Typowy administrator bazy danych MySQL może być znany z pracy i zarządzania bazą danych OLTP (przetwarzania transakcji online) w ramach swojej codziennej rutyny. Możesz być zaznajomiony z tym, jak to działa i jak zarządzać złożonymi operacjami. Chociaż domyślny silnik pamięci masowej dostarczany przez MySQL jest wystarczająco dobry dla OLAP (przetwarzania analitycznego online), jest dość uproszczony, zwłaszcza dla tych, którzy chcą nauczyć się sztucznej inteligencji lub zajmują się prognozowaniem, eksploracją danych, analizą danych.
W tym blogu omówimy MariaDB ColumnStore. Treść zostanie dostosowana z korzyścią dla DBA MySQL, który może mieć mniejszą wiedzę na temat ColumnStore i jego zastosowania w aplikacjach OLAP (Online Analytical Processing).
OLTP a OLAP
OLTP
Zasoby pokrewne Analityka z MariaDB AX — kolumnowy magazyn danych typu Open Source Wprowadzenie do baz danych szeregów czasowych Hybrydowe obciążenia bazy danych OLTP/Analytics w klastrze Galera przy użyciu asynchronicznych modułów podrzędnychTypowym działaniem MySQL DBA do obsługi tego typu danych jest użycie OLTP (przetwarzania transakcji online). OLTP charakteryzuje się dużymi transakcjami w bazie danych, które wykonują wstawianie, aktualizowanie lub usuwanie. Bazy danych typu OLTP są wyspecjalizowane do szybkiego przetwarzania zapytań i utrzymywania integralności danych podczas uzyskiwania dostępu w wielu środowiskach. Jego skuteczność mierzona jest liczbą transakcji na sekundę (tps). Dość często zdarza się, że tabele relacji rodzic-dziecko (po zaimplementowaniu formularza normalizacji) zmniejszają nadmiarowe dane w tabeli.
Rekordy w tabeli są zwykle przetwarzane i przechowywane sekwencyjnie w sposób zorientowany na wiersze i są silnie indeksowane za pomocą unikalnych kluczy w celu optymalizacji pobierania lub zapisu danych. Jest to również powszechne w przypadku MySQL, zwłaszcza gdy mamy do czynienia z dużymi wstawkami lub dużą liczbą jednoczesnych zapisów lub zbiorczych wstawek. Większość silników pamięci masowej obsługiwanych przez MariaDB ma zastosowanie do aplikacji OLTP — InnoDB (domyślny silnik pamięci masowej od wersji 10.2), XtraDB, TokuDB, MyRocks lub MyISAM/Aria.
Aplikacje takie jak CMS, FinTech, Web Apps często radzą sobie z dużymi zapisami i odczytami oraz często wymagają dużej przepustowości. Aby te aplikacje działały, często wymaga głębokiej wiedzy z zakresu wysokiej dostępności, nadmiarowości, odporności i odzyskiwania.
OLAP
OLAP radzi sobie z tymi samymi wyzwaniami, co OLTP, ale stosuje inne podejście (zwłaszcza w przypadku pobierania danych). OLAP radzi sobie z większymi zestawami danych i jest powszechny w przypadku hurtowni danych, często używany w aplikacjach typu business intelligence. Jest powszechnie używany do zarządzania wydajnością firmy, planowania, budżetowania, prognozowania, raportowania finansowego, analiz, modeli symulacyjnych, odkrywania wiedzy i raportowania w hurtowni danych.
Dane przechowywane w OLAP zwykle nie są tak krytyczne, jak te przechowywane w OLTP. Dzieje się tak, ponieważ większość danych można zasymulować, pochodzących z OLTP, a następnie można je wprowadzić do bazy danych OLAP. Dane te są zwykle używane do ładowania zbiorczego, często potrzebnego do analiz biznesowych, które ostatecznie są renderowane na wykresach wizualnych. OLAP wykonuje również wielowymiarową analizę danych biznesowych i dostarcza wyniki, które można wykorzystać do złożonych obliczeń, analizy trendów lub zaawansowanego modelowania danych.
OLAP zazwyczaj trwale przechowuje dane w formacie kolumnowym. Jednak w MariaDB ColumnStore rekordy są dzielone na podstawie kolumn i są przechowywane oddzielnie w pliku. W ten sposób pobieranie danych jest bardzo wydajne, ponieważ skanuje tylko odpowiednią kolumnę, do której odnosi się zapytanie z instrukcją SELECT.
Pomyśl o tym w ten sposób, przetwarzanie OLTP obsługuje codzienne i kluczowe transakcje danych, które uruchamiają Twoją aplikację biznesową, podczas gdy OLAP pomaga zarządzać, przewidywać, analizować i lepiej sprzedawać produkt — elementy składowe posiadania aplikacji biznesowej.
Co to jest MariaDB ColumnStore?
MariaDB ColumnStore to podłączany mechanizm kolumnowej pamięci masowej, który działa na serwerze MariaDB Server. Wykorzystuje równolegle rozproszoną architekturę danych, zachowując ten sam interfejs ANSI SQL, który jest używany w całym portfolio serwerów MariaDB. Ten silnik pamięci istnieje już od jakiegoś czasu, ponieważ został pierwotnie przeniesiony z InfiniDB (obecnie nieistniejący kod, który jest nadal dostępny na github). Jest przeznaczony do skalowania dużych zbiorów danych (do przetwarzania petabajtów danych), skalowalności liniowej i rzeczywistego -czas odpowiedzi na zapytania analityczne. Wykorzystuje zalety we/wy pamięci kolumnowej; kompresja, projekcja just-in-time oraz partycjonowanie poziome i pionowe, aby zapewnić niesamowitą wydajność podczas analizowania dużych zestawów danych.
Wreszcie MariaDB ColumnStore jest podstawą ich produktu MariaDB AX jako głównego silnika pamięci masowej używanego przez tę technologię.
Czym różni się MariaDB ColumnStore od InnoDB?
InnoDB ma zastosowanie do przetwarzania OLTP, które wymaga, aby aplikacja odpowiadała w możliwie najszybszy sposób. Jest to przydatne, jeśli Twoja aplikacja ma do czynienia z taką naturą. Z drugiej strony MariaDB ColumnStore jest odpowiednim wyborem do zarządzania transakcjami dużych zbiorów danych lub dużymi zestawami danych, które obejmują złożone łączenia, agregację na różnych poziomach hierarchii wymiarów, prognozowanie sumy finansowej dla szerokiego zakresu lat lub korzystanie z równości i selekcji zakresów . Te podejścia przy użyciu ColumnStore nie wymagają indeksowania tych pól, ponieważ mogą one działać wystarczająco szybciej. InnoDB tak naprawdę nie radzi sobie z tego typu wydajnością, chociaż nic nie stoi na przeszkodzie, aby spróbować tego, co jest możliwe w przypadku InnoDB, ale za cenę. Wymaga to dodania indeksów, które dodają duże ilości danych do pamięci dyskowej. Oznacza to, że zakończenie zapytania może zająć więcej czasu i może w ogóle się nie skończyć, jeśli jest uwięzione w pętli czasu.
Architektura magazynu kolumn MariaDB
Spójrzmy na architekturę MariaDB ColumStore poniżej:
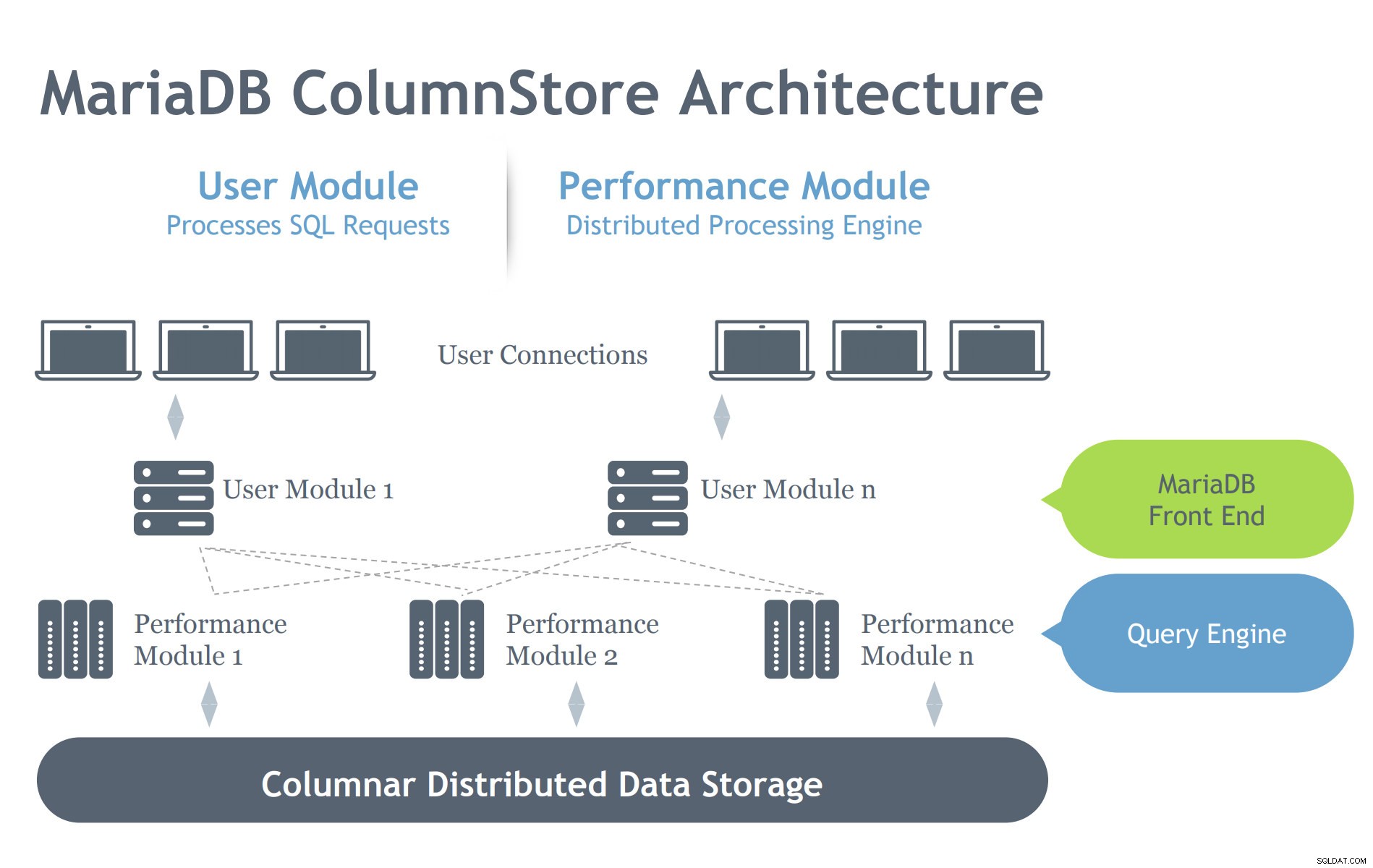 Obraz dzięki uprzejmości prezentacji MariaDB ColumnStore
Obraz dzięki uprzejmości prezentacji MariaDB ColumnStore W przeciwieństwie do architektury InnoDB, ColumnStore zawiera dwa moduły, co oznacza, że jego celem jest wydajna praca w rozproszonym środowisku architektonicznym. InnoDB jest przeznaczony do skalowania na serwerze, ale obejmuje wiele wzajemnie połączonych węzłów w zależności od konfiguracji klastra. W związku z tym ColumnStore ma wiele poziomów komponentów, które dbają o procesy wymagane do serwera MariaDB. Przyjrzyjmy się tym komponentom poniżej:
- Moduł użytkownika (UM):Jednostka UM jest odpowiedzialna za analizowanie żądań SQL w zoptymalizowany zestaw podstawowych kroków zadania wykonywanych przez jeden lub więcej serwerów PM. UM jest zatem odpowiedzialna za optymalizację zapytań i orkiestrację wykonywania zapytań przez serwery PM. Chociaż w ramach wdrożenia wieloserwerowego można wdrożyć wiele instancji usługi UM, za każde zapytanie odpowiada jedna usługa UM. System równoważenia obciążenia bazy danych, taki jak MariaDB MaxScale, może zostać wdrożony w celu odpowiedniego zrównoważenia zewnętrznych żądań względem poszczególnych serwerów UM.
- Moduł wydajności (PM):PM wykonuje szczegółowe kroki zadania otrzymane z UM w sposób wielowątkowy. ColumnStore umożliwia dystrybucję pracy na wiele modułów wydajności. UM składa się z procesu MariaDB mysqld i procesu ExeMgr.
- Mapy zasięgu:ColumnStore przechowuje metadane dotyczące każdej kolumny we współdzielonym obiekcie rozproszonym, znanym jako mapa zasięgu. Serwer UM odwołuje się do mapy zasięgu, aby pomóc w generowaniu poprawnych kroków zadania podstawowego. Serwer PM odwołuje się do mapy zasięgu, aby zidentyfikować prawidłowe bloki dysku do odczytania. Każda kolumna składa się z jednego lub więcej plików, a każdy plik może zawierać wiele ekstentów. W miarę możliwości system próbuje przydzielić ciągłą fizyczną pamięć masową, aby poprawić wydajność odczytu.
- Pamięć:ColumnStore może używać pamięci lokalnej lub współdzielonej (np. SAN lub EBS) do przechowywania danych. Korzystanie z pamięci współdzielonej pozwala na automatyczne przełączenie przetwarzania danych do innego węzła w przypadku awarii serwera PM.
Poniżej przedstawiamy, jak MariaDB ColumnStore przetwarza zapytanie,
- Klienci wysyłają zapytanie do serwera MariaDB działającego w module użytkownika. Serwer wykonuje operację na tabeli dla wszystkich tabel potrzebnych do spełnienia żądania i uzyskuje początkowy plan wykonania zapytania.
- Korzystając z interfejsu silnika pamięci masowej MariaDB, ColumnStore konwertuje obiekt tabeli serwera na obiekty ColumnStore. Obiekty te są następnie wysyłane do procesów modułu użytkownika.
- Moduł użytkownika konwertuje plan wykonania MariaDB i optymalizuje podane obiekty na plan wykonania ColumnStore. Następnie określa kroki potrzebne do uruchomienia zapytania i kolejność, w jakiej muszą zostać uruchomione.
- Moduł użytkownika konsultuje się następnie z mapą zakresu, aby określić, które moduły wydajności należy sprawdzić w celu uzyskania potrzebnych danych, a następnie wykonuje eliminację zakresu, eliminując z listy wszystkie moduły wydajności, które zawierają tylko dane spoza zakresu wymaganego przez zapytanie.
- Moduł użytkownika następnie wysyła polecenia do jednego lub więcej modułów wydajności, aby wykonać blokowe operacje we/wy.
- Moduł lub moduły wydajności przeprowadzają filtrowanie predykatów, przetwarzanie łączenia, początkową agregację danych z pamięci lokalnej lub zewnętrznej, a następnie wysyłają dane z powrotem do modułu użytkownika.
- Moduł użytkownika wykonuje ostateczną agregację zestawu wyników i tworzy zestaw wyników dla zapytania.
- Moduł użytkownika / ExeMgr implementuje dowolne obliczenia funkcji okna, a także wszelkie niezbędne sortowanie w zestawie wyników. Następnie zwraca zestaw wyników na serwer.
- Serwer MariaDB wykonuje dowolne funkcje listy wyboru, operacje ORDER BY i LIMIT na zestawie wyników.
- Serwer MariaDB zwraca zestaw wyników do klienta.
Paradygmaty wykonywania zapytań
Przyjrzyjmy się nieco więcej, w jaki sposób ColumnStore wykonuje zapytanie i kiedy ma ono wpływ.
ColumnStore różni się od standardowych silników pamięci masowej MySQL/MariaDB, takich jak InnoDB, ponieważ ColumnStore zwiększa wydajność, skanując tylko niezbędne kolumny, wykorzystując partycjonowanie obsługiwane przez system oraz wykorzystując wiele wątków i serwerów do skalowania czasu odpowiedzi na zapytania. Wydajność jest korzystna, gdy uwzględniasz tylko kolumny, które są niezbędne do pobierania danych. Oznacza to, że zachłanna gwiazdka (*) w zapytaniu wybierającym ma znaczący wpływ w porównaniu z SELECT
Podobnie jak w przypadku InnoDB i innych silników pamięci masowej, typ danych ma również znaczenie dla wydajności tego, z czego korzystasz. Jeśli powiedzmy, że masz kolumnę, która może mieć tylko wartości od 0 do 100, zadeklaruj to jako tinyint, ponieważ będzie to reprezentowane przez 1 bajt zamiast 4 bajtów dla int. Zmniejszy to koszt we/wy czterokrotnie. W przypadku typów łańcuchowych ważnym progiem jest char(9) i varchar(8) lub wyższy. Każdy plik przechowywania kolumn wykorzystuje stałą liczbę bajtów na wartość. Umożliwia to szybkie wyszukiwanie pozycji innych kolumn w celu utworzenia wiersza. Obecnie górny limit dla kolumnowego przechowywania danych wynosi 8 bajtów. Tak więc dla łańcuchów dłuższych niż ten system utrzymuje dodatkowy zasięg „słownika”, w którym przechowywane są wartości. Kolumnowy plik ekstentu przechowuje następnie wskaźnik w słowniku. Tak więc na przykład odczytywanie i przetwarzanie kolumny varchar(8) niż kolumny char(8) jest droższe. Więc tam, gdzie to możliwe, uzyskasz lepszą wydajność, jeśli możesz użyć krótszych ciągów, zwłaszcza jeśli unikniesz wyszukiwania słownika. Wszystkie typy danych TEXT/BLOB w wersji 1.1 korzystają ze słownika i w razie potrzeby przeprowadzają wyszukiwanie wielu bloków 8KB, aby pobrać te dane, im dłuższe dane, tym więcej bloków jest pobieranych i tym większy potencjalny wpływ na wydajność.
W systemie opartym na wierszach dodanie nadmiarowych kolumn zwiększa ogólny koszt zapytania, ale w systemie kolumnowym koszt występuje tylko wtedy, gdy występuje odwołanie do kolumny. Dlatego należy utworzyć dodatkowe kolumny, aby wspierać różne ścieżki dostępu. Na przykład przechowuj wiodącą część pola w jednej kolumnie, aby umożliwić szybsze wyszukiwanie, ale dodatkowo przechowuj wartość w długim formularzu jako inną kolumnę. Skanowanie krótszego kodu lub kolumny wiodącej części będzie szybsze.
Sprzężenia zapytań są zoptymalizowane pod kątem sprzężeń na dużą skalę i pozwalają uniknąć konieczności stosowania indeksów i narzutów związanych z przetwarzaniem pętli zagnieżdżonych. ColumnStore utrzymuje statystyki tabeli, aby określić optymalną kolejność łączenia. Podobne podejścia współdzielą z InnoDB, na przykład, jeśli łączenie jest zbyt duże dla pamięci UM, wykorzystuje łączenie dyskowe, aby zapytanie zostało zakończone.
W przypadku agregacji ColumnStore dystrybuuje ocenę agregacji tak bardzo, jak to możliwe. Oznacza to, że współużytkuje on usługi UM i PM w celu obsługi zapytań, szczególnie lub bardzo dużej liczby wartości w kolumnach zagregowanych. Select count(*) jest wewnętrznie zoptymalizowany, aby wybrać najmniejszą liczbę bajtów pamięci w tabeli. Oznacza to, że wybrałby kolumnę CHAR(1) (używa 1 bajtu) zamiast kolumny INT, która zajmuje 4 bajty. Implementacja nadal honoruje semantykę ANSI, ponieważ select count(*) będzie uwzględniać wartości null w całkowitej liczbie, w przeciwieństwie do jawnego select(COL-N), który wyklucza wartości null z licznika.
Kolejność i limit są obecnie implementowane na samym końcu przez proces serwera mariadb na tymczasowej tabeli zbioru wyników. Zostało to wspomniane w kroku 9, w jaki sposób ColumnStore przetwarza zapytanie. Z technicznego punktu widzenia wyniki są przekazywane do MariaDB Server w celu posortowania danych.
W przypadku złożonych zapytań, które używają podzapytań, jest to w zasadzie to samo podejście, w którym są wykonywane kolejno i zarządzane przez UM, tak samo jak w przypadku funkcji Window obsługiwanych przez UM, ale używa dedykowanego szybszego procesu sortowania, więc jest w zasadzie szybsze.
Partycjonowanie danych jest zapewniane przez ColumnStore, który korzysta z mapy zasięgu, która utrzymuje minimalne/maksymalne wartości danych kolumn i zapewnia logiczny zakres partycjonowania oraz eliminuje potrzebę indeksowania. Mapy rozszerzeń zapewniają również ręczne partycjonowanie tabel, widoki zmaterializowane, tabele podsumowań oraz inne struktury i obiekty, które muszą być zaimplementowane w bazach danych opartych na wierszach w celu zapewnienia wydajności zapytań. Istnieją pewne korzyści dla wartości kolumnowych, gdy są one uporządkowane lub częściowo uporządkowane, ponieważ umożliwia to bardzo efektywne partycjonowanie danych. W przypadku wartości minimalnych i maksymalnych mapy całego zasięgu po filtrowaniu i wykluczeniu zostaną wyeliminowane. Zobacz tę stronę w ich podręczniku dotyczącym eliminacji zakresu. Zwykle działa to szczególnie dobrze w przypadku danych szeregów czasowych lub podobnych wartości, które z czasem rosną.
Instalowanie MariaDB ColumnStore
Instalacja MariaDB ColumnStore może być prosta i nieskomplikowana. MariaDB ma tutaj szereg notatek, do których możesz się odwołać. W przypadku tego bloga naszym docelowym środowiskiem instalacji jest CentOS 7. Możesz przejść do tego łącza https://downloads.mariadb.com/ColumnStore/1.2.4/ i sprawdzić pakiety oparte na środowisku systemu operacyjnego. Zapoznaj się z poniższymi szczegółowymi krokami, które pomogą Ci przyspieszyć:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Po zakończeniu musisz uruchomić postConfigure polecenie, aby w końcu zainstalować i skonfigurować MariaDB ColumnStore. W tej przykładowej instalacji są dwa węzły, które skonfigurowałem na włóczęgiej maszynie:
csnode1:192.168.2.10
csnode2:192.168.2.20
Oba te węzły są zdefiniowane w odpowiednich /etc/hosts i oba węzły są ustawione tak, aby mieć połączone moduły użytkownika i wydajności na obu hostach. Instalacja jest początkowo trochę banalna. Dlatego dzielimy się tym, jak możesz to skonfigurować, aby mieć podstawę. Zobacz szczegóły poniżej, aby zapoznać się z przykładowym procesem instalacji:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Po zakończeniu instalacji i konfiguracji MariaDB utworzy dla tego konfigurację master/slave, więc wszystko, co załadowaliśmy z csnode1, zostanie zreplikowane do csnode2.
Zrzucanie Big Data
Po instalacji możesz nie mieć przykładowych danych do wypróbowania. Firma IMDB udostępniła przykładowe dane, które można pobrać na swojej stronie https://www.imdb.com/interfaces/. Na potrzeby tego bloga stworzyłem skrypt, który zrobi wszystko za Ciebie. Sprawdź to tutaj https://github.com/paulnamuag/columnstore-imdb-data-load. Po prostu spraw, aby był wykonywalny, a następnie uruchom skrypt. Zrobi wszystko za Ciebie, pobierając pliki, tworząc schemat, a następnie ładując dane do bazy danych. To takie proste.
Wykonywanie przykładowych zapytań
Teraz spróbujmy uruchomić kilka przykładowych zapytań.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Zasadniczo jest to szybsze i szybkie. Istnieją zapytania, których nie można przetworzyć tak samo, jak uruchamiane z innymi silnikami pamięci masowej, takimi jak InnoDB. Na przykład próbowałem się pobawić i wykonać kilka głupich zapytań i zobaczyć, jak reaguje i powoduje:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Stąd znalazłem MCOL-1620 i MCOL-131 i wskazuje to na ustawienie zmiennej infinidb_vtable_mode. Zobacz poniżej:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Ale ustawienie infinidb_vtable_mode=0 , co oznacza, że traktuje zapytanie jako ogólny i wysoce zgodny tryb przetwarzania wiersz po wierszu. Niektóre składniki klauzuli WHERE mogą być przetwarzane przez ColumnStore, ale łączenia są przetwarzane w całości przez mysqld przy użyciu mechanizmu łączenia z zagnieżdżoną pętlą. Zobacz poniżej:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Zajęło to trochę czasu, ponieważ wyjaśnia, że zostało przetworzone w całości przez mysqld. Mimo to optymalizacja i pisanie dobrych zapytań to nadal najlepsze podejście i nie delegowanie wszystkiego do ColumnStore.
Dodatkowo możesz skorzystać z pomocy w analizowaniu zapytań, uruchamiając polecenia, takie jak SELECT calSetTrace(1); lub SELECT calGetStats(); . Możesz użyć tych zestawów poleceń, na przykład zoptymalizować niskie i złe zapytania lub wyświetlić plan zapytań. Sprawdź to tutaj, aby uzyskać więcej informacji na temat analizy zapytań.
Administrowanie sklepem ColumnStore
Po pełnej konfiguracji MariaDB ColumnStore jest dostarczana z narzędziem o nazwie mcsadmin, którego można używać do wykonywania niektórych zadań administracyjnych. Możesz również użyć tego narzędzia, aby dodać kolejny moduł, przypisać lub przenieść do DBroots od PM do PM, itp. Sprawdź ich instrukcję na temat tego narzędzia.
Zasadniczo możesz wykonać następujące czynności, na przykład sprawdzenie informacji o systemie:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Wniosek
MariaDB ColumnStore to bardzo wydajny silnik pamięci masowej do przetwarzania OLAP i dużych zbiorów danych. Jest to całkowicie open source, co jest bardzo korzystne w użyciu niż korzystanie z zastrzeżonych i drogich baz danych OLAP dostępnych na rynku. Istnieją jednak inne alternatywy do wypróbowania, takie jak ClickHouse, Apache HBase lub cstore_fdw firmy Citus Data. Jednak żadne z nich nie używa MySQL/MariaDB, więc może to nie być realną opcją, jeśli zdecydujesz się pozostać przy wariantach MySQL/MariaDB.