W naszym poprzednim samouczku Hadoop , zbadaliśmy Hadoop Partitioner szczegółowo. Teraz omówimy InputSplit w Hadoop MapReduce.
Tutaj omówimy, czym jest Hadoop InputSplit, czyli potrzeba InputSplit w MapReduce. Omówimy również szczegółowo, w jaki sposób te InputSplits są tworzone w Hadoop MapReduce.
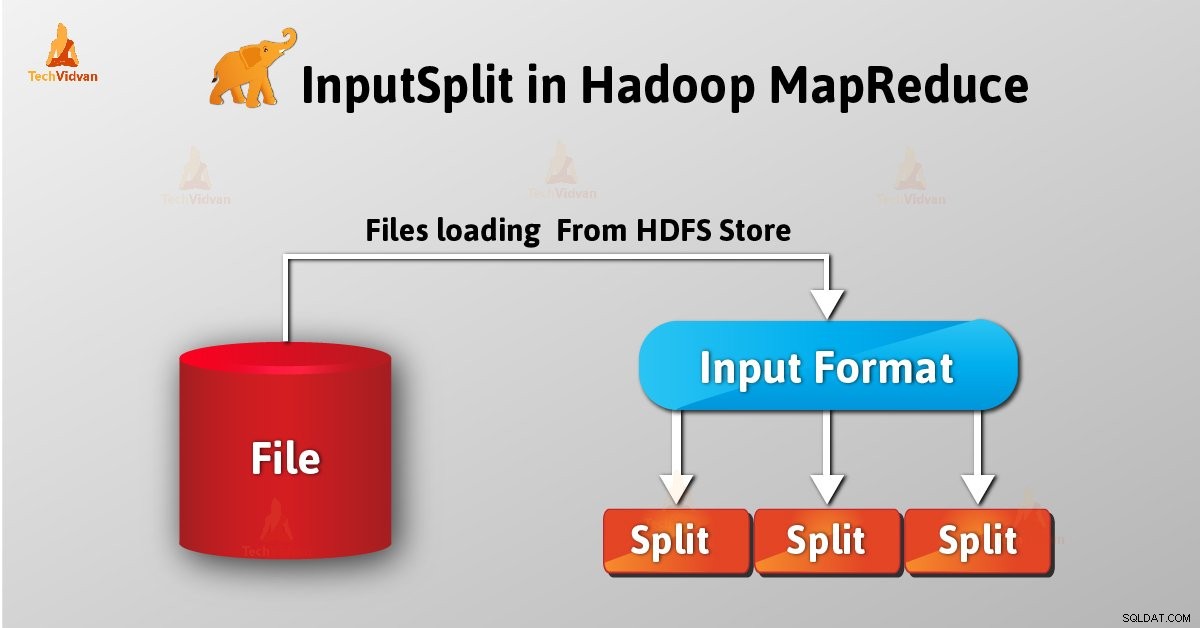
Wprowadzenie do InputSplit w Hadoop
InputSplit to logiczna reprezentacja danych w Hadoop MapReduce. Reprezentuje dane, które poszczególni mapujący procesy. Tak więc liczba zadań mapy jest równa liczbie InputSplits. Framework dzieli się na rekordy, które przetwarzają.
Długość MapReduce InputSplit została zmierzona w bajtach. Każdy InputSplit ma lokalizacje pamięci (ciągi nazw hostów). System MapReduce umieszcza zadania mapy tak blisko danych podziału, jak to możliwe, korzystając z lokalizacji pamięci.
Procesy ramowe Mapuj zadania w kolejności wielkości podziałów, tak aby największy z nich został przetworzony jako pierwszy (algorytm aproksymacji zachłannej). Minimalizuje to czas wykonywania zadania.
Najważniejszą rzeczą, na której należy się skupić, jest to, że Inputsplit nie zawiera danych wejściowych; to tylko odniesienie do danych.
Jak tworzy się InputSplits w Hadoop MapReduce?
Jako użytkownik nie zajmujemy się bezpośrednio InputSplit w Hadoop, ponieważ InputFormat (ponieważ InputFormat jest odpowiedzialny za tworzenie Inputsplit i dzielenie na rekordy) tworzy go. FileInputFormat dzieli plik na kawałki o wielkości 128 MB.
Ponadto, ustawiając mapowane .min .podział .rozmiar parametr w zmapowanej-witrynie .xml użytkownik może zmienić wartość zgodnie z wymaganiami. Również przez to możemy nadpisać parametr w obiekcie Job używanym do przesłania konkretnego zadania MapReduce.
Pisząc niestandardowy InputFormat, możemy również kontrolować, w jaki sposób plik jest dzielony na podziały.
InputSplit jest zdefiniowany przez użytkownika. Użytkownik może również kontrolować wielkość podziału na podstawie wielkości danych w programie MapReduce. Dlatego w wykonaniu zadania MapReduce liczba zadań mapy jest równa liczbie InputSplits.
Wywołując ‘getSplit()’ , klient oblicza podziały dla zadania. Następnie jest wysyłany do mastera aplikacji, który wykorzystuje swoje lokalizacje przechowywania do planowania zadań mapowania, które będą przetwarzać je w klastrze.
Po tym zadaniu mapy przekazuje podział do createRecordReader() metoda. Z tego uzyskuje RecordReader do podziału. Następnie RecordReader wygeneruje rekord (para klucz-wartość) , który przekazuje do funkcji mapy.
Wniosek
Podsumowując można powiedzieć, że InputSplit reprezentuje dane, które przetwarza poszczególny mapper. Dla każdego podziału tworzone jest jedno zadanie na mapie. Dlatego InputFormat tworzy InputSplit.
Jeśli masz jakiekolwiek pytania dotyczące InputSplit w MapReduce, zostaw komentarz w sekcji podanej poniżej.



