Ponieważ używasz wiosny. Możesz użyć MultipartFile aby pobrać plik do kontrolera, a następnie użyj Binary z org.bson do przechowywania pliku w MongoDB , Jeśli rozmiar obrazu <16 MB (jeśli rozmiar obrazu> 16 MB, możesz użyć GridFs
).
Musisz dodać tylko jedną zależność do swojego projektu - spring-data-mongoDB
Weźmy przykład kolekcji User, która wygląda tak:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Tutaj możesz zobaczyć Binary image który reprezentuje twój plik obrazu.
Teraz utwórz repozytorium dla tej kolekcji użytkownika za pomocą MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Utwórz kontroler do celów demonstracyjnych. Użyj pliku @RequestParam MultipartFile file aby pobrać plik do kontrolera, pobierz bajty z pliku i ustaw go na obiekt użytkownika user.setImage(new Binary(file.getBytes())); pełny przykład znajduje się poniżej:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Uruchom serwer i kliknij punkt końcowy, jak pokazano na poniższym zrzucie listonosza
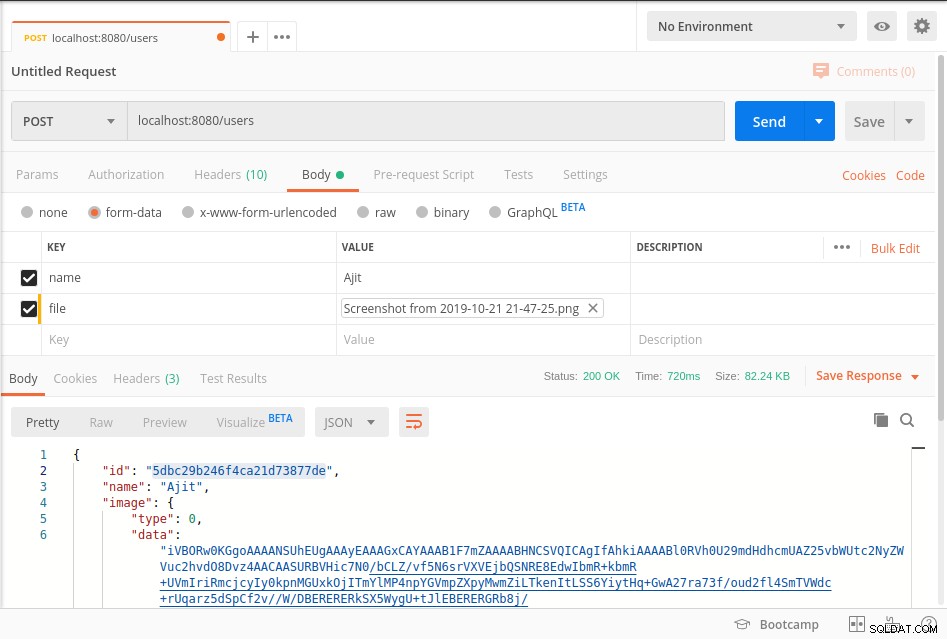
Twoje dane są przechowywane w mongoDb w BinData format i aby pobrać dane z bazy danych, zapoznaj się z getImage metoda powyższego kodu.
EDYTUJ:
Pytający używa tess4j biblioteka do wyodrębniania tekstu z obrazu i doOCR to metoda w tej bibliotece. Wykonałem te kroki, aby wyodrębnić tekst z obrazu w mojej aplikacji Spring Boot.
-
Zainstaluj
tesseract-ocrdo twojego systemu:sudo apt-get install tesseract-ocr -
Pobierz
eng.traineddatadane treningowe z https://github.com/tesseract-ocr/tessdata i przenieś go do głównego folderu projektu. -
Dodaj poniższą zależność do swojego projektu:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Dodaj poniższy kod do istniejącego projektu:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}