MongoDB to baza danych NoSQL, która obsługuje szeroką gamę źródeł wejściowych zestawów danych. Jest w stanie przechowywać dane w elastycznych dokumentach podobnych do JSON, co oznacza, że pola lub metadane mogą się różnić w zależności od dokumentu, a struktura danych może być zmieniana w czasie. Model dokumentu ułatwia pracę z danymi dzięki odwzorowaniu na obiekty w kodzie aplikacji. MongoDB jest również znany jako rozproszona baza danych, więc wysoka dostępność, skalowanie poziome i dystrybucja geograficzna są wbudowane i łatwe w użyciu. Posiada możliwość płynnej modyfikacji parametrów do trenowania modelu. Naukowcy zajmujący się danymi mogą łatwo połączyć strukturyzację danych z tą generacją modelu.
Co to jest uczenie maszynowe?
Uczenie maszynowe to nauka polegająca na nakłonieniu komputerów do uczenia się i działania tak, jak robią to ludzie, oraz do ulepszania ich uczenia się w czasie w sposób autonomiczny. Proces uczenia się zaczyna się od obserwacji lub danych, takich jak przykłady, bezpośrednie doświadczenie lub instrukcje, w celu poszukiwania wzorców w danych i podejmowania lepszych decyzji w przyszłości na podstawie podanych przez nas przykładów. Głównym celem jest umożliwienie komputerom automatycznego uczenia się bez interwencji lub pomocy człowieka i odpowiedniego dostosowania działań.
Rozbudowany model programowania i zapytań
MongoDB oferuje zarówno natywne sterowniki, jak i certyfikowane złącza dla programistów i naukowców zajmujących się danymi budującymi modele uczenia maszynowego z danymi z MongoDB. PyMongo to świetna biblioteka do osadzania składni MongoDB w kodzie Pythona. Możemy zaimportować wszystkie funkcje i metody MongoDB, aby wykorzystać je w naszym kodzie uczenia maszynowego. Jest to świetna technika, aby uzyskać wielojęzyczną funkcjonalność w jednym kodzie. Dodatkową zaletą jest to, że możesz użyć podstawowych funkcji tych języków programowania, aby stworzyć wydajną aplikację.
Język zapytań MongoDB z rozbudowanymi indeksami dodatkowymi umożliwia programistom tworzenie aplikacji, które mogą wysyłać zapytania i analizować dane w wielu wymiarach. Dostęp do danych można uzyskać za pomocą pojedynczych kluczy, zakresów, wyszukiwania tekstowego, wykresów i zapytań geoprzestrzennych za pomocą złożonych agregacji i zadań MapReduce, zwracając odpowiedzi w ciągu milisekund.
W celu zrównoleglenia przetwarzania danych w rozproszonym klastrze baz danych, MongoDB udostępnia potok agregacji i MapReduce. Potok agregacji MongoDB jest modelowany zgodnie z koncepcją potoków przetwarzania danych. Dokumenty wchodzą do wieloetapowego potoku, który przekształca je w zagregowany wynik przy użyciu natywnych operacji wykonywanych w MongoDB. Najbardziej podstawowe etapy potoku zapewniają filtry działające jak zapytania i przekształcenia dokumentu, które modyfikują formę dokumentu wyjściowego. Inne operacje potoku zapewniają narzędzia do grupowania i sortowania dokumentów według określonych pól, a także narzędzia do agregowania zawartości tablic, w tym tablic dokumentów. Ponadto etapy pipseline mogą używać operatorów do zadań, takich jak obliczanie średniej lub odchylenia standardowego w zbiorach dokumentów oraz manipulowanie ciągami. MongoDB zapewnia również natywne operacje MapReduce w bazie danych, wykorzystując niestandardowe funkcje JavaScript do wykonywania mapy i zmniejszania etapów.
Oprócz natywnej struktury zapytań, MongoDB oferuje również wysokowydajny łącznik dla Apache Spark. Łącznik udostępnia wszystkie biblioteki Spark, w tym Python, R, Scala i Java. Dane MongoDB są materializowane w postaci ramek DataFrames i zestawów danych do analizy za pomocą interfejsów API uczenia maszynowego, wykresów, przesyłania strumieniowego i SQL.
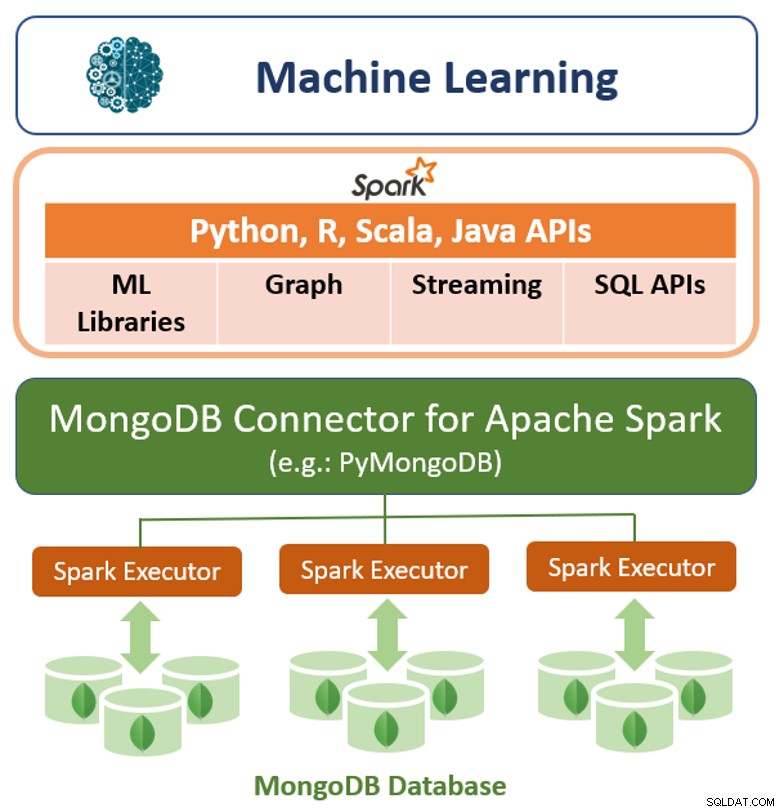
Łącznik MongoDB dla Apache Spark może korzystać z potoku agregacji MongoDB i dodatkowego indeksy do wyodrębniania, filtrowania i przetwarzania tylko tego zakresu danych, których potrzebuje - na przykład analizowanie wszystkich klientów znajdujących się w określonej lokalizacji geograficznej. Różni się to bardzo od prostych magazynów danych NoSQL, które nie obsługują ani indeksów pomocniczych, ani agregacji w bazie danych. W takich przypadkach Spark musiałby wyodrębnić wszystkie dane na podstawie prostego klucza podstawowego, nawet jeśli tylko podzbiór tych danych jest wymagany dla procesu Spark. Oznacza to większe obciążenie przetwarzania, więcej sprzętu i dłuższy czas na uzyskanie wglądu dla naukowców i inżynierów zajmujących się danymi. Aby zmaksymalizować wydajność w dużych, rozproszonych zestawach danych, MongoDB Connector dla Apache Spark może współlokować Resilient Distributed Datasets (RDD) ze źródłowym węzłem MongoDB, minimalizując w ten sposób przepływ danych w klastrze i zmniejszając opóźnienia.
Wydajność, skalowalność i nadmiarowość
Czas uczenia modelu można skrócić, budując platformę uczenia maszynowego na wydajnej i skalowalnej warstwie bazy danych. MongoDB oferuje szereg innowacji, aby zmaksymalizować przepustowość i zminimalizować opóźnienia obciążeń uczenia maszynowego:
- WiredTiger jest znany jako domyślny silnik pamięci masowej dla MongoDB, opracowany przez architektów Berkeley DB, najszerzej stosowanego oprogramowania do zarządzania danymi wbudowanymi na świecie. WiredTiger skaluje się w nowoczesnych, wielordzeniowych architekturach. Korzystając z różnych technik programowania, takich jak wskaźniki zagrożeń, algorytmy bez blokad, szybkie zatrzaskiwanie i przekazywanie komunikatów, WiredTiger maksymalizuje pracę obliczeniową na rdzeń procesora i cykl zegara. Aby zminimalizować obciążenie dysku i operacje we/wy, WiredTiger używa kompaktowych formatów plików i kompresji pamięci.
- W przypadku aplikacji do uczenia maszynowego, które są najbardziej wrażliwe na opóźnienia, MongoDB można skonfigurować za pomocą mechanizmu pamięci masowej w pamięci. Oparty na WiredTiger, ten silnik pamięci masowej zapewnia użytkownikom korzyści związane z przetwarzaniem w pamięci, bez rezygnacji z bogatej elastyczności zapytań, analizy w czasie rzeczywistym i skalowalnej pojemności oferowanej przez konwencjonalne bazy danych oparte na dyskach.
- W celu zrównoleglenia uczenia modeli i skalowania wejściowych zestawów danych poza pojedynczy węzeł, MongoDB wykorzystuje technikę zwaną shardingiem, która dystrybuuje przetwarzanie i dane w klastrach powszechnie dostępnego sprzętu. Fragmentacja MongoDB jest w pełni elastyczna, automatycznie równoważąc dane w klastrze w miarę wzrostu zestawu danych wejściowych lub dodawania i usuwania węzłów.
- W klastrze MongoDB dane z każdego fragmentu są automatycznie dystrybuowane do wielu replik hostowanych na osobnych węzłach. Zestawy replik MongoDB zapewniają nadmiarowość w celu odzyskania danych treningowych w przypadku awarii, zmniejszając obciążenie związane z punktami kontrolnymi.
Dostrajalna spójność MongoDB
MongoDB jest domyślnie silnie spójny, umożliwiając aplikacjom uczenia maszynowego natychmiastowe odczytanie tego, co zostało zapisane w bazie danych, unikając w ten sposób złożoności programistów narzuconej przez ostatecznie spójne systemy. Silna spójność zapewni najdokładniejsze wyniki dla algorytmów uczenia maszynowego; jednak w niektórych scenariuszach dopuszczalne jest porównanie spójności z określonymi celami wydajności poprzez dystrybucję zapytań w klastrze członków wtórnego zestawu replik MongoDB.
Elastyczny model danych w MongoDB
Model danych dokumentu MongoDB ułatwia programistom i analitykom danych przechowywanie i agregowanie danych o dowolnej formie struktury w bazie danych, bez rezygnacji z wyrafinowanych reguł walidacji w celu zarządzania jakością danych. Schemat może być dynamicznie modyfikowany bez przestojów aplikacji lub bazy danych, które wynikają z kosztownych modyfikacji schematu lub przeprojektowania poniesionych przez relacyjne systemy baz danych.
Zapisywanie modeli w bazie danych i ładowanie ich za pomocą Pythona jest również łatwą i bardzo wymaganą metodą. Wybór MongoDB jest również zaletą, ponieważ jest to baza dokumentów o otwartym kodzie źródłowym, a także wiodąca baza danych NoSQL. MongoDB służy również jako złącze do rozproszonego frameworka Apache Spark.
Dynamiczna natura MongoDB
Dynamiczny charakter MongoDB umożliwia jego wykorzystanie w zadaniach manipulacji bazami danych w tworzeniu aplikacji uczenia maszynowego. Jest to bardzo wydajny i łatwy sposób na przeprowadzenie analizy zbiorów danych i baz danych. Wyniki analizy można wykorzystać do uczenia modeli uczenia maszynowego. Zaleca się, aby analitycy danych i programiści uczenia maszynowego opanowali MongoDB i zastosowali go w wielu różnych aplikacjach. Platforma agregacji MongoDB jest używana do przepływu pracy związanej z nauką o danych do przeprowadzania analizy danych dla wielu aplikacji.
Wnioski
MongoDB oferuje kilka różnych możliwości, takich jak:elastyczny model danych, bogate programowanie, model danych, model zapytań i jego przestrajalna spójność, które znacznie ułatwiają uczenie i korzystanie z algorytmów uczenia maszynowego niż w przypadku tradycyjnych, relacyjnych baz danych. Uruchamianie MongoDB jako bazy danych zaplecza umożliwi przechowywanie i wzbogacanie danych uczenia maszynowego, co zapewnia trwałość i zwiększoną wydajność.



