Jeśli chcesz wiedzieć wszystko o Hadoop MapReduce, jesteś we właściwym miejscu. Ten samouczek MapReduce zawiera kompletny przewodnik dotyczący każdego i wszystkiego w Hadoop MapReduce.
W tym wprowadzeniu do MapReduce dowiesz się, czym jest Hadoop MapReduce i jak działa struktura MapReduce. Artykuł obejmuje również MapReduce DataFlow, różne fazy w MapReduce, Mapper, Reducer, Partitioner, Cominer, Tasowanie, Sortowanie, Lokalizacja danych i wiele innych.
Wymieniliśmy również zalety frameworka MapReduce.
Najpierw zbadajmy, dlaczego potrzebujemy Hadoop MapReduce.
Dlaczego MapReduce?
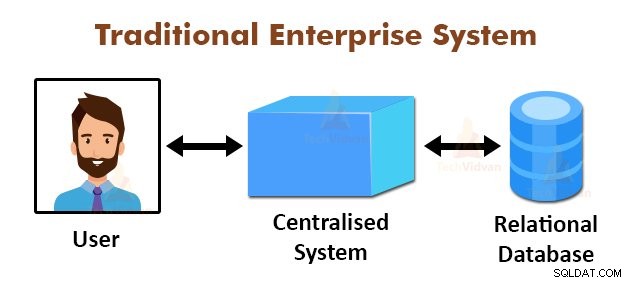
Powyższy rysunek przedstawia schematyczny widok tradycyjnych systemów korporacyjnych. Tradycyjne systemy zwykle posiadają scentralizowany serwer do przechowywania i przetwarzania danych. Ten model nie nadaje się do przetwarzania ogromnych ilości skalowalnych danych.
Ponadto ten model nie mógł być uwzględniony przez standardowe serwery baz danych. Ponadto scentralizowany system tworzy zbyt duże wąskie gardło podczas przetwarzania wielu plików jednocześnie.
Korzystając z algorytmu MapReduce, Google rozwiązało ten problem z wąskim gardłem. Struktura MapReduce dzieli zadanie na małe części i przypisuje zadania do wielu komputerów.
Później wyniki są gromadzone w jednym miejscu, a następnie integrowane w celu utworzenia zestawu danych wynikowych.
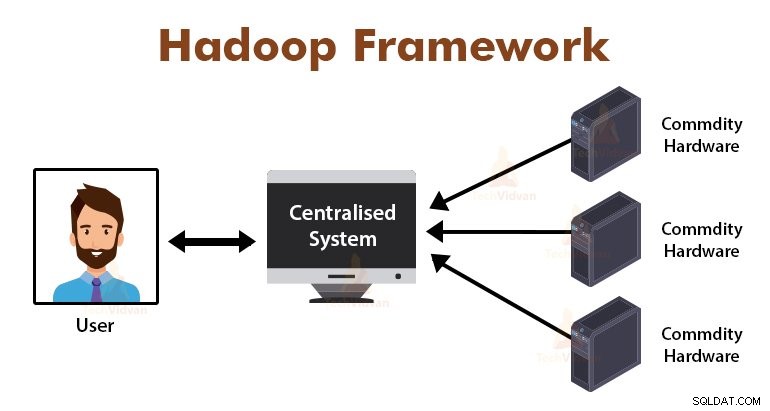
Wprowadzenie do MapReduce Framework
MapReduce to warstwa przetwarzania w Hadoop. Jest to platforma programowa przeznaczona do równoległego przetwarzania ogromnych ilości danych poprzez dzielenie zadania na zestaw niezależnych zadań.
Musimy tylko umieścić logikę biznesową w sposobie działania MapReduce, a framework zajmie się resztą. Struktura MapReduce działa, dzieląc zadanie na małe zadania i przypisując je do jednostek podrzędnych.
Programy MapReduce są napisane w określonym stylu, na który wpływ mają konstrukcje programowania funkcjonalnego, specyficzne idiomy do przetwarzania list danych.
W MapReduce dane wejściowe mają postać listy, a dane wyjściowe z frameworka również mają postać listy. MapReduce jest sercem Hadoop. Wydajność i moc Hadoop wynika z przetwarzania równoległego w ramach MapReduce.
Przyjrzyjmy się teraz, jak działa Hadoop MapReduce.
Jak działa Hadoop MapReduce?
Struktura Hadoop MapReduce działa, dzieląc zadanie na niezależne zadania i wykonując je na maszynach podrzędnych. Zadanie MapReduce jest wykonywane w dwóch etapach, które są fazą mapy i fazą redukcji.
Wejście i wyjście z obu faz to pary klucz, wartości. Struktura MapReduce opiera się na zasadzie lokalizacji danych (omówionej później), co oznacza, że wysyła obliczenia do węzłów, w których znajdują się dane.
- Faza mapy − W fazie mapy funkcja mapy zdefiniowana przez użytkownika przetwarza dane wejściowe. W funkcji mapy użytkownik umieszcza logikę biznesową. Dane wyjściowe z fazy Map są danymi pośrednimi i są przechowywane na dysku lokalnym.
- Faza redukcji – Ta faza jest kombinacją fazy tasowania i fazy redukcji. W fazie Redukcja dane wyjściowe z etapu mapy są przekazywane do Reduktora, gdzie są agregowane. Wyjściem fazy Reduce jest wyjściem końcowym. W fazie redukcji zdefiniowana przez użytkownika funkcja redukcji przetwarza dane wyjściowe Maperów i generuje wyniki końcowe.
Podczas zadania MapReduce platforma Hadoop wysyła zadania Map i zadania Reduce do odpowiednich komputerów w klastrze.
Sam framework zarządza wszystkimi szczegółami przekazywania danych, takimi jak wydawanie zadań, weryfikacja wykonania zadania i kopiowanie danych między węzłami w klastrze. Zadania odbywają się na węzłach, w których znajdują się dane w celu zmniejszenia ruchu sieciowego.
Przepływ danych MapReduce
Wszyscy mogą chcieć wiedzieć, jak te pary klucz-wartość są generowane i jak MapReduce przetwarza dane wejściowe. Ta sekcja zawiera odpowiedzi na wszystkie te pytania.
Zobaczmy, jak dane muszą przepływać z różnych faz w Hadoop MapReduce, aby obsługiwać nadchodzące dane w sposób równoległy i rozproszony.
1. Pliki wejściowe
Wejściowy zestaw danych, który ma zostać przetworzony przez program MapReduce, jest przechowywany w InputFile. InputFile jest przechowywany w rozproszonym systemie plików Hadoop.
2. InputSplit
Rekord w InputFiles jest podzielony na model logiczny. Rozmiar podziału jest ogólnie równy rozmiarowi bloku HDFS. Każdy podział jest przetwarzany przez indywidualnego twórcę map.
3. InputFormat
InputFormat określa specyfikację pliku wejściowego. Definiuje sposób, w jaki RecordReader jest konwertowany do rekordu z InputFile na pary klucz-wartość.
4. RekordReader
RecordReader odczytuje dane z InputSplit i konwertuje rekordy na pary kluczy, wartości i prezentuje je podmiotom mapującym.
5. Twórcy map
Programy mapujące pobierają pary kluczy i wartości jako dane wejściowe z RecordReader i przetwarzają je poprzez implementację funkcji mapowania zdefiniowanej przez użytkownika. W każdym Maperze na raz przetwarzany jest jeden podział.
Deweloper umieścił logikę biznesową w funkcji mapy. Dane wyjściowe wszystkich programów mapujących są danymi pośrednimi, które również mają postać pary klucz-wartość.
6. Tasuj i sortuj
Pośrednie dane wyjściowe generowane przez Mappery są sortowane przed przekazaniem do Reduktora w celu zmniejszenia przeciążenia sieci. Posortowane wyjścia pośrednie są następnie tasowane przez sieć do Reduktora.
7. Reduktor
Reduktor przetwarza i agreguje dane wyjściowe Mappera, implementując funkcję redukcji zdefiniowaną przez użytkownika. Wynik programu Reduktory jest ostatecznym wynikiem i jest przechowywany w rozproszonym systemie plików Hadoop (HDFS).
Przeanalizujmy teraz niektóre terminologie i zaawansowane koncepcje struktury Hadoop MapReduce.
Pary klucz-wartość w MapReduce
Struktura MapReduce działa na parach klucz, wartość, ponieważ zajmuje się schematem niestatycznym. Pobiera dane w postaci klucza, pary wartości, a generowane dane wyjściowe są również w postaci klucza, par wartości.
Para klucz-wartość MapReduce to jednostka rekordu, która jest odbierana przez zadanie MapReduce w celu wykonania. W parze klucz-wartość:
- Klucz to przesunięcie linii od początku linii w pliku.
- Wartość to zawartość linii, z wyłączeniem końcówek linii.
Partitioner MapReduce
Hadoop MapReduce Partitioner partycjonuje przestrzeń kluczy. Przestrzeń kluczy partycjonowania w MapReduce określa, że wszystkie wartości każdego klucza zostały zgrupowane razem i zapewnia, że wszystkie wartości pojedynczego klucza muszą trafić do tego samego elementu redukującego.
To partycjonowanie umożliwia równomierne rozłożenie danych wyjściowych mapera na Reduktor, zapewniając, że właściwy klucz trafia do właściwego Reduktora.
Domyślnym partycjonerem MapReducer jest Hash Partitioner, który partycjonuje przestrzenie kluczy na podstawie wartości skrótu.
Łącznik MapReduce
MapReduce Combiner jest również znany jako „Semi-Reducer”. Odgrywa główną rolę w zmniejszaniu przeciążenia sieci. Struktura MapReduce zapewnia funkcjonalność definiowania Combinera, która łączy pośrednie dane wyjściowe z Maperów przed przekazaniem ich do Reduktora.
Agregacja danych wyjściowych Mappera przed przekazaniem do Reduktora pomaga frameworkowi przetasować małe ilości danych, co prowadzi do niskiego przeciążenia sieci.
Główną funkcją Combinera jest podsumowanie danych wyjściowych Maperów tym samym kluczem i przekazanie ich do Reduktora. Klasa Combiner jest używana między klasą Mapper a klasą Reducer.
Lokalizacja danych w MapReduce
Lokalizacja danych odnosi się do „Przenoszenie obliczeń bliżej danych zamiast przenoszenia danych do obliczeń”. Jest o wiele bardziej wydajne, jeśli obliczenia żądane przez aplikację są wykonywane na komputerze, na którym znajdują się żądane dane.
Jest to bardzo prawdziwe w przypadku, gdy rozmiar danych jest ogromny. Dzieje się tak, ponieważ minimalizuje przeciążenie sieci i zwiększa ogólną przepustowość systemu.
Jedynym założeniem za tym jest to, że lepiej przenieść obliczenia bliżej maszyny, na której znajdują się dane, zamiast przenosić dane do maszyny, na której działa aplikacja.
Apache Hadoop działa na ogromnej ilości danych, więc przenoszenie tak dużej ilości danych przez sieć nie jest wydajne. W związku z tym w ramach projektu opracowano najbardziej innowacyjną zasadę, jaką jest lokalizacja danych, która przenosi logikę obliczeń do danych zamiast przenosić dane do algorytmów obliczeniowych. Nazywa się to lokalizacją danych.
Zalety MapReduce
1. Skalowalność: Struktura MapReduce jest wysoce skalowalna. Umożliwia organizacjom uruchamianie aplikacji z dużych zestawów maszyn, co może wiązać się z wykorzystaniem tysięcy terabajtów danych.
2. Elastyczność: Struktura MapReduce zapewnia organizacji elastyczność w przetwarzaniu danych o dowolnym rozmiarze i dowolnym formacie, ustrukturyzowanym, częściowo ustrukturyzowanym lub nieustrukturyzowanym.
3. Bezpieczeństwo i uwierzytelnianie: Model programowania MapReduce zapewnia wysokie bezpieczeństwo. Chroni przed nieautoryzowanym dostępem do danych i zwiększa bezpieczeństwo klastra.
4. Opłacalne: Platforma przetwarza dane w klastrze zwykłego sprzętu, który jest tanimi maszynami. Dzięki temu jest bardzo opłacalny.
5. Szybko: MapReduce przetwarza dane równolegle, dzięki czemu jest bardzo szybki. Przetworzenie terabajtów danych zajmuje tylko kilka minut.
6. Prosty model programowania: Programy MapReduce mogą być napisane w dowolnym języku, takim jak Java, Python, Perl, R itp. Tak więc każdy może łatwo nauczyć się i pisać programy MapReduce oraz spełniać swoje potrzeby w zakresie przetwarzania danych.
Korzystanie z MapReduce
1. Analiza dziennika: MapReduce służy głównie do analizy plików dziennika. Struktura dzieli duże pliki dziennika na podział i wyszukiwanie map dla różnych stron internetowych, do których uzyskano dostęp.
Za każdym razem, gdy w dzienniku zostanie znaleziona strona internetowa, para klucz-wartość jest przekazywana do reduktora, w którym kluczem jest strona internetowa, a wartością jest „1”. Po wyemitowaniu pary klucz, wartość do Reduktora, Reduktory agregują liczbę dla niektórych stron internetowych.
Ostatecznym wynikiem będzie łączna liczba odwiedzin dla każdej strony internetowej.
2. Indeksowanie pełnotekstowe: MapReduce jest również używany do wykonywania indeksowania pełnotekstowego. Mapper w MapReduce mapuje każdą frazę lub słowo w jednym dokumencie do dokumentu. Reduktor zapisze te mapowania w indeksie.
3. Google używa MapReduce do obliczania ich PageRank.
4. Wykres odwrotnego łącza internetowego: MapReduce jest również używany w Grafie Reverse Web-Link. Funkcja mapy wyprowadza cel i źródło adresu URL, pobierając dane ze strony internetowej (źródło).
Funkcja zmniejszania łączy następnie listę wszystkich źródłowych adresów URL, które są powiązane z danym docelowym adresem URL i zwraca cel oraz listę źródeł.
5. Liczba słów w dokumencie: Framework MapReduce może być użyty do zliczania, ile razy słowo pojawia się w dokumencie.
Podsumowanie
Chodzi o samouczek Hadoop MapReduce. Platforma przetwarza równolegle ogromne ilości danych w klastrze zwykłego sprzętu. Dzieli zadanie na niezależne zadania i wykonuje je równolegle na różnych węzłach w klastrze.
MapReduce pokonuje wąskie gardło tradycyjnego systemu korporacyjnego. Framework działa na kluczu, parach wartości. Użytkownik definiuje dwie funkcje, którymi są funkcja map i funkcja zmniejszania.
Logika biznesowa jest umieszczana w funkcji mapy. W artykule wyjaśniono różne zaawansowane koncepcje frameworka MapReduce.



