Jeśli Twoja infrastruktura IT działa na AWS, prawdopodobnie słyszałeś o Amazon Relational Database Service (RDS), łatwym sposobie konfiguracji, obsługi i skalowania relacyjnej bazy danych w chmurze. Zapewnia ekonomiczną i skalowalną pojemność, automatyzując czasochłonne zadania administracyjne, takie jak dostarczanie sprzętu, konfiguracja bazy danych, instalowanie poprawek i tworzenie kopii zapasowych. Istnieje wiele ofert silników baz danych dla RDS, takich jak MySQL, MariaDB, PostgreSQL, Microsoft SQL Server i Oracle Server.
ClusterControl 1.7.3 działa podobnie do RDS, ponieważ obsługuje wdrażanie klastrów baz danych, zarządzanie, monitorowanie i skalowanie na platformie AWS. Obsługuje również wiele innych platform chmurowych, takich jak Google Cloud Platform i Microsoft Azure. ClusterControl rozumie topologię bazy danych i jest w stanie wykonać automatyczne odzyskiwanie, zarządzanie topologią i wiele innych zaawansowanych funkcji, aby przejąć kontrolę nad bazą danych.
W tym poście na blogu porównamy czasy automatycznego przełączania awaryjnego dla Amazon Aurora, Amazon RDS dla MySQL oraz konfiguracji MySQL Replication wdrożonej i zarządzanej przez ClusterControl. Rodzaj przełączania awaryjnego, który zamierzamy wykonać, to promocja urządzenia podrzędnego na wypadek awarii urządzenia nadrzędnego. W tym miejscu najbardziej aktualne urządzenie podrzędne przejmuje rolę mastera w klastrze, aby wznowić usługę bazy danych.
Nasz test przełączania awaryjnego
Aby zmierzyć czas przełączania awaryjnego, przeprowadzimy prosty test aktualizacji połączenia MySQL, z pętlą do zliczania stanu instrukcji SQL, które łączą się z pojedynczym punktem końcowym bazy danych. Skrypt wygląda tak:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Powyższy skrypt Bash po prostu łączy się z hostem MySQL i wykonuje aktualizację pojedynczego wiersza z limitem czasu wynoszącym 1 sekundę zarówno dla poleceń klienta Bash, jak i mysql. Parametry związane z limitami czasu są wymagane, abyśmy mogli poprawnie zmierzyć czas przestoju w sekundach, ponieważ klient mysql domyślnie zawsze łączy się ponownie, dopóki nie osiągnie czasu oczekiwania na MySQL. Wcześniej wypełniliśmy testowy zestaw danych następującym poleceniem:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareSkrypt informuje, czy powyższe zapytanie powiodło się (OK) czy nie (Fail). Przykładowe wyjścia są pokazane poniżej.
Przełączanie awaryjne z Amazon RDS dla MySQL
W naszym teście używamy najniższej oferty RDS o następujących specyfikacjach:
- Wersja MySQL:5.7.22
- procesor wirtualny:4
- RAM:16 GB
- Typ pamięci:aprowizowane IOPS (SSD)
- IOPS:1000
- Pamięć:100 Gib
- Replikacja multi-AZ:tak
Po tym, jak Amazon RDS udostępni instancję DB, możesz użyć dowolnej standardowej aplikacji klienckiej lub narzędzia MySQL, aby połączyć się z instancją. W ciągu połączenia określasz adres DNS z punktu końcowego instancji DB jako parametr hosta i określasz numer portu z punktu końcowego instancji DB jako parametr portu.
Zgodnie ze stroną dokumentacji Amazon RDS, w przypadku planowanego lub nieplanowanego wyłączenia instancji DB, Amazon RDS automatycznie przełącza się na replikę rezerwową w innej Strefie Dostępności, jeśli włączono Multi-AZ. Czas potrzebny do zakończenia przełączania awaryjnego zależy od aktywności bazy danych i innych warunków w momencie, gdy podstawowa instancja bazy danych stała się niedostępna. Czasy przełączania awaryjnego wynoszą zazwyczaj 60-120 sekund.
Aby zainicjować przełączanie awaryjne multi-AZ w RDS, wykonaliśmy operację ponownego uruchomienia z zaznaczoną opcją „Uruchom ponownie z przełączaniem awaryjnym”, jak pokazano na poniższym zrzucie ekranu:
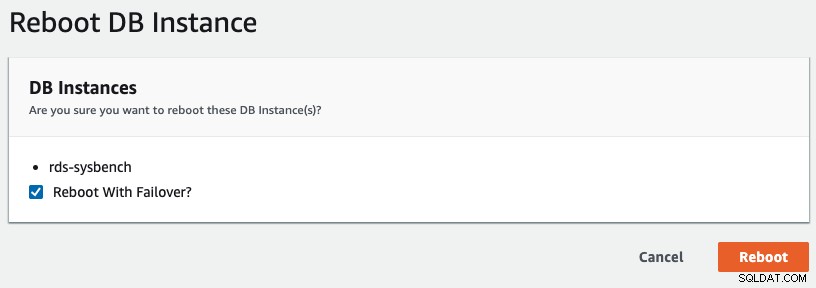
Nasza aplikacja obserwuje następujące rzeczy:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Przestój MySQL widziany po stronie aplikacji rozpoczął się od 03:41:09 do 03:41:36, czyli łącznie około 27 sekund. Na podstawie zdarzeń RDS widzimy, że przełączanie awaryjne multi-AZ miało miejsce dopiero 15 sekund po rzeczywistym przestoju:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Po ponownym uruchomieniu nowej instancji bazy danych około 03:41:33 usługa MySQL była dostępna około 3 sekundy później.
Przełączanie awaryjne z Amazon Aurora dla MySQL
Amazon Aurora można uznać za lepszą wersję RDS, z wieloma godnymi uwagi funkcjami, takimi jak szybsza replikacja ze współużytkowaną pamięcią masową, brak utraty danych podczas przełączania awaryjnego i do 64 TB limitu pamięci. Amazon Aurora dla MySQL jest oparty na open source MySQL Edition, ale sam w sobie nie jest open source; jest to zastrzeżona baza danych o zamkniętym kodzie źródłowym. Działa podobnie z replikacją MySQL (jeden i tylko jeden master, z wieloma slave), a przełączanie awaryjne jest automatycznie obsługiwane przez Amazon Aurora.
Zgodnie z często zadawanymi pytaniami dotyczącymi Amazon Aurora, jeśli masz replikę Amazon Aurora w tej samej lub innej strefie dostępności, podczas przełączania awaryjnego Aurora odwraca rekord nazwy kanonicznej (CNAME) dla instancji bazy danych, aby wskazywał zdrową replikę, która znajduje się w turn jest promowany, aby stać się nowym podstawowym. Od początku do końca, przełączanie awaryjne zwykle kończy się w ciągu 30 sekund.
Jeśli nie masz repliki Amazon Aurora (tj. pojedynczej instancji), Aurora najpierw spróbuje utworzyć nową instancję DB w tej samej strefie dostępności, co instancja oryginalna. Jeśli nie możesz tego zrobić, Aurora spróbuje utworzyć nową instancję DB w innej Strefie Dostępności. Od początku do końca przełączanie awaryjne zwykle trwa niecałe 15 minut.
Twoja aplikacja powinna ponowić próbę połączenia z bazą danych w przypadku utraty połączenia.
Po tym, jak Amazon Aurora zainicjuje twoją instancję DB, otrzymasz dwa punkty końcowe, jeden dla pisarza i jeden dla czytnika. Punkt końcowy czytnika zapewnia obsługę równoważenia obciążenia dla połączeń tylko do odczytu z klastrem DB. Następujące punkty końcowe są pobierane z naszej konfiguracji testowej:
- autor - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- czytnik - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
W naszym teście użyliśmy następujących specyfikacji Aurora:
- Typ instancji:db.r5.large
- Wersja MySQL:5.7.12
- procesor wirtualny:2
- RAM:16 GB
- Replikacja multi-AZ:tak
Aby wyzwolić przełączenie awaryjne, po prostu wybierz instancję zapisującą -> Akcje -> Przełączenie awaryjne, jak pokazano na poniższym zrzucie ekranu:
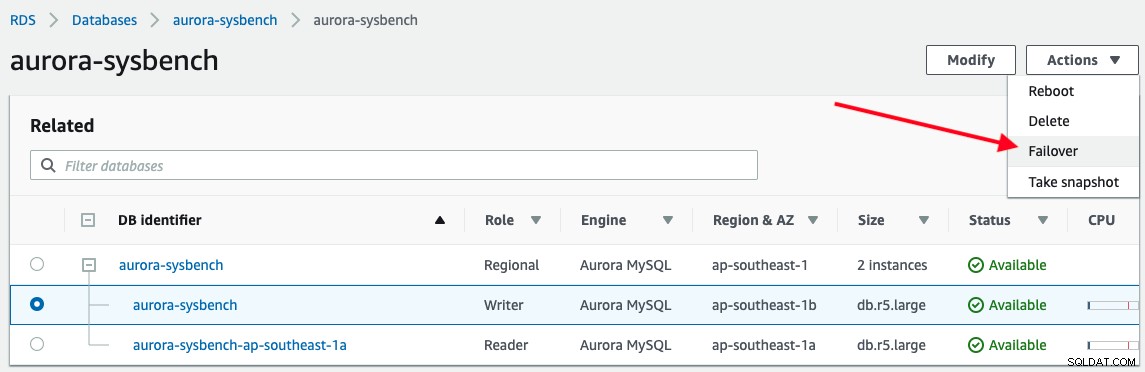
Poniższe dane wyjściowe są zgłaszane przez naszą aplikację podczas łączenia się z punktem końcowym programu Aurora writer :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Przestój bazy danych rozpoczął się od 12:35:49 do 12:35:56 z łączną ilością 7 sekund. To imponujące.
Patrząc na zdarzenie bazy danych z konsoli zarządzania Aurora, miały miejsce tylko te dwa zdarzenia:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedAurora szybko awansuje niewolnika na pana, a zdegraduje go na niewolnika. Zwróć uwagę, że wszystkie repliki Aurora współdzielą ten sam podstawowy wolumin z instancją podstawową, co oznacza, że replikację można przeprowadzić w ciągu milisekund, ponieważ aktualizacje wykonane przez instancję podstawową są natychmiast dostępne dla wszystkich replik Aurora. Dlatego ma minimalne opóźnienie replikacji (Amazon twierdził, że wynosi 100 milisekund i mniej). To znacznie skróci czas kontroli stanu i znacznie skróci czas regeneracji.
Przełączanie awaryjne z ClusterControl
W tym przykładzie naśladujemy podobną konfigurację z Amazon RDS, używając instancji m5.xlarge, z ProxySQL pomiędzy nimi, aby zautomatyzować przełączanie awaryjne z aplikacji przy użyciu pojedynczego dostępu do punktu końcowego, podobnie jak RDS. Poniższy diagram ilustruje naszą architekturę:
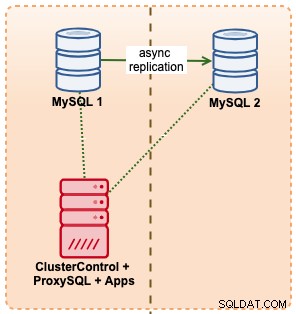
Ponieważ mamy bezpośredni dostęp do instancji bazy danych, uruchomilibyśmy automatyczne przełączanie awaryjne, po prostu zabijając proces MySQL na aktywnym wzorcu:
$ kill -9 $(pidof mysqld)Powyższe polecenie wywołało automatyczne odzyskiwanie w ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Z punktu widzenia naszej aplikacji testowej przestój nastąpił w następującym czasie podczas łączenia się z portem 6033 hosta ProxySQL:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Analizując zarówno zdarzenia zadania odzyskiwania, jak i dane wyjściowe z naszej aplikacji, węzeł bazy danych MySQL nie działał 4 sekundy przed rozpoczęciem zadania odzyskiwania klastra, od 11:08:28 do 11:08:39, z całkowitym przestojem MySQL wynoszącym 11 sekund . Jedną z najbardziej imponujących rzeczy w ClusterControl jest to, że możesz śledzić postęp odzyskiwania na podstawie działań podejmowanych i wykonywanych przez ClusterControl podczas przełączania awaryjnego. Zapewnia poziom przejrzystości, którego nie będziesz w stanie uzyskać w przypadku jakichkolwiek ofert baz danych oferowanych przez dostawców chmury.
W przypadku replikacji MySQL/MariaDB/PostgreSQL, ClusterControl pozwala na bardziej precyzyjne przetwarzanie baz danych dzięki obsłudze następujących zaawansowanych konfiguracji i parametrów:
- Zarządzanie topologią replikacji master-master
- Zarządzanie topologią replikacji łańcucha
- Przeglądarka topologii
- Niewolnicy na białej/czarnej liście, którzy mają być promowani jako mistrzowie
- Sprawdzanie błędnych transakcji
- Przechwytywanie zdarzeń przed/po, sukces/porażka w przypadku awarii/przełączania za pomocą zewnętrznego skryptu
- Automatyczna odbudowa urządzenia podrzędnego w przypadku błędu
- Skaluj urządzenie podrzędne z istniejącej kopii zapasowej
Podsumowanie czasu przełączania awaryjnego
Pod względem czasu przełączania awaryjnego, Amazon RDS Aurora dla MySQL jest wyraźnym zwycięzcą z 7 sekundami , a następnie ClusterControl 11 sekund i Amazon RDS dla MySQL z 27 sekundami .
Zauważ, że jest to tylko prosty test, z jednym klientem i jedną transakcją na sekundę, aby zmierzyć najszybszy czas odzyskiwania. Duże transakcje lub długi proces przywracania mogą wydłużyć czas przełączania awaryjnego, np. długotrwałe transakcje mogą zająć dużo czasu przy zamykaniu MySQL.



