Odbyło się wiele dyskusji na temat OLTP w pamięci (funkcja znana wcześniej jako „Hekaton”) i tego, jak może pomóc w bardzo specyficznych, dużych obciążeniach. W trakcie innej rozmowy zauważyłem coś w CREATE TYPE dokumentacja SQL Server 2014, która sprawiła, że pomyślałem, że może istnieć bardziej ogólny przypadek użycia:

Stosunkowo ciche i niezapowiedziane dodatki do dokumentacji CREATE TYPE
Na podstawie diagramu składni wydaje się, że parametry z wartościami tabelarycznymi (TVP) mogą być zoptymalizowane pod kątem pamięci, podobnie jak trwałe tabele. I dzięki temu koła natychmiast zaczęły się obracać.
Jedną z rzeczy, do których używałem TVP, jest pomoc klientom w wyeliminowaniu kosztownych metod dzielenia ciągów w T-SQL lub CLR (patrz tło w poprzednich postach tutaj, tutaj i tutaj). W moich testach użycie zwykłego TVP przewyższyło równoważne wzorce przy użyciu funkcji dzielenia CLR lub T-SQL o znaczny margines (25-50%). Zastanawiałem się logicznie:czy TVP zoptymalizowany pod kątem pamięci przyniesie jakikolwiek wzrost wydajności?
Ogólnie pojawiły się pewne obawy dotyczące OLTP w pamięci, ponieważ istnieje wiele ograniczeń i luk w funkcjach, potrzebna jest osobna grupa plików dla danych zoptymalizowanych pod kątem pamięci, trzeba przenieść całe tabele do zoptymalizowanych pod kątem pamięci, a najlepszą korzyścią jest zazwyczaj osiąga się to również poprzez tworzenie natywnie kompilowanych procedur składowanych (które mają własny zestaw ograniczeń). Jak zademonstruję, zakładając, że typ tabeli zawiera proste struktury danych (np. reprezentujące zbiór liczb całkowitych lub łańcuchów), użycie tej technologii tylko dla TVP eliminuje niektóre tych problemów.
Test
Nadal będziesz potrzebować grupy plików zoptymalizowanej pod kątem pamięci, nawet jeśli nie zamierzasz tworzyć trwałych tabel zoptymalizowanych pod kątem pamięci. Stwórzmy więc nową bazę danych z odpowiednią strukturą:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Teraz możemy utworzyć zwykły typ tabeli, tak jak zrobilibyśmy to dzisiaj, oraz tabelę zoptymalizowaną pod kątem pamięci z nieklastrowanym indeksem mieszającym i liczbą wiader, które wyciągnęłam z powietrza (więcej informacji na temat obliczania wymagań dotyczących pamięci i liczby wiader można znaleźć w prawdziwy świat tutaj):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Jeśli spróbujesz tego w bazie danych, która nie ma grupy plików zoptymalizowanej pod kątem pamięci, otrzymasz ten komunikat o błędzie, tak jak w przypadku próby utworzenia normalnej tabeli zoptymalizowanej pod kątem pamięci:
Msg 41337, poziom 16, stan 0, wiersz 9Grupa plików MEMORY_OPTIMIZED_DATA nie istnieje lub jest pusta. Nie można utworzyć tabel zoptymalizowanych pod kątem pamięci dla bazy danych, dopóki nie ma jednej grupy plików MEMORY_OPTIMIZED_DATA, która nie jest pusta.
Aby przetestować zapytanie względem zwykłej tabeli niezoptymalizowanej pod kątem pamięci, po prostu przeciągnąłem dane do nowej tabeli z przykładowej bazy danych AdventureWorks2012, używając SELECT INTO aby zignorować wszystkie te nieznośne ograniczenia, indeksy i rozszerzone właściwości, a następnie utworzyłem indeks klastrowy w kolumnie, o której wiedziałem, że będę szukać (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
Następnie utworzyłem cztery procedury składowane:dwie dla każdego typu tabeli; każdy przy użyciu EXISTS i JOIN podejścia (zwykle lubię badać oba, chociaż wolę EXISTS; później zobaczysz, dlaczego nie chciałem ograniczać moich testów tylko do EXISTS ). W tym przypadku po prostu przypisuję dowolny wiersz do zmiennej, dzięki czemu mogę zaobserwować dużą liczbę wykonań bez zajmowania się zestawami wyników i innymi danymi wyjściowymi i narzutami:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
Następnie musiałem zasymulować rodzaj zapytania, które zwykle dotyczy tego typu tabeli i wymaga przede wszystkim wzorca TVP lub podobnego. Wyobraź sobie formularz z rozwijanym menu lub zestawem pól wyboru zawierającym listę produktów, a użytkownik może wybrać 20, 50 lub 200, które chce porównać, wymienić, co masz. Wartości nie będą w ładnym, ciągłym zestawie; będą one zazwyczaj rozrzucone po całym miejscu (gdyby był to przewidywalny ciągły zakres, zapytanie byłoby znacznie prostsze:wartości początkowe i końcowe). Więc po prostu wybrałem dowolne 20 wartości z tabeli (próbując pozostać poniżej, powiedzmy, 5% wielkości tabeli), uporządkowanych losowo. Łatwy sposób na zbudowanie wielokrotnego użytku VALUES klauzula taka jest następująca:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; Wyniki (prawie na pewno będą się różnić):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
W przeciwieństwie do bezpośredniego INSERT...SELECT , dzięki temu dość łatwo jest manipulować tymi danymi wyjściowymi w wyrażeniu wielokrotnego użytku, aby wielokrotnie wypełniać nasze TVP tymi samymi wartościami i w wielu iteracjach testowania:
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
Jeśli uruchomimy tę partię za pomocą SQL Sentry Plan Explorer, otrzymane plany pokazują dużą różnicę:TVP w pamięci jest w stanie użyć sprzężenia zagnieżdżonych pętli i 20 jednowierszowych wyszukiwań indeksów klastrowych, w przeciwieństwie do sprzężenia przez scalanie zasilanego 502 wierszami przez klastrowe skanowanie indeksu dla klasycznego TVP. I w tym przypadku EXISTS i JOIN przyniosły identyczne plany. Może to oznaczać znacznie większą liczbę wartości, ale kontynuujmy przy założeniu, że liczba wartości będzie mniejsza niż 5% rozmiaru tabeli:
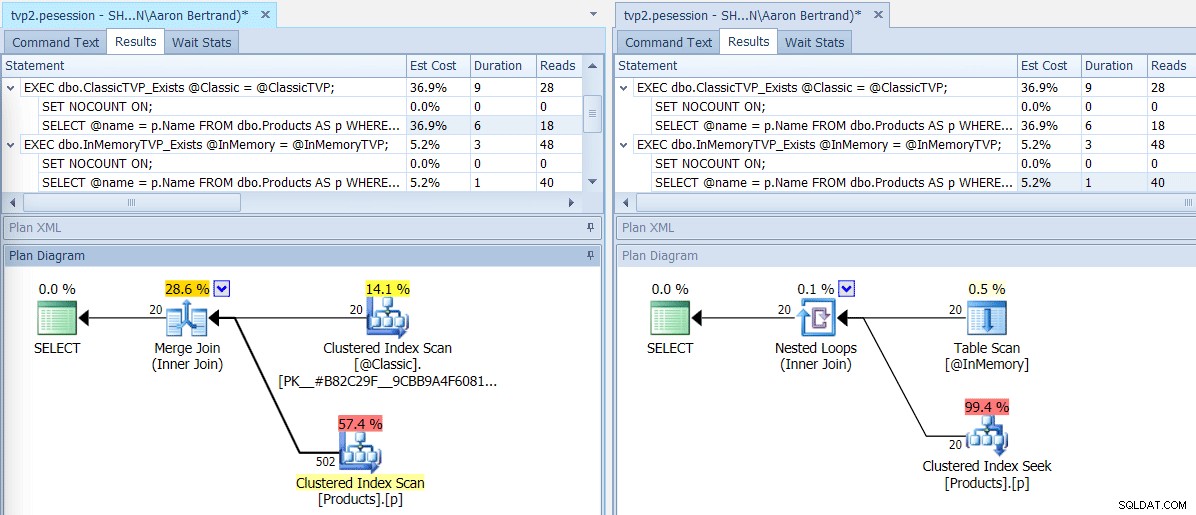 Plany programów telewizyjnych w wersji klasycznej i w pamięci
Plany programów telewizyjnych w wersji klasycznej i w pamięci
 Podpowiedzi dla operatorów skanowania/wyszukiwania, podkreślające główne różnice – Klasyczna po lewej, In- Pamięć po prawej
Podpowiedzi dla operatorów skanowania/wyszukiwania, podkreślające główne różnice – Klasyczna po lewej, In- Pamięć po prawej
Co to oznacza na dużą skalę? Wyłączmy jakąkolwiek kolekcję showplanu i nieznacznie zmieńmy skrypt testowy, aby uruchomić każdą procedurę 100 000 razy, przechwytując skumulowane środowisko wykonawcze ręcznie:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
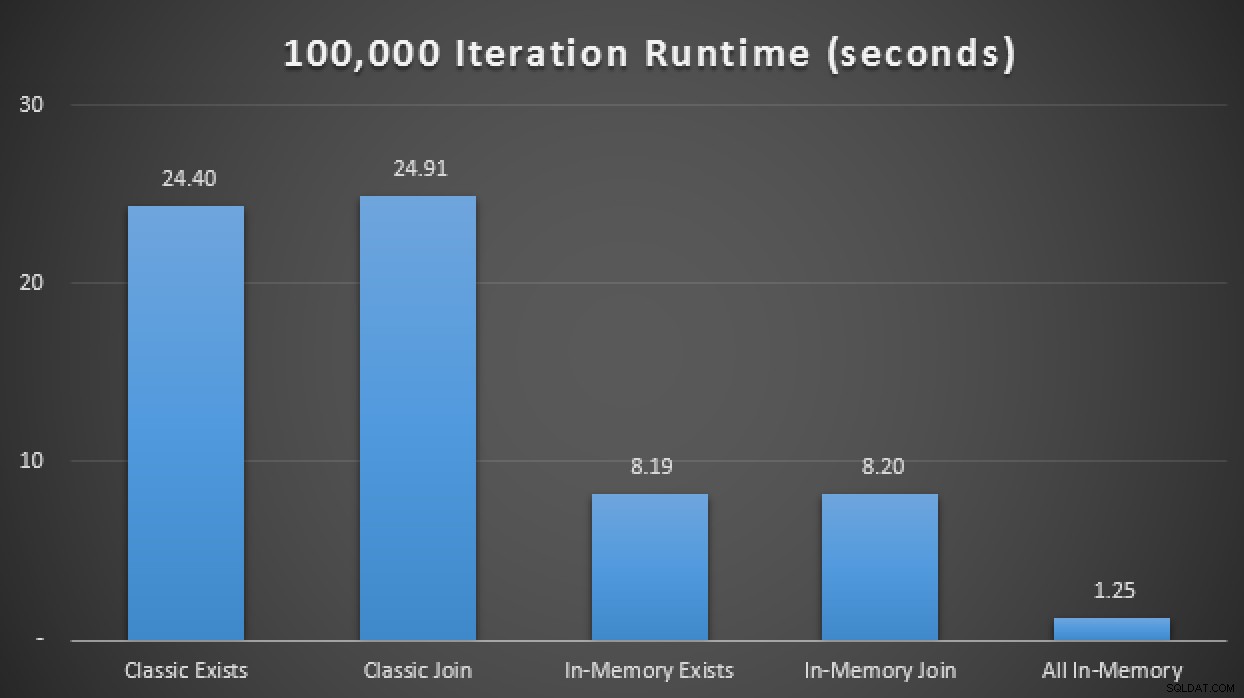
SELECT SYSDATETIME(); W wynikach, uśrednionych dla 10 przebiegów, widzimy, że przynajmniej w tym ograniczonym przypadku testowym użycie typu tabeli zoptymalizowanej pod kątem pamięci przyniosło około 3-krotną poprawę prawdopodobnie najbardziej krytycznej metryki wydajności w OLTP (czasu wykonywania):
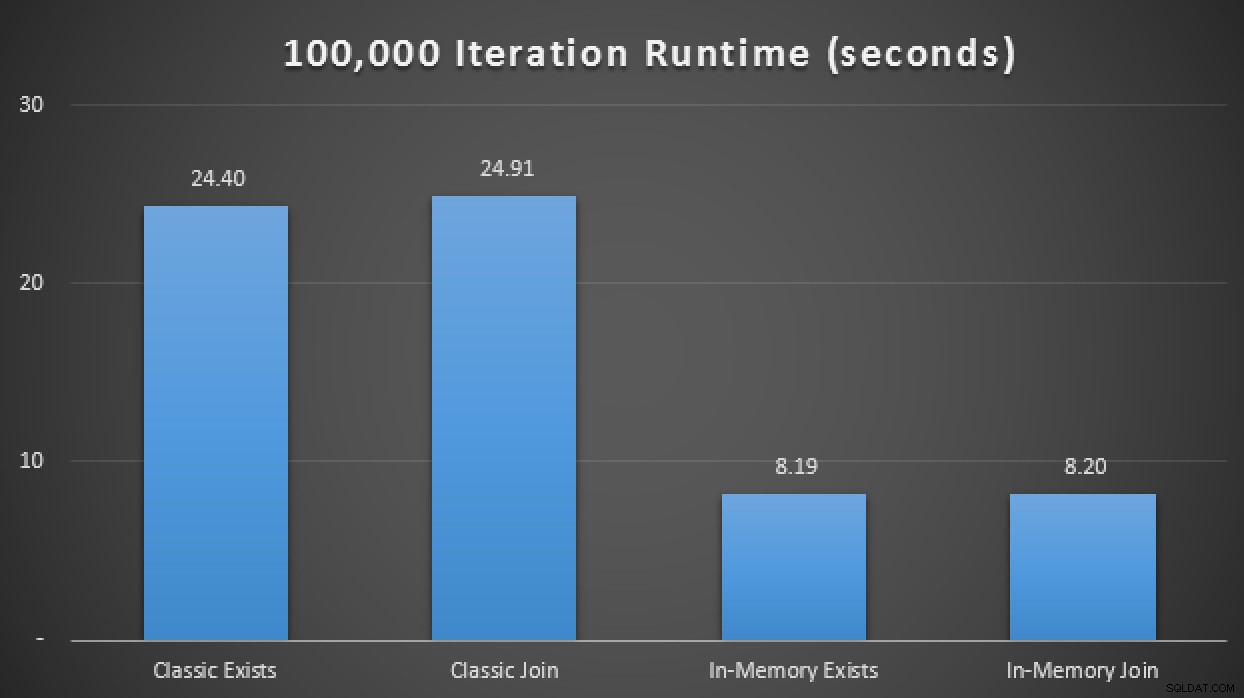
Wyniki w czasie wykonywania wykazują trzykrotną poprawę dzięki programom TVP w pamięci
W pamięci + W pamięci + W pamięci:Inicjacja w pamięci
Teraz, gdy widzieliśmy, co możemy zrobić, po prostu zmieniając zwykły typ tabeli na typ tabeli zoptymalizowany pod kątem pamięci, zobaczmy, czy możemy wycisnąć więcej wydajności z tego samego wzorca zapytania, gdy zastosujemy trifecta:in-memory table, przy użyciu natywnie skompilowanej procedury składowanej zoptymalizowanej pod kątem pamięci, która akceptuje tabelę tabeli w pamięci jako parametr o wartościach przechowywanych w tabeli.
Najpierw musimy utworzyć nową kopię tabeli i wypełnić ją z tabeli lokalnej, którą już utworzyliśmy:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
Następnie tworzymy natywnie skompilowaną procedurę składowaną, która przyjmuje nasz istniejący typ tabeli zoptymalizowany pod kątem pamięci jako TVP:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Kilka zastrzeżeń. Nie możemy użyć zwykłego, niezoptymalizowanego pod kątem pamięci typu tabeli jako parametru do natywnie skompilowanej procedury składowanej. Jeśli spróbujemy, otrzymamy:
Msg 41323, poziom 16, stan 1, procedura InMemoryProcedureTyp tabeli „dbo.ClassicTVP” nie jest typem tabeli zoptymalizowanym pod kątem pamięci i nie może być używany w natywnie skompilowanej procedurze składowanej.
Ponadto nie możemy użyć EXISTS wzór tutaj albo; kiedy próbujemy, otrzymujemy:
Podkwerendy (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Istnieje wiele innych zastrzeżeń i ograniczeń związanych z OLTP w pamięci i natywnie skompilowanymi procedurami składowanymi. Chciałem tylko podzielić się kilkoma rzeczami, których najwyraźniej brakuje w testach.
Dodając tę nową, natywnie skompilowaną procedurę składowaną do powyższej macierzy testowej, odkryłem, że – ponownie, uśredniając 10 przebiegów – wykonała 100 000 iteracji w zaledwie 1,25 sekundy. Oznacza to w przybliżeniu 20-krotną poprawę w stosunku do zwykłych TVP i 6-7-krotną poprawę w stosunku do TVP w pamięci przy użyciu tradycyjnych tabel i procedur:
Wyniki w czasie wykonywania wykazują nawet 20-krotną poprawę dzięki funkcji In-Memory
Wniosek
Jeśli używasz TVP teraz lub używasz wzorców, które mogłyby zostać zastąpione przez TVP, koniecznie musisz rozważyć dodanie zoptymalizowanych pod kątem pamięci TVP do swoich planów testowych, ale pamiętaj, że możesz nie zauważyć takich samych ulepszeń w swoim scenariuszu. (I oczywiście, pamiętając, że ogólnie TVP ma wiele zastrzeżeń i ograniczeń i nie są one również odpowiednie dla wszystkich scenariuszy. Erland Sommarskog ma tutaj świetny artykuł o dzisiejszych TVP.)
W rzeczywistości możesz zauważyć, że na dolnym końcu wolumenu i współbieżności nie ma różnicy – ale przetestuj w realistycznej skali. To był bardzo prosty i wymyślny test na nowoczesnym laptopie z pojedynczym dyskiem SSD, ale kiedy mówimy o rzeczywistej objętości i/lub obrotowych dyskach mechanicznych, te cechy wydajności mogą mieć znacznie większą wagę. W dalszej części pojawią się demonstracje dotyczące większych rozmiarów danych.