Więcej analizy zapytania dotyczącego populacji kluczy
W części 3 naszej serii śledzenia ODBC przyjrzymy się bliżej kluczom zarządzania programem Access dla tabel połączonych ODBC oraz sposobom sortowania i grupowania zapytań SELECT. W poprzednim artykule dowiedzieliśmy się, że zestaw rekordów typu dynaset to w rzeczywistości 2 oddzielne zapytania, przy czym pierwsze zapytanie pobiera tylko klucze z tabeli połączonej ODBC, która jest następnie używana do wypełniania danych. W tym artykule przyjrzymy się nieco więcej o tym, jak program Access zarządza kluczami i jak wywnioskuje, jaki jest klucz do użycia w tabeli połączonej ODBC, a także jakie ma konsekwencje. Zaczniemy od sortowania.
Dodawanie sortowania do zapytania
Widzieliście w poprzednim artykule, że zaczęliśmy od prostego SELECT bez konkretnego zamówienia. Widziałeś też, jak program Access po raz pierwszy pobrał CityID i użyj wyniku pierwszego zapytania, aby następnie wypełnić kolejne zapytania, aby zapewnić użytkownikowi wrażenie szybkości podczas otwierania dużego zestawu rekordów. Jeśli kiedykolwiek doświadczyłeś sytuacji, w której dodawanie sortowania lub grupowania do zapytania nagle spowalniało, wyjaśnisz, dlaczego.
Dodajmy sortowanie do StateProvinceID w zapytaniu programu Access:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Teraz, jeśli prześledzimy SQL ODBC, powinniśmy zobaczyć wynik:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Jeśli porównasz ze śladem z poprzedniego artykułu, zobaczysz, że są one takie same, z wyjątkiem pierwszego zapytania. Program Access umieścił sortowanie w pierwszym zapytaniu, którego używa do pobrania kluczy. Ma to sens, ponieważ wymuszając sortowanie na kluczach, których używa do przeglądania rekordów, program Access ma gwarancję, że będzie mieć zgodność jeden do jednego między pozycją porządkową rekordu a tym, jak powinien być sortowany. Następnie wypełnia rekordy dokładnie w ten sam sposób. Jedyną różnicą jest kolejność kluczy, których używa do wypełniania innych zapytań.
Zastanówmy się, co się stanie, gdy dodamy GROUP BY obliczając miasta na stan:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Śledzenie powinno wyprowadzić:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Być może zauważyłeś również, że zapytanie otwiera się teraz powoli i mimo że może być ustawione jako zestaw rekordów typu dynaset, program Access zignorował to i potraktował jako zestaw rekordów typu migawki. Ma to sens, ponieważ zapytania nie można aktualizować i ponieważ tak naprawdę nie można przejść do dowolnej pozycji w zapytaniu takim jak to. Dlatego musisz poczekać, aż wszystkie wiersze zostaną pobrane, zanim będziesz mógł swobodnie przeglądać. StateProvinceID nie może być użyty do zlokalizowania rekordu, ponieważ byłoby kilka rekordów w Cities stół. Chociaż użyłem GROUP BY w tym przykładzie nie musi to być grupa, która powoduje, że program Access zamiast tego używa zestawu rekordów typu migawki. Używanie DISTINCT na przykład miałby ten sam efekt. Przydatną praktyczną zasadą pozwalającą przewidzieć, czy program Access będzie używał zestawu rekordów typu zestaw dynamiczny, jest zapytanie, czy dany wiersz w wynikowym zestawie rekordów jest mapowany z powrotem na dokładnie jeden wiersz w źródle danych ODBC. Jeśli tak nie jest, program Access użyje zachowania migawki, nawet jeśli zapytanie miało używać dynaset. W konsekwencji, tylko dlatego, że domyślnym jest zestaw rekordów typu dynaset, nie gwarantuje to, że w rzeczywistości będzie to zestaw rekordów typu dynaset. To tylko prośba , a nie żądanie.
Określanie klucza używanego do wybierania
Być może zauważyłeś, że w poprzednim śledzonym języku SQL zarówno w tym, jak i w poprzednich artykułach, program Access używał CityID jako klucz. Ta kolumna została pobrana w pierwszym zapytaniu, a następnie użyta w kolejnych przygotowanych zapytaniach. Ale skąd program Access wie, których kolumn tabeli połączonej powinien używać? Pierwszym odruchem byłoby stwierdzenie, że sprawdza klucz podstawowy i używa go. Byłoby to jednak błędne. W rzeczywistości silnik bazy danych Access będzie wykorzystywał SQLStatistics ODBC funkcji podczas łączenia lub ponownego łączenia tabeli w celu sprawdzenia, jakie indeksy są dostępne. Ta funkcja zwróci zestaw wyników z jednym wierszem dla każdej kolumny uczestniczącej w indeksie dla wszystkich indeksów. Ten zbiór wyników jest zawsze posortowany i zgodnie z konwencją zawsze sortuje indeksy klastrowe, indeksy haszowane, a następnie inne typy indeksów. W ramach każdego typu indeksu indeksy zostaną posortowane alfabetycznie według ich nazw. Aparat bazy danych programu Access wybierze pierwszy znaleziony unikatowy indeks, nawet jeśli nie jest to rzeczywisty klucz podstawowy. Aby to udowodnić, stworzymy głupią tabelę z kilkoma dziwnymi indeksami:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Jeśli następnie wypełnimy tabelę pewnymi danymi i połączymy się z nią w programie Access, a następnie otworzymy widok arkusza danych w tabeli połączonej, zobaczymy to w śledzonym SQL ODBC. Dla zwięzłości zawarte są tylko 2 pierwsze polecenia.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Ponieważ
OtherStuff uczestniczy w indeksie klastrowym, pojawił się przed rzeczywistym kluczem podstawowym, a zatem został wybrany przez aparat bazy danych programu Access do użycia w zestawie rekordów typu dynaset w celu wybrania pojedynczego wiersza. Dzieje się tak również pomimo faktu, że unikatowa nazwa indeksu klastrowego pojawiłaby się po nazwie indeksu podstawowego. Taktyka wymuszenia w aparacie bazy danych programu Access wybrania określonego indeksu dla tabeli polegałaby na zmianie jego typu lub zmianie nazwy w taki sposób, aby sortował alfabetycznie w grupie typu indeksu. W przypadku SQL Server klucze podstawowe są zwykle klastrowane i może istnieć tylko jeden indeks klastrowany, więc szczęśliwym przypadkiem jest to, że jest to zwykle prawidłowy indeks do użycia przez silnik bazy danych Access. Jeśli jednak baza danych SQL Server zawiera tabele z nieklastrowanymi kluczami podstawowymi i istnieje klastrowany unikalny indeks, który może nie być optymalnym wyborem. W przypadkach, w których nie ma żadnych indeksów klastrowych, możesz wpłynąć na to, które unikalne indeksy będą używane, nazywając indeks tak, aby był sortowany przed innymi indeksami. Może to być pomocne w przypadku innego oprogramowania RDBMS, w którym tworzenie indeksu klastrowego dla klucza podstawowego nie jest praktyczne lub możliwe. Indeks po stronie dostępu dla połączonego widoku SQL lub tabeli bez indeksów
W przypadku łączenia z widokiem SQL lub tabelą SQL, która nie ma zdefiniowanych żadnych indeksów ani klucza podstawowego, aparat bazy danych programu Access nie będzie mógł używać żadnych indeksów. Jeśli używałeś menedżera tabel połączonych do łączenia tabeli lub widoku SQL bez indeksów, mogłeś zobaczyć takie okno dialogowe:
 Jeśli wybierzemy
Jeśli wybierzemy ID , zakończ łączenie, otwórz połączoną tabelę w widoku projektu, a następnie okno dialogowe indeksów, powinniśmy zobaczyć to:
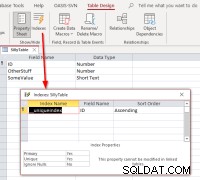 Pokazuje, że tabela ma indeks o nazwie
Pokazuje, że tabela ma indeks o nazwie __uniqueindex ale nie istnieje w oryginalnym źródle danych. Co się dzieje? Odpowiedź jest taka, że program Access utworzył stronę dostępu indeks do jego użycia, aby pomóc zidentyfikować, który może być używany jako identyfikator rekordu dla takich tabel lub widoków. Jeśli zdarzy się, że programowo ponownie połączysz tabele, a nie użyjesz Menedżera tabel połączonych, okaże się, że konieczne będzie zreplikowanie zachowania, aby takie tabele połączone można było aktualizować. Można to zrobić, wykonując polecenie Access SQL:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Możesz użyć na przykład
CurrentDb.Execute aby wykonać Access SQL w celu utworzenia indeksu w tabeli połączonej. Nie należy jednak wykonywać go jako zapytania przekazującego, ponieważ indeks nie jest w rzeczywistości tworzony na serwerze. Tylko korzyści z programu Access umożliwiają aktualizowanie tego połączonego stołu. Warto zauważyć, że Access zezwoli tylko na jeden indeks dla takiej tabeli połączonej i tylko wtedy, gdy nie ma jeszcze indeksów. Niemniej jednak widać, że użycie widoku SQL może być pożądaną opcją w przypadkach, gdy projekt bazy danych nie pozwala na użycie indeksów klastrowych i nie chcesz bawić się nazwą indeksu, aby skłonić aparat bazy danych Access do korzystania z tego indeksu, nie ten indeks. Możesz wyraźnie kontrolować indeks i kolumny, które powinien zawierać podczas łączenia widoku SQL.
Wnioski
Z poprzedniego artykułu widzieliśmy, że zestaw rekordów typu dynaset zwykle wysyła 2 zapytania. Pierwsze zapytanie zwykle dotyczy wypełniania danych. Przyjrzeliśmy się dokładniej, jak program Access obsługuje wypełnianie kluczy, których będzie używał dla zestawu rekordów typu Dynaset. Widzieliśmy, jak program Access faktycznie przekonwertuje sortowanie z oryginalnego zapytania programu Access, a następnie użyje go w zapytaniu z wypełnianiem kluczy. Widzieliśmy, że kolejność zapytań o populację kluczy ma bezpośredni wpływ na to, jak dane w zestawie rekordów będą sortowane i prezentowane użytkownikowi. Dzięki temu użytkownik może wykonywać takie rzeczy, jak przeskakiwanie do wpisu britrary na podstawie pozycji porządkowej na liście.
Następnie zobaczyliśmy, że grupowanie i inne operacje SQL, które uniemożliwiają mapowanie jeden-jeden między zwróconym wierszem a wierszem pierwotnym, powodują, że program Access potraktuje zapytanie programu Access tak, jakby było zestawem rekordów typu migawka, pomimo żądania zestawu rekordów typu zestaw dynamiczny.
Następnie przyjrzeliśmy się, w jaki sposób program Access określa klucz do zarządzania aktualizacjami za pomocą tabeli połączonej ODBC. W przeciwieństwie do tego, czego można by się spodziewać, niekoniecznie wybierze klucz podstawowy tabeli, ale raczej pierwszy unikalny indeks, jaki znajdzie, w zależności od typu indeksu i nazwy indeksu. Omówiliśmy strategie zapewniające, że program Access wybierze właściwy unikalny indeks. Przyjrzeliśmy się widokowi SQL, który zwykle nie ma żadnych indeksów, i omówiliśmy metodę informowania programu Access o tym, jak kluczować widok SQL lub tabelę, która nie ma żadnego klucza podstawowego, co pozwala nam na większą kontrolę nad tym, jak program Access będzie obsługiwał aktualizacje dla te tabele połączone ODBC.
W następnym artykule przyjrzymy się, w jaki sposób program Access faktycznie wykonuje aktualizacje danych, gdy użytkownicy wprowadzają zmiany za pomocą zapytania programu Access lub źródła rekordów.
Nasi eksperci ds. dostępu są gotowi do pomocy. Zadzwoń do nas pod numer 773-809-5456 lub napisz do nas na adres sales@itimpact.com.