Uzyskaj omówienie dostępnych mechanizmów tworzenia kopii zapasowych danych przechowywanych w Apache HBase oraz sposobów przywracania tych danych w przypadku różnych scenariuszy odzyskiwania danych/przełączania awaryjnego
Wraz ze wzrostem przyjęcia i integracji HBase z krytycznymi systemami biznesowymi, wiele przedsiębiorstw musi chronić ten ważny zasób biznesowy, tworząc solidne strategie tworzenia kopii zapasowych i odzyskiwania po awarii (BDR) dla swoich klastrów HBase. Choć może to zabrzmieć zniechęcająco do szybkiego i łatwego tworzenia kopii zapasowych i przywracania potencjalnie petabajtów danych, HBase i ekosystem Apache Hadoop zapewniają wiele wbudowanych mechanizmów, które pozwalają to osiągnąć.
W tym poście otrzymasz ogólny przegląd dostępnych mechanizmów tworzenia kopii zapasowych danych przechowywanych w HBase oraz sposobów przywracania tych danych w przypadku różnych scenariuszy odzyskiwania danych/przełączania awaryjnego. Po przeczytaniu tego posta powinieneś być w stanie podjąć świadomą decyzję, która strategia BDR jest najlepsza dla Twoich potrzeb biznesowych. Powinieneś także zrozumieć zalety, wady i wpływ każdego mechanizmu na wydajność. (Podane tutaj szczegóły dotyczą CDH 4.3.0/HBase 0.94.6 i nowszych.)
Uwaga:w momencie pisania tego tekstu Cloudera Enterprise 4 oferuje gotowe do produkcji funkcje tworzenia kopii zapasowych i odzyskiwania po awarii dla HDFS i Hive Metastore za pośrednictwem Cloudera BDR 1.0 jako indywidualnie licencjonowaną funkcję. HBase nie jest zawarty w tym wydaniu GA; dlatego wymagane są różne mechanizmy opisane na tym blogu. (Cloudera Enterprise 5, obecnie w wersji beta, oferuje zarządzanie migawkami HBase przez Cloudera BDR.)
Kopia zapasowa
HBase to rozproszony magazyn danych o strukturze logu w postaci drzewa scalającego ze złożonymi mechanizmami wewnętrznymi zapewniającymi dokładność danych, spójność, przechowywanie wersji i tak dalej. Jak więc na świecie uzyskać spójną kopię zapasową tych danych, która znajduje się w kombinacji plików HFiles i dzienników zapisu z wyprzedzeniem (WAL) na HDFS i w pamięci na dziesiątkach serwerów regionalnych?
Zacznijmy od najmniej destrukcyjnego, najmniejszego śladu danych, mechanizmu o najmniejszym wpływie na wydajność i przejdźmy do najbardziej destrukcyjnego narzędzia w stylu wózka widłowego:
- Migawki
- Replikacja
- Eksportuj
- Kopiuj tabelę
- HTable API
- Kopia zapasowa offline danych HDFS
Poniższa tabela zawiera przegląd umożliwiający szybkie porównanie tych podejść, które opiszę szczegółowo poniżej.
| Wpływ na wydajność | Ślad danych | Przestój | Przyrostowe kopie zapasowe | Łatwa implementacja | Średni czas do odzyskania (MTTR) | |
| Migawki | Minimalne | Mały | Krótki (tylko w przypadku przywracania) | Nie | Łatwe | Sekundy |
| Replikacja | Minimalne | Duży | Brak | Wewnętrzna | Średni | Sekundy |
| Eksportuj | Wysoki | Duży | Brak | Tak | Łatwe | Wysoki |
| Kopiuj tabelę | Wysoki | Duży | Brak | Tak | Łatwe | Wysoki |
| API | Średni | Duży | Brak | Tak | Trudne | Do Ciebie |
| Ręczny | Nie dotyczy | Duży | Długie | Nie | Średni | Wysoki |
Migawki
Od wersji CDH 4.3.0 migawki HBase są w pełni funkcjonalne, bogate w funkcje i nie wymagają przestojów klastra podczas ich tworzenia. Mój kolega Matteo Bertozzi bardzo dobrze opisał migawki w swoim wpisie na blogu, a następnie głębokie nurkowanie. Tutaj przedstawię tylko ogólny przegląd.
Migawki po prostu rejestrują chwilę dla Twojej tabeli, tworząc odpowiednik twardych łączy UNIX do plików pamięci masowej Twojej tabeli na HDFS (rysunek 1). Te migawki są kończone w ciągu kilku sekund, prawie nie obciążają klastra wydajnością i tworzą niewielki ślad danych. Twoje dane nie są w ogóle duplikowane, a jedynie skatalogowane w małych plikach metadanych, co pozwala systemowi cofnąć się do tego momentu, jeśli zajdzie potrzeba przywrócenia tego zrzutu.
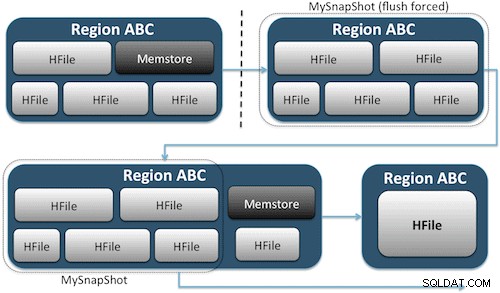
Tworzenie zrzutu tabeli jest tak proste, jak uruchomienie tego polecenia z powłoki HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Po wydaniu tego polecenia znajdziesz kilka małych plików danych znajdujących się w /hbase/.snapshot/myTable (CDH4) lub /hbase/.hbase-snapshots (Apache 0.94.6.1) w HDFS, które zawierają informacje niezbędne do przywrócenia migawki . Przywracanie jest tak proste, jak wydawanie tych poleceń z powłoki:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Uwaga:jak widać, przywrócenie migawki wymaga krótkiej przerwy w działaniu, ponieważ tabela musi być w trybie offline. Wszelkie dane dodane/zaktualizowane po wykonaniu przywróconej migawki zostaną utracone.
Jeśli Twoje wymagania biznesowe są takie, że musisz mieć kopię zapasową danych poza siedzibą firmy, możesz użyć polecenia exportSnapshot, aby zduplikować dane tabeli do lokalnego klastra HDFS lub zdalnego klastra HDFS do wyboru.
Migawki to za każdym razem pełny obraz Twojego stołu; obecnie nie jest dostępna żadna funkcja tworzenia zrzutów przyrostowych.
Replikacja HBase
Replikacja HBase to kolejne narzędzie do tworzenia kopii zapasowych o bardzo niskim nakładzie pracy. (Mój kolega Himanshu Vashishtha szczegółowo omawia replikację w tym poście na blogu). Podsumowując, replikację można zdefiniować na poziomie rodziny kolumn, działa ona w tle i synchronizuje wszystkie zmiany między klastrami w łańcuchu replikacji.
Replikacja ma trzy tryby:master->slave, master<->master i cykliczny. Takie podejście zapewnia elastyczność pozyskiwania danych z dowolnego centrum danych i zapewnia ich replikację we wszystkich kopiach tej tabeli w innych centrach danych. W przypadku katastrofalnej awarii w jednym centrum danych aplikacje klienckie mogą zostać przekierowane do alternatywnej lokalizacji danych za pomocą narzędzi DNS.
Replikacja to solidny, odporny na błędy proces, który zapewnia „ostateczną spójność”, co oznacza, że w dowolnym momencie ostatnie edycje tabeli mogą nie być dostępne we wszystkich replikach tej tabeli, ale mają gwarancję, że w końcu do niej dotrą.
Uwaga:W przypadku istniejących tabel musisz najpierw ręcznie skopiować tabelę źródłową do tabeli docelowej za pomocą jednego z innych sposobów opisanych w tym poście. Replikacja działa tylko na nowych zapisach/edycjach po jej włączeniu.

(Ze strony replikacji Apache)
Eksportuj
Narzędzie do eksportu HBase to wbudowane narzędzie HBase, które umożliwia łatwe eksportowanie danych z tabeli HBase do zwykłych plików SequenceFiles w katalogu HDFS. Tworzy zadanie MapReduce, które wykonuje serię wywołań interfejsu API HBase do klastra i pojedynczo pobiera każdy wiersz danych z określonej tabeli i zapisuje te dane w określonym katalogu HDFS. To narzędzie wymaga większej wydajności dla Twojego klastra, ponieważ wykorzystuje MapReduce i interfejs API klienta HBase, ale jest bogate w funkcje i obsługuje filtrowanie danych według wersji lub zakresu dat – umożliwiając w ten sposób tworzenie przyrostowych kopii zapasowych.
Oto próbka polecenia w najprostszej formie:
hbase org.apache.hadoop.hbase.mapreduce.Export
Po wyeksportowaniu tabeli możesz skopiować wynikowe pliki danych w dowolne miejsce (na przykład poza siedzibą/poza klastrem). Możesz również określić zdalny klaster/katalog HDFS jako lokalizację wyjściową polecenia, a funkcja Export zapisze zawartość bezpośrednio w zdalnym klastrze. Pamiętaj, że to podejście wprowadzi element sieciowy do ścieżki zapisu eksportu, więc powinieneś upewnić się, że połączenie sieciowe ze zdalnym klastrem jest niezawodne i szybkie.
Kopiuj tabelę
Narzędzie CopyTable jest dobrze omówione we wpisie na blogu Jona Hsieha, ale tutaj podsumuję podstawy. Podobnie jak w przypadku eksportu, CopyTable tworzy zadanie MapReduce, które wykorzystuje interfejs API HBase do odczytu z tabeli źródłowej. Kluczową różnicą jest to, że CopyTable zapisuje swoje dane wyjściowe bezpośrednio do tabeli docelowej w HBase, która może być lokalna w klastrze źródłowym lub w klastrze zdalnym.
Przykładem najprostszej formy polecenia jest:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
To polecenie skopiuje zawartość tabeli o nazwie „test” do tabeli w tym samym klastrze o nazwie „testCopy”.
Należy zauważyć, że funkcja CopyTable wiąże się ze znacznym obciążeniem wydajnością, ponieważ używa poszczególnych „pozycji” do zapisywania danych wiersz po wierszu w tabeli docelowej. Jeśli Twoja tabela jest bardzo duża, funkcja CopyTable może spowodować zapełnienie pamięci memstore na serwerach regionu docelowego, wymagając opróżnień pamięci memstore, które ostatecznie doprowadzą do kompaktowania, wyrzucania elementów bezużytecznych itd.
Ponadto należy wziąć pod uwagę wpływ na wydajność uruchamiania MapReduce przez HBase. W przypadku dużych zbiorów danych takie podejście może nie być idealne.
HTable API (np. niestandardowa aplikacja Java)
Jak zawsze w przypadku Hadoop, zawsze możesz napisać własną, niestandardową aplikację, która korzysta z publicznego interfejsu API i bezpośrednio wysyła zapytania do tabeli. Możesz to zrobić za pomocą zadań MapReduce, aby wykorzystać zalety rozproszonego przetwarzania wsadowego tej struktury lub za pomocą innych środków własnego projektu. Jednak takie podejście wymaga głębokiego zrozumienia programowania Hadoop oraz wszystkich interfejsów API i wpływu na wydajność ich używania w klastrze produkcyjnym.
Kopia zapasowa offline surowych danych HDFS
Najbardziej brutalny mechanizm tworzenia kopii zapasowych — również najbardziej destrukcyjny — obejmuje największy ślad danych. Możesz czysto zamknąć klaster HBase i ręcznie skopiować wszystkie struktury danych i katalogów znajdujące się w /hbase w klastrze HDFS. Ponieważ HBase nie działa, zapewni to, że wszystkie dane zostały utrwalone w HFiles w HDFS i otrzymasz dokładną kopię danych. Jednak uzyskanie przyrostowych kopii zapasowych będzie prawie niemożliwe, ponieważ nie będziesz w stanie stwierdzić, jakie dane zostały zmienione lub dodane podczas próby tworzenia przyszłych kopii zapasowych.
Należy również pamiętać, że przywrócenie danych wymagałoby naprawy meta w trybie offline, ponieważ plik .META. tabela zawierałaby potencjalnie nieprawidłowe informacje w momencie przywracania. Takie podejście wymaga również szybkiej i niezawodnej sieci do przesyłania danych poza siedzibą firmy i późniejszego ich przywracania, jeśli zajdzie taka potrzeba.
Z tych powodów Cloudera zdecydowanie odradza takie podejście do kopii zapasowych HBase.
Odzyskiwanie po awarii
HBase został zaprojektowany jako system rozproszony wyjątkowo odporny na awarie z natywną nadmiarowością, przy założeniu, że sprzęt będzie często ulegał awarii. Odzyskiwanie po awarii w HBase zwykle występuje w kilku formach:
- Katastrofalna awaria na poziomie centrum danych, wymagająca przełączenia awaryjnego do lokalizacji kopii zapasowej
- Konieczność przywrócenia poprzedniej kopii danych z powodu błędu użytkownika lub przypadkowego usunięcia
- Możliwość przywrócenia kopii danych z określonego momentu do celów audytu
Podobnie jak w przypadku każdego planu odzyskiwania po awarii, wymagania biznesowe będą decydować o tym, jak plan jest zaprojektowany i ile pieniędzy w niego zainwestować. Po utworzeniu wybranych kopii zapasowych przywracanie przybiera różne formy w zależności od wymaganego typu odzyskiwania:
- Przełączanie awaryjne na klaster kopii zapasowej
- Importuj tabelę/Przywróć migawkę
- Wskaż katalog główny HBase do lokalizacji kopii zapasowej
Jeśli Twoja strategia tworzenia kopii zapasowych polega na zreplikowaniu danych HBase do klastra kopii zapasowej w innym centrum danych, przełączenie awaryjne jest tak proste, jak skierowanie aplikacji użytkownika końcowego do klastra kopii zapasowej za pomocą technik DNS.
Należy jednak pamiętać, że jeśli planujesz zezwolić na zapisywanie danych w klastrze zapasowym w okresie przestoju, musisz upewnić się, że po zakończeniu awarii dane wrócą do klastra podstawowego. Replikacja master-to-master lub cykliczna obsłuży ten proces automatycznie, ale schemat replikacji master-slave spowoduje, że klaster master nie będzie zsynchronizowany, co wymaga ręcznej interwencji po wyłączeniu.
Oprócz opisanej wcześniej funkcji eksportu istnieje odpowiednie narzędzie do importu, które może pobrać dane z kopii zapasowej utworzonej wcześniej przez funkcję Export i przywrócić je do tabeli HBase. Ten sam wpływ na wydajność, który zastosowano w przypadku eksportu, dotyczy również importu. Jeśli Twój schemat tworzenia kopii zapasowych obejmował wykonywanie migawek, przywrócenie poprzedniej kopii danych jest tak proste, jak przywrócenie tej migawki.
Możesz również odzyskać dane po awarii, po prostu modyfikując właściwość hbase.root.dir w hbase-site.xml i wskazując ją na kopię zapasową katalogu / hbase, jeśli wykonałeś brute-force offline kopię struktur danych HDFS . Jest to jednak również najmniej pożądana opcja przywracania, ponieważ wymaga dłuższego przestoju podczas kopiowania całej struktury danych z powrotem do klastra produkcyjnego i, jak wspomniano wcześniej, .META. może nie być zsynchronizowany.
Wniosek
Podsumowując, odzyskiwanie danych po jakiejś formie utraty lub awarii wymaga dobrze zaprojektowanego planu BDR. Zdecydowanie zalecam dokładne zrozumienie wymagań biznesowych dotyczących czasu pracy, dokładności/dostępności danych i odzyskiwania po awarii. Uzbrojony w szczegółową wiedzę na temat wymagań biznesowych, możesz starannie wybrać narzędzia, które najlepiej spełniają te potrzeby.
Wybór narzędzi to jednak dopiero początek. Powinieneś przeprowadzić zakrojone na szeroką skalę testy swojej strategii BDR, aby upewnić się, że działa ona funkcjonalnie w Twojej infrastrukturze, spełnia Twoje potrzeby biznesowe oraz że Twoje zespoły operacyjne są bardzo zaznajomione z krokami wymaganymi przed wystąpieniem przestoju i przekonasz się na własnej skórze, że Twój plan BDR nie zadziała.
Jeśli chcesz komentować lub dalej omawiać ten temat, skorzystaj z naszego forum społeczności dla HBase.
Dalsza lektura:
- Prezentacja Jona Hsieha Strata + Hadoop World 2012
- HBase:ostateczny przewodnik (Lars George)
- HBase w akcji (Nick Dimiduk/Amandeep Khurana)



