Zapytania muszą być buforowane w każdej mocno obciążonej bazie danych, po prostu nie ma możliwości, aby baza danych obsłużyła cały ruch z rozsądną wydajnością. Istnieje wiele mechanizmów, w których można zaimplementować pamięć podręczną zapytań. Począwszy od pamięci podręcznej zapytań MySQL, która działała dobrze w przypadku obciążeń głównie tylko do odczytu, o niskiej współbieżności i która nie ma miejsca w przypadku dużych jednoczesnych obciążeń (do tego stopnia, że Oracle usunął go w MySQL 8.0), do zewnętrznych magazynów kluczy-wartość jak Redis, memcached lub CouchBase.
Głównym problemem związanym z używaniem zewnętrznego dedykowanego magazynu danych (ponieważ nie zalecamy nikomu korzystania z pamięci podręcznej zapytań MySQL) jest to, że jest to kolejny magazyn danych do zarządzania. Jest to kolejne środowisko do utrzymania, skalowania problemów do obsłużenia, błędów do debugowania i tak dalej.
Dlaczego więc nie zabić dwóch ptaków jednym kamieniem, wykorzystując swój serwer proxy? Zakłada się tutaj, że używasz serwera proxy w swoim środowisku produkcyjnym, ponieważ pomaga on w zapytaniach równoważenia obciążenia między instancjami i maskuje podstawową topologię bazy danych, zapewniając prosty punkt końcowy dla aplikacji. ProxySQL jest świetnym narzędziem do tego zadania, ponieważ może dodatkowo pełnić funkcję warstwy buforującej. W tym poście na blogu pokażemy, jak buforować zapytania w ProxySQL za pomocą ClusterControl.
Jak działa pamięć podręczna zapytań w ProxySQL?
Przede wszystkim trochę tła. ProxySQL zarządza ruchem poprzez reguły zapytań i może wykonywać buforowanie zapytań przy użyciu tego samego mechanizmu. ProxySQL przechowuje zapytania w pamięci podręcznej w strukturze pamięci. Dane z pamięci podręcznej są usuwane przy użyciu ustawienia czasu wygaśnięcia (TTL). TTL można zdefiniować dla każdej reguły zapytania indywidualnie, więc użytkownik może zdecydować, czy reguły zapytań mają być zdefiniowane dla każdego indywidualnego zapytania, z odrębnym TTL, czy po prostu musi utworzyć kilka reguł, które będą pasować do większości ruch.
Istnieją dwa ustawienia konfiguracyjne, które definiują sposób używania pamięci podręcznej zapytań. Najpierw mysql-query_cache_size_MB który definiuje miękki limit rozmiaru pamięci podręcznej zapytań. Nie jest to sztywny limit, więc ProxySQL może zużywać nieco więcej pamięci niż to, ale wystarczy, aby utrzymać kontrolę nad wykorzystaniem pamięci. Drugie ustawienie, które możesz zmienić, to mysql-query_cache_stores_empty_result . Określa, czy pusty zestaw wyników jest buforowany, czy nie.
Pamięć podręczna zapytań ProxySQL została zaprojektowana jako magazyn klucz-wartość. Wartość jest zbiorem wyników zapytania, a klucz składa się z połączonych wartości, takich jak:użytkownik, schemat i tekst zapytania. Następnie z tego ciągu tworzony jest skrót, który jest używany jako klucz.
Konfigurowanie ProxySQL jako pamięci podręcznej zapytań przy użyciu ClusterControl
W początkowej konfiguracji mamy klaster replikacji składający się z jednego urządzenia nadrzędnego i jednego podrzędnego. Mamy również pojedynczy serwer ProxySQL.
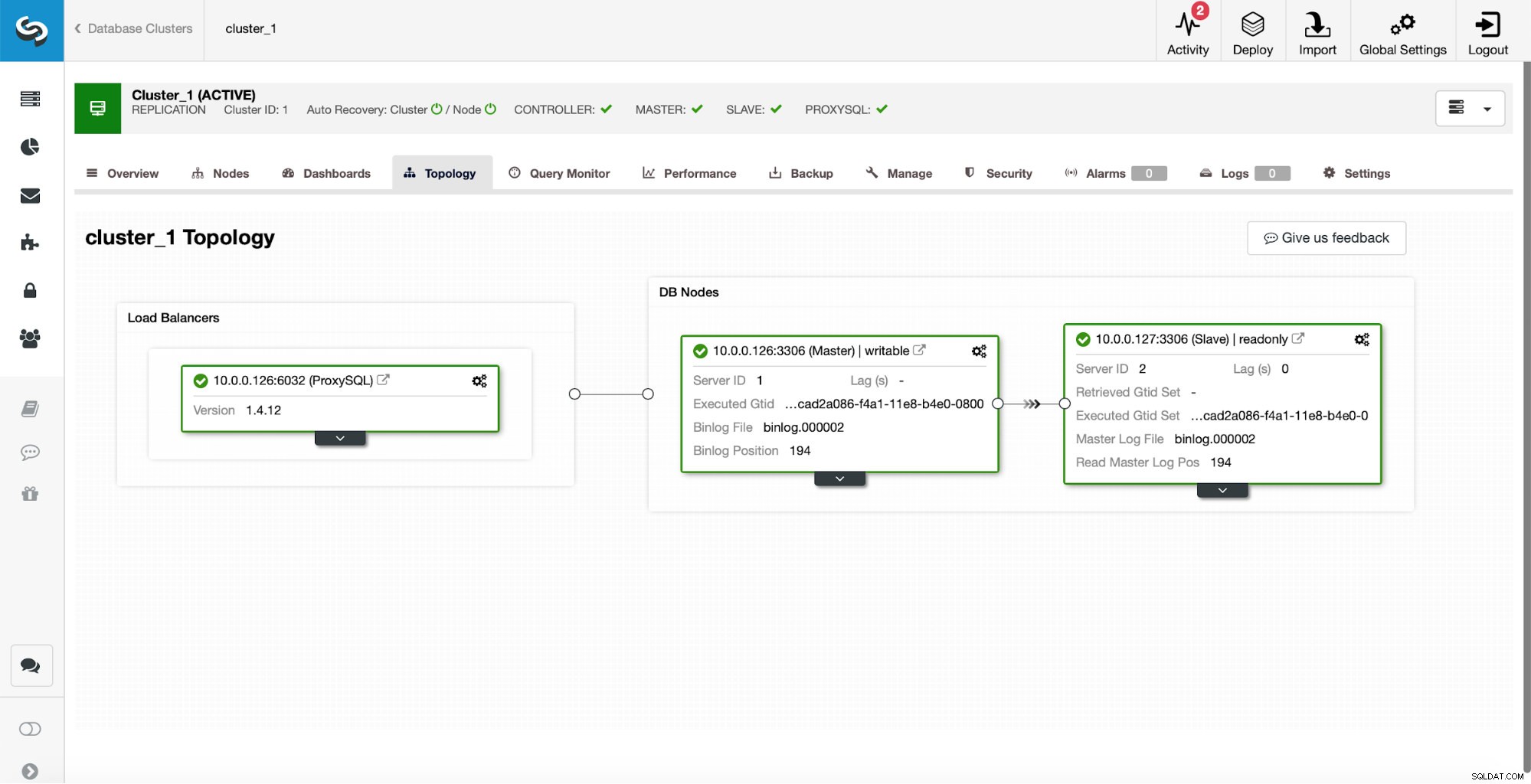
W żadnym wypadku nie jest to konfiguracja na poziomie produkcyjnym, ponieważ musielibyśmy zaimplementować jakiś rodzaj wysokiej dostępności dla warstwy proxy (na przykład poprzez wdrożenie więcej niż jednej instancji ProxySQL, a następnie utrzymywanie jej na wierzchu dla zmiennego wirtualnego adresu IP), ale to będzie więcej niż wystarczające do naszych testów.
Najpierw zweryfikujemy konfigurację ProxySQL, aby upewnić się, że ustawienia pamięci podręcznej zapytań są zgodne z naszymi oczekiwaniami.
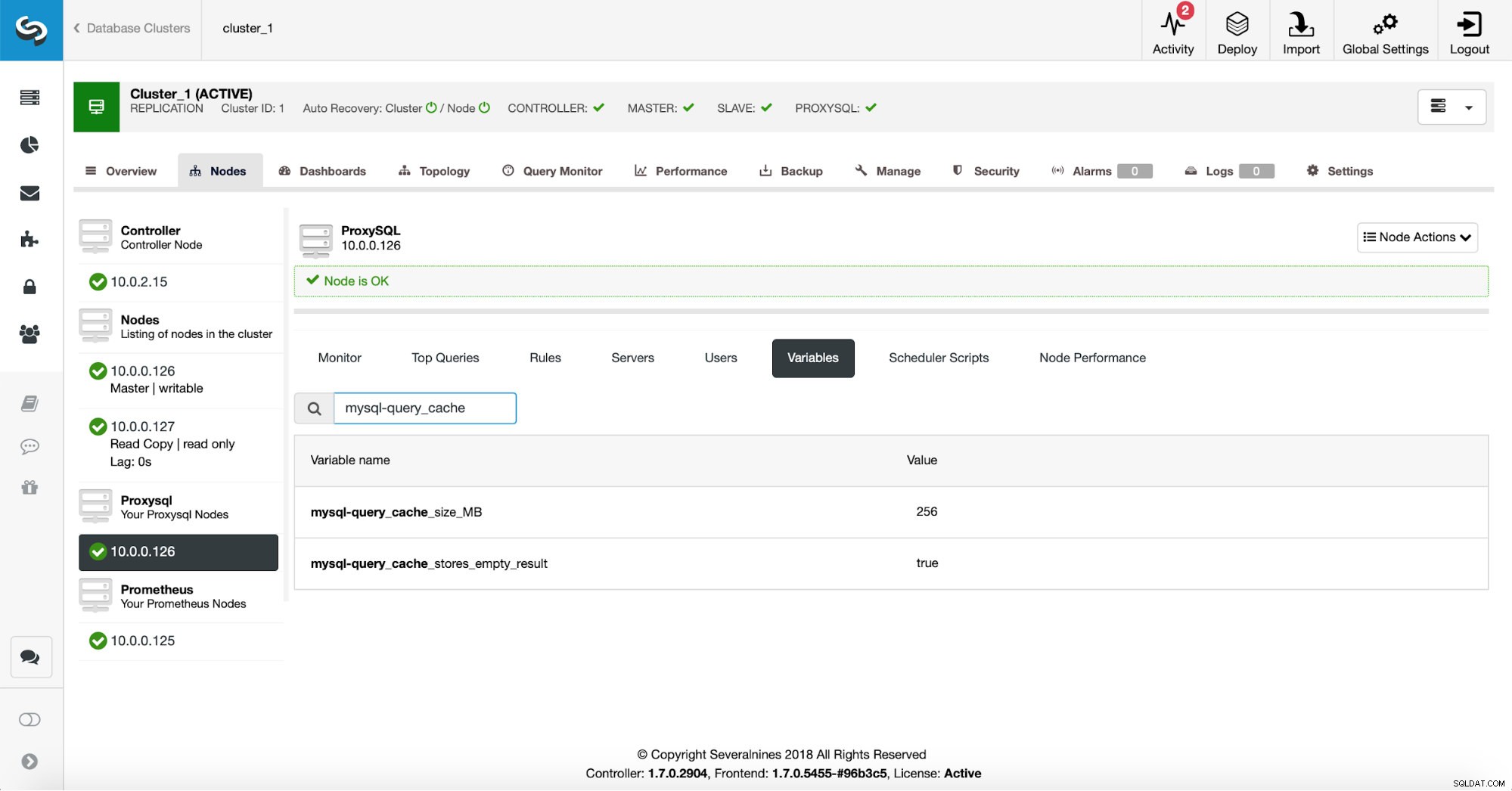
256 MB pamięci podręcznej zapytań powinno wystarczyć, a my chcemy buforować również puste zbiory wyników - czasami zapytanie, które nie zwraca żadnych danych, nadal musi wykonać dużo pracy, aby sprawdzić, czy nie ma nic do zwrócenia.
Następnym krokiem jest stworzenie reguł zapytań, które będą pasować do zapytań, które chcesz buforować. W ClusterControl można to zrobić na dwa sposoby.
Ręczne dodawanie reguł zapytań
Pierwszy sposób wymaga nieco więcej ręcznych działań. Korzystając z ClusterControl, możesz łatwo utworzyć dowolną regułę zapytań, w tym reguły zapytań, które wykonują buforowanie. Najpierw spójrzmy na listę reguł:
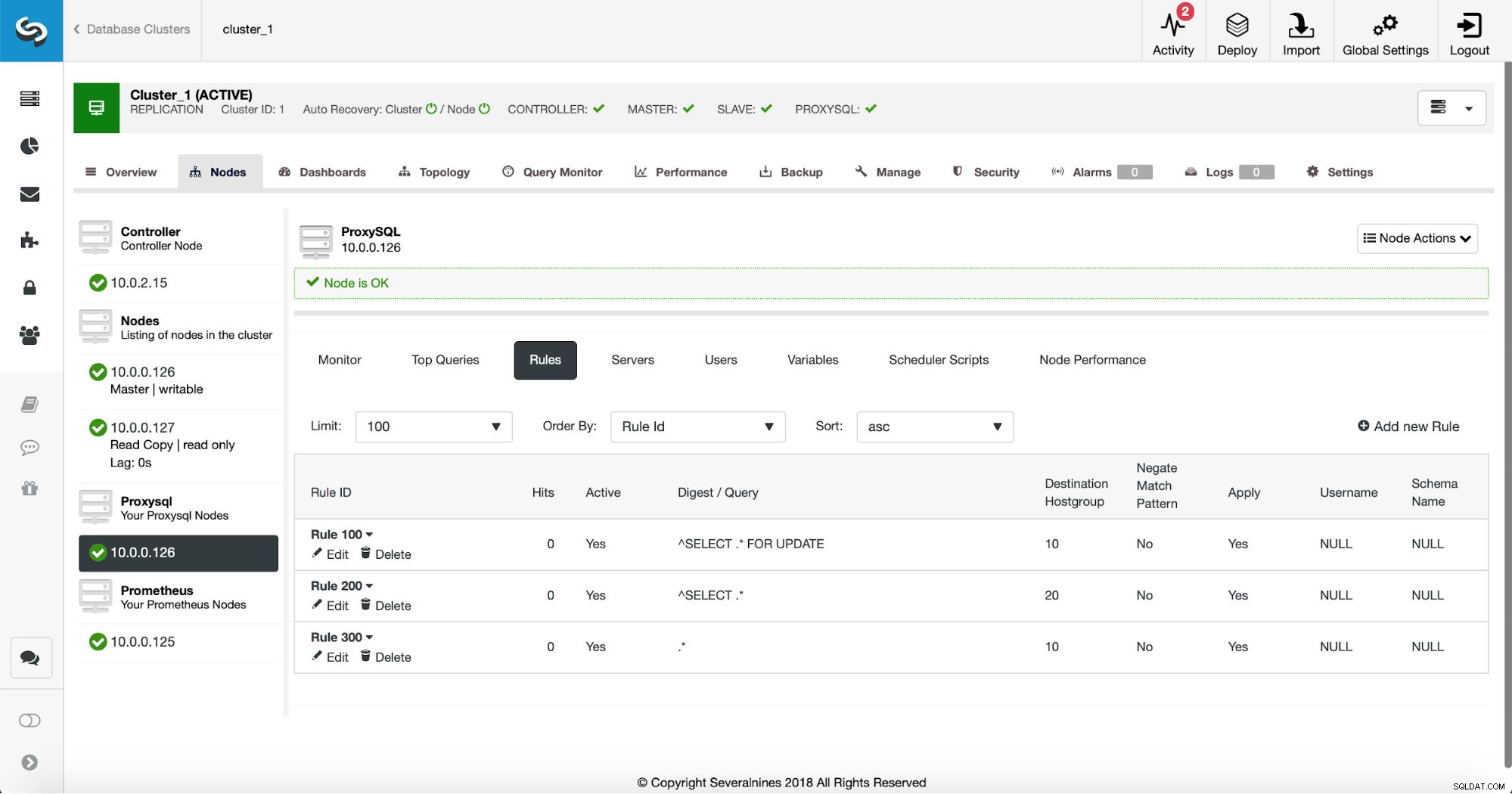
W tym momencie mamy zestaw reguł zapytań do wykonania podziału odczytu/zapisu. Pierwsza reguła ma identyfikator 100. Nasza nowa reguła zapytania musi zostać przetworzona przed tą, więc użyjemy niższego identyfikatora reguły. Stwórzmy regułę zapytań, która będzie buforować zapytania podobne do tego:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c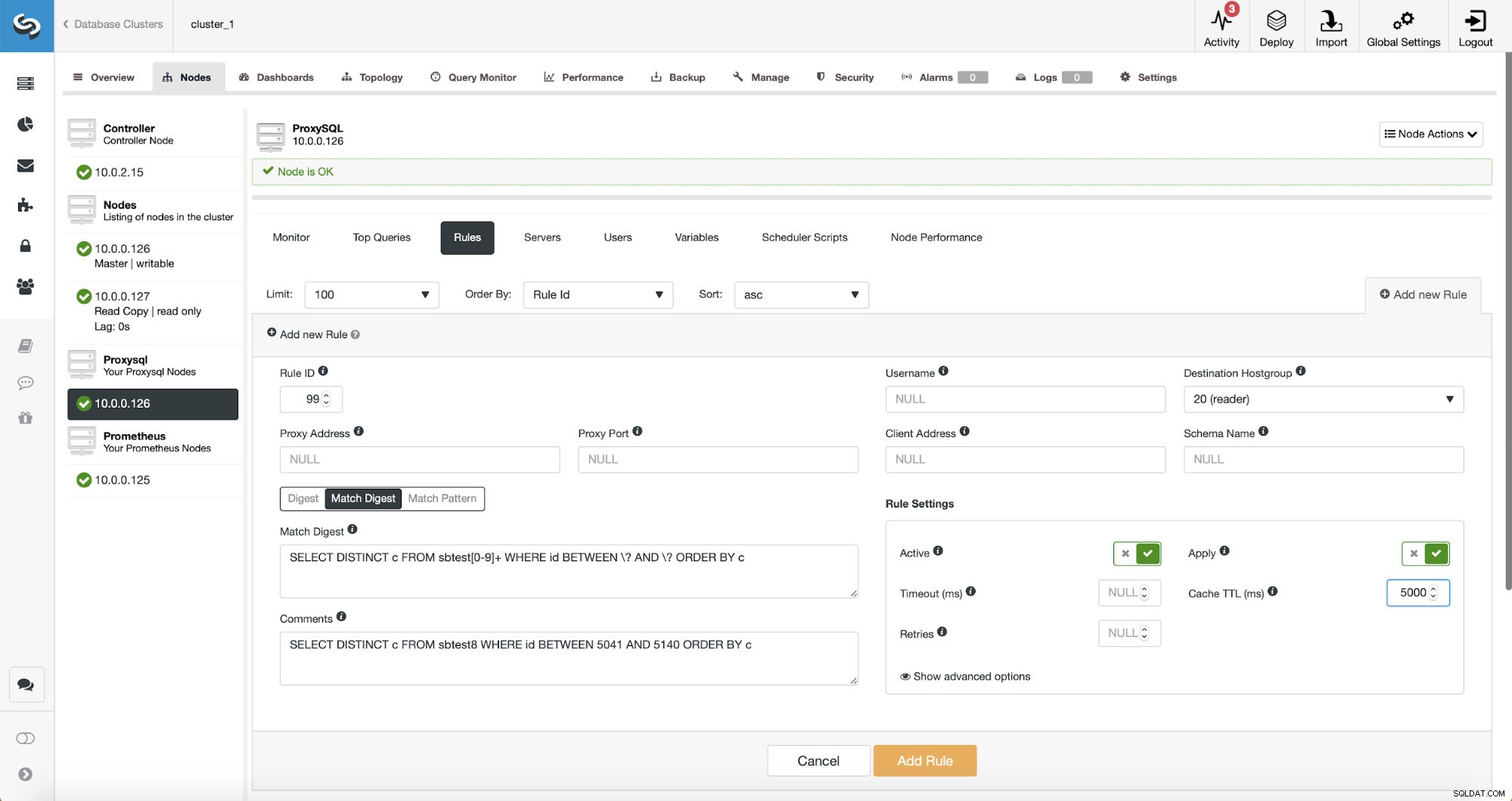
Istnieją trzy sposoby dopasowania zapytania:Digest, Match Digest i Match Pattern. Porozmawiajmy tu trochę o nich. Po pierwsze, Match Digest. Możemy tutaj ustawić wyrażenie regularne, które będzie pasować do uogólnionego ciągu zapytania, który reprezentuje pewien typ zapytania. Na przykład dla naszego zapytania:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cOgólna reprezentacja to:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cJak widać, usunięto argumenty do klauzuli WHERE, dlatego wszystkie zapytania tego typu są reprezentowane jako pojedynczy ciąg. Ta opcja jest całkiem przyjemna w użyciu, ponieważ pasuje do całego typu zapytania, a co ważniejsze, jest pozbawiona wszelkich spacji. Dzięki temu pisanie wyrażenia regularnego jest o wiele łatwiejsze, ponieważ nie musisz uwzględniać dziwnych łamań wierszy, spacji na początku lub na końcu ciągu i tak dalej.
Digest to skrót, który ProxySQL oblicza na podstawie formularza Match Digest.
Wreszcie dopasowanie wzorca dopasowuje pełny tekst zapytania, który został wysłany przez klienta. W naszym przypadku zapytanie będzie miało postać:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cZamierzamy użyć funkcji Match Digest, ponieważ chcemy, aby wszystkie te zapytania były objęte regułą zapytań. Gdybyśmy chcieli buforować tylko to konkretne zapytanie, dobrą opcją byłoby użycie wzorca dopasowania.
Wyrażenie regularne, którego używamy to:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cDopasowujemy dosłownie dokładny ciąg uogólnionego zapytania z jednym wyjątkiem — wiemy, że to zapytanie trafia do wielu tabel, dlatego dodaliśmy wyrażenie regularne, aby dopasować je do wszystkich.
Po wykonaniu tej czynności możemy sprawdzić, czy reguła zapytania obowiązuje, czy nie.
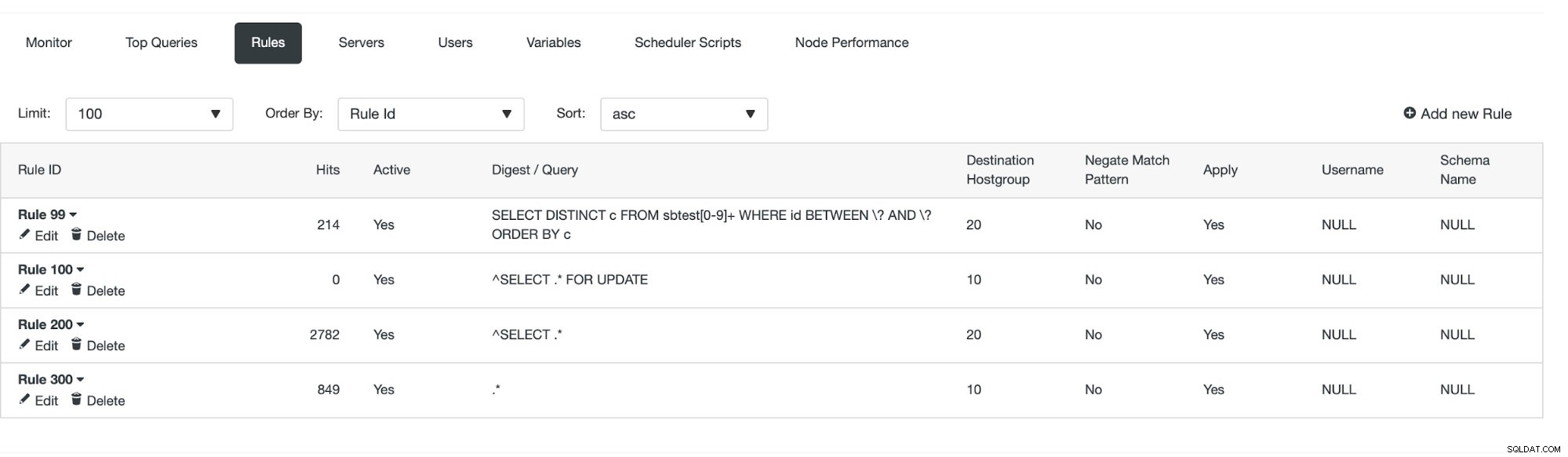
Widzimy, że liczba trafień rośnie, co oznacza, że używana jest nasza reguła zapytania. Następnie przyjrzymy się innym sposobom tworzenia reguły zapytania.
Korzystanie z ClusterControl do tworzenia reguł zapytań
ProxySQL posiada użyteczną funkcjonalność zbierania statystyk kierowanych zapytań. Możesz śledzić dane, takie jak czas wykonania, ile razy dane zapytanie zostało wykonane i tak dalej. Te dane są również obecne w ClusterControl:
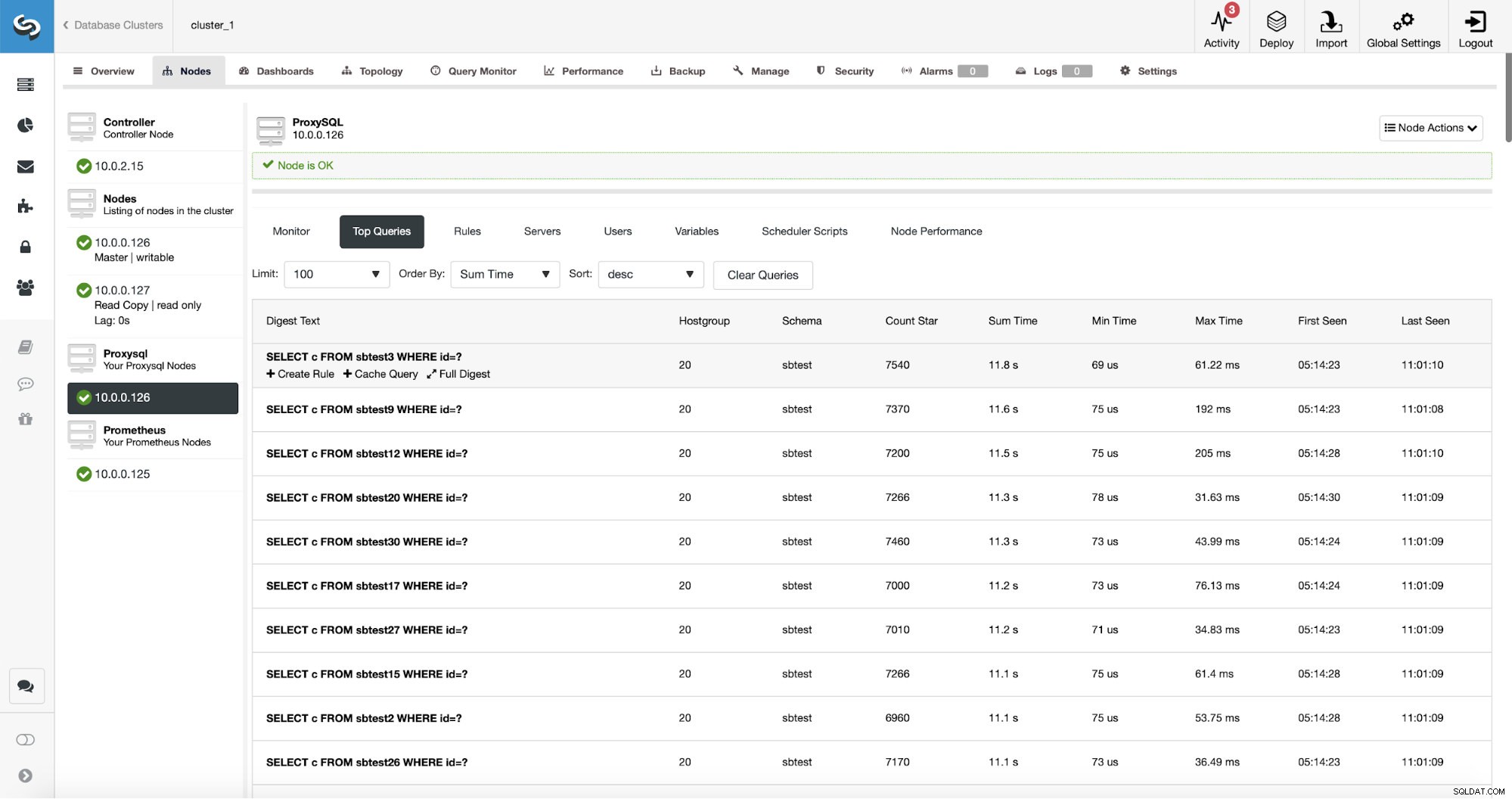
Co więcej, jeśli wskażesz dany typ zapytania, możesz stworzyć powiązaną z nim regułę zapytania. Możesz również łatwo buforować ten konkretny typ zapytania.
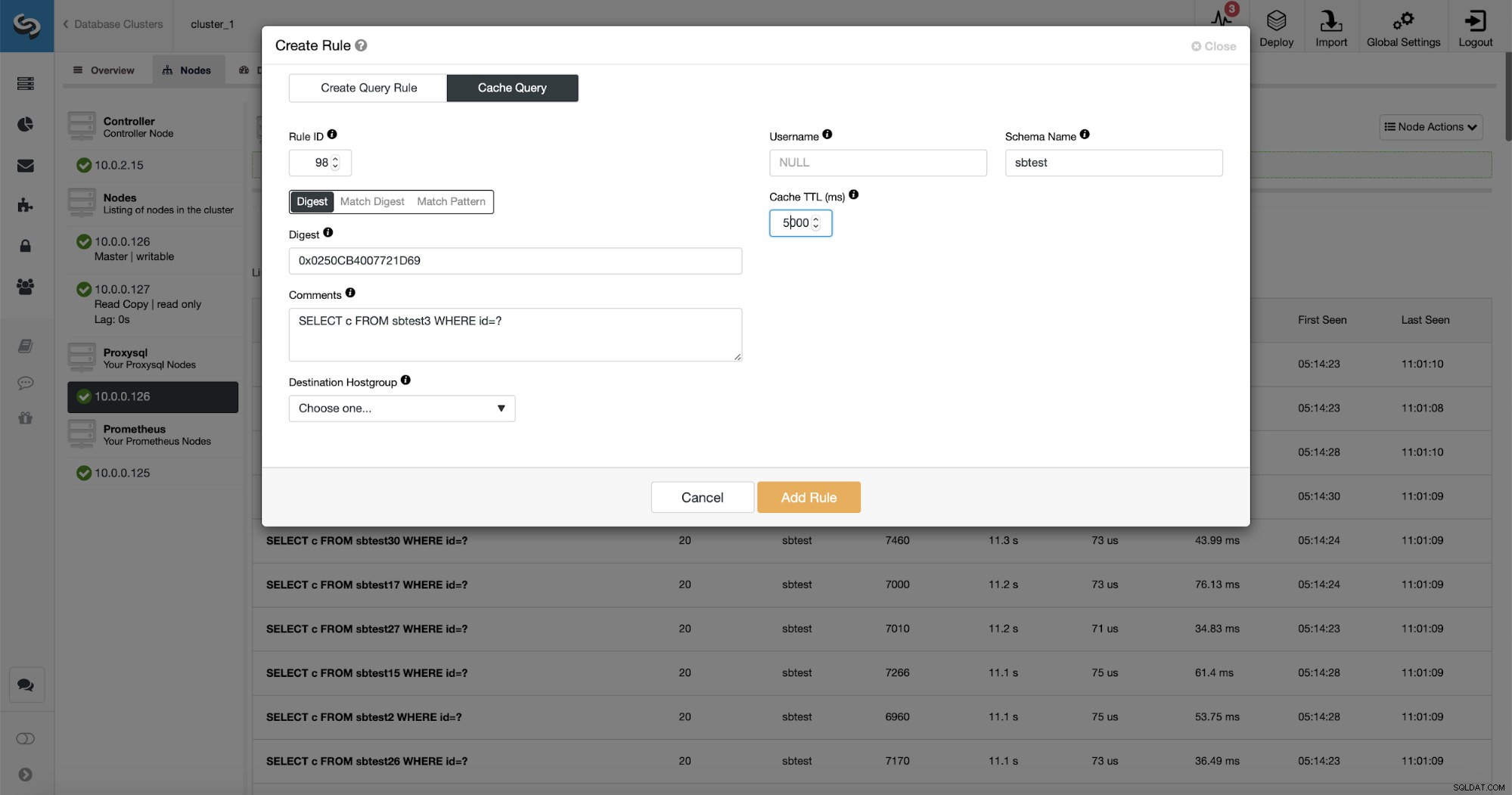
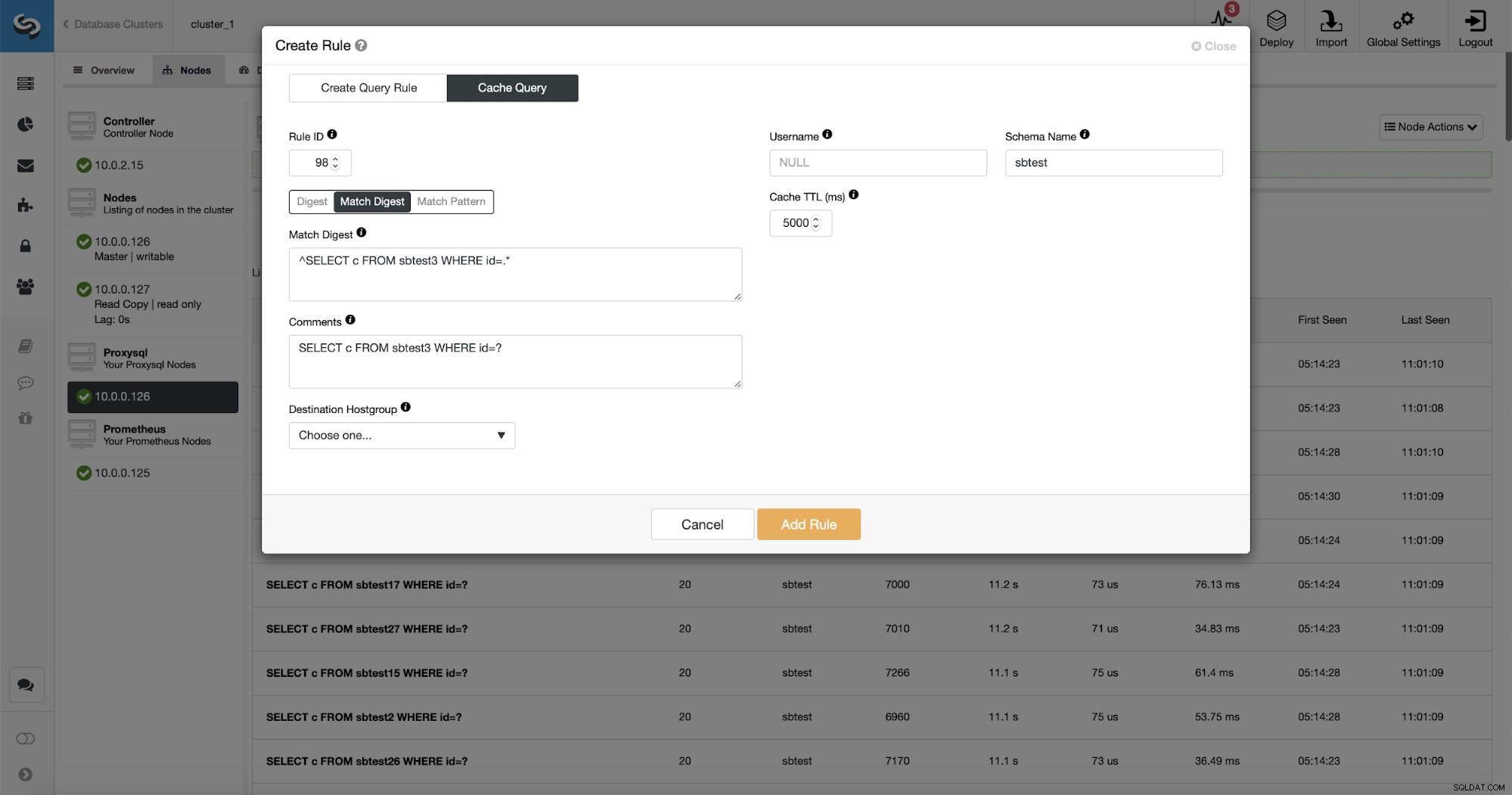
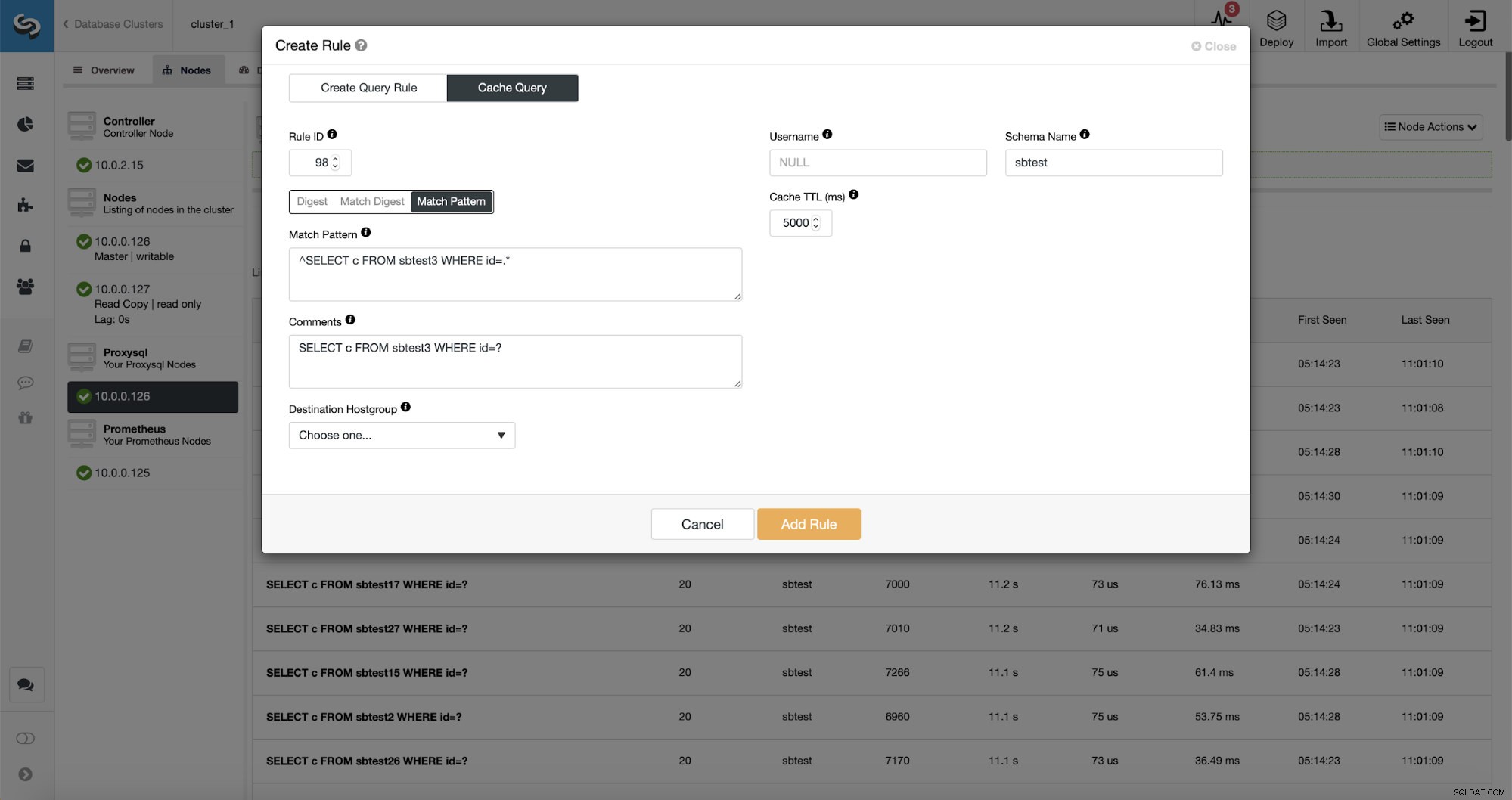
Jak widać, niektóre dane, takie jak IP reguły, TTL pamięci podręcznej lub nazwa schematu, są już wypełnione. ClusterControl wypełni również dane na podstawie mechanizmu dopasowywania, który zdecydowałeś się użyć. Możemy łatwo użyć hash dla danego typu zapytania lub użyć funkcji Match Digest lub Match Pattern, jeśli chcemy dostroić wyrażenie regularne (na przykład robiąc to samo, co wcześniej i rozszerzając wyrażenie regularne tak, aby pasowało do wszystkich tabele w schemacie sbtest).
To wszystko, czego potrzebujesz, aby łatwo tworzyć reguły pamięci podręcznej zapytań w ProxySQL. Pobierz ClusterControl i wypróbuj go już dziś.



