W sekcji komentarzy jednego z naszych blogów czytelnik zapytał o wpływ wsrep_slave_threads na wydajność i skalowalność we/wy Galera Cluster. W tamtym czasie nie mogliśmy łatwo odpowiedzieć na to pytanie i utworzyć kopię zapasową większej ilości danych, ale w końcu udało nam się skonfigurować środowisko i przeprowadzić kilka testów.
Nasz czytelnik wskazał na testy porównawcze, które wykazały, że zwiększenie liczby wątków wsrep_slave_threads nie miało żadnego wpływu na wydajność klastra Galera.
Aby wyjaśnić wpływ tego ustawienia, tworzymy mały klaster trzech węzłów (m5d.xlarge). To pozwoliło nam wykorzystać bezpośrednio podłączony dysk SSD nvme dla katalogu danych MySQL. W ten sposób zminimalizowaliśmy ryzyko, że pamięć masowa stanie się wąskim gardłem w naszej konfiguracji.
Ustawiliśmy pulę buforów InnoDB na 8 GB i przerobiliśmy logi do dwóch plików po 1 GB każdy. Zwiększyliśmy również innodb_io_capacity do 2000 i innodb_io_capacity_max do 10000. Miało to również zapewnić, że żadne z tych ustawień nie wpłynie na naszą wydajność.
Cały problem z takimi benchmarkami polega na tym, że wąskich gardeł jest tak wiele, że trzeba je eliminować jeden po drugim. Dopiero po dostrojeniu konfiguracji i upewnieniu się, że sprzęt nie będzie stanowił problemu, można mieć nadzieję, że pojawią się bardziej subtelne ograniczenia.
Wygenerowaliśmy ~90 GB danych za pomocą sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareNastępnie wykonano benchmark. Przetestowaliśmy dwa ustawienia:wsrep_slave_threads=1 i wsrep_slave_threads=16. Sprzęt nie był wystarczająco wydajny, aby jeszcze bardziej zwiększyć tę zmienną. Należy również pamiętać, że nie przeprowadziliśmy szczegółowego testu porównawczego, aby określić, czy wsrep_slave_threads powinno być ustawione na 16, 8, czy może 4 w celu uzyskania najlepszej wydajności. Chcieliśmy zobaczyć, czy możemy pokazać wpływ na klaster. I tak, wpływ był wyraźnie widoczny. Na początek kilka wykresów kontroli przepływu.
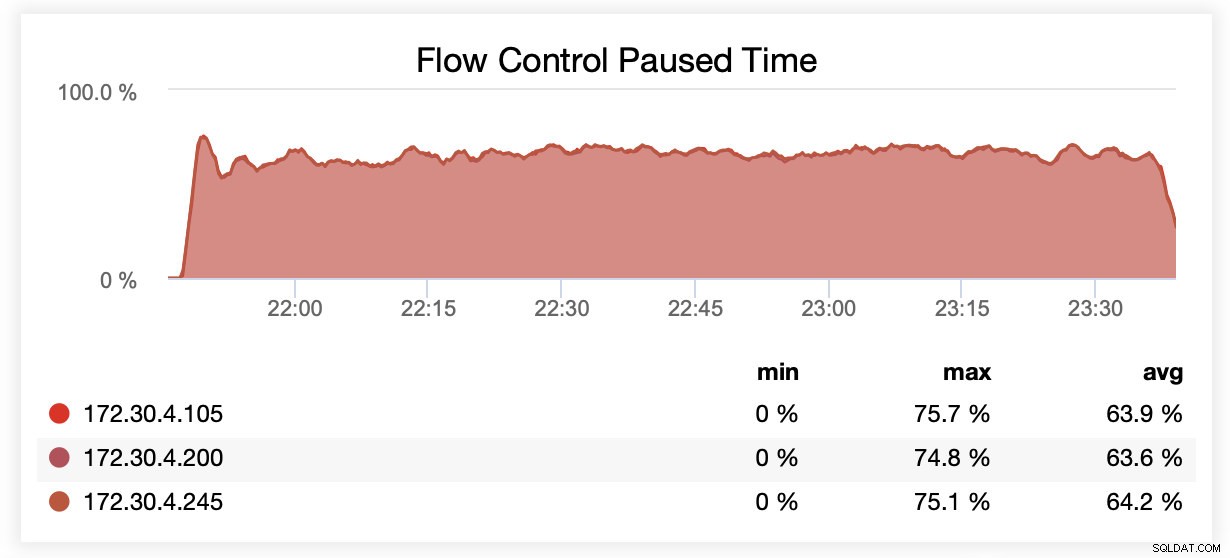
Podczas pracy z wsrep_slave_threads=1 węzły były wstrzymywane średnio przez około 64% czasu ze względu na kontrolę przepływu.
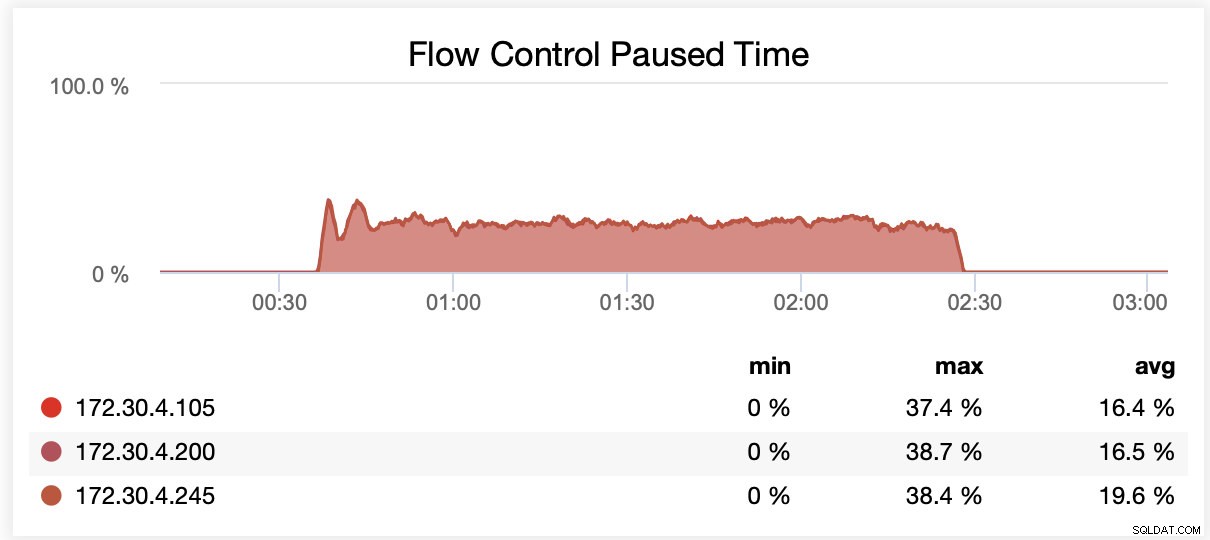
Podczas pracy z wsrep_slave_threads=16 węzły były wstrzymywane średnio przez około 20% czasu z powodu kontroli przepływu.
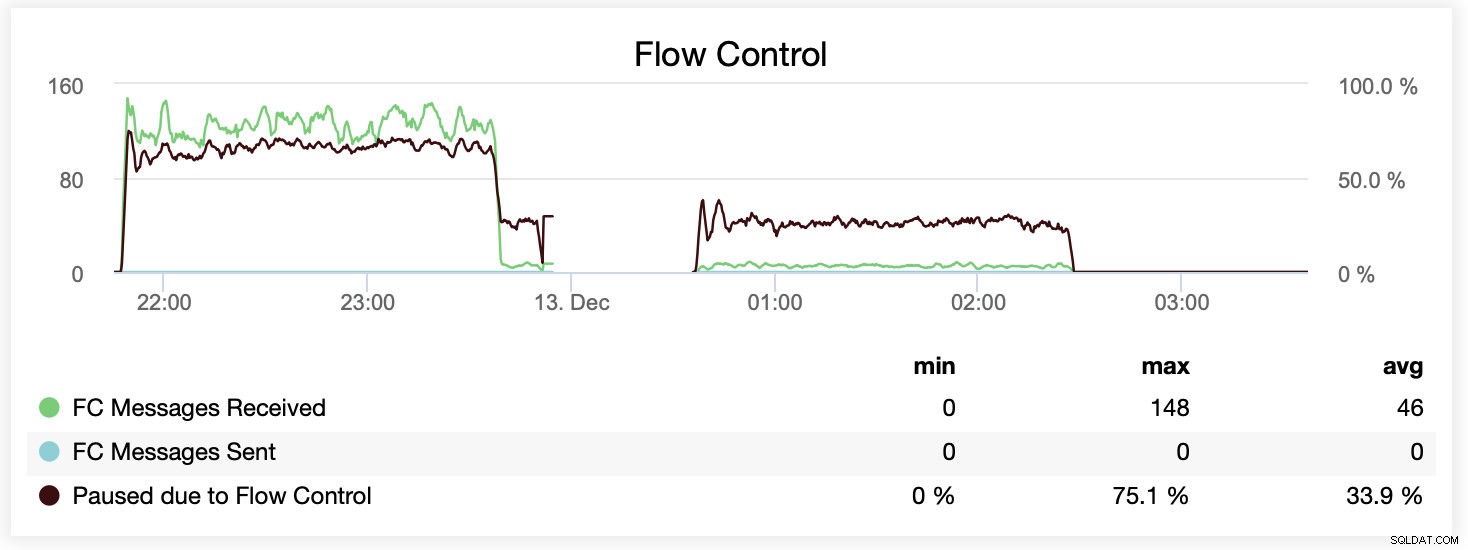
Możesz także porównać różnicę na jednym wykresie. Spadek na końcu pierwszej części to pierwsza próba uruchomienia z wsrep_slave_threads=16. Serwerom zabrakło miejsca na dysku na logi binarne i musieliśmy ponownie uruchomić ten test porównawczy w późniejszym czasie.
Jak przełożyło się to na wydajność? Różnica jest widoczna, choć zdecydowanie nie tak spektakularna.
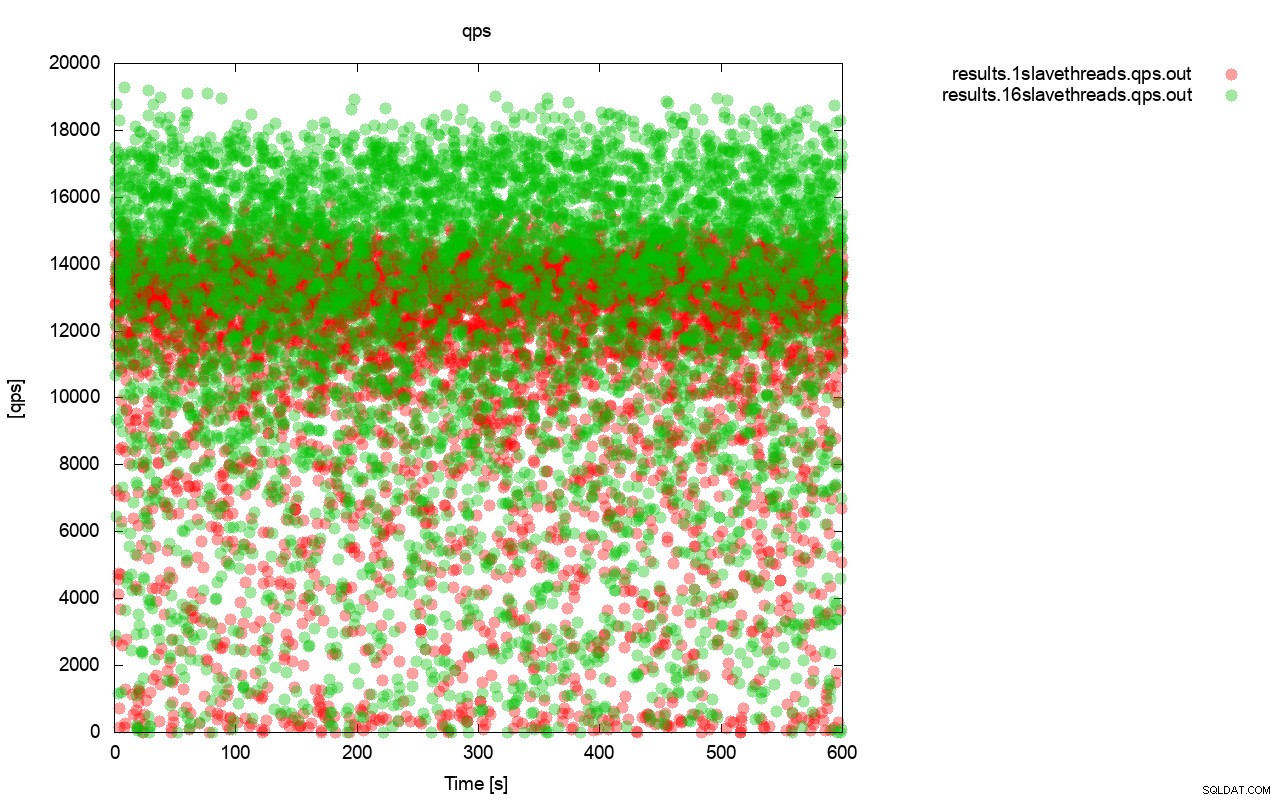
Najpierw wykres zapytań na sekundę. Przede wszystkim można zauważyć, że w obu przypadkach wyniki są wszechobecne. Jest to głównie związane z niestabilną wydajnością pamięci we/wy i losowo uruchamianą kontrolą przepływu. Nadal możesz zobaczyć, że wydajność „czerwonego” wyniku (wsrep_slave_threads=1) jest znacznie niższa niż „zielonego” ( wsrep_slave_threads=16).
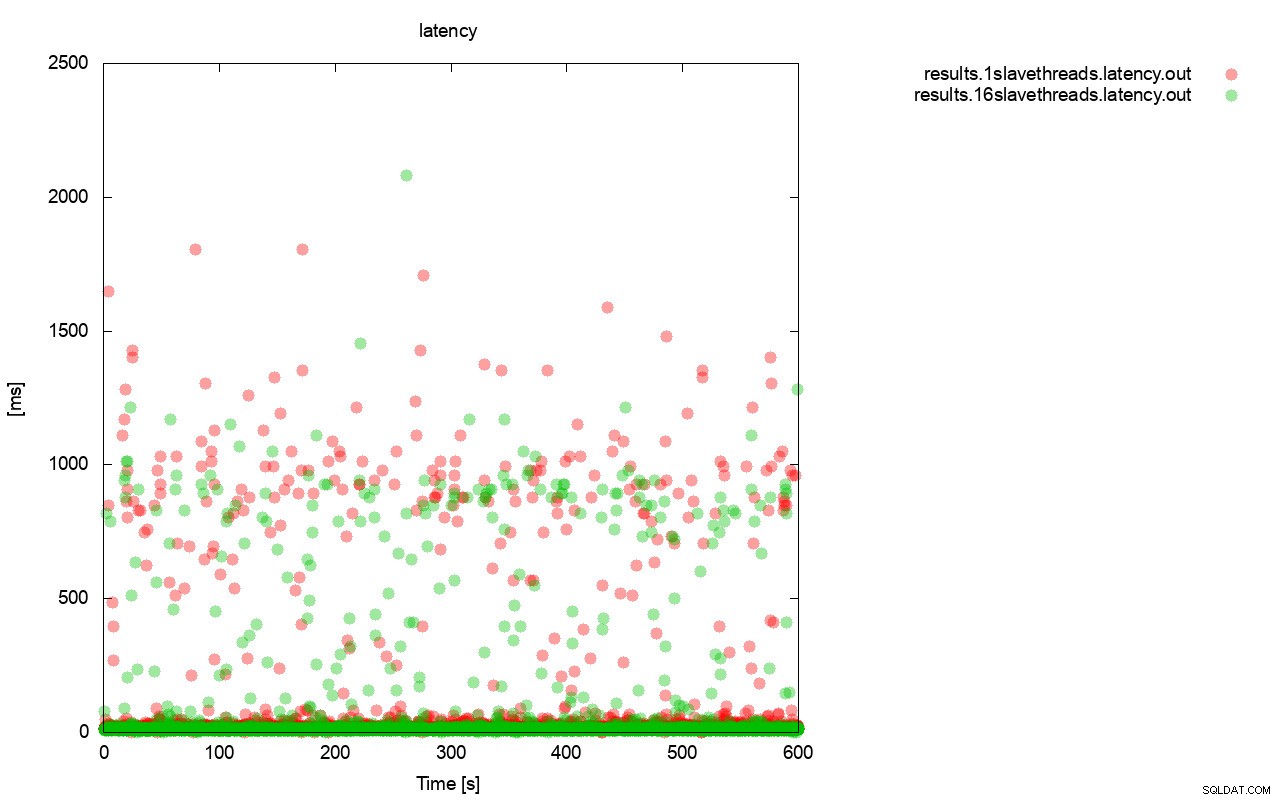
Całkiem podobny obraz jest, gdy spojrzymy na opóźnienie. Możesz zobaczyć więcej (i zazwyczaj głębszych) straganów do biegu z wsrep_slave_thread=1.
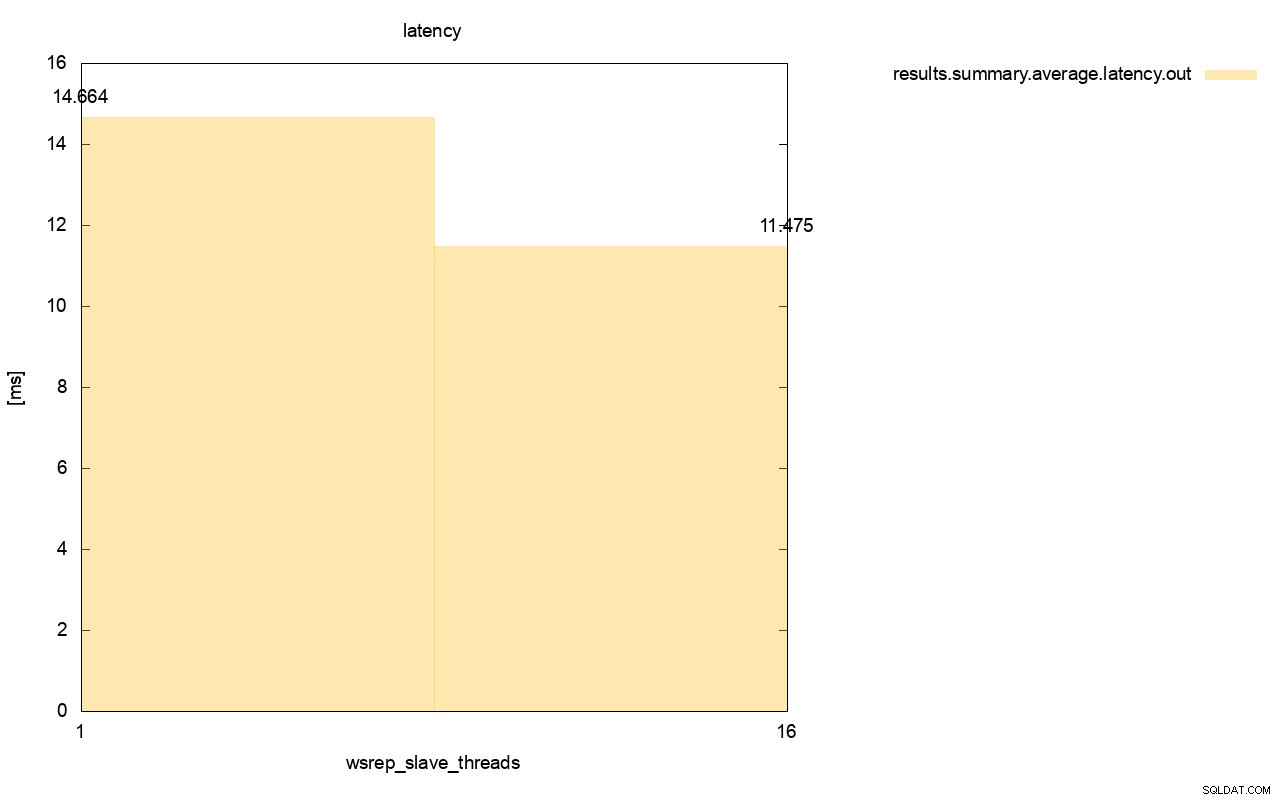
Różnica jest jeszcze bardziej widoczna, gdy obliczyliśmy średnie opóźnienie we wszystkich przebiegach i widać, że opóźnienie wsrep_slave_thread=1 jest o 27% wyższe niż opóźnienie z 16 wątkami podrzędnymi, co oczywiście nie jest dobre, ponieważ chcemy, aby opóźnienie było mniejsze , nie wyżej.
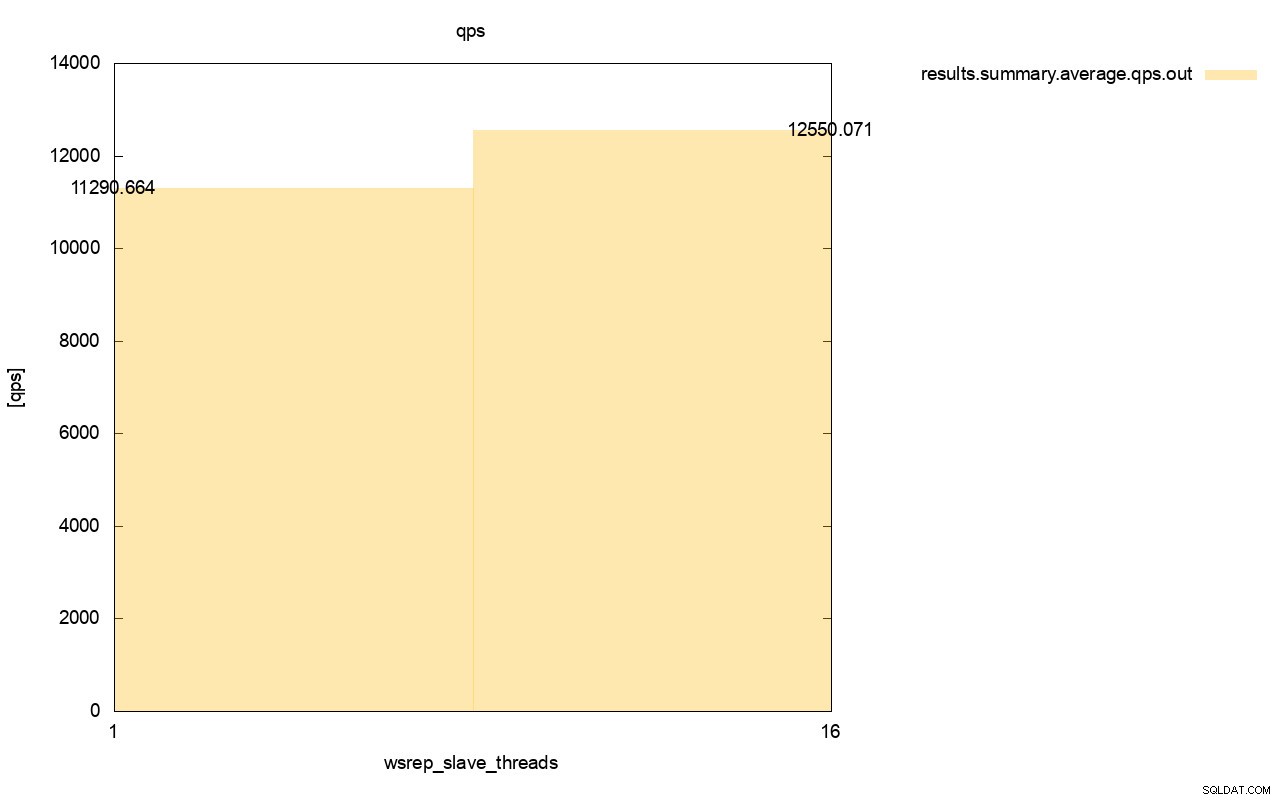
Widoczna jest również różnica w przepustowości, około 11% poprawy, gdy dodaliśmy więcej wsrep_slave_threads.
Jak widać, wpływ jest. W żadnym wypadku nie jest to 16x (nawet jeśli w ten sposób zwiększyliśmy liczbę wątków podrzędnych w Galerze), ale jest zdecydowanie na tyle widoczne, że nie możemy go zaklasyfikować jako zwykłej anomalii statystycznej.
Należy pamiętać, że w naszym przypadku użyliśmy dość małych węzłów. Różnica powinna być jeszcze bardziej znacząca, jeśli mówimy o dużych instancjach działających na wolumenach EBS z tysiącami aprowizowanych IOPS.
Wtedy bylibyśmy w stanie uruchomić sysbench jeszcze bardziej agresywnie, z większą liczbą jednoczesnych operacji. Powinno to poprawić równoległość zestawów zapisu, jeszcze bardziej zwiększając zysk z wielowątkowości. Ponadto szybszy sprzęt oznacza, że Galera będzie w stanie wykorzystać te 16 wątków w bardziej wydajny sposób.
Przeprowadzając takie testy, musisz pamiętać, że musisz przesunąć konfigurację prawie do granic możliwości. Replikacja jednowątkowa może obsłużyć dość duże obciążenie i musisz uruchomić duży ruch, aby faktycznie nie była wystarczająco wydajna, aby obsłużyć zadanie.
Mamy nadzieję, że ten post na blogu da ci lepszy wgląd w możliwości Galera Cluster do równoległego stosowania zestawów zapisu oraz czynniki ograniczające z tym związane.