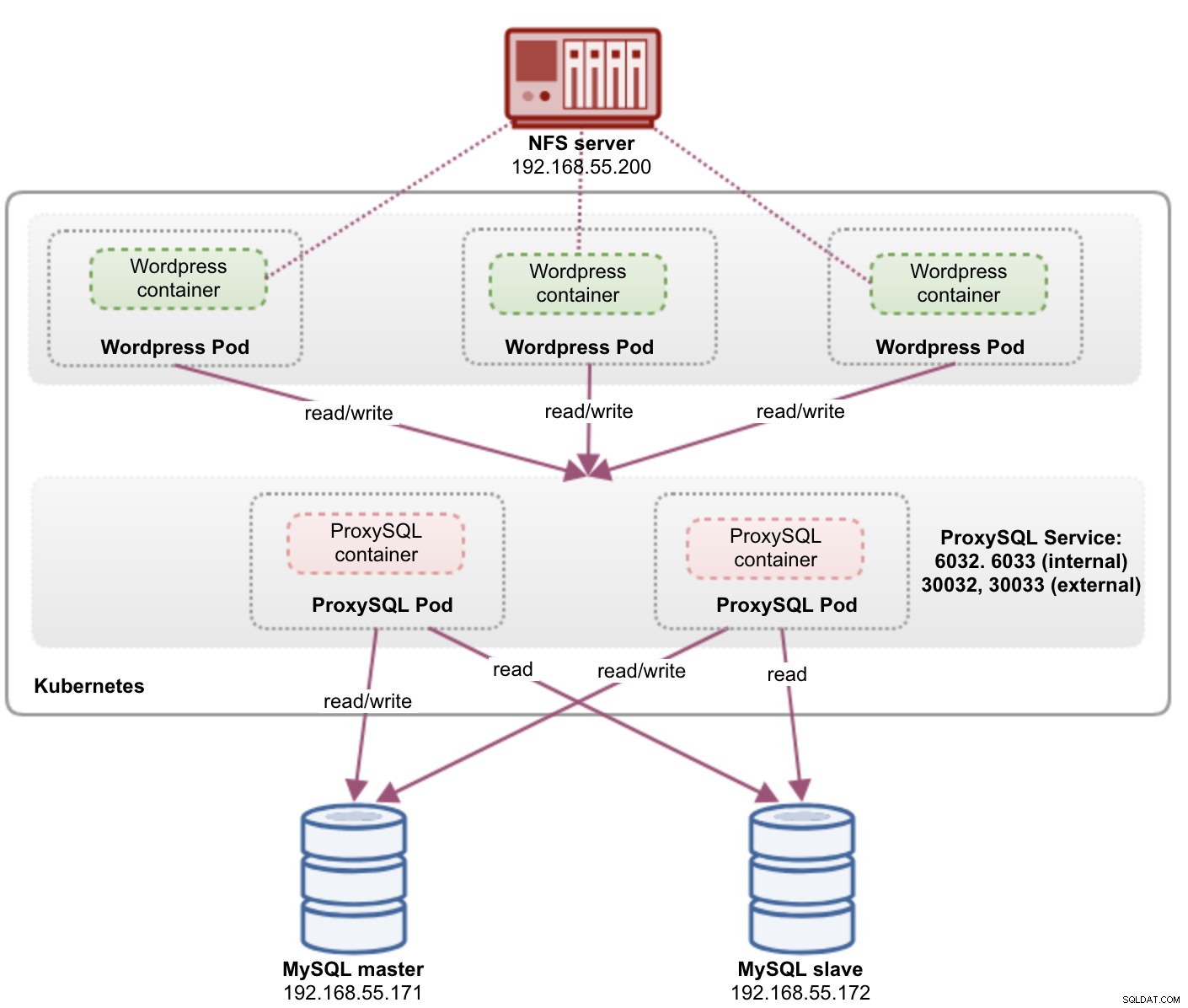
Port 80 opublikowany przez pody Wordpress jest teraz mapowany na świat zewnętrzny przez port 30088. Możemy uzyskać dostęp do naszego wpisu na blogu pod adresem https://{any_kubernetes_host}:30088/ i powinien zostać przekierowany na stronę instalacji Wordpress. Jeśli będziemy kontynuować instalację, pominiemy część dotyczącą połączenia z bazą danych i wyświetlimy bezpośrednio tę stronę:
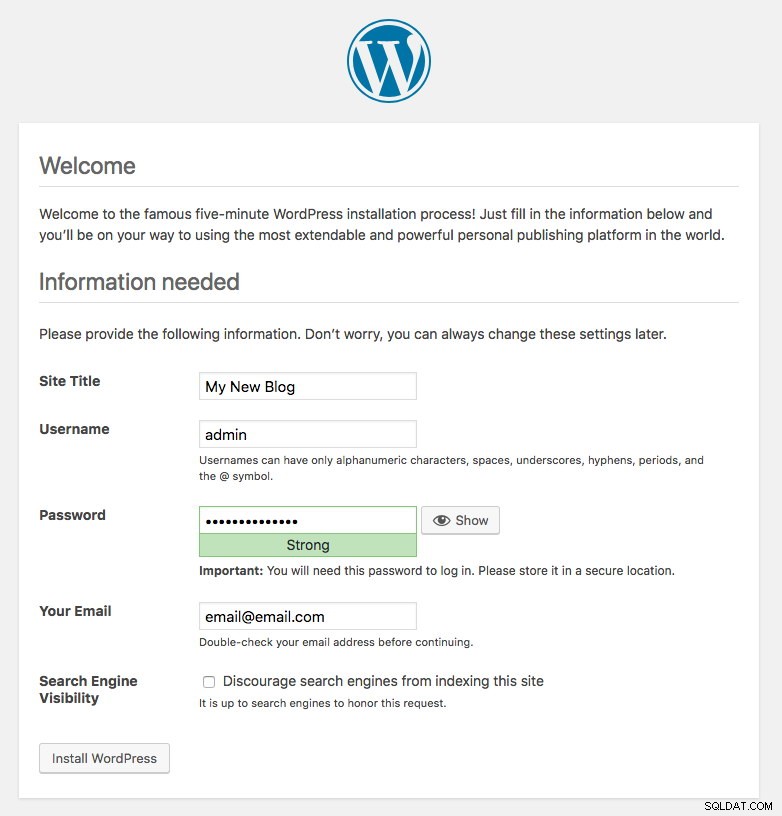
Oznacza to, że nasza konfiguracja MySQL i ProxySQL jest poprawnie skonfigurowana w pliku wp-config.php. W przeciwnym razie zostaniesz przekierowany na stronę konfiguracji bazy danych.
Nasze wdrożenie zostało zakończone.
Pody ProxySQL i zarządzanie usługami
Oczekuje się, że przełączanie awaryjne i odzyskiwanie będą obsługiwane automatycznie przez Kubernetes. Na przykład, jeśli pracownik Kubernetes przestanie działać, pod zostanie odtworzony w następnym dostępnym węźle po --pod-eviction-timeout (domyślnie 5 minut). Jeśli kontener ulegnie awarii lub zostanie zabity, Kubernetes zastąpi go niemal natychmiast.
Oczekuje się, że niektóre typowe zadania zarządzania będą inne podczas uruchamiania w Kubernetes, jak pokazano w następnych sekcjach.
Łączenie z ProxySQL
Chociaż ProxySQL jest udostępniany zewnętrznie na portach 30033 (MySQL) i 30032 (Admin), jest również dostępny wewnętrznie za pośrednictwem opublikowanych portów, odpowiednio 6033 i 6032. Tak więc, aby uzyskać dostęp do instancji ProxySQL w sieci Kubernetes, użyj CLUSTER-IP lub nazwy usługi „proxysql” jako wartości hosta. Na przykład, w ramach programu Wordpress, możesz uzyskać dostęp do konsoli administracyjnej ProxySQL za pomocą następującego polecenia:
$ mysql -uproxysql-admin -p -hproxysql -P6032Jeśli chcesz połączyć się zewnętrznie, użyj portu zdefiniowanego w wartości nodePort dla usługi YAML i wybierz dowolny węzeł Kubernetes jako wartość hosta:
$ mysql -uproxysql-admin -p -hkube3.local -P30032To samo dotyczy połączenia MySQL ze zrównoważonym obciążeniem na porcie 30033 (zewnętrznym) i 6033 (wewnętrznym).
Skalowanie w górę i w dół
Skalowanie w górę jest łatwe dzięki Kubernetes:
$ kubectl scale deployment proxysql --replicas=5
deployment.extensions/proxysql scaledSprawdź stan wdrożenia:
$ kubectl rollout status deployment proxysql
deployment "proxysql" successfully rolled outSkalowanie również jest podobne. Tutaj chcemy przywrócić z 5 do 2 replik:
$ kubectl scale deployment proxysql --replicas=2
deployment.extensions/proxysql scaledMożemy również przyjrzeć się zdarzeniom wdrożenia dla ProxySQL, aby uzyskać lepszy obraz tego, co wydarzyło się w przypadku tego wdrożenia, korzystając z opcji „opisz”:
$ kubectl describe deployment proxysql
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 0
Normal ScalingReplicaSet 7m10s deployment-controller Scaled up replica set proxysql-6c55f647cb to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled down replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled up replica set proxysql-6c55f647cb to 2
Normal ScalingReplicaSet 6m53s deployment-controller Scaled down replica set proxysql-769895fbf7 to 0
Normal ScalingReplicaSet 54s deployment-controller Scaled up replica set proxysql-6c55f647cb to 5
Normal ScalingReplicaSet 21s deployment-controller Scaled down replica set proxysql-6c55f647cb to 2Połączenia z podami będą automatycznie równoważone przez Kubernetes.
Zmiany konfiguracji
Jednym ze sposobów wprowadzania zmian w konfiguracji w naszych zasobnikach ProxySQL jest przechowywanie wersji naszej konfiguracji przy użyciu innej nazwy ConfigMap. Po pierwsze, zmodyfikuj nasz plik konfiguracyjny bezpośrednio za pomocą ulubionego edytora tekstu:
$ vim /root/proxysql.cnfNastępnie załaduj go do Kubernetes ConfigMap pod inną nazwą. W tym przykładzie do nazwy zasobu dołączamy „-v2”:
$ kubectl create configmap proxysql-configmap-v2 --from-file=proxysql.cnfSprawdź, czy ConfigMap jest poprawnie załadowany:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 3d15h
proxysql-configmap-v2 1 19mOtwórz plik wdrożenia ProxySQL, proxysql-rs-svc.yml i zmień następującą linię w sekcji configMap na nową wersję:
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap-v2 #change this lineNastępnie zastosuj zmiany do naszego wdrożenia ProxySQL:
$ kubectl apply -f proxysql-rs-svc.yml
deployment.apps/proxysql configured
service/proxysql configuredZweryfikuj wdrożenie, sprawdzając zdarzenie ReplicaSet przy użyciu flagi „describe”:
$ kubectl describe proxysql
...
Pod Template:
Labels: app=proxysql
tier=frontend
Containers:
proxysql:
Image: severalnines/proxysql:1.4.12
Ports: 6033/TCP, 6032/TCP
Host Ports: 0/TCP, 0/TCP
Environment: <none>
Mounts:
/etc/proxysql.cnf from proxysql-config (rw)
Volumes:
proxysql-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: proxysql-configmap-v2
Optional: false
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: proxysql-769895fbf7 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 53s deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 41s deployment-controller Scaled down replica set proxysql-95b8d8446 to 0Zwróć uwagę na sekcję „Woluminy” z nową nazwą ConfigMap. Możesz również zobaczyć zdarzenia wdrożenia na dole danych wyjściowych. W tym momencie nasza nowa konfiguracja została załadowana do wszystkich podów ProxySQL, w których Kubernetes obniżył ProxySQL ReplicaSet do 0 (zgodnie ze strategią RollingUpdate) i przywrócił je do pożądanego stanu 2 replik.
Ostateczne myśli
Do tego momentu omówiliśmy możliwe podejście do wdrażania ProxySQL w Kubernetes. Uruchamianie ProxySQL z pomocą Kubernetes ConfigMap otwiera nową możliwość klastrowania ProxySQL, gdzie jest nieco inny niż natywna obsługa klastrów wbudowana w ProxySQL.
W nadchodzącym poście w blogu omówimy klastrowanie ProxySQL przy użyciu Kubernetes ConfigMap i jak to zrobić we właściwy sposób. Bądź na bieżąco!