W tym artykule omówiono niektóre mniej znane funkcje i ograniczenia optymalizatora zapytań oraz wyjaśniono przyczyny wyjątkowo słabej wydajności łączenia haszującego w konkretnym przypadku.
Przykładowe dane
Przykładowy skrypt tworzenia danych, który znajduje się poniżej, opiera się na istniejącej tabeli liczb. Jeśli jeszcze takiego nie masz, możesz użyć poniższego skryptu, aby go skutecznie utworzyć. Wynikowa tabela będzie zawierać pojedynczą kolumnę liczb całkowitych z liczbami od jednego do jednego miliona:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
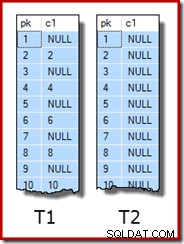
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Same przykładowe dane składają się z dwóch tabel, T1 i T2. Oba mają sekwencyjną kolumnę klucza podstawowego o nazwie pk i drugą kolumnę dopuszczającą wartość null o nazwie c1. Tabela T1 zawiera 600 000 wierszy, w których wiersze o numerach parzystych mają taką samą wartość dla c1 jak kolumna pk, a wiersze o numerach nieparzystych mają wartość NULL. Tabela c2 ma 32 000 wierszy, w których kolumna c1 ma wartość NULL w każdym wierszu. Poniższy skrypt tworzy i wypełnia te tabele:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Pierwsze dziesięć wierszy przykładowych danych w każdej tabeli wygląda tak:
Łączenie dwóch stołów
Ten pierwszy test polega na połączeniu dwóch tabel w kolumnie c1 (nie w kolumnie pk) i zwróceniu wartości pk z tabeli T1 dla wierszy, które łączą się:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Zapytanie faktycznie nie zwróci żadnych wierszy, ponieważ kolumna c1 ma wartość NULL we wszystkich wierszach tabeli T2, więc żadne wiersze nie mogą pasować do predykatu łączenia równości. Może to brzmieć dziwnie, ale jestem pewien, że opiera się na prawdziwym zapytaniu produkcyjnym (znacznie uproszczonym, aby ułatwić dyskusję).
Należy zauważyć, że ten pusty wynik nie zależy od ustawienia ANSI_NULLS, ponieważ kontroluje tylko sposób obsługi porównań z literałem lub zmienną o wartości null. W przypadku porównań kolumn predykat równości zawsze odrzuca wartości null.
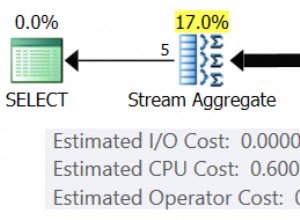
Plan wykonania tego prostego zapytania ze złączeniem ma kilka interesujących funkcji. Najpierw przyjrzymy się planowi przed wykonaniem („szacowanemu”) w SQL Sentry Plan Explorer:
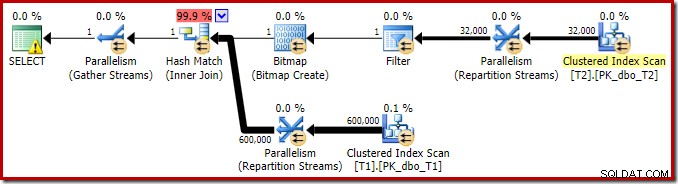
Ostrzeżenie na ikonie WYBIERZ tylko narzeka na brak indeksu w tabeli T1 dla kolumny c1 (z pk jako dołączoną kolumną). Sugestia indeksu jest tutaj nieistotna.
Pierwszym naprawdę interesującym elementem tego planu jest filtr:
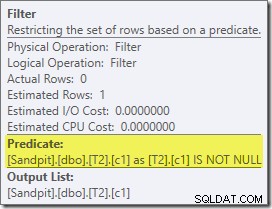
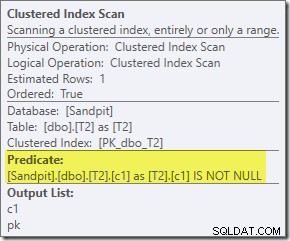
Ten predykat IS NOT NULL nie pojawia się w zapytaniu źródłowym, chociaż jest domniemany w predykacie sprzężenia, jak wspomniano wcześniej. Interesujące jest to, że został wydzielony jako jawny dodatkowy operator i umieszczony przed operacją łączenia. Zwróć uwagę, że nawet bez filtra zapytanie nadal dałoby poprawne wyniki – samo złączenie nadal odrzucałoby wartości null.
Filtr jest ciekawy również z innych powodów. Jego szacowany koszt wynosi dokładnie zero (mimo że oczekuje się, że będzie działać na 32 000 wierszy) i nie został przesunięty w dół do skanowania indeksu klastrowego jako predykat rezydualny. Optymalizator zwykle bardzo chętnie to robi.
Obie te rzeczy można wyjaśnić faktem, że ten filtr został wprowadzony w przepisaniu po optymalizacji. Po zakończeniu przez optymalizator zapytań przetwarzania opartego na kosztach brana jest pod uwagę stosunkowo niewielka liczba przepisywania planu stałego. Jeden z nich jest odpowiedzialny za wprowadzenie filtra.
Możemy zobaczyć wyniki wyboru planu opartego na kosztach (przed przepisaniem) za pomocą nieudokumentowanych flag śledzenia 8607 i znanego 3604, aby skierować tekstowe dane wyjściowe do konsoli (karta wiadomości w SSMS):
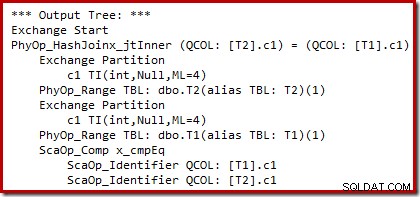
Drzewo wyjściowe pokazuje sprzężenie haszujące, dwa skany i niektóre operatory równoległości (wymiany). Nie ma filtra odrzucającego wartość NULL w kolumnie c1 tabeli T2.
Konkretne przepisanie po optymalizacji dotyczy wyłącznie danych wejściowych kompilacji sprzężenia mieszającego. W zależności od oceny sytuacji, może dodać jawny filtr, aby odrzucić wiersze, które mają wartość NULL w kluczu sprzężenia. Wpływ filtru na szacowaną liczbę wierszy jest również zapisywany w planie wykonania, ale ponieważ optymalizacja oparta na kosztach została już zakończona, koszt filtru nie jest obliczany. Jeśli nie jest to oczywiste, koszty obliczeniowe są stratą wysiłku, jeśli wszystkie decyzje oparte na kosztach zostały już podjęte.
Filtr pozostaje bezpośrednio w danych wejściowych kompilacji, a nie jest wypychany w dół do klastrowego skanowania indeksu, ponieważ główne działanie optymalizacyjne zostało zakończone. Przepisywanie po optymalizacji to skuteczne poprawki w ostatniej chwili do ukończonego planu wykonania.
Drugie i całkiem oddzielne przepisanie po optymalizacji jest odpowiedzialne za operator Bitmap w ostatecznym planie (możesz zauważyć, że brakowało go również w wyniku 8607):
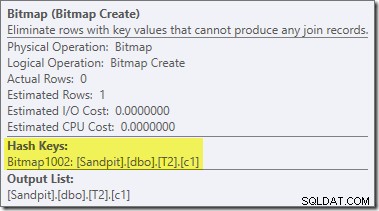
Ten operator ma również szacowany zerowy koszt zarówno we/wy, jak i procesora. Inną rzeczą, która identyfikuje go jako operatora wprowadzonego przez późną modyfikację (a nie podczas optymalizacji opartej na kosztach), jest to, że jego nazwa to Bitmap, po której następuje liczba. Istnieją inne rodzaje map bitowych wprowadzone podczas optymalizacji opartej na kosztach, jak zobaczymy nieco później.
Na razie ważną rzeczą w tej bitmapie jest to, że rejestruje ona wartości c1 widoczne podczas fazy budowania połączenia mieszającego. Ukończona bitmapa jest wypychana na stronę sondowania złączenia, gdy skrót przechodzi z fazy budowania do fazy sondowania. Mapa bitowa służy do wykonywania wczesnej redukcji częściowego łączenia, eliminując wiersze po stronie sondy, które nie mogą być połączone. jeśli potrzebujesz więcej informacji na ten temat, zobacz mój poprzedni artykuł na ten temat.
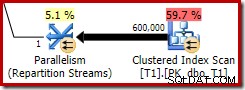
Drugi efekt mapy bitowej można zobaczyć na skanowaniu indeksu klastrowego po stronie sondy:
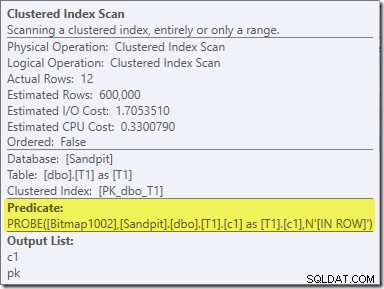
Powyższy zrzut ekranu pokazuje ukończoną bitmapę, która jest sprawdzana w ramach klastrowego skanowania indeksu w tabeli T1. Ponieważ kolumna źródłowa jest liczbą całkowitą (działałby również bigint), sprawdzanie mapy bitowej jest wypychane do końca do aparatu magazynu (co wskazuje kwalifikator „INROW”), a nie jest sprawdzane przez procesor zapytań. Bardziej ogólnie, mapa bitowa może być zastosowana do dowolnego operatora po stronie sondy, od wymiany w dół. Jak daleko procesor zapytań może przesunąć bitmapę, zależy od typu kolumny i wersji SQL Server.
Aby zakończyć analizę głównych cech tego planu wykonania, musimy spojrzeć na plan powykonawczy („rzeczywisty”):
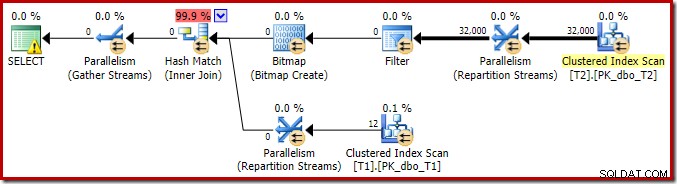
Pierwszą rzeczą, którą należy zauważyć, jest rozkład wierszy w wątkach między skanem T2 a wymianą strumieni repartycji bezpośrednio nad nim. Podczas jednego testu zobaczyłem następującą dystrybucję w systemie z czterema procesorami logicznymi:
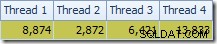
Rozkład nie jest szczególnie równomierny, jak to często bywa w przypadku skanowania równoległego na stosunkowo małej liczbie wierszy, ale przynajmniej wszystkie wątki otrzymały trochę pracy. Rozkład wątków między tą samą wymianą strumieni repartycji i filtrem jest bardzo różny:
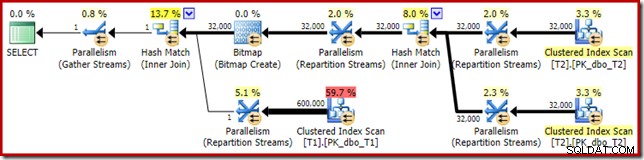
Pokazuje to, że wszystkie 32 000 wierszy z tabeli T2 zostało przetworzonych przez jeden wątek. Aby zobaczyć dlaczego, musimy spojrzeć na właściwości giełdy:

Ta wymiana, podobnie jak ta po stronie sondy łączenia mieszającego, musi zapewniać, że wiersze z tymi samymi wartościami klucza łączenia kończą się w tym samym wystąpieniu łączenia mieszającego. W DOP 4 istnieją cztery łączenia haszujące, każde z własną tabelą haszującą. Aby uzyskać poprawne wyniki, wiersze po stronie kompilacji i wiersze po stronie sondy z tymi samymi kluczami łączenia muszą dotrzeć do tego samego łączenia mieszającego; w przeciwnym razie możemy sprawdzić wiersz po stronie sondy z niewłaściwą tabelą mieszającą.
W planie równoległym w trybie wiersza SQL Server osiąga to poprzez ponowne partycjonowanie obu danych wejściowych przy użyciu tej samej funkcji skrótu w kolumnach sprzężenia. W tym przypadku sprzężenie znajduje się w kolumnie c1, więc dane wejściowe są rozdzielane na wątki przez zastosowanie funkcji mieszającej (typ partycjonowania:hash) do kolumny klucza sprzężenia (c1). Problem polega na tym, że kolumna c1 zawiera tylko jedną wartość – null – w tabeli T2, więc wszystkie 32 000 wierszy ma tę samą wartość skrótu, ponieważ wszystkie kończą się w tym samym wątku.
Dobrą wiadomością jest to, że nic z tego nie ma znaczenia dla tego zapytania. Filtr przepisywania po optymalizacji eliminuje wszystkie wiersze przed wykonaniem dużej ilości pracy. Na moim laptopie powyższe zapytanie jest wykonywane (zgodnie z oczekiwaniami bez wyników) w około 70 ms .
Łączenie trzech stołów
W drugim teście dodajemy dodatkowe sprzężenie z tabeli T2 do jej klucza głównego:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Nie zmienia to logicznych wyników zapytania, ale zmienia plan wykonania:
Zgodnie z oczekiwaniami, samosprzężenie tabeli T2 w jej kluczu podstawowym nie ma wpływu na liczbę wierszy, które kwalifikują się z tej tabeli:
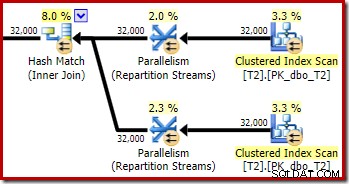
Rozkład rzędów w wątkach jest również dobry w tej sekcji planu. W przypadku skanowania jest podobny do poprzedniego, ponieważ skanowanie równoległe dystrybuuje wiersze do wątków na żądanie. Podział wymiany na podstawie skrótu klucza łączenia, którym tym razem jest kolumna pk. Biorąc pod uwagę zakres różnych wartości pk, wynikowy rozkład wątków jest również bardzo równomierny:
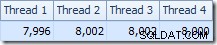
Wracając do bardziej interesującej części szacunkowego planu, istnieją pewne różnice w porównaniu z testem dwóch stołów:

Po raz kolejny wymiana po stronie kompilacji kończy się routingiem wszystkich wierszy do tego samego wątku, ponieważ c1 jest kluczem łączenia, a zatem kolumną partycjonowania dla wymian strumieni repartycji (pamiętaj, że c1 jest puste dla wszystkich wierszy w tabeli T2).
Istnieją dwie inne ważne różnice w tej części planu w porównaniu z poprzednim testem. Po pierwsze, nie ma filtra, który usuwałby wiersze o wartości null-c1 ze strony kompilacji sprzężenia mieszającego. Wyjaśnienie tego jest związane z drugą różnicą – Bitmapa uległa zmianie, chociaż nie jest to oczywiste na powyższym obrazku:
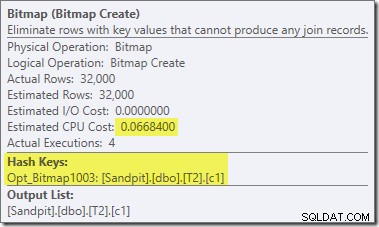
To jest Opt_Bitmap, a nie Bitmap. Różnica polega na tym, że ta bitmapa została wprowadzona podczas optymalizacji opartej na kosztach, a nie przez przepisanie w ostatniej chwili. Mechanizm, który uwzględnia zoptymalizowane mapy bitowe, jest powiązany z przetwarzaniem zapytań ze sprzężeniem gwiaździstym. Logika łączenia w gwiazdę wymaga co najmniej trzech połączonych tabel, więc wyjaśnia to, dlaczego zoptymalizowany bitmapa nie została uwzględniona w przykładzie łączenia dwóch tabel.
Ta zoptymalizowana mapa bitowa ma niezerowy szacowany koszt procesora i bezpośrednio wpływa na ogólny plan wybrany przez optymalizator. Jego wpływ na oszacowanie kardynalności po stronie sondy można zobaczyć w operatorze strumieni podziału:
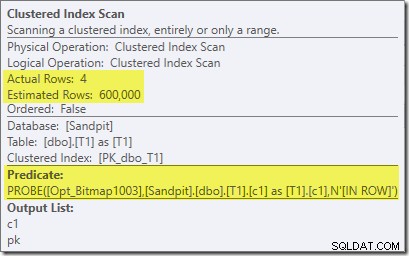
Zauważ, że efekt kardynalności jest widoczny podczas wymiany, mimo że bitmapa jest ostatecznie wpychana do silnika pamięci masowej („INROW”), tak jak widzieliśmy w pierwszym teście (ale zauważ teraz odniesienie do Opt_Bitmap):
Plan powykonawczy („rzeczywisty”) wygląda następująco:
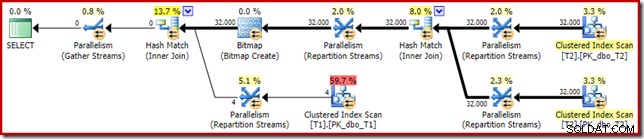
Przewidywana skuteczność zoptymalizowanej mapy bitowej oznacza, że oddzielne przepisywanie po optymalizacji dla filtra zerowego nie jest stosowane. Osobiście uważam, że jest to niefortunne, ponieważ wczesne wyeliminowanie wartości null za pomocą filtra neguje potrzebę budowania mapy bitowej, wypełniania tabel mieszających i wykonywania ulepszonego skanowania bitmapowego tabeli T1. Niemniej jednak optymalizator decyduje inaczej i po prostu nie ma z tym sprzeczności w tym przypadku.
Pomimo dodatkowego samodzielnego łączenia tabeli T2 i dodatkowej pracy związanej z brakującym filtrem, ten plan wykonania nadal daje oczekiwany wynik (bez wierszy) w krótkim czasie. Typowe wykonanie na moim laptopie zajmuje około 200 ms .
Zmiana typu danych
W tym trzecim teście zmienimy typ danych w kolumnie c1 w obu tabelach z liczb całkowitych na dziesiętne. W tym wyborze nie ma nic szczególnego; ten sam efekt można zaobserwować w przypadku dowolnego typu liczbowego, który nie jest liczbą całkowitą ani bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Ponowne użycie zapytania z trzema sprzężeniami:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Szacowany plan wykonania wygląda bardzo znajomo:
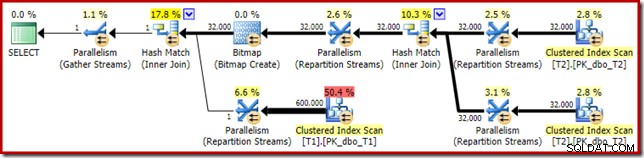
Pomijając fakt, że zoptymalizowana bitmapa nie może być już stosowana „INROW” przez silnik pamięci masowej ze względu na zmianę typu danych, plan wykonania jest zasadniczo identyczny. Poniższy zapis pokazuje zmianę we właściwościach skanowania:
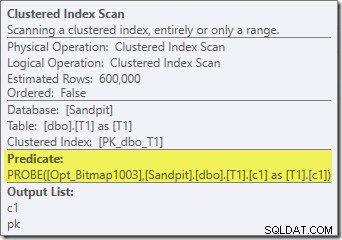
Niestety, wydajność jest dość dramatyczna. To zapytanie jest wykonywane nie za 70 lub 200 ms, ale za około 20 minut . W teście, który dał następujący plan wykonania, czas działania wynosił w rzeczywistości 22 minuty i 29 sekund:

Najbardziej oczywistą różnicą jest to, że skanowanie indeksu klastrowego w tabeli T1 zwraca 300 000 wierszy, nawet po zastosowaniu zoptymalizowanego filtru mapy bitowej. Ma to sens, ponieważ mapa bitowa jest zbudowana na wierszach zawierających tylko wartości null w kolumnie c1. Mapa bitowa usuwa wiersze inne niż null ze skanowania T1, pozostawiając tylko 300 000 wierszy z wartościami null dla c1. Pamiętaj, że połowa wierszy w T1 jest zerowa.
Mimo to wydaje się dziwne, że połączenie 32 000 wierszy z 300 000 wierszy powinno zająć ponad 20 minut. Na wypadek, gdybyś się zastanawiał, jeden rdzeń procesora został ustalony na 100% dla całego wykonania. Wyjaśnienie tej słabej wydajności i ekstremalnego wykorzystania zasobów opiera się na niektórych pomysłach, które zbadaliśmy wcześniej:
Wiemy już na przykład, że pomimo ikon wykonywania równoległego, wszystkie wiersze z T2 kończą w tym samym wątku. Przypominamy, że równoległe łączenie haszujące w trybie wiersza wymaga ponownego partycjonowania w kolumnach złączenia (c1). Wszystkie wiersze z T2 mają tę samą wartość – null – w kolumnie c1, więc wszystkie wiersze kończą się na tym samym wątku. Podobnie wszystkie wiersze z T1, które przechodzą przez filtr mapy bitowej, również mają wartość null w kolumnie c1, więc są również partycjonowane do tego samego wątku. To wyjaśnia, dlaczego jeden rdzeń wykonuje całą pracę.
Nadal może wydawać się nierozsądne, że hasz łączący 32 000 wierszy z 300 000 wierszami powinien zająć 20 minut, zwłaszcza że kolumny sprzężenia po obu stronach mają wartość zerową i i tak nie będą się łączyć. Aby to zrozumieć, musimy zastanowić się, jak działa to połączenie haszujące.
Dane wejściowe kompilacji (32 000 wierszy) tworzą tabelę mieszającą przy użyciu kolumny łączenia, c1. Ponieważ każdy wiersz po stronie kompilacji zawiera tę samą wartość (null) dla kolumny sprzężenia c1, oznacza to, że wszystkie 32 000 wierszy trafia do tego samego wiadra mieszającego. Gdy sprzężenie haszujące przełącza się na sondowanie pod kątem dopasowań, każdy wiersz po stronie sondy z kolumną o wartości null c1 również haszuje do tego samego zasobnika. Połączenie haszujące musi następnie sprawdzić wszystkie 32 000 wpisów w tym zasobniku pod kątem dopasowania.
Sprawdzenie 300 000 rzędów sondy daje 32 000 porównań wykonanych 300 000 razy. Jest to najgorszy przypadek łączenia haszującego:wszystkie rzędy boczne kompilacji mieszają się z tym samym wiadrem, co daje zasadniczo produkt kartezjański. Wyjaśnia to długi czas wykonania i stałe 100% wykorzystanie procesora, ponieważ skrót podąża za długim łańcuchem wiader skrótu.
Ta słaba wydajność pomaga wyjaśnić, dlaczego istnieje przepisywanie po optymalizacji w celu wyeliminowania wartości null w danych wejściowych kompilacji do łączenia mieszającego. Szkoda, że w tym przypadku filtr nie został zastosowany.
Obejścia
Optymalizator wybiera ten kształt planu, ponieważ błędnie szacuje, że zoptymalizowana mapa bitowa odfiltruje wszystkie wiersze z tabeli T1. Chociaż to oszacowanie jest wyświetlane w strumieniach podziału zamiast w skanowaniu indeksu klastrowego, nadal jest to podstawa decyzji. Przypominamy, że ponownie znajduje się odpowiednia sekcja planu przedegzekucyjnego:
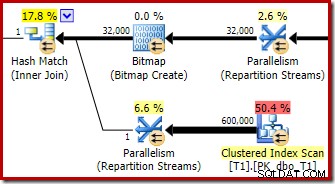
Gdyby to było prawidłowe oszacowanie, przetworzenie połączenia mieszającego nie zajęłoby w ogóle czasu. Szkoda, że oszacowanie selektywności dla zoptymalizowanej mapy bitowej jest tak bardzo błędne, gdy typ danych nie jest prostą liczbą całkowitą lub bigintem. Wygląda na to, że mapa bitowa zbudowana na kluczu całkowitym lub bigint jest również w stanie odfiltrować puste wiersze, które nie mogą się dołączyć. Jeśli tak jest w rzeczywistości, jest to główny powód, aby preferować kolumny łączenia liczb całkowitych lub bigint.
Poniższe rozwiązania są w dużej mierze oparte na pomyśle wyeliminowania problematycznych zoptymalizowanych bitmap.
Wykonywanie seryjne
Jednym ze sposobów zapobiegania braniu pod uwagę zoptymalizowanych bitmap jest wymaganie planu nierównoległego. Operatory map bitowych w trybie wiersza (zoptymalizowane lub inne) są widoczne tylko w planach równoległych:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); To zapytanie jest wyrażane przy użyciu nieco innej składni ze wskazówką FORCE ORDER w celu wygenerowania kształtu planu, który jest łatwiejszy do porównania z poprzednimi planami równoległymi. Podstawową funkcją jest wskazówka MAXDOP 1.
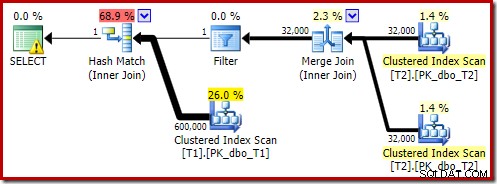
Ten szacunkowy plan pokazuje przywrócenie filtra przepisywania po optymalizacji:
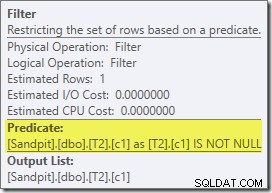
Wersja planu po wykonaniu pokazuje, że odfiltrowuje wszystkie wiersze z danych wejściowych kompilacji, co oznacza, że skanowanie po stronie sondy można całkowicie pominąć:
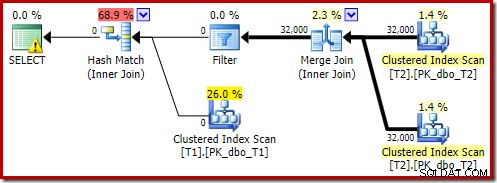
Jak można się spodziewać, ta wersja zapytania wykonuje się bardzo szybko – średnio około 20ms dla mnie. Podobny efekt możemy osiągnąć bez podpowiedzi FORCE ORDER i przepisywania zapytania:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
W tym przypadku optymalizator wybiera inny kształt planu, z filtrem umieszczonym bezpośrednio nad skanem T2:
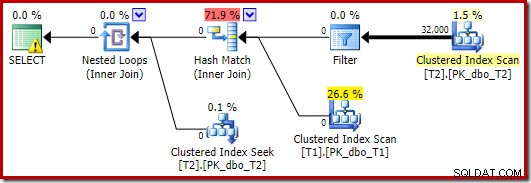
Działa to jeszcze szybciej – w około 10 ms – jak można by się spodziewać. Oczywiście nie byłby to dobry wybór, gdyby liczba obecnych (i możliwych do połączenia) wierszy była znacznie większa.
Wyłączanie zoptymalizowanych bitmap
Nie ma podpowiedzi do zapytania, aby wyłączyć zoptymalizowane mapy bitowe, ale możemy osiągnąć ten sam efekt, używając kilku nieudokumentowanych flag śledzenia. Jak zawsze, to tylko dla wartości procentowej; nigdy nie chciałbyś ich używać w prawdziwym systemie lub aplikacji:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Wynikowy plan wykonania to:
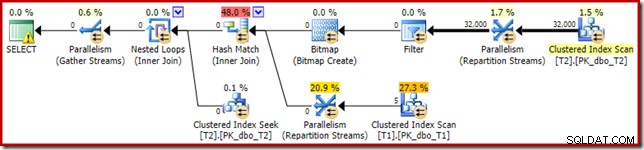
Bitmapa jest bitmapą przepisaną po optymalizacji, a nie zoptymalizowaną bitmapą:
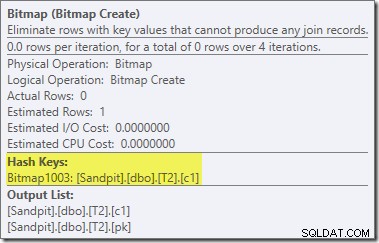
Zwróć uwagę na szacunkowe koszty zerowe i nazwę mapy bitowej (a nie Opt_Bitmap). bez zoptymalizowanej mapy bitowej w celu zniekształcenia oszacowań kosztów, przepisywanie po optymalizacji w celu uwzględnienia filtra odrzucającego wartość NULL jest aktywowane. Ten plan wykonania trwa około 70 ms .
Ten sam plan wykonania (z filtrem i niezoptymalizowaną mapą bitową) można również utworzyć, wyłączając regułę optymalizatora odpowiedzialną za generowanie planów bitmapowych łączenia gwiazd (ponownie, ściśle nieudokumentowane i nie do użytku w świecie rzeczywistym):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
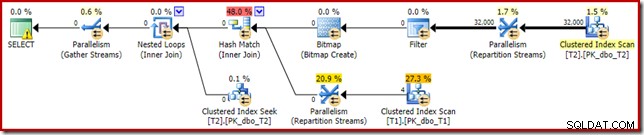
W tym wyraźny filtr
To najprostsza opcja, ale można by to zrobić tylko wtedy, gdy byłaby świadoma omówionych do tej pory kwestii. Teraz, gdy wiemy, że musimy wyeliminować wartości null z T2.c1, możemy dodać to bezpośrednio do zapytania:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Wynikowy szacunkowy plan wykonania może nie do końca odpowiada Twoim oczekiwaniom:
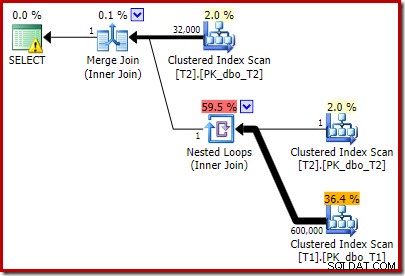
Dodany przez nas dodatkowy predykat został przeniesiony do środkowego klastrowego skanowania indeksu T2:
Plan powykonawczy to:
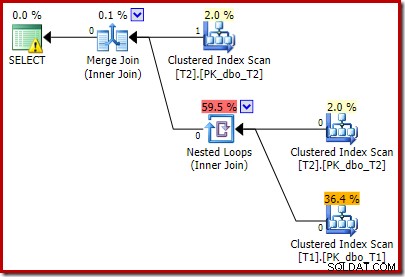
Zauważ, że Merge Join wyłącza się po odczytaniu jednego wiersza z jego górnych danych wejściowych, a następnie nie może znaleźć wiersza na niższych danych wejściowych, ze względu na efekt dodanego predykatu. Skanowanie indeksu klastrowego tabeli T1 nigdy nie jest w ogóle wykonywane, ponieważ sprzężenie zagnieżdżonych pętli nigdy nie otrzymuje wiersza na jego sterujących danych wejściowych. Ta końcowa forma zapytania zostanie wykonana w ciągu jednej lub dwóch milisekund.
Ostateczne przemyślenia
W tym artykule omówiono sporo podstaw, aby zbadać niektóre mniej znane zachowania optymalizatora zapytań i wyjaśnić przyczyny wyjątkowo słabej wydajności łączenia haszującego w konkretnym przypadku.
Kuszące może być pytanie, dlaczego optymalizator nie dodaje rutynowo filtrów odrzucających wartość NULL przed złączeniami równości. Można jedynie przypuszczać, że nie byłoby to korzystne w dość powszechnych przypadkach. Nie oczekuje się, że większość złączeń napotka wiele odrzuceń wartości null =null, a rutynowe dodawanie predykatów może szybko przynieść efekt przeciwny do zamierzonego, szczególnie w przypadku obecności wielu kolumn złączeń. W przypadku większości złączeń odrzucanie wartości null wewnątrz operatora złączenia jest prawdopodobnie lepszą opcją (z perspektywy modelu kosztów) niż wprowadzenie jawnego filtra.
Wygląda na to, że podejmuje się wysiłki, aby zapobiec wystąpieniu najgorszych przypadków poprzez przepisanie po optymalizacji zaprojektowane w celu odrzucenia wierszy sprzężenia zerowego, zanim dotrą one do danych wejściowych kompilacji sprzężenia mieszającego. Wydaje się, że istnieje niefortunna interakcja między efektem zoptymalizowanych filtrów bitmapowych a zastosowaniem tego przepisania. Niefortunne jest również to, że gdy ten problem z wydajnością wystąpi, bardzo trudno jest zdiagnozować go na podstawie samego planu wykonania.
Na razie najlepszą opcją wydaje się być świadomy tego potencjalnego problemu z wydajnością z łączeniami mieszającymi w kolumnach dopuszczających wartość null i dodanie jawnych predykatów odrzucających wartość null (z komentarzem!), aby w razie potrzeby zapewnić wydajny plan wykonania. Użycie podpowiedzi MAXDOP 1 może również ujawnić alternatywny plan z widocznym filtrem ostrzegawczym.
Zgodnie z ogólną zasadą, zapytania, które łączą się w kolumnach typu liczb całkowitych i szukają istniejących danych, zazwyczaj lepiej pasują do modelu optymalizatora i możliwości silnika wykonawczego niż alternatywy.
Podziękowania
Chciałbym podziękować SQL_Sasquatch (@sqL_handLe) za zgodę na udzielenie odpowiedzi na jego oryginalny artykuł analizą techniczną. Przykładowe dane użyte tutaj są w dużej mierze oparte na tym artykule.
Chciałbym również podziękować Robowi Farleyowi (blog | twitter) za nasze dyskusje techniczne na przestrzeni lat, a zwłaszcza jedną ze stycznia 2015 roku, w której omawialiśmy implikacje dodatkowych predykatów odrzucających wartości null dla złączeń ekwiwalentnych. Rob kilkakrotnie pisał o powiązanych tematach, w tym w odwrotnych predykatach – spójrz w obie strony, zanim przejdziesz.