HBase zapisuje dane na wielu serwerach, zwanych serwerami regionalnymi .
Każdy serwer regionu zawiera jeden lub kilka regionów , a dane są alokowane w tych regionach; Hbase będzie kontrolować, który serwer regionu kontroluje regiony.
Ilość regionów można zdefiniować na poziomie tworzenia tabeli:
[hbase@gw vagrant]$ kinit -kt /etc/security/keytabs/hbase.headless.keytab hbase
[hbase@gw vagrant]$ hbase shell
hbase(main):001:0> create 'table2', 'columnfamily1', {NUMREGIONS => 5, SPLITALGO => 'HexStringSplit'}Wcześniej określiliśmy, że 5 regionów będzie dokładnych, pod względem liczby serwerów regionalnych i pożądanego rozmiaru regionów, oraz 2 podstawowe algorytmy, HexStringSplit i UniformSplit (ale możesz dodać swoje).
Możesz zapewnić własne podziały :
hbase(main):001:0> create 'table2', 'columnfamily1', {NUMREGIONS => 5, SPLITS=> ['a', 'b', 'c']}
Więc ta tabela2 został stworzony z naszymi 5 regionami, przejdźmy do HBase webUI, aby zobaczyć, jak to wygląda :
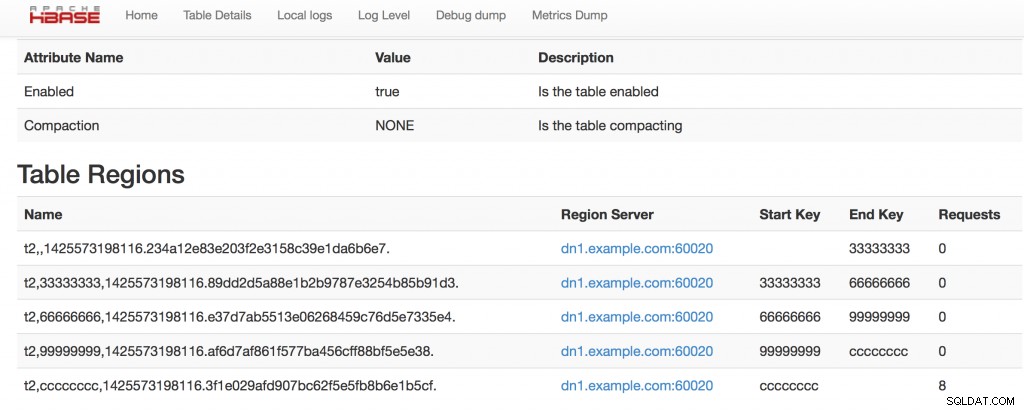 Mamy swoje 5 regionów, widzimy podział kluczy, a w nazwach regionów możemy zobaczyć:nazwa_tabeli, start_key,end_key,timestamp.ENCODED_REGIONNAME.
Mamy swoje 5 regionów, widzimy podział kluczy, a w nazwach regionów możemy zobaczyć:nazwa_tabeli, start_key,end_key,timestamp.ENCODED_REGIONNAME.
Więc teraz, jeśli chcemy scalić regiony, możemy użyć merge_region w powłoce hbase.
Regiony muszą przylegać do siebie.
hbase(main):010:0> merge_region '234a12e83e203f2e3158c39e1da6b6e7', '89dd2d5a88e1b2b9787e3254b85b91d3'
0 row(s) in 0.0140 secondsTak.
Zauważ, że ENCODED_REGIONNAME regionu wyników jest nowy.
hbase(main):012:0> merge_region 'bfad503057fca37bd60b5a83109f7dc6','e37d7ab5513e06268459c76d5e7335e4'
0 row(s) in 0.0040 secondsW końcu połączmy wszystkie regiony!
hbase(main):013:0> merge_region '0f5fc22bf0beacbf83c1ad562324c778','af6d7af861f577ba456cff88bf5e5e38','3f1e029afd907bc62f5e5fb8b6e1b5cf','3f1e029afd907bc62f5e5fb8b6e1b5cf'
0 row(s) in 0.0290 secondsWtedy widzimy, że pozostał tylko jeden region :

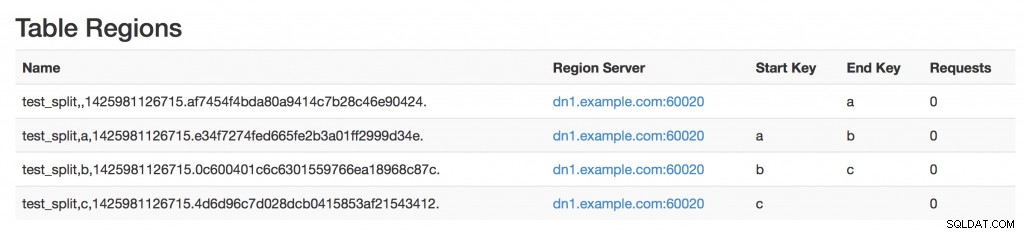
Dla rekordu możesz utworzyć wstępnie podzieloną tabelę HBase, jeśli znasz podział kluczy:albo przez przekazanie SPLITS, albo przez podanie SPLITS_FILE, który zawiera punkty podziału (więc liczba linii =regiony -1)
Zwróć uwagę na kolejność, SPLITS_FILE zanim {…} nie będzie działać.
[hbase@gw vagrant]$ echo "a\nb\nc" > /tmp/splits.txt;
[hbase@gw vagrant]$ kinit -kt /etc/security/keytabs/hbase.headless.keytab hbase
[hbase@gw vagrant]$ hbase shell
hbase(main):011:0> create 'test_split', { NAME=> 'cf', VERSIONS => 1, TTL => 69200 }, SPLITS_FILE => '/tmp/splits.txt'A wynik: