Ten wpis na blogu jest kontynuacją poprzedniej części 1, w której omówiliśmy podstawy integracji SNMP z ClusterControl.
W tym wpisie na blogu skupimy się na pułapkach SNMP i alertach. Pułapki SNMP to najczęściej używane komunikaty alarmowe wysyłane ze zdalnego urządzenia obsługującego protokół SNMP (agenta) do centralnego kolektora, „menedżera SNMP”. W przypadku ClusterControl pułapka może być ostrzeżeniem, gdy alarm krytyczny dla klastra nie wynosi 0, co oznacza, że dzieje się coś złego.
Jak pokazano w poprzednim poście na blogu, na potrzeby tego sprawdzenia koncepcji mamy dwie definicje powiadomień pułapek SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Powiadomienia (lub pułapki) to krytyczneAlarmNotification i krytyczneAlarmNotificationEnded. Oba zdarzenia powiadomień mogą być używane do sygnalizowania naszej usłudze Nagios, niezależnie od tego, czy klaster ma aktywne alarmy krytyczne, czy nie. W Nagios terminem na to jest sprawdzanie pasywne, dzięki któremu Nagios nie próbuje określić, czy host/usługa jest NIEDOSTĘPNA lub NIEDOSTĘPNA. Skonfigurujemy również aktywne kontrole, w których kontrole są inicjowane przez logikę kontroli w demonie Nagios, przy użyciu definicji usługi również do monitorowania alarmów krytycznych/ostrzeżeń zgłaszanych przez nasz klaster.
Pamiętaj, że ten wpis na blogu wymaga poprawnego skonfigurowania agenta MIB i SNMP Manynines, jak pokazano w pierwszej części tej serii blogów.
Instalowanie rdzenia Nagios
Nagios Core to darmowa wersja pakietu monitorującego Nagios. Przede wszystkim musimy go zainstalować i wszystkie niezbędne pakiety, a następnie wtyczki Nagios, snmptrapd i snmptt. Zwróć uwagę, że instrukcje w tym poście na blogu zakładają, że wszystkie węzły działają na CentOS 7.
Zainstaluj pakiety niezbędne do uruchomienia Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlUtwórz użytkownika nagios i grupę nagcmd, aby umożliwić wykonywanie poleceń zewnętrznych przez interfejs sieciowy, dodaj użytkownika nagios i apache do grupy nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apachePobierz najnowszą wersję Nagios Core stąd, skompiluj ją i zainstaluj:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeZainstaluj konfigurację internetową Nagios:
$ make install-webconfOpcjonalnie zainstaluj motyw eksfoliacji Nagios (lub możesz trzymać się motywu domyślnego):
$ make install-exfoliationUtwórz konto użytkownika (nagiosadmin) do logowania się do interfejsu internetowego Nagios. Zapamiętaj hasło, które przypisałeś temu użytkownikowi:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminUruchom ponownie serwer Apache, aby nowe ustawienia zaczęły obowiązywać:
$ systemctl restart httpd
$ systemctl enable httpdPobierz stąd wtyczki Nagios, skompiluj i zainstaluj:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installZweryfikuj domyślne pliki konfiguracyjne Nagios:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosOtwórz przeglądarkę i przejdź do https://{IPaddress}/nagios i powinieneś zobaczyć podstawowe uwierzytelnianie HTTP, w którym musisz określić nazwę użytkownika jako nagiosadmin z wybranym wcześniej hasłem.
Dodawanie serwera ClusterControl do Nagios
Utwórz plik definicji hosta Nagios dla ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgI dodaj następujące wiersze:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Kilka wyjaśnień:
-
W pierwszej sekcji definiujemy naszego hosta, podając nazwę hosta i adres serwera ClusterControl.
-
Sekcje usług, w których umieszczamy nasze definicje usług, które mają być monitorowane przez Nagios. Pierwsze dwa w zasadzie mówią usłudze, aby sprawdziła dane wyjściowe SNMP pod kątem konkretnego identyfikatora obiektu. Pierwsza usługa dotyczy alarmu krytycznego, dlatego dodajemy -c0 w poleceniu check_snmp, aby wskazać, że powinien to być alarm krytyczny w Nagios, jeśli wartość przekroczy 0. Natomiast dla alarmów ostrzegawczych wskażemy to ostrzeżeniem, jeśli wartość wynosi 1 i więcej.
-
Ostatnia definicja usługi dotyczy pułapek SNMP, których oczekiwalibyśmy od serwera ClusterControl w przypadku krytycznego alarmu podniesiony jest większy niż 0. Ta sekcja użyje definicji snmp_trap_template, jak pokazano w następnym kroku.
Skonfiguruj snmp_trap_template, dodając następujące wiersze do /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Dołącz plik konfiguracyjny ClusterControl do Nagios, dodając następujący wiersz w środku
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgUruchom kontrolę konfiguracji przed lotem:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgUpewnij się, że na końcu danych wyjściowych znajduje się następujący wiersz:
"Things look okay - No serious problems were detected during the pre-flight check"Uruchom ponownie Nagios, aby załadować zmiany:
$ systemctl restart nagiosTeraz, gdy spojrzymy na stronę Nagios w sekcji Usługi (menu po lewej stronie), zobaczymy coś takiego:
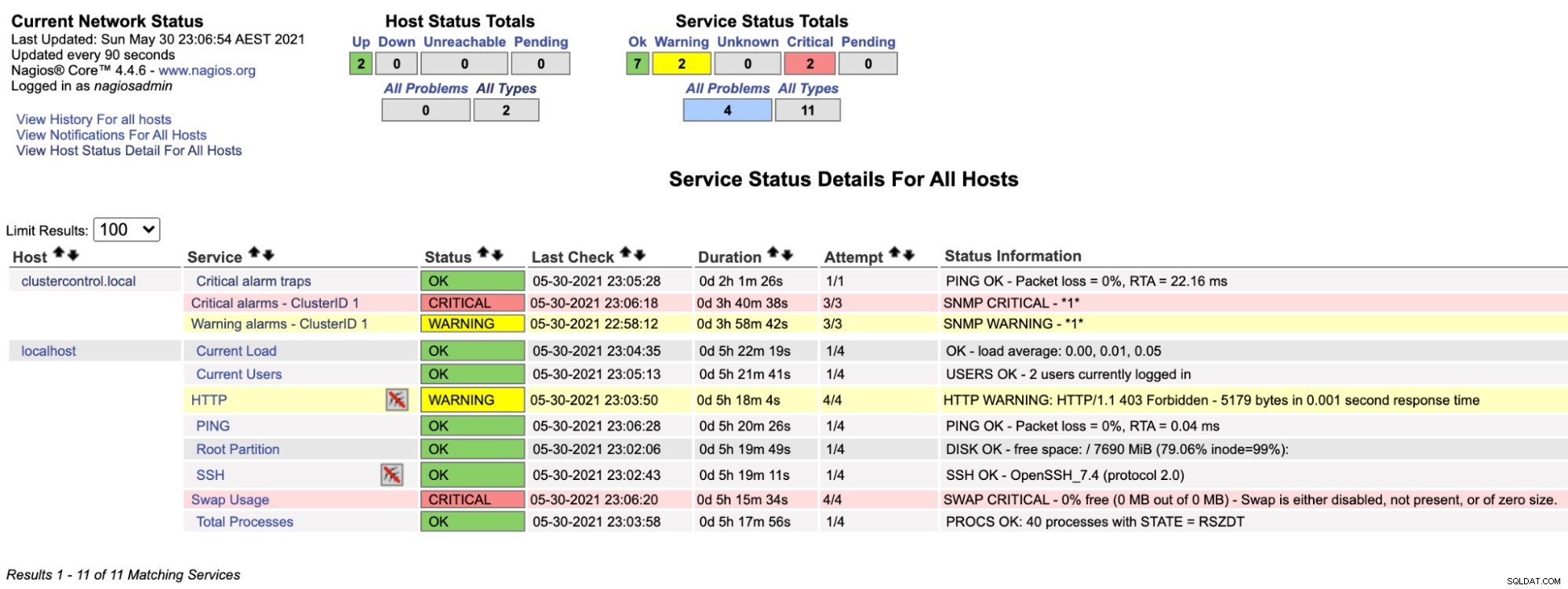
Zwróć uwagę, że wiersz „Alarmy krytyczne — ClusterID 1” zmienia kolor na czerwony, jeśli wartość krytycznego alarmu zgłaszana przez ClusterControl jest większa niż 0, natomiast wiersz „Alarmy ostrzegawcze — ClusterID 1” jest żółty, co wskazuje, że został zgłoszony alarm ostrzegawczy. Jeśli nie wydarzy się nic ciekawego, zobaczysz, że dla clustercontrol.local wszystko jest zielone.
Konfigurowanie Nagios do odbierania pułapki
Pułapki są wysyłane przez zdalne urządzenia do serwera Nagios, nazywa się to sprawdzaniem pasywnym. W idealnym przypadku nie wiemy, kiedy zostanie wysłana pułapka, ponieważ zależy to od tego, czy urządzenie wysyłające zdecyduje, że wyśle pułapkę. Na przykład z UPS (podtrzymanie bateryjne), gdy tylko urządzenie straci zasilanie, wyśle pułapkę, aby powiedzieć „hej, straciłem moc”. W ten sposób Nagios jest natychmiast informowany.
Aby odbierać pułapki SNMP, musimy skonfigurować serwer Nagios z następującymi rzeczami:
-
snmptrapd (demon odbierający pułapki SNMP)
-
snmptt (SNMP Trap Translator, demon obsługi pułapek)
Gdy snmptrapd odbierze pułapkę, przekaże ją do snmptt, gdzie skonfigurujemy go, aby zaktualizować system Nagios, a następnie Nagios wyśle alert zgodnie z konfiguracją grupy kontaktów.
Zainstaluj repozytorium EPEL, a następnie niezbędne pakiety:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogSkonfiguruj demona pułapki SNMP w /etc/snmp/snmptrapd.conf i ustaw następujące wiersze:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerPowyższe oznacza po prostu, że pułapki odebrane przez demona snmptrapd zostaną przekazane do /usr/sbin/snmptthandler.
Dodaj plik SEVERALNINES-CLUSTERCONTROL-MIB.txt do /usr/share/snmp/mibs, tworząc /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtUtwórz /etc/snmp/snmp.conf (zwróć uwagę bez „d”) i dodaj tam naszą niestandardową bazę MIB:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBUruchom usługę snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdNastępnie musimy skonfigurować następujące linie konfiguracyjne w /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDZauważ, że włączyliśmy moduł net_snmp_perl i dodaliśmy kolejną ścieżkę konfiguracji, /etc/snmp/snmptt-cc.conf wewnątrz snmptt.ini. Musimy tutaj zdefiniować zdarzenia ClusterControl snmptt, aby można je było przekazać do Nagios. Utwórz nowy plik w /etc/snmp/snmptt-cc.conf i dodaj następujące wiersze:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCKilka wyjaśnień:
-
Zdefiniowaliśmy dwie pułapki - krytyczneAlarmNotification i krytyczneAlarmNotificationEnded.
-
NotificationAlarmNotification po prostu wywołuje krytyczny alert i przekazuje go do usługi "Krytyczne pułapki alarmowe" zdefiniowanej w Nagios. $aA oznacza zwrócenie adresu IP agenta pułapki. Wartość 2 jest wartością wyniku sprawdzenia, która w tym przypadku jest krytyczna (0=OK, 1=OSTRZEŻENIE, 2=KRYTYCZNE, 3=NIEZNANE).
-
KritikalarmNotificationEnded po prostu generuje alert OK i przekazuje go do usługi „Krytyczne pułapki alarmowe”, aby anulować poprzednia pułapka po tym, jak wszystko wraca do normy. $aA oznacza zwrócenie adresu IP agenta pułapki. Wartość 0 jest wartością wyniku sprawdzenia, która w tym przypadku jest OK. Aby uzyskać więcej informacji na temat podstawień łańcuchów rozpoznawanych przez snmptt, zapoznaj się z tym artykułem w sekcji „FORMAT”.
-
Możesz użyć snmpttconvertmib do wygenerowania pliku obsługi zdarzeń snmptt dla konkretnego MIB.
Zauważ, że domyślnie ścieżka obsługi zdarzeń nie jest dostarczana przez rdzeń Nagios. Dlatego musimy skopiować ten katalog eventhandlers ze źródła Nagios do katalogu contrib, jak pokazano poniżej:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersMusimy również przypisać grupę snmptt jako część grupy nagcmd, aby mogła wykonać nagios.cmd w skrypcie submit_check_result:
$ usermod -a -G nagcmd snmpttUruchom usługę snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttMenedżer SNMP (serwer Nagios) jest teraz gotowy do przyjmowania i przetwarzania przychodzących pułapek SNMP.
Wysyłanie pułapki z serwera ClusterControl
Załóżmy, że ktoś chce wysłać pułapkę SNMP do menedżera SNMP, 192.168.10.11 (serwer Nagios), ponieważ całkowita liczba alarmów krytycznych osiągnęła 2 dla klastra o identyfikatorze 1, można uruchomić następujące polecenie na serwer ClusterControl (po stronie klienta), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Lub w formacie OID (zalecane):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Gdzie .1.3.6.1.4.1.57397.1.1.3.1 jest równe zdarzeniu pułapki „criticalAlarmNotification”, a kolejne OID są reprezentacjami odpowiednio całkowitej liczby bieżących alarmów krytycznych i identyfikatora klastra .
Na serwerze Nagios powinieneś zauważyć, że usługa pułapek zmieniła kolor na czerwony:
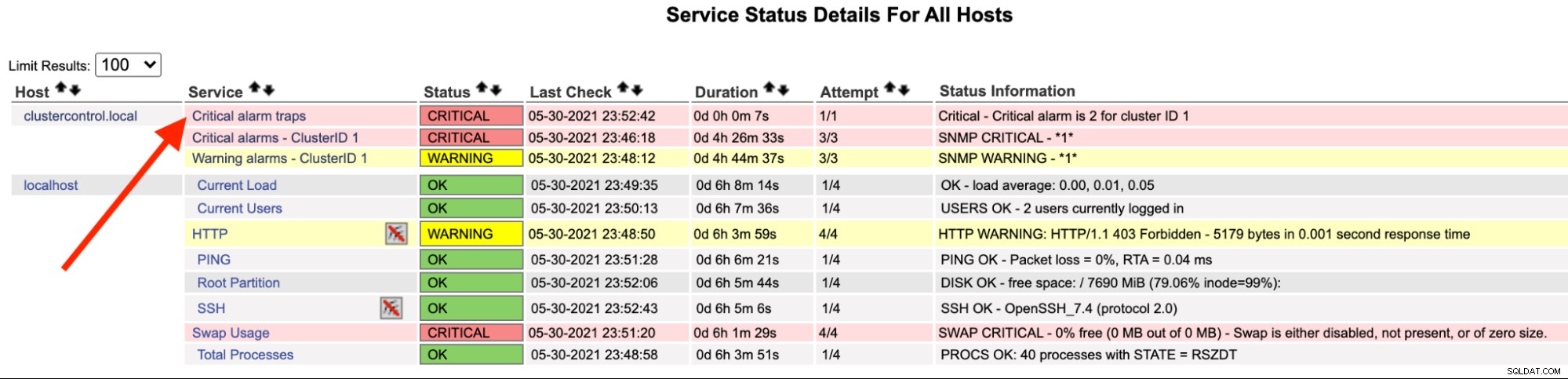
Możesz to również zobaczyć w /var/log/messages następującej linii:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Po rozwiązaniu alarmu, aby wysłać normalną pułapkę, możemy wykonać następujące polecenie:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Gdzie .1.3.6.1.1.4.57397.1.1.3.2 jest równe zdarzeniu krytycznyAlarmNotificationEnded, a kolejne OID są reprezentacją całkowitej liczby bieżących alarmów krytycznych (w tym przypadku powinno być0 ) i odpowiednio identyfikator klastra.
Na serwerze Nagios powinieneś zauważyć, że usługa pułapek znów jest zielona:
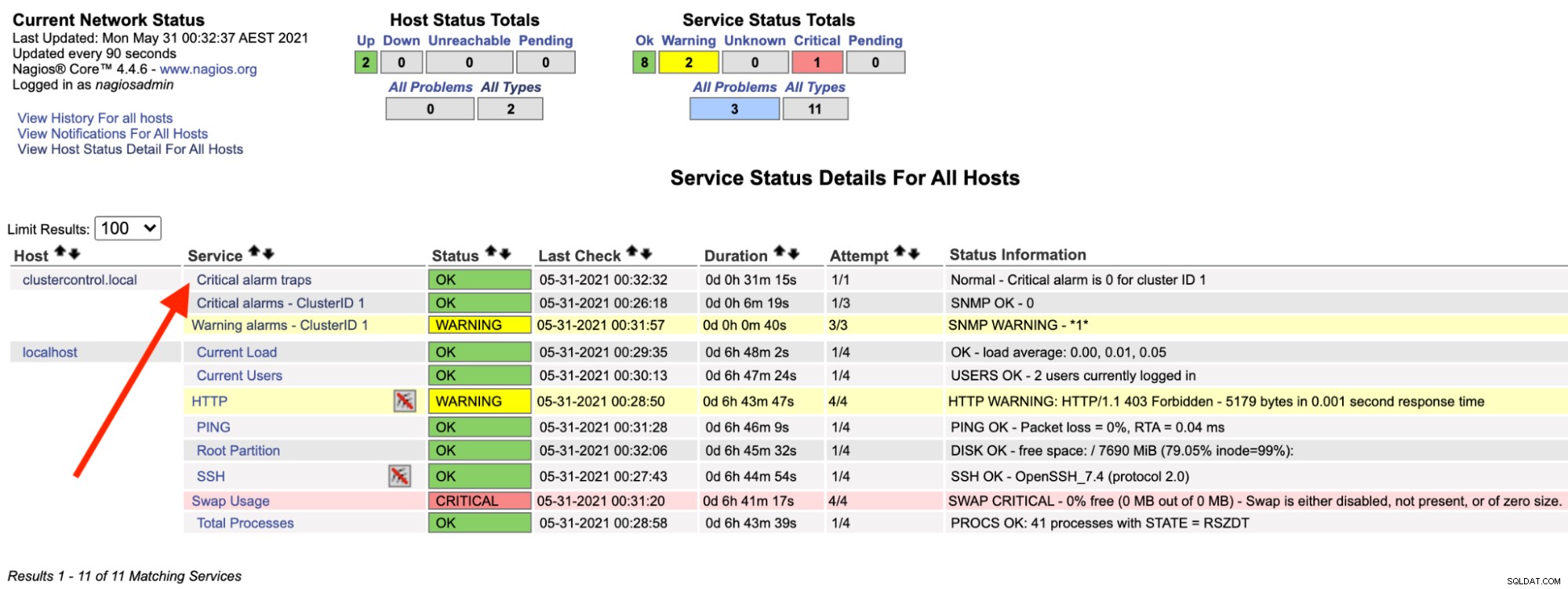
Powyższe czynności można zautomatyzować za pomocą prostego skryptu bash:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneAby uruchomić skrypt w tle, po prostu wykonaj:
$ bash alarmtrapper.bash &W tym momencie powinniśmy być w stanie zobaczyć usługę „Krytyczne pułapki alarmowe” Nagios w akcji, jeśli wystąpi awaria naszego klastra automatycznie.
Ostateczne myśli
W tej serii blogów pokazaliśmy dowód koncepcji, w jaki sposób można skonfigurować ClusterControl do monitorowania, generowania/przetwarzania pułapek i alarmowania za pomocą protokołu SNMP. Oznacza to również początek naszej podróży do włączenia SNMP do naszych przyszłych wersji. Bądź na bieżąco, ponieważ będziemy wprowadzać więcej informacji na temat tej ekscytującej funkcji.



