W tym samouczku MongoDB zamierzamy poznać unikalne funkcje MongoDB. Przestudiowaliśmy podstawową wiedzę na temat czym jest MongoDB . Naszym celem w tym artykule jest nauczenie się funkcji MongoDB do opanowania w nim.
Omówmy więc szczegółowo funkcje MongoDB.

Poznaj funkcje MongoDB | Samouczek MongoDB dla początkujących
Funkcje MongoDB
Będąc bazą danych NoSQL, MongoDB ma tak wiele wspaniałych funkcji. Te niesamowite cechy sprawiają, że ta technologia jest bardzo wyjątkowa i atrakcyjna. Ponadto te funkcje sprawiają, że MongoDB jest powszechnie użyteczny i popularny.
Omówmy kilka funkcji MongoDB, które pomogą nam z nim pracować.
- Zapytania ad hoc
- Baza danych bez schematów
- Zorientowany na dokumenty
- Indeksowanie
- Replikacja
- Agregacja
- GridFS
- Sharding
- Wysoka wydajność
ja. Zapytania doraźne
Generalnie, kiedy projektujemy schemat bazy danych, nie wiemy z góry, jakie zapytania będziemy wykonywać. Zapytania ad-hoc to zapytania nieznane podczas tworzenia struktury bazy danych.
Tak więc MongoDB zapewnia obsługę zapytań ad-hoc, co czyni ją tak wyjątkową w tym przypadku. Zapytania ad hoc są aktualizowane w czasie rzeczywistym, co prowadzi do poprawy wydajności.
ii. Baza danych bez schematów
W MongoDB jedna kolekcja zawiera różne dokumenty. Nie ma schematu, więc może mieć wiele pól, treści i rozmiarów innych niż inny dokument w tej samej kolekcji. Dlatego MongoDB wykazuje elastyczność w obsłudze baz danych.
iii. Zorientowany na dokument
MongoDB to baza danych zorientowana na dokumenty, która sama w sobie jest świetną funkcją. W relacyjnych bazach danych znajdują się tabele i wiersze do rozmieszczenia danych. Każdy rząd ma specyficzny nr. kolumn i te mogą przechowywać określony typ danych.
Nadchodzi elastyczność NoSQL, w której są pola zamiast tabel i wierszy. Istnieją różne dokumenty, które mogą przechowywać różne rodzaje danych. Istnieją zbiory podobnych dokumentów. Każdy dokument ma unikalny identyfikator klucza lub identyfikator obiektu, który może być zdefiniowany przez użytkownika lub system.

Funkcje MongoDB — zorientowane na dokumenty
iv. Indeksowanie
Indeksowanie jest bardzo ważne dla poprawy wydajności zapytań wyszukiwania. Gdy stale przeprowadzamy wyszukiwania w dokumencie, powinniśmy zindeksować te pola, które pasują do naszych kryteriów wyszukiwania.
W MongoDB możemy zaindeksować dowolne pole indeksowane indeksami pierwotnymi i wtórnymi. Przyspieszając wyszukiwanie zapytań, indeksowanie MongoDB zwiększa wydajność.
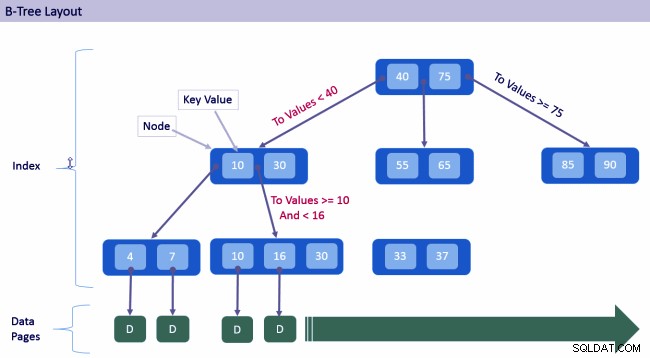
Funkcje MongoDB – indeksowanie
v. Replikacja
Jeśli chodzi o redundancję, narzędziem, z którego korzysta MongoDB, jest replikacja. Ta funkcja dystrybuuje dane do wielu komputerów. Może mieć węzły podstawowe i ich jeden lub więcej zestawów replik. Zasadniczo replikacja przygotowuje się na nieprzewidziane okoliczności.
Gdy z jakiegoś powodu węzeł podstawowy nie działa, węzeł pomocniczy staje się podstawowym dla instancji. Oszczędza to nasz czas na konserwację i sprawia, że operacje są płynne.
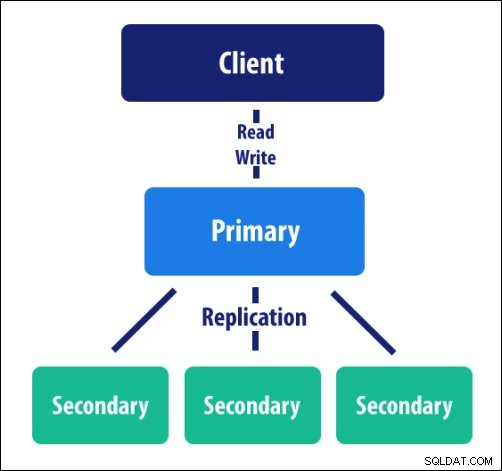
Funkcje MongoDB — replikacja
vi. Agregacja
MongoDB ma strukturę agregacji zapewniającą wydajną użyteczność. Możemy przetwarzać dane zbiorczo i uzyskać jeden wynik nawet po wykonaniu różnych operacji na danych grupy.
Potok agregacji, funkcja map-reduce i jednocelowe metody agregacji to trzy sposoby zapewnienia struktury agregacji. Zobaczymy je szczegółowo w kolejnych artykułach.

Funkcje MongoDB – Agregacja
vii. GridFS
GridFS to funkcja przechowywania i pobierania plików. W przypadku plików większych niż 16 MB ta funkcja jest bardzo przydatna. GridFS dzieli dokument na części zwane porcjami i przechowuje je w osobnym dokumencie. Te porcje mają domyślny rozmiar 255kB z wyjątkiem ostatniej porcji.
Kiedy pytamy GridFS o plik, składa on wszystkie potrzebne fragmenty.
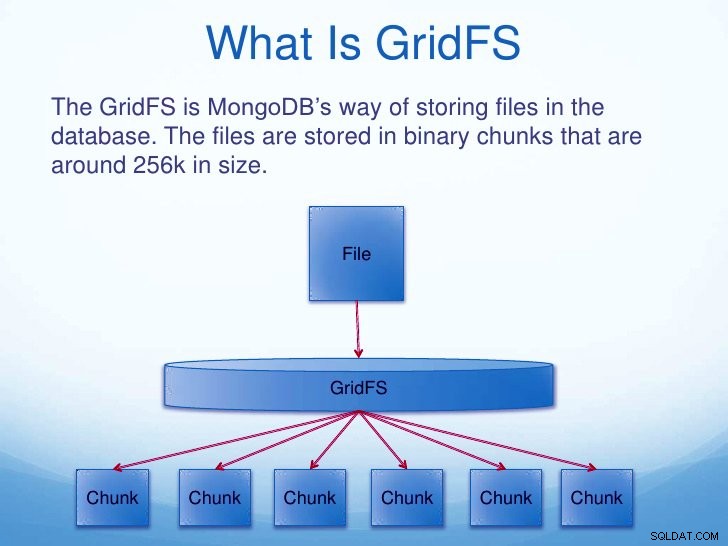
Funkcje MongoDB – GridFS
viii. Fragmentacja
Zasadniczo koncepcja shardingu pojawia się, gdy musimy poradzić sobie z większymi zestawami danych. Te ogromne dane mogą powodować pewne problemy, gdy przyjdzie do nich zapytanie. Ta funkcja pomaga w dystrybucji tych problematycznych danych do wielu instancji MongoDB.
Kolekcje w MongoDB, które mają większy rozmiar, są dystrybuowane w wielu kolekcjach. Te kolekcje nazywane są „odłamkami”. Odłamki są implementowane przez klastry.
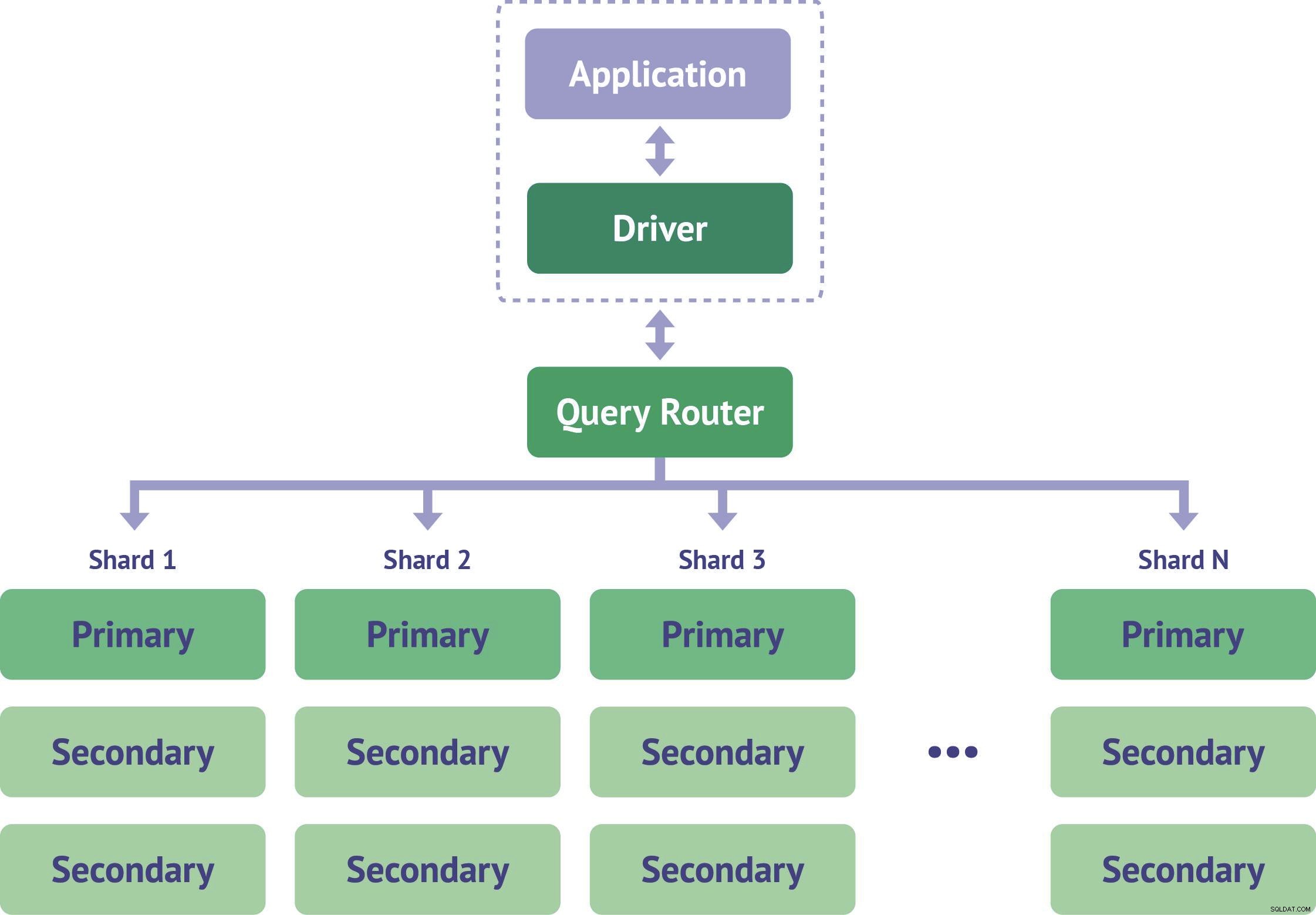
Funkcje MongoDB — fragmentowanie
ix. Wysoka wydajność
MongoDB to baza danych typu open source o wysokiej wydajności. Świadczy to o wysokiej dostępności i skalowalności. Ma szybszą odpowiedź na zapytania ze względu na indeksowanie i replikację. To sprawia, że jest to lepszy wybór w przypadku dużych zbiorów danych i aplikacji czasu rzeczywistego.
Tak więc chodziło o samouczek funkcji MongoDB. Mam nadzieję, że podoba Ci się nasze wyjaśnienie.
Wniosek
Dlatego omówiliśmy wszystkie ważne MongoDB oferuje wysoką wydajność, dzielenie na fragmenty, GridFS, agregację, replikację, indeksowanie, zorientowaną na dokumenty, bazę danych bez schematów i zapytania ad-hoc.
A także, jak są używane w dzisiejszym świecie. Zobaczymy zalety i ograniczenia MongoDB w kolejnym samouczku MongoDB.
Ponadto, jeśli masz jakiekolwiek pytania, możesz je zadać w sekcji komentarzy.



