Typowym scenariuszem w wielu aplikacjach klient-serwer jest umożliwienie użytkownikowi końcowemu dyktowania kolejności sortowania wyników. Niektórzy chcą najpierw zobaczyć przedmioty o najniższej cenie, niektórzy chcą najpierw zobaczyć najnowsze przedmioty, a niektórzy chcą je zobaczyć w kolejności alfabetycznej. Jest to złożona rzecz do osiągnięcia w Transact-SQL, ponieważ nie można po prostu powiedzieć:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN ... ORDER BY @SortColumn; -- lub ... ORDER BY @SortColumn @SortDirection;ENDGO
Dzieje się tak, ponieważ T-SQL nie zezwala na zmienne w tych lokalizacjach. Jeśli użyjesz tylko @SortColumn, otrzymasz:
Msg 1008, Level 16, State 1, Line xPozycja SELECT identyfikowana przez ORDER BY numer 1 zawiera zmienną jako część wyrażenia identyfikującego pozycję kolumny. Zmienne są dozwolone tylko w przypadku porządkowania według wyrażenia odwołującego się do nazwy kolumny.
(A kiedy komunikat o błędzie mówi „wyrażenie odwołujące się do nazwy kolumny”, może się to okazać niejednoznaczne i zgadzam się. Ale mogę cię zapewnić, że nie oznacza to, że zmienna jest odpowiednim wyrażeniem).
Jeśli spróbujesz dołączyć @SortDirection, komunikat o błędzie jest nieco bardziej nieprzejrzysty:
Msg 102, Poziom 15, Stan 1, Wiersz xNieprawidłowa składnia w pobliżu „@SortDirection”.
Jest kilka sposobów na obejście tego, a twoim pierwszym odruchem może być użycie dynamicznego SQL lub wprowadzenie wyrażenia CASE. Ale jak w przypadku większości rzeczy, istnieją komplikacje, które mogą zmusić cię do podążania tą czy inną ścieżką. Więc którego powinieneś użyć? Przyjrzyjmy się, jak te rozwiązania mogą działać, i porównajmy ich wpływ na wydajność dla kilku różnych podejść.
Przykładowe dane
Korzystając z widoku katalogu, który chyba wszyscy rozumiemy całkiem dobrze, sys.all_objects, stworzyłem następującą tabelę w oparciu o sprzężenie krzyżowe, ograniczając tabelę do 100 000 wierszy (chciałem danych, które wypełniają wiele stron, ale to nie zajęło dużo czasu na zapytanie i test):
CREATE DATABASE OrderBy;GOUSE OrderBy;GO SELECT TOP (100000) key_col =ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- BIGINT z indeksem klastrowym s1.[object_id], -- INT bez an index name =s1.name -- NVARCHAR z pomocniczym indeksem COLLATE SQL_Latin1_General_CP1_CI_AS, type_desc =s1.type_desc -- NVARCHAR(60) bez indeksu COLLATE SQL_Latin1_General_CP1_CI_AS, s1.modify_date -- datetimedbo FROMINTO sys.all_objects JAKO s1 KRZYŻ DOŁĄCZ sys.all_objects JAKO s2ORDER BY s1.[object_id];
(Sztuczka COLLATE polega na tym, że wiele widoków katalogu ma różne kolumny z różnymi sortowaniami, co zapewnia, że obie kolumny będą pasować do celów tej demonstracji.)
Następnie utworzyłem typową parę indeksów klastrowany/nieklastrowy, która może istnieć w takiej tabeli, przed optymalizacją (nie mogę użyć identyfikatora_obiektu dla klucza, ponieważ sprzężenie krzyżowe tworzy duplikaty):
UTWÓRZ UNIKALNY SKLASTROWANY INDEKS key_col NA dbo.sys_objects(key_col); CREATE INDEX nazwa ON dbo.sys_objects(name);
Przypadki użycia
Jak wspomniano powyżej, użytkownicy mogą chcieć zobaczyć te dane uporządkowane na różne sposoby, więc określmy kilka typowych przypadków użycia, które chcemy wspierać (i przez wsparcie mam na myśli zademonstrowanie):
- Uporządkowane według key_col rosnąco ** domyślnie, jeśli użytkownika to nie obchodzi
- Uporządkowane według object_id (rosnąco/malejąco)
- Uporządkowane według nazwy (rosnąco/malejąco)
- Uporządkowane według type_desc (rosnąco/malejąco)
- Posortowane według daty modyfikacji (rosnąco/malejąco)
Pozostawimy kolejność key_col jako domyślną, ponieważ powinna być najbardziej wydajna, jeśli użytkownik nie ma preferencji; ponieważ key_col jest arbitralnym odpowiednikiem, który nie powinien nic znaczyć dla użytkownika (i może nawet nie być dla niego widoczny), nie ma powodu, aby zezwalać na sortowanie wsteczne w tej kolumnie.
Podejścia, które nie działają
Najczęstszym podejściem, które widzę, gdy ktoś po raz pierwszy zaczyna rozwiązywać ten problem, jest wprowadzenie do zapytania logiki kontroli przepływu. Oczekują, że będą w stanie to zrobić:
SELECT key_col, [object_id], name, type_desc, mod_dateFROM dbo.sys_objectsORDER BY IF @SortColumn ='key_col' key_colIF @SortColumn ='object_id' [object_id]IF @SortColumn ='nazwa' kierunek...IF @SortColumn ='nazwa' =„ASC” ASCELSE DESC;
To oczywiście nie działa. Następnie widzę, że CASE został wprowadzony niepoprawnie, używając podobnej składni:
SELECT key_col, [object_id], name, type_desc, mod_dateFROM dbo.sys_objectsORDER BY CASE @ SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] WHEN 'name' THEN name ... END CASE @ „ASC” NASTĘPNIE ASC ELSE DESC END;
To jest bliżej, ale nie udaje się z dwóch powodów. Jednym z nich jest to, że CASE to wyrażenie, które zwraca dokładnie jedną wartość określonego typu danych; łączy to typy danych, które są niezgodne, a zatem przerywa wyrażenie CASE. Drugim jest to, że nie ma możliwości warunkowego zastosowania w ten sposób kierunku sortowania bez użycia dynamicznego SQL.
Podejścia, które działają
Trzy główne podejścia, które widziałem, są następujące:
Grupuj zgodne typy i wskazówki razem
Aby używać CASE z ORDER BY, musi istnieć odrębne wyrażenie dla każdej kombinacji zgodnych typów i kierunków. W tym przypadku musielibyśmy użyć czegoś takiego:
CREATE PROCEDURE dbo.Sort_CaseExpanded @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN USTAW NOCOUNT ON; SELECT key_col, [object_id], name, type_desc, modyfikacji_date FROM dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] . SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] END END DESC, CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'name' THEN_type name WHEN type_desc END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'name' THEN name WHEN 'type_desc' THEN type_desc END END DESC, CASE WHEN @SortColumn ='modify_date' AND @SortdateC'END ='AS , PRZYPADEK GDY @SortColumn ='modify_date' AND @SortDirection ='DESC' THEN modyfikuj_data END DESC;END
Możesz powiedzieć, wow, to brzydki kawałek kodu, i zgodziłbym się z tobą. Myślę, że właśnie dlatego wiele osób buforuje swoje dane na interfejsie użytkownika i pozwala warstwie prezentacji zająć się żonglowaniem nimi w różnych kolejnościach. :-)
Możesz nieco zwinąć tę logikę, konwertując wszystkie typy niełańcuchowe na łańcuchy, które będą poprawnie sortować, np.
CREATE PROCEDURE dbo.Sort_CaseCollapsed @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN USTAW NOCOUNT ON; SELECT key_col, [object_id], name, type_desc, modyfikacji_date FROM dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col'), 12) WHEN object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([object_id]), 24) WHEN 'nazwa' THEN nazwa WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), data_modyfikacji, 120) END END, CASE WEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN RIGHT(' 000000000000' + RTRIM(key_col), 12) WHEN 'object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23 ) + RTRIM([object_id]), 24) KIEDY 'nazwa' TO nazwa KIEDY 'type_desc' THEN type_desc KIEDY 'modify_date' THEN CONVERT(CHAR(19), zmiana_data, 120) END END DESC;END Mimo to jest to dość brzydki bałagan i musisz powtórzyć wyrażenia dwukrotnie, aby poradzić sobie z różnymi kierunkami sortowania. Podejrzewam również, że użycie OPTION RECOMPILE w tym zapytaniu zapobiegłoby ukąszeniu przez podsłuchiwanie parametrów. Z wyjątkiem przypadku domyślnego, nie jest tak, że większość wykonywanej tutaj pracy będzie kompilacją.
Zastosuj rangę za pomocą funkcji okna
Odkryłem tę fajną sztuczkę od AndriyM, chociaż jest ona najbardziej użyteczna w przypadkach, gdy wszystkie potencjalne kolumny porządkowe są zgodnego typu, w przeciwnym razie wyrażenie użyte dla ROW_NUMBER() jest równie złożone. Najbardziej sprytną częścią jest to, że aby przełączać się między porządkiem rosnącym i malejącym, po prostu mnożymy ROW_NUMBER() przez 1 lub -1. Możemy to zastosować w tej sytuacji w następujący sposób:
CREATE PROCEDURE dbo.Sort_RowNumber @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON;;WITH x AS ( SELECT key_col, [object_id], name, type_desc, mod_date, rn =ROW_NUMBER() OVER ( ORDER BY CASE @SortColumn WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12) WHEN ' object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([object_id]), 24) WHEN 'nazwa' THEN nazwa WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), modyfikacja_data, 120) END) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END FROM dbo.sys_objects ) SELECT key_col , [identyfikator_obiektu], nazwa, typ_opis, data_modyfikacji FROM x ORDER BY rn;ENDGO Tutaj ponownie może pomóc OPTION RECOMPILE. Ponadto możesz zauważyć, że w niektórych z tych przypadków powiązania są obsługiwane inaczej przez różne plany — na przykład podczas zamawiania według nazwy zwykle zobaczysz, że key_col przechodzi w kolejności rosnącej w każdym zestawie zduplikowanych nazw, ale możesz również zobaczyć wartości się pomieszały. Aby zapewnić bardziej przewidywalne zachowanie w przypadku remisów, zawsze możesz dodać dodatkową klauzulę ORDER BY. Zauważ, że jeśli chcesz dodać key_col do pierwszego przykładu, musisz zrobić z niego wyrażenie, aby key_col nie było dwukrotnie wymienione w ORDER BY (możesz to zrobić na przykład za pomocą key_col + 0).
Dynamiczny SQL
Wiele osób ma zastrzeżenia do dynamicznego SQL – nie da się go odczytać, jest pożywką dla SQL injection, prowadzi do planowania rozrostu pamięci podręcznej, niweczy cel stosowania procedur składowanych… Niektóre z nich są po prostu nieprawdziwe, a niektóre z nich są łatwe do złagodzenia. Dodałem tutaj pewną walidację, którą można równie łatwo dodać do dowolnej z powyższych procedur:
CREATE PROCEDURE dbo.Sort_DynamicSQL @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; -- odrzuć wszelkie nieprawidłowe kierunki sortowania:IF UPPER(@SortDirection) NOT IN ('ASC','DESC') BEGIN RAISERROR('Nieprawidłowy parametr dla @SortDirection:%s', 11, 1, @SortDirection); POWRÓT -1; END -- odrzuć wszelkie nieoczekiwane nazwy kolumn:IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date') BEGIN RAISERROR('Nieprawidłowy parametr dla @SortColumn:%s', 11, 1, @SortColumn); POWRÓT -1; KONIEC ZESTAWU @SortColumn =NAZWA WYCENA(@SortColumn); ZADEKLARUJ @ sql NVARCHAR(MAX); SET @sql =N'SELECT key_col, [object_id], name, type_desc, modyfikacji_date FROM dbo.sys_objects ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';'; EXEC sp_executesql @sql;END Porównania wydajności
Dla każdej powyższej procedury utworzyłem opakowującą procedurę składowaną, aby móc łatwo przetestować wszystkie scenariusze. Cztery procedury opakowujące wyglądają tak, oczywiście z inną nazwą procedury:
UTWÓRZ PROCEDURĘ dbo.Test_Sort_CaseExpandedASBEGIN USTAW NR WŁ.; EXEC dbo.Sort_CaseExpanded; -- domyślnie EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'nazwa','DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date','ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC';END
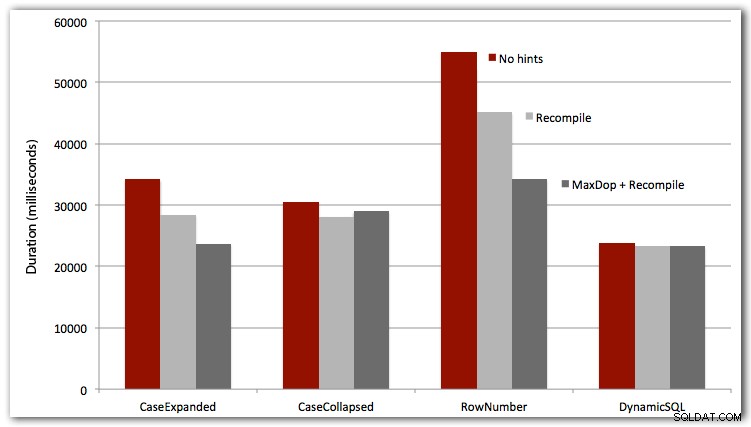
Następnie za pomocą SQL Sentry Plan Explorer wygenerowałem rzeczywiste plany wykonania (i powiązane z nimi metryki) z następującymi zapytaniami i powtórzyłem proces 10 razy, aby podsumować całkowity czas trwania:
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;EXEC dbo.Test_Sort_CaseExpanded;--EXEC dbo.Test_Sort_CaseCollapsed;--EXEC dbo.Test_Sort_RowNumber;--EXEC dbo.Test_Sort_Dynamic>SQL;Przetestowałem również pierwsze trzy przypadki z OPTION RECOMPILE (nie ma to większego sensu w przypadku dynamicznego SQL, ponieważ wiemy, że za każdym razem będzie to nowy plan), a wszystkie cztery przypadki z MAXDOP 1, aby wyeliminować zakłócenia równoległości. Oto wyniki:
Wniosek
Aby uzyskać całkowitą wydajność, dynamiczny SQL wygrywa za każdym razem (choć tylko z niewielkim marginesem w tym zestawie danych). Podejście ROW_NUMBER(), choć sprytne, przegrywało w każdym teście (przepraszam AndriyM).
Jeszcze fajniej jest wprowadzić klauzulę WHERE, nie mówiąc już o stronicowaniu. Te trzy są jak idealna burza wprowadzająca złożoność do tego, co zaczyna się jako proste zapytanie wyszukiwania. Im więcej permutacji ma zapytanie, tym bardziej prawdopodobne jest, że zechcesz usunąć czytelność poza okno i użyć dynamicznego SQL w połączeniu z ustawieniem „Optymalizuj pod kątem obciążeń ad hoc”, aby zminimalizować wpływ planów jednorazowego użytku w pamięci podręcznej planu.