Współczesne IT musi mieć nierelacyjny, dynamiczny schemat (co oznacza brak wymagań dla zapytań o złączeniach), aby zapewnić obsługę aplikacji Big Data/czasu rzeczywistego. Bazy danych NoSQL zostały stworzone z myślą o poprawie wydajności przetwarzania danych i rozwiązaniu możliwości skalowania w celu pokonania obciążenia rozproszonej bazy danych przy użyciu koncepcji wielu hostów, dzięki czemu zyskały zapotrzebowanie nowej generacji na przetwarzanie danych.
Oprócz zapewniania niezbędnego wsparcia dla różnych modeli danych i języków skryptowych, MongoDB pozwala również programistom na łatwe rozpoczęcie procesu.
Baza danych NoSQL otwiera drzwi do...
- Protokoły tekstowe wykorzystujące język skryptowy (REST i JSON, BSON)
- Naprawdę minimalny koszt generowania, przechowywania i transportu danych
- Obsługuj ogromne ilości przetwarzania danych.
- Większa wydajność zapisu
- Nie jest wymagane do wykonania mapowania obiektowo-relacyjnego i procesu normalizacji
- Brak sztywnych kontroli z regułami integralności referencyjnej
- Zmniejszenie kosztów utrzymania dzięki administratorom baz danych
- Obniżenie kosztów ekspansji
- Szybki dostęp do pary klucz-wartość
- Zaawansowana obsługa uczenia maszynowego i inteligencji
Akceptacja rynkowa MongoDB
Współczesne potrzeby Big Data Analytics i nowoczesnych aplikacji odgrywają kluczową rolę w potrzebie poprawy cyklu życia przetwarzania danych, bez oczekiwania na rozbudowę sprzętu i wzrost kosztów.
Jeśli planujesz nową aplikację i chcesz wybrać bazę danych, podjęcie właściwej decyzji przy wielu dostępnych na rynku opcjach baz danych może być skomplikowanym procesem.
Ranking popularności silników DB pokazuje, że MongoDB zajmuje pierwsze miejsce w porównaniu z Oracle NoSQL (które uplasowało się na 74. miejscu). Trend wskazuje jednak, że coś się zmienia. Potrzeba wielu opłacalnych rozszerzeń idzie w parze ze znacznie prostszym modelowaniem danych, a administracja zmienia sposób, w jaki programiści chcieliby rozważyć najlepsze rozwiązanie dla swoich systemów.
Według aktualnych informacji o udziale w rynku firmy Datanyze, na Oracle Nosql działa około 289 witryn internetowych z udziałem w rynku wynoszącym 11%, podczas gdy poza tym MongoDB ma kompletną witrynę 12 185 z udziałem w rynku wynoszącym 4,66 %. Te imponujące liczby wskazują, że MongoDB ma przed sobą świetlaną przyszłość.
Modelowanie danych NoSQL
Modelowanie danych wymaga zrozumienia...
- Typy Twoich aktualnych danych.
- Jakich typów danych oczekujesz w przyszłości?
- W jaki sposób Twoja aplikacja uzyskuje dostęp do wymaganych danych z systemu?
- W jaki sposób Twoja aplikacja będzie pobierać wymagane dane do przetworzenia?
Ekscytująca rzecz dla tych, którzy zawsze podążali drogą Oracle przy tworzeniu schematów, a następnie przechowywaniu danych, MongoDB umożliwia tworzenie kolekcji wraz z dokumentem. Oznacza to, że tworzenie kolekcji nie jest koniecznością przed utworzeniem dokumentu, co sprawia, że MongoDB jest bardzo ceniony za swoją elastyczność.
W Oracle NoSQL należy jednak najpierw utworzyć definicję tabeli, po czym można kontynuować tworzenie wierszy.
Następną fajną rzeczą jest to, że MongoDB nie implikuje ścisłych zasad implementacji schematów i relacji, co daje swobodę ciągłego doskonalenia systemu bez obawy o konieczność zapewnienia ścisłego projektowania schematów.
Spójrzmy na niektóre porównania między MongoDB i Oracle NoSQL.
Porównanie koncepcji NoSQL w MongoDB i Oracle
Terminologie NoSQL
| MongoDB | Oracle NoSQL | Fakty |
| Kolekcja | Tabela / Widok | Kolekcja/tabela pełnią rolę kontenera do przechowywania; są podobne, ale nie identyczne. |
| Dokument | Wiersz | Dla MongoDB dane przechowywane w kolekcji w postaci dokumentów i pól. W przypadku Oracle NoSQL tabela jest zbiorem wierszy, w których każdy wiersz zawiera rekord danych. Każdy wiersz tabeli składa się z pól kluczy i danych, które są definiowane podczas tworzenia tabeli. |
| Pole | Kolumna | |
| Indeks | Indeks | Obie bazy danych używają indeksu w celu poprawy szybkości przeszukiwania bazy danych. |
Sklep z dokumentami i sklep z kluczami wartości
Oracle NoSQL zapewnia system przechowywania, który przechowuje wartości indeksowane przez klucz; ta koncepcja jest postrzegana jako najmniej złożony model, ponieważ zestawy danych składają się z indeksowanej pary klucz-wartość. Zapisy uporządkowane za pomocą tonacji durowych i molowych.
Klucz główny może być postrzegany jako wskaźnik obiektu, a klucz pomocniczy jako pola w rekordzie. Sprawne wyszukiwanie danych jest możliwe dzięki wykorzystaniu klucza jako mechanizmu dostępu do danych, podobnie jak klucza podstawowego.
MongoDB rozszerza pary klucz-wartość. Każdy dokument ma unikalny klucz, który służy do odzyskania dokumentu. Dokumenty są nazywane schematami dynamicznymi, ponieważ kolekcje w dokumencie nie muszą mieć tego samego zestawu pól. Kolekcja może mieć wspólne pole z różnymi typami danych. Te atrybuty prowadzą model danych dokumentu do bezpośredniego mapowania w celu obsługi nowoczesnych języków zorientowanych obiektowo.
| MongoDB | Oracle NoSQL |
| Sklep z dokumentami Przykład:  | Sklep klucz-wartość Przykład: 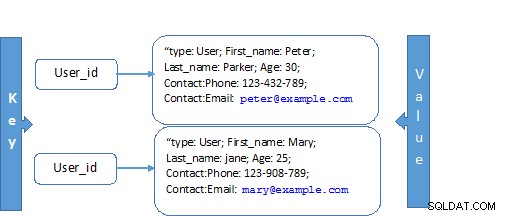 |
BSON i JSON
Oracle NoSQL używa JSON jako standardowego formatu danych do przesyłania (pary dane + atrybut-wartość). Z drugiej strony MongoDB używa BSON.
| MongoDB | Oracle NoSQL |
| BSON | JSON |
| Binarny JSON - format danych binarnych - przyspiesza przetwarzanie | Javascript Object Notation - format standardowy. Znacznie wolniejsze przetwarzanie w porównaniu z BSON. |
| Charakterystyka :
| Charakterystyka:
|
BSON nie jest tekstem czytelnym dla człowieka, w przeciwieństwie do JSON. BSON oznacza zakodowaną binarnie serializację danych podobnych do JSON, używaną głównie do przechowywania danych i formatu przesyłania z MongoDB. Format danych BSON składa się z listy uporządkowanych elementów zawierających nazwę pola (łańcuch), typ i wartość. Jeśli chodzi o typy danych obsługiwane przez BSON, wszystkie typy danych powszechnie spotykane w JSON i zawierają dwa dodatkowe typy danych (Dane binarne i Data). Dane binarne lub znane jako BinData, które są mniejsze niż 16 MB, mogą być przechowywane bezpośrednio w dokumentach MongoDB. Mówi się, że BSON zajmuje więcej miejsca niż dokumenty danych JSON.
Istnieją dwa powody, dla których MongoDB zajmuje więcej miejsca w porównaniu z Oracle NoSQL:
- MongoDB osiągnął cel, jakim było umożliwienie szybkiego przemieszczania się, dzięki czemu opcja szybkiego przemieszczania wymaga, aby dokument BSON zawierał dodatkowe metadane (długość ciągu i podobiektów).
- Projekt BSON może szybko kodować i dekodować. Na przykład liczby całkowite są przechowywane jako 32-bitowe (lub 64-bitowe) liczby całkowite, aby wyeliminować parsowanie do iz tekstu. Ten proces zajmuje więcej miejsca niż JSON dla małych liczb całkowitych, ale jest znacznie szybszy do przeanalizowania.
Definicja modelu danych
Oświadczenie o pobraniu MongoDB
Utwórz kolekcję
db.createCollection("users")Tworzenie kolekcji z automatycznym _id
db.users.insert
( {
User_id: "U1",
First_name: "Mary"
Last_name : "Winslet",
Age : 15
Contact : {
Phone: "123-456-789"
Email: "example@sqldat.com"
}
access : {
Level:5,
Group:"dev"
}
})MongoDB umożliwia osadzanie powiązanych fragmentów informacji w tym samym rekordzie bazy danych. Projekt modelu danych
Oświadczenie dotyczące tabeli Oracle NoSQL
Korzystanie z CLI SQL do konfiguracji przestrzeni nazw:
Create namespace newns1; Korzystanie z przestrzeni nazw do kojarzenia tabel z tabelą podrzędną
news1:users
News1:users.accessUtwórz tabelę z TOŻSAMOŚCIĄ, używając:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_id String,
First_name String,
Last_name String,
Contact Record (Phone string,
Email string),
Primary key (idValue));Utwórz tabelę przy użyciu SQL JSON:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_profile JSON,
Primary Key (shard(idValue),User_id));
Wiersze w tabeli użytkowników:wpisz JSON
{
"id":U1,
"User_profile" : {
"First_name":"Mary",
"Lastname":"Winslet",
"Age":15,
"Contact":{"Phone":"123-456-789",
"Email":"example@sqldat.com"
}
}W oparciu o powyższe definicje danych MongoDB umożliwia różne metody tworzenia schematów. Zbiór można zdefiniować wprost lub podczas pierwszego wstawiania danych do dokumentu. Podczas tworzenia kolekcji możesz zdefiniować obiekt. Objectid to klucz podstawowy dla dokumentów MongoDB. Objectid to 12-bajtowy binarny typ BSON, który zawiera 12 bajtów wygenerowanych przez sterowniki MongoDB i serwer przy użyciu domyślnego algorytmu. Objectid MongoDB jest przydatny i służy do sortowania dokumentu utworzonego w określonej kolekcji.
Oracle NoSQL ma kilka sposobów na rozpoczęcie definiowania tabel. Jeśli domyślnie używasz Oracle SQL CLI, tworzenie nowej tabeli zostanie umieszczone w sysdefault, dopóki nie zdecydujesz się utworzyć nowej przestrzeni nazw, aby skojarzyć z nią zestaw nowych tabel. Powyższy przykład ilustruje utworzoną nową przestrzeń nazw „ns1”, a tabela użytkowników jest skojarzona z nową przestrzenią nazw.
Oprócz identyfikowania klucza podstawowego, Oracle NoSQL używa również kolumny IDENTITY do automatycznego zwiększania wartości za każdym razem, gdy dodajesz wiersz. Wartość IDENTITY jest generowana automatycznie i musi być typem danych Integer, Long lub Number. W Oracle NoSQL IDENTITY łączy się z Generatorem Sekwencji, podobnie jak koncepcja objectid z MongoDB. Ponieważ Oracle NoSQL umożliwia użycie klucza IDENTITY jako klucza podstawowego. Jeśli rozważasz klucz IDENTITY jako klucz podstawowy, jest to miejsce, w którym należy dokładnie rozważyć, ponieważ może on mieć wpływ na wstawianie danych i proces aktualizacji.
Definicja poziomu tabeli/kolekcji MongoDB i Oracle NoSQL pokazuje, w jaki sposób informacje „kontaktowe” są osadzone w tej samej pojedynczej strukturze bez konieczności dodatkowej definicji schematu. Zaletą osadzania zestawu danych jest to, że do pobrania osadzonego zestawu danych nie będą potrzebne żadne dalsze zapytania.
Jeśli chcesz utrzymać swój system w prostej formie, MongoDB zapewnia najlepszą opcję przechowywania dokumentów z danymi przy mniejszej komplikacji. Jednocześnie MongoDB zapewnia możliwości dostarczania istniejącego złożonego modelu danych ze schematu relacyjnego za pomocą narzędzia do walidacji schematu.
Oracle NoSQL zapewnia możliwości korzystania z SQL, takie jak język zapytań z DDL i DML, co wymaga znacznie mniej wysiłku dla użytkowników, którzy mają pewne doświadczenie w korzystaniu z systemów Relation Database.
Powłoka MongoDB korzysta z JavaScript, a jeśli nie znasz języka lub powłoki mongo, najlepszym rozwiązaniem dla tego procesu jest skorzystanie z narzędzia IDE. 5 najlepszych narzędzi MongoDB IDE w 2020 r., takich jak studio 3T, Robo 3T, NoSQLBooster, MongoDB Compass i Nucleon Database Master, pomoże Ci w tworzeniu złożonych zapytań i zarządzaniu nimi przy użyciu funkcji agregacji.
Wydajność i dostępność
Ponieważ model struktury danych MongoDB wykorzystuje dokumenty i kolekcje, użycie formatu danych BSON do przetwarzania ogromnej ilości danych staje się znacznie szybsze w porównaniu z Oracle NoSQL. Chociaż niektórzy uważają, że wykonywanie zapytań o dane za pomocą SQL jest dla wielu użytkowników wygodniejszą ścieżką, problemem staje się pojemność. Kiedy mamy ogromną ilość danych do obsługi, potrzebę zwiększenia przepustowości, a następnie użycie SQL do projektowania złożonych zapytań, procesy te proszą nas o ponowne przyjrzenie się wydajności serwera i wzrostowi kosztów w czasie.
Zarówno MongoDB, jak i Oracle NoSQL zapewniają funkcje shardingu i replikacji. Sharding to proces, który umożliwia rozłożenie zestawu danych i ogólnego obciążenia przetwarzania na wiele partycji fizycznych w celu zwiększenia szybkości przetwarzania (odczytu/zapisu). Implementacja fragmentu za pomocą Oracle wymaga posiadania wcześniejszych informacji o tym, jak działają klucze fragmentowania. Powodem procesu planowania wstępnego jest potrzeba implementacji klucza shard na poziomie inicjacji schematu.
Implementacja fragmentu za pomocą MongoDB daje miejsce na pracę nad zbiorem danych w celu zidentyfikowania potencjalnego właściwego klucza fragmentu na podstawie wzorców zapytań przed wdrożeniem. Ponieważ proces shardingu obejmuje replikację danych, MongoDB ma również reputację szybkiej replikacji danych. Replikacja zapewnia odporność na awarie, ponieważ wszystkie dane muszą znajdować się na jednym serwerze.
Wnioski
To, co sprawia, że MongoDB jest preferowane w stosunku do Oracle NoSQL, to fakt, że jest on w formacie binarnym i ma wrodzoną lekkość, przejezdność i wydajność. Pozwala to wesprzeć rozwijającą się nowoczesną aplikację w obszarze uczenia maszynowego i sztucznej inteligencji.
Cechy MongoDB pozwalają programistom pracować znacznie pewniej, aby szybciej budować nowoczesne aplikacje. Model danych MongoDB umożliwia przetwarzanie ogromnych ilości nieustrukturyzowanych danych z większą szybkością, która jest dobrze przemyślana w porównaniu z Oracle NoSQL. Oracle NoSQL wygrywa, jeśli chodzi o narzędzia, które ma do zaoferowania i możliwe opcje tworzenia modeli danych. Jednak konieczne jest upewnienie się, że programiści i projektanci mogą szybko uczyć się i dostosowywać do technologii, co nie ma miejsca w przypadku Oracle NoSQL.



