Od czasu wydania ClusterControl 1.2.11 w 2015 r. MariaDB MaxScale jest obsługiwana jako system równoważenia obciążenia bazy danych. Z biegiem lat MaxScale rozrósł się i dojrzał, dodając kilka bogatych funkcji. Niedawno wydano MariaDB MaxScale 2.2 i wprowadzono kilka nowych funkcji, w tym zarządzanie awaryjnym klastrem replikacji.
MariaDB MaxScale umożliwia wdrożenia typu master/slave z wysoką dostępnością, automatycznym przełączaniem awaryjnym, ręcznym przełączaniem i automatycznym ponownym dołączaniem. Jeśli master ulegnie awarii, MariaDB MaxScale może automatycznie awansować najbardziej aktualnego slave'a na mastera. Jeśli uszkodzony master zostanie odzyskany, MariaDB MaxScale może automatycznie przekonfigurować go jako slave do nowego mastera. Ponadto administratorzy mogą wykonać ręczne przełączenie, aby zmienić urządzenie główne na żądanie.
W naszych poprzednich blogach omawialiśmy, jak wdrożyć MaxScale za pomocą ClusterControl, a także wdrożyć MariaDB MaxScale w Dockerze. Dla tych, którzy nie są jeszcze zaznajomieni z MariaDB MaxScale, jest to zaawansowany, plug-in serwer proxy bazy danych dla serwerów baz danych MariaDB. Maxscale znajduje się między aplikacjami klienckimi a serwerami baz danych, kierując zapytania klientów i odpowiedzi serwera. Monitoruje również serwery, szybko zauważając wszelkie zmiany w stanie serwera lub topologii replikacji.
Chociaż Maxscale posiada niektóre cechy innych technologii równoważenia obciążenia, takich jak ProxySQL, ta nowa funkcja przełączania awaryjnego (będąca częścią mechanizmu monitorowania i automatycznego wykrywania) wyróżnia się. W tym blogu omówimy tę ekscytującą nową funkcję Maxscale.
Omówienie mechanizmu przełączania awaryjnego MariaDB MaxScale
Wykrywanie nadrzędne
Jest teraz mniej prawdopodobne, że monitor zmieni nagle serwer główny, nawet jeśli inny serwer ma więcej serwerów podrzędnych niż bieżący serwer główny. Administrator DBA może wymusić ponowny wybór urządzenia nadrzędnego, ustawiając bieżący sterownik nadrzędny tylko do odczytu lub usuwając wszystkie jego urządzenia podrzędne, jeśli sterownik główny nie działa.
Tylko jeden serwer może mieć jednocześnie flagę stanu Master, nawet w konfiguracji multimaster. Inne serwery w grupie multimaster otrzymują flagi stanu Relay Master i Slave.
Przełącz nowy autowybór nadrzędny
Polecenie przełączania można teraz wywołać, podając jako parametr tylko nazwę instancji monitora. W takim przypadku monitor automatycznie wybierze serwer do promocji.
Wykrywanie opóźnienia replikacji
Pomiar opóźnienia replikacji teraz po prostu odczytuje Seconds_Behind_Master -pole wyjścia statusu slave'ów. Urządzenie podrzędne oblicza tę wartość, porównując znacznik czasu w zdarzeniu binlog, które urządzenie podporządkowane aktualnie przetwarza, z własnym zegarem urządzenia podrzędnego. Jeśli urządzenie podrzędne ma wiele połączeń podrzędnych, używane jest najmniejsze opóźnienie.
Automatyczne przełączanie po wykryciu małej ilości miejsca na dysku
Dzięki najnowszym wersjom MariaDB Server monitor może teraz sprawdzać ilość miejsca na dysku w zapleczu i wykrywać braki na serwerze. W takim przypadku monitor można ustawić tak, aby automatycznie przełączał się z głównego urządzenia o małej ilości miejsca na dysku. Urządzenia Slave można również ustawić w trybie konserwacji. Miejsce na dysku jest również czynnikiem branym pod uwagę przy wyborze nowego mastera do promowania.
Zobacz switchover_on_low_disk_space i maintenance_on_low_disk_space, aby uzyskać więcej informacji.
Funkcja resetowania replikacji
replikacja resetowania polecenie monitor usuwa wszystkie połączenia podrzędne i dzienniki binarne, a następnie konfiguruje replikację. Przydatne, gdy dane są zsynchronizowane, ale identyfikatory gtid nie są.
Obsługa zaplanowanych zdarzeń w trybie przełączania awaryjnego/przełączania/ponownego dołączania
Zdarzenia serwera uruchamiane przez wątek harmonogramu zdarzeń są teraz obsługiwane podczas operacji modyfikacji klastra. Zobacz handle_server_events, aby uzyskać więcej informacji.
Zewnętrzne wsparcie główne
Monitor może wykryć, czy serwer w klastrze replikuje się z zewnętrznego mastera (serwera, który nie jest monitorowany przez monitor MaxScale). Jeśli serwer replikujący jest serwerem głównym klastra, uważa się, że sam klaster posiada zewnętrzny serwer główny.
Jeśli nastąpi przełączenie awaryjne/przełączanie, nowy serwer główny jest ustawiony na replikację z zewnętrznego serwera głównego klastra. Nazwa użytkownika i hasło do replikacji są zdefiniowane w parametrach użytkownik_replikacji i hasło_replikacji. Używany adres i port to te, które są pokazywane przez POKAŻ WSZYSTKIE PODRĘCZNE STATUS na starym głównym serwerze klastra. W przypadku przełączenia stary master również przestaje replikować z serwera zewnętrznego, aby zachować topologię.
Po przełączeniu awaryjnym nowy master jest replikowany z zewnętrznego mastera. Jeśli uszkodzony stary master wróci do trybu online, jest również replikowany z serwera zewnętrznego. Aby znormalizować sytuację, włącz funkcję auto_rejoin lub ręcznie wykonaj ponowne dołączanie. Spowoduje to przekierowanie starego mastera do aktualnego mastera klastra.
W jaki sposób przełączanie awaryjne jest przydatne i ma zastosowanie?
Przełączanie awaryjne pomaga zminimalizować przestoje, wykonywać codzienną konserwację lub radzić sobie z katastrofalnymi i niechcianymi konserwacjami, które czasami mogą wystąpić w niefortunnych momentach. Dzięki zdolności MaxScale do izolowania aplikacji klienckich od serwerów baz danych zaplecza, dodaje cenną funkcjonalność, która pomaga zminimalizować przestoje.
Wtyczka monitorująca MaxScale stale monitoruje stan serwerów baz danych zaplecza. Wtyczka routingu MaxScale następnie wykorzystuje te informacje o stanie, aby zawsze kierować zapytania do serwerów baz danych zaplecza, które są w użyciu. Jest wtedy w stanie wysyłać zapytania do klastrów baz danych zaplecza, nawet jeśli niektóre serwery w klastrze przechodzą konserwację lub występują awarie.
Wysoka konfigurowalność MaxScale umożliwia zachowanie przejrzystości zmian w konfiguracji klastra dla aplikacji klienckich. Na przykład, jeśli nowy serwer musi zostać administracyjnie dodany lub usunięty z klastra master-slave, możesz po prostu dodać konfigurację MaxScale do listy serwerów wtyczek monitora i routera za pomocą konsoli maxadmin CLI. Aplikacja kliencka będzie całkowicie nieświadoma tej zmiany i będzie nadal wysyłać zapytania do bazy danych do portu nasłuchiwania MaxScale.
Utrzymanie serwera bazy danych w utrzymaniu jest proste i łatwe. Po prostu wykonaj następujące polecenie za pomocą maxctrl, a MaxScale przestanie wysyłać jakiekolwiek zapytania do tego serwera. Na przykład
maxctrl: set server DB_785 maintenance
OKNastępnie sprawdź stan serwerów w następujący sposób,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘W trybie konserwacji MaxScale przestanie kierować wszelkie nowe żądania do serwera. W przypadku bieżących żądań MaxScale nie zabije tych sesji, ale raczej pozwoli dokończyć ich wykonanie i nie przerwie żadnych uruchomionych zapytań w trybie konserwacji. Należy również pamiętać, że tryb konserwacji nie jest trwały. Jeśli MaxScale zostanie ponownie uruchomiony, gdy węzeł jest w trybie konserwacji, nowe wystąpienie MariaDB MaxScale nie będzie honorować tego trybu. Jeśli wiele wystąpień MariaDB MaxScale jest skonfigurowanych do korzystania z węzła, należy ustawić tryb konserwacji w każdym wystąpieniu MariaDB MaxScale. Jeśli jednak wiele usług w ramach jednej instancji MariaDB MaxScale korzysta z serwera, wystarczy ustawić tryb konserwacji tylko raz na serwerze, aby wszystkie usługi odnotowały zmianę trybu.
Po zakończeniu konserwacji po prostu wyczyść serwer za pomocą następującego polecenia. Na przykład
maxctrl: clear server DB_785 maintenance
OKSprawdzając, czy wróciło do normy, po prostu uruchom polecenie listuj serwery .
Możesz również wykonać pewne czynności administracyjne za pośrednictwem interfejsu użytkownika ClusterControl. Zobacz przykładowy zrzut ekranu poniżej:
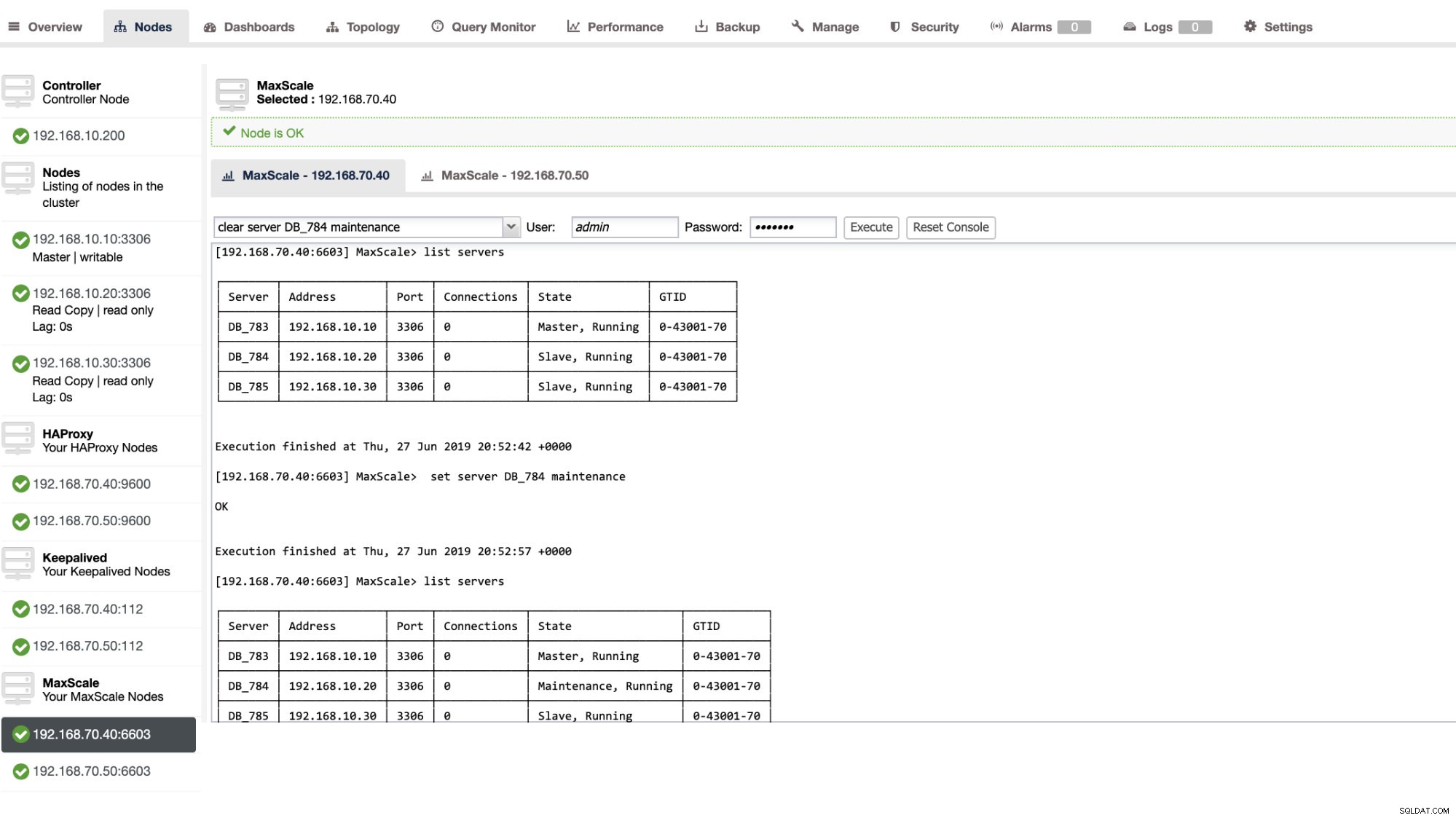
MaxScale Failover w akcji
Automatyczne przełączanie awaryjne
Przełączanie awaryjne MaxScale MariaDB działa bardzo wydajnie i odpowiednio konfiguruje urządzenie podrzędne zgodnie z oczekiwaniami. W tym teście mamy następujący zestaw plików konfiguracyjnych, który został utworzony i zarządzany przez ClusterControl. Zobacz poniżej:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonZwróć uwagę, że tylko auto_failover i automatyczne_ponowne dołączanie to zmienne, które dodałem, ponieważ ClusterControl nie doda tego domyślnie po skonfigurowaniu systemu równoważenia obciążenia MaxScale (zapoznaj się z tym blogiem, aby dowiedzieć się, jak skonfigurować MaxScale za pomocą ClusterControl). Nie zapomnij, że musisz ponownie uruchomić MariaDB MaxScale po zastosowaniu zmian w pliku konfiguracyjnym. Po prostu biegnij,
systemctl restart maxscalei możesz już iść.
Przed przystąpieniem do testu przełączania awaryjnego sprawdźmy najpierw stan klastra:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Wygląda świetnie!
Zabiłem mastera za pomocą komendy pure killer KILL -9 $(pidof mysqld) w moim węźle głównym i widzę, bez zaskoczenia, że monitor szybko to zauważył i uruchomił przełączanie awaryjne. Zobacz dzienniki w następujący sposób:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Przyjrzyjmy się teraz kondycji klastra,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Węzeł 192.168.10.10, który wcześniej był głównym, został wyłączony. Próbowałem ponownie uruchomić i sprawdzić, czy uruchomi się automatyczne ponowne dołączanie, i jak zauważyłeś w dzienniku 2019-06-28 06:39:20.165, tak szybko udało się przechwycić stan węzła, a następnie automatycznie skonfigurować konfigurację, bez kłopotów z włączeniem jej przez administratora.
Teraz, sprawdzając na koniec jego stan, wygląda na to, że działa idealnie, zgodnie z oczekiwaniami. Zobacz poniżej:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Mój były mistrz został naprawiony i odzyskany, a ja chcę się zmienić
Przejście na poprzedniego mistrza również nie jest kłopotliwe. Możesz to obsługiwać za pomocą maxctrl (lub maxadmin w poprzednich wersjach MaxScale) lub przez interfejs użytkownika ClusterControl (jak pokazano wcześniej).
Odwołajmy się po prostu do poprzedniego stanu kondycji klastra replikacji wcześniej i chcieliśmy przełączyć 192.168.10.10 (obecnie podrzędny) z powrotem do stanu nadrzędnego. Zanim przejdziemy dalej, być może będziesz musiał najpierw zidentyfikować monitor, którego będziesz używać. Możesz to sprawdzić za pomocą poniższego polecenia:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Gdy już to zrobisz, możesz wykonać następujące polecenie poniżej, aby przełączyć:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKNastępnie ponownie sprawdź stan klastra,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Wygląda idealnie!
Dzienniki szczegółowo pokażą Ci, jak poszło i serię działań podczas przełączania. Zobacz szczegóły poniżej:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]W przypadku błędnego przełączenia nie będzie kontynuowane, a co za tym idzie wygeneruje błąd, jak pokazano w powyższym logu. Dzięki temu będziesz bezpieczny i żadnych przerażających niespodzianek.
Zapewnianie wysokiej dostępności MaxScale
Chociaż jest to trochę nie na temat w odniesieniu do przełączania awaryjnego, chciałem dodać tutaj kilka cennych punktów dotyczących wysokiej dostępności i ich związku z przełączaniem awaryjnym MariaDB MaxScale.
Zapewnienie wysokiej dostępności MaxScale jest ważną częścią w przypadku awarii systemu, uszkodzenia dysku lub uszkodzenia maszyny wirtualnej. Takie sytuacje są nieuniknione i mogą wpłynąć na stan konfiguracji automatycznego przełączania awaryjnego, gdy wystąpią te nieoczekiwane cykle konserwacji.
W przypadku środowiska typu klastra replikacji jest to bardzo korzystne i wysoce zalecane w przypadku określonej konfiguracji MaxScale. Celem tego jest to, że tylko jedna instancja MaxScale powinna mieć możliwość modyfikowania klastra w danym momencie. Jeśli masz konfigurację z Keepalive, to tutaj są instancje o statusie MASTER. Sam MaxScale nie zna swojego stanu, ale z maxctrl (lub maxadmin w poprzednich wersjach) można ustawić instancję MaxScale w tryb pasywny. Od wersji 2.2.2 pasywny MaxScale zachowuje się podobnie do aktywnego, z tą różnicą, że nie wykona przełączania awaryjnego, przełączania ani ponownego dołączania. Nawet ręczne wersje tych poleceń kończą się błędem. Różnice między trybami pasywnym/aktywnym mogą zostać rozszerzone w przyszłości, więc bądź na bieżąco z takimi zmianami w MaxScale. Aby to zrobić, wykonaj następujące czynności:
maxctrl: alter maxscale passive true
OKMożesz to później zweryfikować, uruchamiając poniższe polecenie:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Jeśli chcesz sprawdzić, jak skonfigurować wysoką dostępność za pomocą Keepalive, sprawdź ten post z MariaDB.
Obsługa VIP
Dodatkowo, ponieważ MaxScale nie ma wbudowanej obsługi VIP, możesz użyć Keepalived do obsługi tego za Ciebie. Wystarczy użyć virtual_ipaddress przypisanego do węzła stanu MASTER. To prawdopodobnie wymyśli zarządzanie wirtualnym adresem IP, podobnie jak MHA ze zmienną master_failover_script. Jak wspomniano wcześniej, zapoznaj się z wpisem na blogu dotyczącym konfiguracji Keepalived z MaxScale, opublikowanym przez MariaDB.
Wniosek
MariaDB MaxScale jest bogata w funkcje i ma wiele możliwości, nie tylko ograniczających się do bycia serwerem proxy i systemem równoważenia obciążenia, ale także oferuje mechanizm przełączania awaryjnego, którego szukają duże organizacje. Jest to prawie uniwersalne oprogramowanie, ale oczywiście ma ograniczenia, których może wymagać określona aplikacja, w przeciwieństwie do innych systemów równoważenia obciążenia, takich jak ProxySQL.
ClusterControl oferuje również automatyczne przełączanie awaryjne i główny mechanizm automatycznego wykrywania, a także odzyskiwanie klastrów i węzłów z możliwością wdrożenia Maxscale i innych technologii równoważenia obciążenia.
Każde z tych narzędzi ma swoje zróżnicowane funkcje i funkcje, ale MariaDB MaxScale jest dobrze obsługiwana przez ClusterControl i może być wdrożona w rozsądny sposób wraz z Keepalved, HAProxy, aby przyspieszyć wykonywanie codziennych rutynowych zadań.