Każdy system baz danych posiada ustrukturyzowany komponent, który jest odpowiedzialny za utrzymywanie sposobu przechowywania i obsługi danych zarówno w pamięci, jak i na dysku. Jest to często określane jako silnik pamięci masowej. Częściej oceniając architekturę operacyjnych baz danych, programiści biorą pod uwagę czynniki z pierwszej ręki, takie jak modelowanie danych, zmniejszone opóźnienia, ulepszone operacje przepustowości, spójność danych, łatwość skalowalności i minimalna odporność na błędy. Mimo to trzeba mieć szczegółową i zaawansowaną wiedzę na temat bazowego silnika pamięci masowej, aby móc go lepiej dostroić, aby skutecznie dostarczał podświetlone czynniki.
Poniżej przedstawiono prosty cykl aplikacji do systemu db...
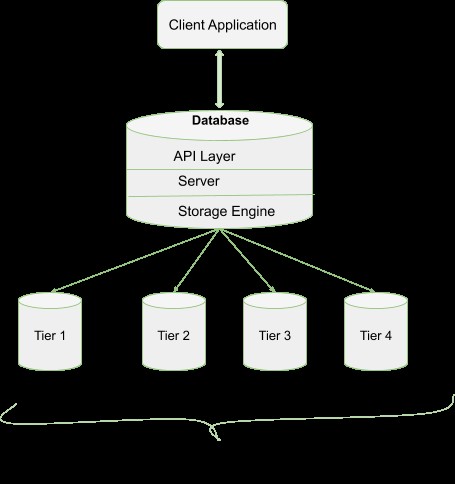 Przykład typowej architektury aplikacji
Przykład typowej architektury aplikacji Silnik pamięci masowej WiredTiger
MongoDB obsługuje głównie 3 silniki pamięci masowej, których wydajność różni się w zależności od określonych obciążeń. Silniki pamięci masowej to:
- Silnik pamięci masowej WiredTiger
- Silnik pamięci masowej w pamięci
- Silnik pamięci masowej MMAPv1
Silnik pamięci masowej WiredTiger ma obie konfiguracje silnika opartego na B-Tree i silnika opartego na strukturze logów.
Silnik oparty na B-Tree
Jest to jeden ze starożytnych silników pamięci masowej, z których wywodzą się inne wyrafinowane konfiguracje. Jest to samobalansująca, drzewiasta struktura danych, która zapewnia sortowanie danych i umożliwia wyszukiwanie, dostęp sekwencyjny, wstawianie i usuwanie w sposób logarytmiczny. Jest to przechowywanie oparte na wierszach, tak że każdy wiersz jest traktowany jako pojedynczy rekord w bazie danych
Zalety silnika B-Tree do przechowywania danych
- Wysoka przepustowość i małe opóźnienia w odczytach. B-Trees ma tendencję do powiększania się i rozszerzania tak, że przemierza się bardzo niewiele węzłów.
- Utrzymuje klucze w posortowanej kolejności podczas przechodzenia sekwencyjnego, a indeksy są równoważone algorytmem rekurencyjnym.
- Wewnętrzne węzły magazynowe są zawsze zapełnione co najmniej do połowy, co ogólnie zmniejsza straty.
- Łatwe w obsłudze dużej liczby wstawiania i usuwania w krótkim czasie.
- Hierarchiczne indeksowanie jest stosowane w celu zmniejszenia odczytów dysku.
- Przyspiesza wstawianie i usuwanie poprzez użycie częściowo pełnych bloków.
Ograniczenia silnika pamięci masowej B-Tree
- Słaba wydajność zapisu ze względu na konieczność zapewnienia uporządkowanej struktury danych z losowymi zapisami. Zapisy losowe są droższe niż zapisy sekwencyjne w pamięci.
- Kara za gotowość do modyfikacji i zapisu całego bloku, nawet za niewielką aktualizację wiersza w bloku.
Silnik oparty na strukturze logu opartego na drzewie scalania
Ze względu na słabą wydajność zapisu silnika opartego na B-Tree, programiści musieli wymyślić sposób radzenia sobie z większymi zestawami danych w DBMS. W związku z tym stworzono mechanizm Log Structured Merge Tree Based Engine (LSM Tree), aby poprawić wydajność indeksowanego dostępu do plików o dużej objętości zapisu przez dłuższy czas. W takim przypadku losowe zapisy na pierwszym etapie kaskadowania pamięci są zamieniane na sekwencyjne zapisy w pierwszym składniku na dysku.
Zalety silnika do przechowywania drzew LSM
- Możliwość wykonywania szybkich zapisów sekwencyjnych poprawia szybką obsługę dużych, szybko rosnących danych.
- Dobrze nadaje się do warstwowej pamięci masowej, co zapewnia organizacjom lepszy wybór pod względem kosztów i wydajności. W tym przypadku dyski SSD oparte na technologii Flash zapewniają doskonałą wydajność.
- Lepsza kompresja i wydajność przechowywania, a tym samym oszczędność miejsca i zwiększenie prawie pełnego przechowywania
- Dane są zawsze dostępne do natychmiastowego zapytania.
- Wstawienia są bardzo szybkie.
Ograniczenia silnika pamięci masowej B-Tree
Zużywa więcej pamięci w porównaniu do B-Tree podczas operacji odczytu ze względu na wzmocnienie odczytu i przestrzeni. Jednak niektóre podejścia, takie jak filtry bloom, w praktyce złagodziły ten efekt, dzięki czemu liczba plików do sprawdzenia podczas zapytania punktowego jest zmniejszona.
Technologia WiredTiger została zaprojektowana w taki sposób, aby wykorzystywać zalety zarówno B-Tree, jak i LSM, co czyni ją wyrafinowanym i najlepszym silnikiem pamięci masowej dla MongoDB. IT jest w rzeczywistości domyślnym silnikiem pamięci masowej MongoDB.
Kilkadziesiąt — Zostań administratorem baz danych MongoDB — wprowadzenie MongoDB do produkcjiDowiedz się, co trzeba wiedzieć, aby wdrażać, monitorować, zarządzać i skalować MongoDB. Pobierz za darmoArchitektura silnika pamięci masowej WiredTiger
Jak wspomniano powyżej, obejmuje ona koncepcję dwóch podstawowych silników pamięci masowej, czyli silników B-Tree i LSM Tree, a zatem jest to silnik pamięci masowej wielowersyjnej kontroli współbieżności (MVCC). Zalety tych dwóch połączonych umożliwiają systemowi zobaczenie migawki bazy danych w momencie, gdy uzyskuje dostęp do kolekcji. Punkty kontrolne są ustalane w taki sposób, że spójny widok danych jest zapisywany na dysku pomiędzy punktami kontrolnymi. W przypadku awarii między punktami kontrolnymi, łatwo je odzyskać za pomocą tych punktów kontrolnych, a nawet jeśli nie ma punktów kontrolnych dla danych, można je odzyskać z plików dziennika dysku.
Rozległe użycie pamięci podręcznej zamiast dysku w celu zwiększenia małych opóźnień. Silnik pamięci masowej WiredTiger w dużej mierze opiera się na pamięci podręcznej stron systemu operacyjnego, dzięki czemu skompresowane dane są pobierane bez angażowania dysku. Poza tym najrzadziej używane dane są usuwane z pamięci RAM, zachowując więcej miejsca na pamięć podręczną.
Koncepcja pamięci masowej B-Tree zapewnia wysoce wydajny odczyt i dobrą wydajność zapisu przy niskim obciążeniu procesora. Ma również implementację blokowania na poziomie dokumentu, która umożliwia wysoce współbieżne obciążenia, a ta współbieżność w konsekwencji ułatwia serwerowi wykorzystanie wielu rdzeni procesorów. Ogólnie rzecz biorąc, wszystkie tezy zwiększają wysoką skalowalność bazy danych.
Wersja Enterprise obsługuje szyfrowanie na dysku dla silnika pamięci masowej WiredTiger, co jest funkcją, która znacznie poprawia bezpieczeństwo danych.
Silnik pamięci masowej WiredTiger umożliwia rejestrowanie z wyprzedzeniem, co zapewnia automatyczne odzyskiwanie po awarii i sprawia, że zapisy są trwałe.
Zalety silnika pamięci masowej WiredTiger
- Wydajne przechowywanie dzięki wielu technologiom kompresji, takim jak kompresja Snapp, gzip i prefiks.
- Jest wysoce skalowalny dzięki równoczesnym odczytom i zapisom. To ostatecznie poprawia przepustowość i ogólną wydajność bazy danych.
- Zapewnij trwałość danych dzięki dziennikowi zapisu z wyprzedzeniem i wykorzystaniu punktów kontrolnych.
- Optymalne wykorzystanie pamięci. WiredTiger używa zarówno wewnętrznej pamięci podręcznej, jak i pamięci podręcznej systemu plików.
- Dzięki pamięci podręcznej systemu plików MongoDB może z łatwością korzystać z wolnej pamięci, która nie jest używana przez pamięć podręczną WiredTiger.
Wady silnika pamięci masowej WiredTiger
Trudności w aktualizacji danych. Schemat współbieżności zapobiega aktualizacjom na miejscu, tak że aktualizacja wartości pola w dokumencie powoduje ponowne zapisanie całego dokumentu.
Wniosek
Silnik pamięci masowej WiredTiger integruje koncepcje dwóch głównych silników pamięci masowej, silnika pamięci masowej B-Tree i drzewa LSM, aby osiągnąć maksymalną i optymalną wydajność. Rozważenie korzyści z obu przypadków i wspólne ich wykorzystanie sprawia, że WiredTiger jest silnikiem do przechowywania ogólnego zastosowania. Z tego powodu w obecnych wersjach MongoDB jest to domyślny silnik przechowywania. Oznacza to, że jeśli naprawdę nie masz silnego powodu, aby się nim brzydzić, to jest to najlepsze dla twoich danych. Jednak wybór silnika pamięci masowej w dużej mierze zależy od przypadku użycia danych, a raczej od sytuacji, w której WiredTiger nie może spełnić Twoich oczekiwań. Ogólnie jest to najlepszy domyślny silnik pamięci masowej.



