W części 1 tej serii poświęconej migawkom Apache HBase dowiedziałeś się, jak korzystać z nowej funkcji migawek, i poznałeś trochę teorii na temat implementacji. Teraz nadszedł czas, aby głębiej zagłębić się w szczegóły techniczne.
Co to jest stół?
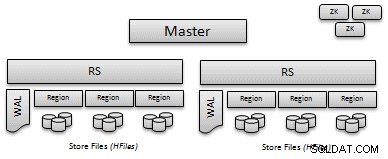
Tabela HBase składa się z zestawu informacji o metadanych oraz zestawu par klucz/wartość:
- Informacje o tabeli :plik manifestu opisujący „ustawienia” tabeli, takie jak rodziny kolumn, kodeki kompresji i kodowania, typy filtrów bloom i tak dalej.
- Regiony :Tabele „partycje” nazywane są regionami. Każdy region jest odpowiedzialny za obsługę ciągłego zestawu kluczy/wartości i są one definiowane przez klucz początkowy i klucz końcowy.
- WAL/MemStore :Przed zapisaniem danych na dysku, puts są zapisywane w dzienniku Write Ahead Log (WAL), a następnie przechowywane w pamięci, aż ciśnienie pamięci wyzwoli opróżnianie na dysk. WAL zapewnia łatwy sposób na odzyskanie pozycji, które nie zostały opróżnione na dysk w przypadku awarii.
- File HF :W pewnym momencie wszystkie dane są zrzucane na dysk; HFile to format HBase, który zawiera przechowywane klucze/wartości. Pliki HFiles są niezmienne, ale można je usunąć podczas kompaktowania lub usuwania regionu.
(Uwaga:aby dowiedzieć się więcej o ścieżce zapisu HBase, zapoznaj się z wpisem na blogu o ścieżce zapisu HBase).
Co to jest migawka?
Migawka to zestaw informacji o metadanych, który umożliwia administratorowi powrót do poprzedniego stanu tabeli, w której został wykonany. Migawka nie jest kopią tabeli; najprostszym sposobem myślenia o tym jest zestaw operacji do śledzenia metadanych (informacje o tabeli i regiony) oraz danych (HFiles, memstore, WAL). Podczas wykonywania zrzutu obrazu żadne kopie danych nie są zaangażowane.
- Migawki offline :Najprostszym przypadkiem wykonania migawki jest wyłączenie tabeli. Wyłączenie tabeli oznacza, że wszystkie dane są opróżniane na dysku i nie są akceptowane żadne zapisy ani odczyty. W tym przypadku zrobienie migawki to tylko kwestia przejrzenia metadanych tabeli i plików HFiles na dysku oraz zachowania odniesienia do nich. Master wykonuje tę operację, a wymagany czas jest określany głównie przez czas wymagany przez nazwanode HDFS do dostarczenia listy plików.
- Migawki online :Jednak w większości sytuacji tabele są włączone, a każdy serwer regionu obsługuje żądania put i get. W takim przypadku master otrzymuje żądanie migawki i prosi każdy serwer regionu o wykonanie migawki regionów, za które jest odpowiedzialny.
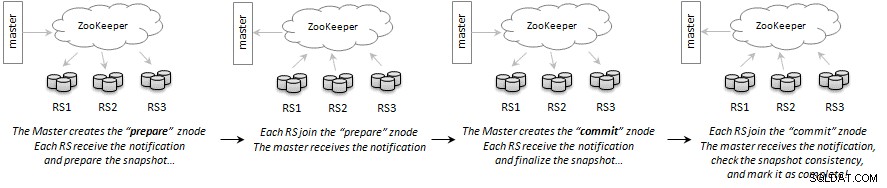
Komunikacja między serwerem głównym i regionalnym odbywa się za pośrednictwem Apache ZooKeeper przy użyciu dwufazowej transakcji podobnej do zatwierdzania. Master tworzy znode, co oznacza „przygotuj migawkę”. Każdy serwer regionu przetworzy żądanie i przygotuje migawkę dla regionów z tabeli, za którą jest odpowiedzialny. Po zakończeniu dodają podwęzeł do węzła z żądaniem przygotowania o znaczeniu „Gotowe”.
Gdy wszystkie serwery regionu zgłoszą swój status, master tworzy kolejny znode, co oznacza „Zatwierdź migawkę”; każdy serwer regionu sfinalizuje migawkę i zgłosi stan przed dołączeniem do węzła. Gdy wszystkie serwery regionu zgłoszą się z powrotem, master sfinalizuje migawkę i oznaczy operację jako ukończoną. W przypadku, gdy serwer regionalny zgłosi awarię, master utworzy nowy węzeł używany do rozgłaszania komunikatu o przerwaniu.
Ponieważ serwer regionu stale przetwarza nowe żądania, różne przypadki użycia mogą wymagać różnych modeli spójności. Na przykład ktoś może być zainteresowany niechlujną migawką bez nowych danych w MemStore, ktoś inny może chcieć w pełni spójnej migawki, która wymaga blokowania zapisów przez chwilę i tak dalej.
Z tego powodu procedura wykonywania migawki na serwerze regionu jest podłączana. Obecnie jedyną obecną implementacją jest „Flush Snapshot”, która wykonuje opróżnianie przed wykonaniem migawki i gwarantuje tylko spójność wierszy. Inne procedury z różnymi politykami spójności mogą zostać wdrożone w przyszłości.
W przypadku online czas potrzebny na wykonanie migawki jest ograniczony przez czas wymagany przez najwolniejszy serwer regionu do wykonania operacji migawki i zgłoszenia sukcesu do urządzenia głównego. Ta operacja zwykle trwa kilka sekund.
Archiwizacja
Jak widzieliśmy wcześniej, HFiles są niezmienne. Pozwala nam to uniknąć kopiowania danych podczas wykonywania migawki lub operacji klonowania, ale podczas kompaktowania są one usuwane i zastępowane wersją skompaktowaną. W takim przypadku, jeśli masz migawkę lub sklonowaną tabelę, która odwołuje się do jednego z tych plików, zamiast je usuwać, są one przenoszone do lokalizacji „archiwum”. Jeśli usuniesz migawkę i nikt inny nie odwołuje się do plików, do których odwołuje się migawka, te pliki zostaną usunięte.
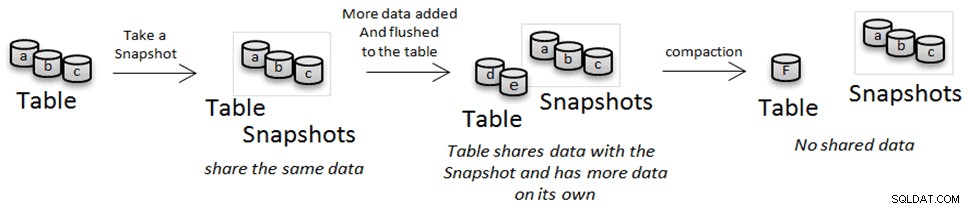
Klonowanie i przywracanie tabel
Migawki można postrzegać jako rozwiązanie do tworzenia kopii zapasowych, w którym można ich używać do przywracania/odzyskiwania tabeli po błędzie użytkownika lub aplikacji, ale funkcja migawek może pozwolić na znacznie więcej niż zwykłe tworzenie kopii zapasowych i przywracanie. Po sklonowaniu tabeli z migawki możesz napisać zadanie MapReduce lub prostą aplikację, aby selektywnie scalić różnice lub to, co uważasz za ważne, w środowisku produkcyjnym. Innym przypadkiem użycia jest to, że możesz testować zmiany schematu lub aktualizacje danych bez konieczności czekania godzinami na kopię tabeli i bez konieczności duplikowania dużej ilości danych na dysku.
Klonuj tabelę z migawki
Kiedy administrator wykonuje operację klonowania, nowa tabela ze schematem tabeli obecnym w migawce jest tworzona wstępnie podzielona z kluczami start/end w informacjach o regionach migawki. Po utworzeniu metadanych tabeli zamiast kopiowania danych stosuje się tę samą sztuczkę, co w przypadku migawki. Ponieważ HFiles są niezmienne, tworzone jest tylko odniesienie do pliku źródłowego; pozwala to na uniknięcie kopiowania danych i umożliwia edycję klonu bez wpływu na tabelę źródłową lub migawkę. Operacja klonowania jest wykonywana przez mastera.
Przywróć tabelę z migawki
Operacja przywracania jest podobna do operacji klonowania; możesz myśleć o tym jako o usunięciu tabeli i sklonowaniu jej z migawki. Operacja przywracania przywraca stare dane obecne w migawce, usuwając wszelkie dane z tabeli, których nie ma również w migawce, a także schemat tabeli jest przywracany do schematu migawki. Pod maską przywracanie jest realizowane przez wykonanie porównania między stanem tabeli a migawką, usunięcie plików, których nie ma w migawce i dodanie odwołań do tych w migawce, ale nieobecnych w bieżącym stanie. Zmodyfikowano również deskryptor tabeli, aby odzwierciedlić „schemat” tabeli w momencie tworzenia migawki. Operacja przywracania jest wykonywana przez mastera, a tabela musi być wyłączona.
Przyszłe
Obecnie implementacja migawek obejmuje wszystkie podstawowe wymagane funkcje. Jak widzieliśmy, nowe zasady spójności migawek dla migawek w trybie online mogą zapewnić większą elastyczność, spójność lub poprawę wydajności. Lepsze zarządzanie plikami może zmniejszyć obciążenie węzła nazw HDFS i poprawić zarządzanie miejscem na dysku. Ponadto na liście rzeczy do zrobienia znajdują się wskaźniki, interfejs WWW (odcień) i inne.
Wniosek
Migawki HBase dodają nowe funkcje, takie jak „koordynacja procedur” używana przez migawkę online lub migawkę kopiowania przy zapisie, przywracanie i klonowanie.
Migawki zapewniają szybszą i lepszą alternatywę dla ręcznie robionych rozwiązań „kopii zapasowych” i „klonowania” opartych na distcp lub CopyTable. Wszystkie operacje na migawkach (migawka, przywracanie, klonowanie) nie obejmują kopii danych, co skutkuje szybszymi migawkami tabeli i oszczędnością miejsca na dysku.
Aby uzyskać więcej informacji na temat włączania i używania migawek, zapoznaj się z dokumentacją dotyczącą zarządzania operacyjnego HBase.
Matteo Bertozzi jest inżynierem oprogramowania w zespole Platformy i koordynatorem HBase.



