W poprzednim poście na blogu pokazaliśmy kilka podstawowych kroków, aby wdrożyć i zarządzać samodzielnym serwerem MySQL, a także konfiguracją replikacji MySQL za pomocą modułu MySQL Puppet. W tej drugiej instalacji omówimy podobne kroki, ale teraz z konfiguracją Galera Cluster.
Klaster Galera z marionetką
Jak być może wiesz, Galera Cluster ma trzech głównych dostawców:
- Klaster MySQL Galera (kodowanie)
- Klaster Percona XtraDB (Percona)
- Klaster MariaDB (wbudowany w serwer MariaDB przez MariaDB)
Powszechną praktyką we wdrożeniach klastra Galera jest umieszczenie dodatkowej warstwy nad klastrem bazy danych w celu równoważenia obciążenia. Jest to jednak złożony proces, który zasługuje na swój własny post.
W Kuźni Marionetek dostępnych jest wiele modułów Marionetek, których można użyć do stworzenia klastra Galera. Oto niektóre z nich...
- puppetlabs/mysql – tylko MariaDB Galera
- fraenki/galera - Klaster Percona XtraDB i MySQL Galera od Codership
- edestecd/mariadb – tylko klaster MariaDB
- filiadata/percona — klaster Percona XtraDB
Ponieważ naszym celem jest zapewnienie podstawowej wiedzy na temat pisania manifestu i automatyzacji wdrażania klastra Galera, omówimy wdrażanie klastra MariaDB Galera za pomocą modułu puppetlabs/mysql. W przypadku innych modułów zawsze możesz zajrzeć do ich odpowiedniej dokumentacji, aby uzyskać instrukcje lub wskazówki dotyczące instalacji.
W Galera Cluster kolejność podczas uruchamiania węzła ma kluczowe znaczenie. Aby poprawnie uruchomić nowy klaster, jeden węzeł musi być ustawiony jako węzeł referencyjny. Ten węzeł zostanie uruchomiony z ciągiem połączenia z pustym hostem (gcomm://), aby zainicjować klaster. Ten proces nazywa się ładowaniem początkowym.
Po uruchomieniu węzeł stanie się podstawowym komponentem, a pozostałe węzły można uruchomić za pomocą standardowego polecenia mysql start (systemctl start mysql lub service mysql start ), po którym następuje ciąg połączenia z pełnym hostem (gcomm://db1,db2,db3). Bootstrapping jest wymagany tylko wtedy, gdy żaden inny węzeł w klastrze nie jest blokowany przez główny komponent (sprawdź w wsrep_cluster_status status).
Proces uruchamiania klastra musi być wykonany jawnie przez użytkownika. Sam manifest NIE może uruchamiać klastra (bootstrap dowolnego węzła) przy pierwszym uruchomieniu, aby uniknąć ryzyka utraty danych. Pamiętaj, manifest kukiełkowy musi być napisany tak, aby był jak najbardziej idempotentny. Manifest musi być bezpieczny, aby mógł być wykonywany wielokrotnie bez wpływu na już działające instancje MySQL. Oznacza to, że musimy skupić się przede wszystkim na konfiguracji repozytorium, instalacji pakietów, konfiguracji wstępnej i konfiguracji użytkownika SST.
Następujące opcje konfiguracji są obowiązkowe dla Galera:
- wsrep_on :Flaga włączająca API replikacji zbioru zapisów dla Galera Cluster (tylko MariaDB).
- wsrep_cluster_name :nazwa klastra. Musi być identyczny we wszystkich węzłach należących do tego samego klastra.
- wsrep_cluster_address :ciąg połączenia komunikacyjnego Galera, przedrostek z gcomm://, po którym następuje lista węzłów, oddzielone przecinkiem. Pusta lista węzłów oznacza inicjalizację klastra.
- wsrep_provider :Ścieżka, w której znajduje się biblioteka Galera. Ścieżka może się różnić w zależności od systemu operacyjnego.
- bind_address :MySQL musi być dostępny z zewnątrz, więc wartość '0.0.0.0' jest obowiązkowa.
- wsrep_sst_method :W przypadku MariaDB preferowaną metodą SST jest mariabackup.
- wsrep_sst_auth :Użytkownik i hasło MySQL (oddzielone dwukropkiem), aby wykonać transfer zrzutu. Zwykle określamy użytkownika, który ma możliwość tworzenia pełnej kopii zapasowej.
- wsrep_node_address :adres IP do komunikacji i replikacji Galera. Użyj współczynnika marionetek, aby wybrać prawidłowy adres IP.
- wsrep_node_name :nazwa hosta FQDN. Użyj współczynnika marionetek, aby wybrać prawidłową nazwę hosta.
W przypadku wdrożeń opartych na Debianie skrypt poinstalacyjny spróbuje automatycznie uruchomić serwer MariaDB. Jeśli skonfigurowaliśmy wsrep_on=ON (flaga umożliwiająca włączenie Galera) z pełnym adresem w wsrep_cluster_address zmienna, serwer ulegnie awarii podczas instalacji. Dzieje się tak, ponieważ nie ma podstawowego komponentu, z którym można by się połączyć.
Aby poprawnie uruchomić klaster w Galera, pierwszy węzeł (nazywany węzłem ładowania początkowego) musi być skonfigurowany z pustym ciągiem połączenia (wsrep_cluster_address =gcomm://), aby zainicjować węzeł jako komponent podstawowy. Możesz także uruchomić dostarczony skrypt ładowania początkowego, o nazwie galera_new_cluster, który zasadniczo robi podobną rzecz w tle.
Wdrożenie klastra Galera (MariaDB)
Wdrożenie Galera Cluster wymaga dodatkowej konfiguracji w źródle APT w celu zainstalowania preferowanego repozytorium wersji MariaDB.
Należy pamiętać, że replikacja Galera jest wbudowana w serwer MariaDB i nie wymaga instalowania żadnych dodatkowych pakietów. Biorąc to pod uwagę, wymagana jest dodatkowa flaga, aby włączyć Galera za pomocą wsrep_on=ON. Bez tej flagi MariaDB będzie działać jako samodzielny serwer.
W naszym środowisku opartym na Debianie opcja wsrep_on może być obecna w manifeście dopiero po zakończeniu pierwszego wdrożenia (jak pokazano poniżej w krokach wdrażania). Ma to na celu upewnienie się, że pierwsze, początkowe uruchomienie działa jako samodzielny serwer dla Puppet, aby udostępnić węzeł, zanim będzie całkowicie gotowy do bycia węzłem Galera.
Zacznijmy od przygotowania treści manifestu jak poniżej (w razie potrzeby zmodyfikuj sekcję zmiennych globalnych):
# Puppet manifest for Galera Cluster MariaDB 10.3 on Ubuntu 18.04 (Puppet v6.4.2)
# /etc/puppetlabs/code/environments/production/manifests/galera.pp
# global vars
$sst_user = 'sstuser'
$sst_password = 'S3cr333t$'
$backup_dir = '/home/backup/mysql'
$mysql_cluster_address = 'gcomm://192.168.0.161,192.168.0.162,192.168.0.163'
# node definition
node "db1.local", "db2.local", "db3.local" {
Apt::Source['mariadb'] ~>
Class['apt::update'] ->
Class['mysql::server'] ->
Class['mysql::backup::xtrabackup']
}
# apt module must be installed first: 'puppet module install puppetlabs-apt'
include apt
# custom repository definition
apt::source { 'mariadb':
location => 'https://sfo1.mirrors.digitalocean.com/mariadb/repo/10.3/ubuntu',
release => $::lsbdistcodename,
repos => 'main',
key => {
id => 'A6E773A1812E4B8FD94024AAC0F47944DE8F6914',
server => 'hkp://keyserver.ubuntu.com:80',
},
include => {
src => false,
deb => true,
},
}
# Galera configuration
class {'mysql::server':
package_name => 'mariadb-server',
root_password => 'example@sqldat.com#',
service_name => 'mysql',
create_root_my_cnf => true,
remove_default_accounts => true,
manage_config_file => true,
override_options => {
'mysqld' => {
'datadir' => '/var/lib/mysql',
'bind_address' => '0.0.0.0',
'binlog-format' => 'ROW',
'default-storage-engine' => 'InnoDB',
'wsrep_provider' => '/usr/lib/galera/libgalera_smm.so',
'wsrep_provider_options' => 'gcache.size=1G',
'wsrep_cluster_name' => 'galera_cluster',
'wsrep_cluster_address' => $mysql_cluster_address,
'log-error' => '/var/log/mysql/error.log',
'wsrep_node_address' => $facts['networking']['interfaces']['enp0s8']['ip'],
'wsrep_node_name' => $hostname,
'innodb_buffer_pool_size' => '512M',
'wsrep_sst_method' => 'mariabackup',
'wsrep_sst_auth' => "${sst_user}:${sst_password}"
},
'mysqld_safe' => {
'log-error' => '/var/log/mysql/error.log'
}
}
}
# force creation of backup dir if not exist
exec { "mkdir -p ${backup_dir}" :
path => ['/bin','/usr/bin'],
unless => "test -d ${backup_dir}"
}
# create SST and backup user
class { 'mysql::backup::xtrabackup' :
xtrabackup_package_name => 'mariadb-backup',
backupuser => "${sst_user}",
backuppassword => "${sst_password}",
backupmethod => 'mariabackup',
backupdir => "${backup_dir}"
}
# /etc/hosts definition
host {
'db1.local': ip => '192.168.0.161';
'db2.local': ip => '192.169.0.162';
'db3.local': ip => '192.168.0.163';
}W tym momencie potrzebne jest trochę wyjaśnienia. „wsrep_node_address” musi wskazywać na ten sam adres IP, który został zadeklarowany w wsrep_cluster_address. W tym środowisku nasze hosty mają dwa interfejsy sieciowe i chcemy użyć drugiego interfejsu (o nazwie enp0s8) do komunikacji Galera (do którego podłączona jest sieć 192.168.0.0/24). Dlatego używamy współczynnika Puppet, aby uzyskać informacje z węzła i zastosować je do opcji konfiguracji. Reszta jest dość oczywista.
W każdym węźle MariaDB uruchom następujące polecenie, aby zastosować katalog jako użytkownik root:
$ puppet agent -tKatalog zostanie zastosowany do każdego węzła w celu instalacji i przygotowania. Po zakończeniu musimy dodać następujący wiersz do naszego manifestu w sekcji "override_options => mysqld":
'wsrep_on' => 'ON',Powyższe spełni wymagania Galera dla MariaDB. Następnie ponownie zastosuj katalog w każdym węźle MariaDB:
$ puppet agent -tPo zakończeniu jesteśmy gotowi do uruchomienia naszego klastra. Ponieważ jest to nowy klaster, możemy wybrać dowolny węzeł jako węzeł referencyjny, czyli węzeł ładowania początkowego. Wybierzmy db1.local (192.168.0.161) i uruchom następujące polecenie:
$ galera_new_cluster #db1Po uruchomieniu pierwszego węzła możemy uruchomić pozostały węzeł za pomocą standardowego polecenia start (jeden węzeł na raz):
$ systemctl restart mariadb #db2 and db3Po uruchomieniu zerknij do dziennika błędów MySQL w /var/log/mysql/error.log i upewnij się, że dziennik kończy się następującym wierszem:
2019-06-10 4:11:10 2 [Note] WSREP: Synchronized with group, ready for connectionsPowyższe mówi nam, że węzły są zsynchronizowane z grupą. Następnie możemy zweryfikować status za pomocą następującego polecenia:
$ mysql -uroot -e 'show status like "wsrep%"'Upewnij się, że we wszystkich węzłach wsrep_cluster_size , wsrep_cluster_status i wsrep_local_state_comment to odpowiednio 3, „Podstawowy” i „Zsynchronizowany”.
Zarządzanie MySQL
Ten moduł może być używany do wykonywania wielu zadań związanych z zarządzaniem MySQL...
- opcje konfiguracji (modyfikacja, zastosowanie, konfiguracja niestandardowa)
- zasoby bazy danych (baza danych, użytkownik, dotacje)
- kopia zapasowa (tworzenie, planowanie, użytkownik kopii zapasowej, pamięć)
- proste przywracanie (tylko mysqldump)
- instalacja/aktywacja wtyczek
Kontrola usług
Najbezpieczniejszym sposobem udostępniania Galera Cluster z Puppet jest ręczna obsługa wszystkich operacji kontroli usług (nie pozwól, aby Puppet się tym zajmował). W przypadku prostego, stopniowego ponownego uruchamiania klastra wystarczy standardowe polecenie usługi. Uruchom następujące polecenie po jednym węźle na raz.
$ systemctl restart mariadb # Systemd
$ service mariadb restart # SysVinitJednak w przypadku partycji sieciowej i braku podstawowego składnika (sprawdź w wsrep_cluster_status ), należy załadować najnowszy węzeł, aby przywrócić działanie klastra bez utraty danych. Możesz wykonać kroki, jak pokazano w powyższej sekcji wdrażania. Aby dowiedzieć się więcej o procesie ładowania początkowego z przykładowym scenariuszem, omówiliśmy to szczegółowo w tym poście na blogu, Jak załadować MySQL lub MariaDB Galera Cluster.
Zasób bazy danych
Użyj klasy mysql::db, aby upewnić się, że baza danych z powiązanym użytkownikiem i uprawnieniami jest obecna, na przykład:
# make sure the database and user exist with proper grant
mysql::db { 'mynewdb':
user => 'mynewuser',
password => 'passw0rd',
host => '192.168.0.%',
grant => ['SELECT', 'UPDATE']
} Powyższa definicja może być przypisana do dowolnego węzła, ponieważ każdy węzeł w klastrze Galera jest nadrzędnym.
Kopia zapasowa i przywracanie
Ponieważ utworzyliśmy użytkownika SST przy użyciu klasy xtrabackup, Puppet skonfiguruje wszystkie wymagania wstępne dla zadania kopii zapasowej — utworzenie użytkownika kopii zapasowej, przygotowanie ścieżki docelowej, przypisanie własności i uprawnień, ustawienie zadania cron i ustawienie opcji polecenia kopii zapasowej do użycia w dostarczonym skrypcie kopii zapasowej. Każdy węzeł zostanie skonfigurowany z dwoma zadaniami tworzenia kopii zapasowych (jedno dla cotygodniowego pełnego, a drugie dla dziennego przyrostu) domyślnie na 23:05, jak można stwierdzić na podstawie danych wyjściowych crontab:
$ crontab -l
# Puppet Name: xtrabackup-weekly
5 23 * * 0 /usr/local/sbin/xtrabackup.sh --target-dir=/home/backup/mysql --backup
# Puppet Name: xtrabackup-daily
5 23 * * 1-6 /usr/local/sbin/xtrabackup.sh --incremental-basedir=/home/backup/mysql --target-dir=/home/backup/mysql/`date +%F_%H-%M-%S` --backupJeśli zamiast tego chcesz zaplanować mysqldump, użyj klasy mysql::server::backup, aby przygotować zasoby kopii zapasowej. Załóżmy, że w naszym manifeście mamy następującą deklarację:
# Prepare the backup script, /usr/local/sbin/mysqlbackup.sh
class { 'mysql::server::backup':
backupuser => 'backup',
backuppassword => 'passw0rd',
backupdir => '/home/backup',
backupdirowner => 'mysql',
backupdirgroup => 'mysql',
backupdirmode => '755',
backuprotate => 15,
time => ['23','30'], #backup starts at 11:30PM everyday
include_routines => true,
include_triggers => true,
ignore_events => false,
maxallowedpacket => '64M'
}Powyższe mówi Puppetowi, aby skonfigurował skrypt kopii zapasowej w /usr/local/sbin/mysqlbackup.sh i zaplanował to codziennie o 23:30. Jeśli chcesz wykonać natychmiastową kopię zapasową, po prostu wywołaj:
$ mysqlbackup.shW przypadku przywracania, moduł obsługuje przywracanie tylko metodą kopii zapasowej mysqldump, importując plik SQL bezpośrednio do bazy danych za pomocą klasy mysql::db, na przykład:
mysql::db { 'mydb':
user => 'myuser',
password => 'mypass',
host => 'localhost',
grant => ['ALL PRIVILEGES'],
sql => '/home/backup/mysql/mydb/backup.gz',
import_cat_cmd => 'zcat',
import_timeout => 900
}Plik SQL będzie ładowany tylko raz, a nie przy każdym uruchomieniu, chyba że zostanie użyte polecenie force_sql => true.
Zarządzanie konfiguracją
W tym przykładzie użyliśmy manage_config_file => true z override_options do ustrukturyzowania naszych linii konfiguracyjnych, które później zostaną wypchnięte przez Puppet. Wszelkie modyfikacje pliku manifestu będą odzwierciedlać tylko zawartość docelowego pliku konfiguracyjnego MySQL. Ten moduł nie załaduje konfiguracji do środowiska wykonawczego ani nie zrestartuje usługi MySQL po wepchnięciu zmian do pliku konfiguracyjnego. Obowiązkiem administratora jest ponowne uruchomienie usługi w celu aktywowania zmian.
Aby dodać niestandardową konfigurację MySQL, możemy umieścić dodatkowe pliki w "includedir", domyślnie w /etc/mysql/conf.d. Pozwala nam to nadpisać ustawienia lub dodać dodatkowe, co jest pomocne, jeśli nie używasz override_options w klasie mysql::server. Zdecydowanie zaleca się skorzystanie z szablonu Puppet. Umieść niestandardowy plik konfiguracyjny w katalogu szablonów modułu (domyślnie , /etc/puppetlabs/code/environments/production/modules/mysql/templates), a następnie dodaj następujące wiersze w manifeście:
# Loads /etc/puppetlabs/code/environments/production/modules/mysql/templates/my-custom-config.cnf.erb into /etc/mysql/conf.d/my-custom-config.cnf
file { '/etc/mysql/conf.d/my-custom-config.cnf':
ensure => file,
content => template('mysql/my-custom-config.cnf.erb')
}Puppet a ClusterControl
Czy wiesz, że możesz również zautomatyzować wdrażanie MySQL lub MariaDB Galera za pomocą ClusterControl? Możesz użyć modułu ClusterControl Puppet, aby go zainstalować lub po prostu pobierając go z naszej strony internetowej.
W porównaniu z ClusterControl można spodziewać się następujących różnic:
- Trochę nauki, aby zrozumieć składnię Puppet, formatowanie, struktury, zanim będziesz mógł pisać manifesty.
- Manifest musi być regularnie testowany. Bardzo często pojawia się błąd kompilacji kodu, zwłaszcza jeśli katalog jest stosowany po raz pierwszy.
- Puppet zakłada, że kody są idempotentne. Warunek testu/sprawdzenia/weryfikacji leży w gestii autora, aby uniknąć zepsucia się z uruchomionym systemem.
- Puppet wymaga agenta w zarządzanym węźle.
- Niezgodność wsteczna. Niektóre stare moduły nie działały poprawnie w nowej wersji.
- Monitorowanie bazy danych/hosta należy skonfigurować osobno.
Kreator wdrażania ClusterControl prowadzi proces wdrażania:
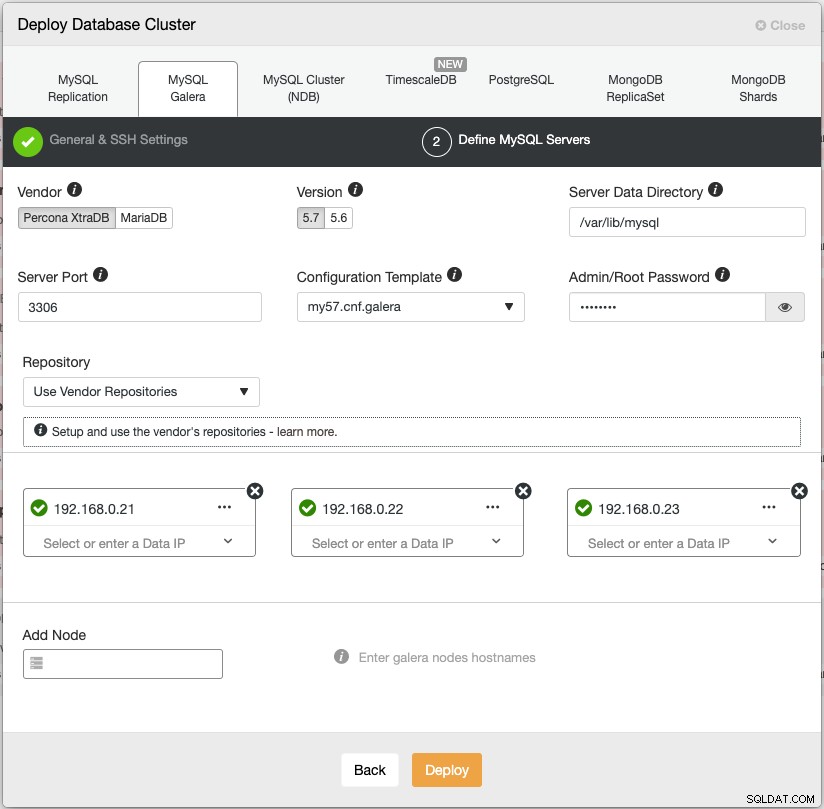
Alternatywnie możesz użyć interfejsu wiersza poleceń ClusterControl o nazwie „s9s”, aby osiągnąć podobne wyniki. Poniższe polecenie tworzy trzywęzłowy klaster Percona XtraDB (pod warunkiem, że wszystkie węzły są bez hasła, które zostało wcześniej skonfigurowane):
$ s9s cluster --create \
--cluster-type=galera \
--nodes='192.168.0.21;192.168.0.22;192.168.0.23' \
--vendor=percona \
--cluster-name='Percona XtraDB Cluster 5.7' \
--provider-version=5.7 \
--db-admin='root' \
--db-admin-passwd='$ecR3t^word' \
--logPonadto ClusterControl obsługuje wdrażanie systemów równoważenia obciążenia dla klastra Galera — HAproxy, ProxySQL i MariaDB MaxScale — wraz z wirtualnym adresem IP (dostarczanym przez Keepalived), aby wyeliminować każdy pojedynczy punkt awarii usługi bazy danych.
Po wdrożeniu węzły/klastry mogą być monitorowane i w pełni zarządzane przez ClusterControl, w tym automatyczne wykrywanie awarii, automatyczne odzyskiwanie, zarządzanie kopiami zapasowymi, zarządzanie równoważeniem obciążenia, podłączanie asynchronicznego urządzenia podrzędnego, zarządzanie konfiguracją i tak dalej. Wszystkie te elementy są połączone w jeden produkt. Średnio klaster bazy danych będzie gotowy do działania w ciągu 30 minut. Potrzebuje tylko bezhasłowego SSH do węzłów docelowych.
Możesz również zaimportować już działający klaster Galera, wdrożony przez Puppet (lub w inny sposób) do ClusterControl, aby doładować klaster wszystkimi fajnymi funkcjami, które są z nim związane. Wersja społecznościowa (bezpłatna na zawsze!) oferuje wdrażanie i monitorowanie.
W następnym odcinku przeprowadzimy Cię przez wdrożenie systemu równoważenia obciążenia MySQL przy użyciu Puppet. Bądź na bieżąco!