To czwarta i ostatnia część serii Benchmarking Managed PostgreSQLCloud Solutions . W chwili pisania tego tekstu Microsoft Azure PostgreSQL był w wersji 10.7, nowszej niż dwaj rywale:Amazon Aurora PostgreSQL w wersji 10.6 i Google Cloud SQL dla PostgreSQL w wersji 9.6.
Microsoft zdecydował się uruchomić Azure PostgreSQL w systemie Windows:
postgres=> select version();
version
------------------------------------------------------------
PostgreSQL 10.7, compiled by Visual C++ build 1800, 64-bit
(1 row)W przypadku tego konkretnego testu, który nie wyszedł zbyt dobrze i zaryzykuję zgadnięcie, że Microsoft doskonale zdaje sobie sprawę z ograniczeń, dlatego pod parasolem PostgreSQL oferuje również wersję zapoznawczą PostgreSQL w wersji Citus Data. Podejście to wygląda podobnie do smaków AWS PostgreSQL, RDS i odpowiednio Aurory.
Na marginesie, podczas konfigurowania konta Azure byłem zaskoczony brakiem uwierzytelniania 2FA/MFA (dwuczynnikowego/wieloczynnikowego), które uznałem za przyznane dzięki AWS Virtual MFA firmy Amazon i dwuetapowej weryfikacji Google. Microsoft oferuje usługę MFA tylko klientom korporacyjnym subskrybującym Active Directory lub Office 365. Ponieważ Citus Cloud wymusza 2FA dla produkcyjnej bazy danych, być może Microsoft nie jest tak daleko od wdrożenia go na platformie Azure.
TL;DR
Brak wyników dla platformy Azure. Na 8-rdzeniowej instancji bazy danych, identycznej pod względem liczby rdzeni jak na AWS i G Cloud, testy nie zakończyły się z powodu błędów bazy danych. Na 16-rdzeniowej instancji pgbench się zakończył, a sysbench doszedł do stworzenia pierwszych 3 tabel, w którym to momencie przerwałem proces. Chociaż byłem gotów poświęcić rozsądną ilość wysiłku, czasu i pieniędzy na wykonanie testów oraz udokumentowanie błędów i ich przyczyn, celem tego ćwiczenia było wykonanie testu porównawczego, dlatego nigdy nie zastanawiałem się nad rozwiązywaniem zaawansowanych problemów lub kontaktem Obsługa platformy Azure, ani nie ukończyłem testu sysbench na 16-rdzeniowej bazie danych.
Instancje w chmurze
Klient
Najbliżej instancji AWS wybranej na początku tej serii blogów instancja klienta platformy Azure była instancją E32s v3 o następujących specyfikacjach:
- procesor wirtualny:32 (16 rdzeni x 2 wątki/rdzeń)
- RAM:256 GiB
- Pamięć:Azure Premium SSD
- Sieć:przyspieszona sieć do 30 Gb/s
Oto zrzut ekranu portalu ze szczegółami instancji:
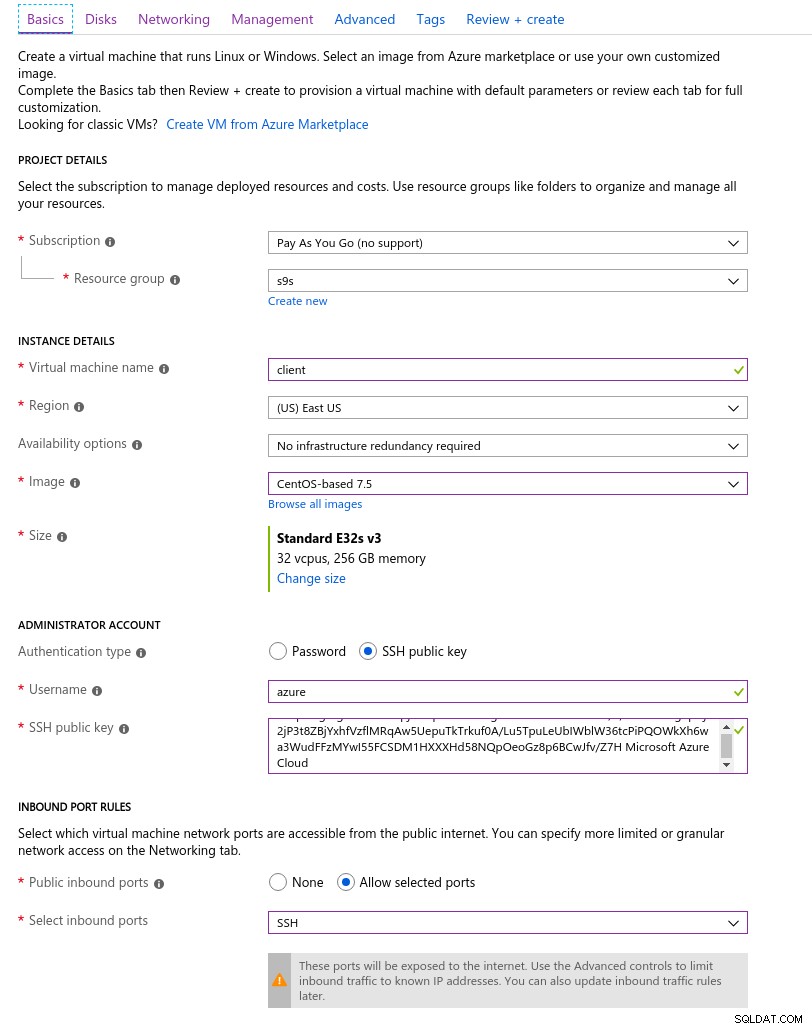 Szczegóły instancji klienta
Szczegóły instancji klienta Przyspieszona sieć jest domyślnie włączona po wybraniu dowolnej z obsługiwanych maszyn wirtualnych:
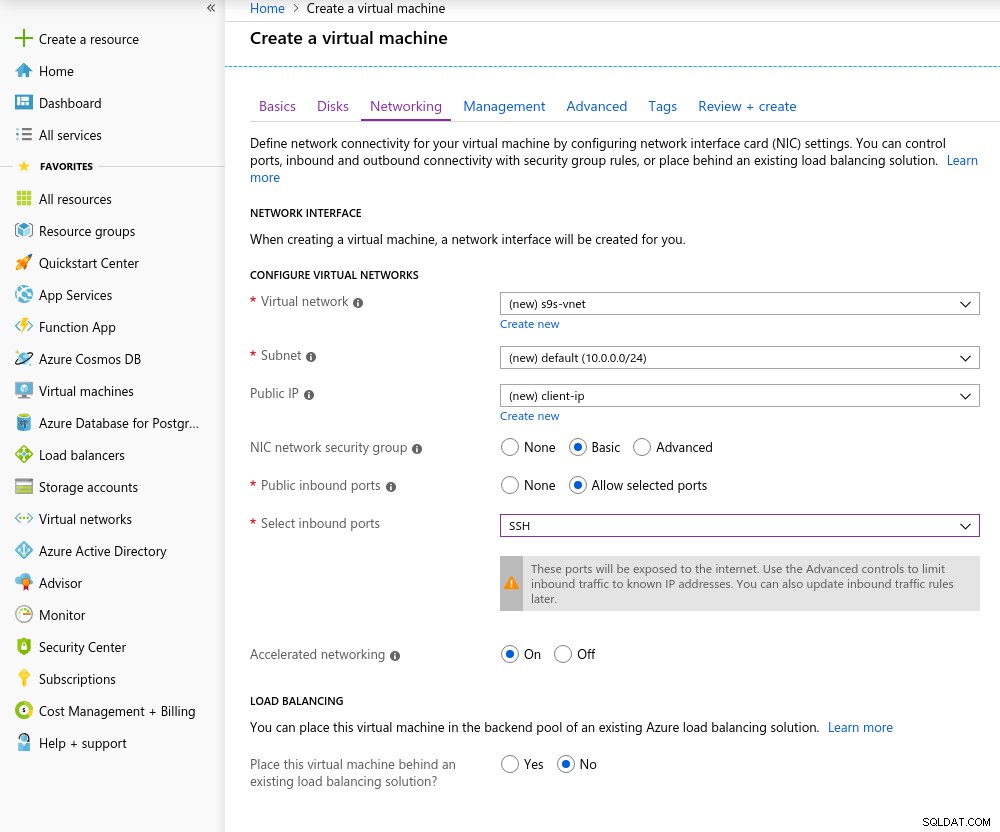 Przyspieszona sieć włączona
Przyspieszona sieć włączona Ponieważ jest to reguła w chmurze, aby osiągnąć najlepszą wydajność sieci, klient i serwer muszą znajdować się w tej samej strefie dostępności, co zrobiłem, konfigurując środowisko we wschodnim regionie AZ.
Podobnie jak w przypadku Google Cloud, należy zażądać zwiększenia limitu dla instancji z więcej niż 10 rdzeniami. Microsoft uczynił to naprawdę łatwym. Po przejściu na płatne konto otrzymałem potwierdzenie zatwierdzenia, zanim mogłem dokończyć odpowiedź w bilecie wyjaśniającą, dlaczego proszę o podwyżkę.
Baza danych
Wybierając rozmiar instancji, próbowałem dopasować specyfikacje instancji używanych w AWS i Google Cloud:
- procesor wirtualny:8
- RAM:80 GiB (maksymalnie)
- Pamięć:6000 IOPS (rozmiar 2TiB przy 3 IOPS/GB)
- Sieć:2000 MB/s
Niski rozmiar pamięci wynika z formuły pamięci na rdzeń wirtualny używanej do alokacji pamięci:
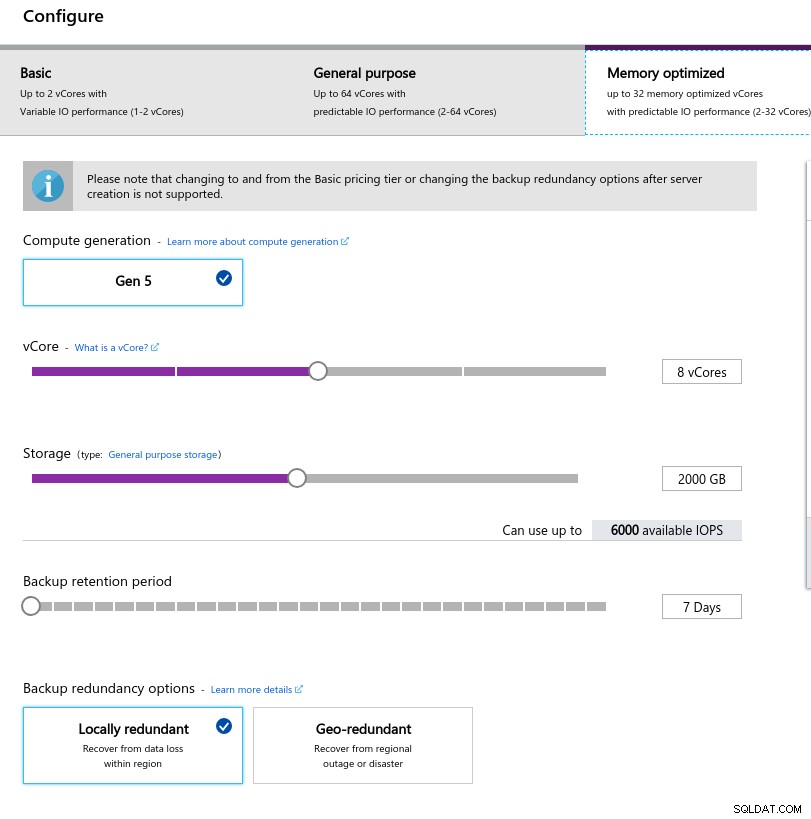 Konfiguracja instancji bazy danych
Konfiguracja instancji bazy danych Podobnie jak w Google Cloud, i w przeciwieństwie do AWS, im większa pamięć masowa, tym wyższy IOPS, przy wzroście stosunku 3:1, jednak gdy rozmiar osiągnie 2TiB, IOPS jest ograniczony do 6000 IOPS.
Wykonywanie testów
Konfiguracja
Konfiguracja przebiegała zgodnie z procesem opisanym w poprzednich częściach serii blogów, z poprawką taktowania AWS pgbench dla 11.1 mającą zastosowanie do Azure PostgreSQL w wersji 10.7. Poprawki można również uzyskać z wkładów AWS Labs do repozytorium PostgreSQL Github.
W trakcie przeprowadzania testów wykorzystałem poniższy skrypt, który jest zgodny z przewodnikiem Amazon i w tym przypadku jest dostosowany do wersji PostgreSQL na platformie Azure (10.7). Na komputerze klienckim działa CentOS 7.5:
#!/bin/bash
set -eE
trap "exit 1" ERR
yum -y install \
wget ant git php gnuplot gcc make readline-devel zlib-devel \
postgresql-jdbc bzr automake libtool patch libevent-devel \
openssl-devel ncurses-devel
wget https://ftp.postgresql.org/pub/source/v10.7/postgresql-10.7.tar.gz
rm -rf postgresql-10.7
tar -xzf postgresql-10.7.tar.gz
cd postgresql-10.7
wget https://s3.amazonaws.com/aurora-pgbench-patches/pgbench-init-timing.patch
patch --verbose -p1 -b < pgbench-init-timing.patch
./configure
make -j 4 all
make install
cd ..
rm -rf sysbench
git clone -b 0.5 https://github.com/akopytov/sysbench.git
cd sysbench
./autogen.sh
CFLAGS="-L/usr/local/pgsql/lib/ -I /usr/local/pgsql/include/" \
| ./configure \
--with-pgsql \
--without-mysql \
--with-pgsql-includes=/usr/local/pgsql/include/ \
--with-pgsql-libs=/usr/local/pgsql/lib/
make
make install
cd sysbench/tests
make install
sed -i \
'/^export PGHOST=/,/^export LD_LIBRARY_PATH.*pgsql/d' \
~/.bashrc
cat << "__eot__" >> ~/.bashrc
export PGHOST=CHANGEME
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=/usr/local/pgsql/bin:/usr/local/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
__eot__
echo "All done."Po zakończeniu skryptu edytuj .bashrc, aby ustawić zmienne środowiskowe PostgreSQL. Platforma Azure wyróżnia się formatem nazwy użytkownika PostgreSQL, ponieważ oczekuje formatu {nazwa użytkownika}@{host} zamiast wszechobecnego {nazwa użytkownika}:
[example@sqldat.com scripts]# psql
psql: FATAL: Invalid Username specified. Please check the Username and retry connection. The Username should be in <example@sqldat.com> format.Przed rozpoczęciem testów sprawdź, czy używamy właściwej wersji narzędzi klienta:
[example@sqldat.com scripts]# psql --version
psql (PostgreSQL) 10.7[example@sqldat.com scripts]# pgbench --version
pgbench (PostgreSQL) 10.7[example@sqldat.com scripts]# sysbench --version
sysbench 0.5pgench
Zainicjuj bazę danych pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…i kilka minut później:
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.04 s, remaining 426.44 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 427.22 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.18 s, remaining 600.63 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 530.99 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.30 s, remaining 595.12 s)
...
584300000 of 1000000000 tuples (58%) done (elapsed 2421.82 s, remaining 1723.01 s)
584400000 of 1000000000 tuples (58%) done (elapsed 2421.86 s, remaining 1722.32 s)
584500000 of 1000000000 tuples (58%) done (elapsed 2422.81 s, remaining 1722.29 s)
584600000 of 1000000000 tuples (58%) done (elapsed 2422.84 s, remaining 1721.60 s)
584700000 of 1000000000 tuples (58%) done (elapsed 2422.88 s, remaining 1720.92 s)
584800000 of 1000000000 tuples (58%) done (elapsed 2425.06 s, remaining 1721.76 s)
584900000 of 1000000000 tuples (58%) done (elapsed 2425.09 s, remaining 1721.07 s)
585000000 of 1000000000 tuples (58%) done (elapsed 2425.28 s, remaining 1720.50 s)
...
999700000 of 1000000000 tuples (99%) done (elapsed 4142.69 s, remaining 1.24 s)
999800000 of 1000000000 tuples (99%) done (elapsed 4142.95 s, remaining 0.83 s)
999900000 of 1000000000 tuples (99%) done (elapsed 4142.98 s, remaining 0.41 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 4143.92 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 14805.73 s (insert 4146.94 s, commit 0.02 s, vacuum 6581.15 s, index 4077.61 s)
done.Jak dotąd tak dobrze.
Szybkie spojrzenie na bazę danych, aby potwierdzić, że jest gotowa do pracy:
example@sqldat.com:5432 postgres> \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Table space | Description
-------------------+-----------------+----------+----------------------------+----------------------------+-------------------------------------+-----------+------------+--------------------------------------------
azure_maintenance | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | azure_superuser=CTc/azure_superuser | No Access | pg_default |
azure_sys | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 12 MB | pg_default |
postgres | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 160 GB | pg_default | default administrative connection database
template0 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | unmodifiable empty database
| | | | | azure_superuser=CTc/azure_superuser | | |
template1 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | default template for new databases
| | | | | azure_superuser=CTc/azure_superuser | | |
(5 rows)Ponieważ Azure nie pozwala na zmianę max_connections i biorąc pod uwagę, że dla wybranej instancji limit jest ograniczony do 960, będziemy musieli odpowiednio dostosować liczbę klientów pgbench:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not known
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not knownI oto jest pierwsza czkawka.
Szybkie sprawdzenie rozdzielczości DNS hosta nie wykazuje żadnych problemów:
[example@sqldat.com scripts]# dig +short $PGHOST
cr1.eastus1-a.control.database.windows.net.
191.238.6.43[example@sqldat.com scripts]# cat /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
search 11jv1qvdjs5utlhtlyb5vdyeth.bx.internal.cloudapp.net
nameserver 168.63.129.16Przegląd mojego screenloga pokazuje, że prawie połowa połączeń została zakończona:
~$ cat screenlog.1 | nl | grep 'could not translate host name "postgresql-10-7.*Name or service not known' | wc -l
469pg_stat_activity opowiada bardziej szczegółową historię — mamy wzrost do 950 połączeń:
example@sqldat.com:5432 postgres> select now(), count(*) from pg_stat_activity where usename = 'postgres' and application_name = 'pgbench'; now | count
-------------------------------+-------
2019-05-03 23:39:18.200291+00 | 950
(1 row)…jednak monitorowanie powyższego zapytania pokazuje nagły spadek liczby połączeń z 950 do 628 w ciągu zaledwie 10 sekund:
example@sqldat.com:5432 postgres> \watch 10
Fri 03 May 2019 11:41:05 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:41:05.044025+00 | 950
(1 row)
...
Fri 03 May 2019 11:43:10 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:10.512766+00 | 950
(1 row)
Fri 03 May 2019 11:43:20 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:17.419011+00 | 628
(1 row)
Fri 03 May 2019 11:43:30 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:31.434638+00 | 613
(1 row)Aby obejść problem z DNS, przypisałem PGHOST adres IP hosta:
[example@sqldat.com scripts]# set | grep PG
PGDATABASE=postgres
PGHOST=191.238.6.43
example@sqldat.com
PGPORT=5432
example@sqldat.comMając to obejście, ponownie uruchomiłem test:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
progress: 61.1 s, 457.7 tps, lat 559.138 ms stddev 1755.888
progress: 120.1 s, 78.8 tps, lat 3883.772 ms stddev 10551.545
progress: 180.1 s, 17.6 tps, lat 50831.708 ms stddev 31214.512
progress: 240.1 s, 15.2 tps, lat 42474.763 ms stddev 32702.050
progress: 300.1 s, 16.1 tps, lat 43584.559 ms stddev 29818.142
progress: 360.1 s, 26.5 tps, lat 36914.096 ms stddev 37152.588
progress: 420.0 s, 33.4 tps, lat 27542.926 ms stddev 37075.457
progress: 480.0 s, 20.2 tps, lat 47149.060 ms stddev 47087.474
progress: 540.0 s, 13.5 tps, lat 55609.260 ms stddev 60394.287
progress: 600.0 s, 36.5 tps, lat 49566.853 ms stddev 99155.598
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 950
number of threads: 950
duration: 600 s
number of transactions actually processed: 44293
latency average = 12493.888 ms
latency stddev = 40490.231 ms
tps = 60.907130 (including connections establishing)
tps = 64.213520 (excluding connections establishing)Na pierwszy rzut oka wydawało się, że wszystko poszło dobrze, jednak niezwykle wysokie wartości opóźnień w połączeniu z wcześniejszymi problemami z DNS i klientem obsługującym „przyspieszoną sieć” sugerują, że coś jest nie tak na poziomie sieci i jest to prawdopodobne przyczyną niskich wyników tps. Ale najgorsze dopiero nadejdzie.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentstół systemowy
Najpierw utwórz tabele:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepare
After a little while:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
FATAL: PQexec() failed: 7 server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: CREATE TABLE sbtest1 (
id SERIAL NOT NULL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
)
FATAL: failed to execute function `prepare': 3To nie wyglądało dobrze, więc sprawdziłem logi PostgreSQL:
2019-05-03 23:51:12 UTC-5ccbbe4f.88-WARNING: worker took too long to start; canceled
2019-05-03 23:51:14 UTC-5ccbbe4f.84-PANIC: could not write to log file 000000010000001F000000CD at offset 13664256, length 8192: Invalid argument
+++ NT HARD ERROR (0xd0000144) +++
Parameter 0: 0xffffffffc0000005
Parameter 1: 0x1b80f0f73b
Parameter 2: 0x1
Parameter 3: 0x0Chociaż usługa powinna sama się zregenerować, zdecydowałem się zrestartować instancję, aby przyspieszyć proces.
2019-05-04 00:43:23 UTC-5ccce02a.2c-HINT: Is another postmaster already running on port 20108? If not, wait a few seconds and retry.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: listening on IPv4 address "0.0.0.0", port 20108
2019-05-04 00:43:24 UTC-5ccce02a.2c-LOG: database system is ready to accept connections
...
2019-05-05 00:03:35 UTC-5cce2856.2c-HINT: Is another postmaster already running on port 20326? If not, wait a few seconds and retry.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: listening on IPv4 address "0.0.0.0", port 20326
2019-05-05 00:03:38 UTC-5cce285a.3c-FATAL: the database system is starting up
2019-05-05 00:03:38 UTC-5cce285a.3c-LOG: connection received: host=127.0.0.1 port=47247 pid=60
2019-05-05 00:03:49 UTC-5cce2865.40-FATAL: the database system is starting up
2019-05-05 00:03:49 UTC-5cce2865.40-LOG: connection received: host=127.0.0.1 port=47284 pid=64
2019-05-05 00:03:59 UTC-5cce286f.44-FATAL: the database system is starting up
2019-05-05 00:03:59 UTC-5cce286f.44-LOG: connection received: host=127.0.0.1 port=47312 pid=68
2019-05-05 00:04:00 UTC-5cce2856.2c-LOG: database system is ready to accept connections
2019-05-05 00:04:00 UTC-5cce2870.38-LOG: database system was shut down at 2019-05-05 00:03:34 UTCW tym momencie włączyłem również wgląd w wydajność zapytań:
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pgms_wait_sampling.query_capture_mode" changed to "ALL"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pg_qs.query_capture_mode" changed to "TOP"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce287a.6c-ERROR: database "azure_sys" already exists
2019-05-05 00:04:13 UTC-5cce287a.6c-STATEMENT: CREATE DATABASE azure_sys TEMPLATE template0Przed ponownym uruchomieniem zadania sysbench chciałem się upewnić, że baza danych jest zdrowa, dlatego uruchomiłem drugi test pgbench:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.Według monitora zapytań pg_stat_activity, serwer zgasł, gdy liczba połączeń osiągnęła 710:
example@sqldat.com:5432 postgres> \watch 1
Sun 05 May 2019 12:44:11 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:11.010413+00 | 220
(1 row)
Sun 05 May 2019 12:44:12 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:12.041667+00 | 231
(1 row)
...
now | count
------------------------------+-------
2019-05-05 00:47:33.16533+00 | 710
(1 row)
Sun 05 May 2019 12:47:40 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:47:40.524662+00 | 710
(1 row)A z logów PostgreSQL dowiadujemy się, że coś wydarzyło się w rurze łączącej:
2019-05-05 00:44:11 UTC-5cce31da.c60-LOG: connection received: host=40.114.85.62 port=50925 pid=3168
2019-05-05 00:44:11 UTC-5cce31db.c58-LOG: connection received: host=40.114.85.62 port=55256 pid=3160
2019-05-05 00:44:11 UTC-5cce31db.c5c-LOG: connection received: host=40.114.85.62 port=34526 pid=3164
2019-05-05 00:44:11 UTC-5cce31db.c64-LOG: connection received: host=40.114.85.62 port=1178 pid=3172
...
2019-05-05 00:47:32 UTC-5cce329a.146c-LOG: connection received: host=40.114.85.62 port=41769 pid=5228
2019-05-05 00:47:33 UTC-5cce3287.1404-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3288.1428-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3289.1434-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3291.1448-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce32a3.1484-LOG: connection received: host=40.114.85.62 port=50296 pid=5252
2019-05-05 00:47:33 UTC-5cce32a5.1488-LOG: connection received: host=40.114.85.62 port=28304 pid=5256
2019-05-05 00:47:39 UTC-5cce31d2.a24-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31d5.ae8-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e3.ee4-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e9.1054-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce3291.1444-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:40 UTC-5cce31cd.8ec-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.W obliczu ograniczeń w max_connections i problemów napotkanych podczas testów pgbench i sysbench, zacząłem się interesować, czy 16-rdzeniowa baza danych będzie zachowywać się tak samo.
16-rdzeniowa instancja bazy danych
W przypadku 16-rdzeniowej instancji bazy danych limit max_connections jest wystarczająco duży, aby pomieścić 1000 klientów:
example@sqldat.com:5432 postgres> show max_connections ;
max_connections
-----------------
1900
(1 row)To pozwoliło mi uruchomić te same polecenia testowe, których używałem u poprzednich dostawców chmury.
Test porównawczy zakończył się pomyślnie, a wyniki są pokazane poniżej:
pgbench
- Inicjalizacja:
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.08 s, remaining 807.39 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 628.37 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.16 s, remaining 527.89 s) ... 600100000 of 1000000000 tuples (60%) done (elapsed 2499.90 s, remaining 1665.90 s) 600200000 of 1000000000 tuples (60%) done (elapsed 2500.07 s, remaining 1665.33 s) ... 999900000 of 1000000000 tuples (99%) done (elapsed 4170.91 s, remaining 0.42 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 4171.29 s, remaining 0.00 s) vacuum... set primary keys... total time: 13701.50 s (insert 4173.33 s, commit 0.05 s, vacuum 7098.74 s, index 2429.39 s) done. - Uruchom:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048 starting vacuum...end. progress: 81.4 s, 5639.1 tps, lat 80.094 ms stddev 73.213 progress: 120.0 s, 4091.0 tps, lat 224.161 ms stddev 608.523 progress: 180.0 s, 6932.1 tps, lat 145.143 ms stddev 228.925 progress: 240.0 s, 7287.9 tps, lat 136.521 ms stddev 156.643 progress: 300.0 s, 7567.8 tps, lat 132.722 ms stddev 158.754 progress: 360.0 s, 8077.9 tps, lat 123.801 ms stddev 139.033 progress: 420.0 s, 6076.9 tps, lat 163.886 ms stddev 201.121 progress: 480.0 s, 5376.2 tps, lat 186.678 ms stddev 191.270 progress: 540.0 s, 4864.0 tps, lat 205.696 ms stddev 164.261 progress: 600.0 s, 3759.3 tps, lat 266.073 ms stddev 542.717 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 3614386 latency average = 152.935 ms latency stddev = 248.593 ms tps = 6002.082008 (including connections establishing) tps = 6513.306467 (excluding connections establishing)
Poszło całkiem dobrze, jednak nie ma prawidłowego sposobu porównania tych wyników z wynikami AWS i G Cloud, ponieważ nie testujemy na podobnej platformie. Ale to wystarczy, aby przejść do następnego punktu.
stół systemowy
Ponieważ testy pgbench zakończyły się pomyślnie, zdecydowałem się w pełni wykorzystać kredyt w wysokości 200 USD na platformę Azure i potwierdzić, że sysbench jest dalej niż poprzednie uruchomienie na 8-rdzeniowej instancji:
sysbench \
--test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=191.238.6.43 \
--pgsql-db=postgres \
example@sqldat.com \
example@sqldat.com \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 prepare
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
Creating secondary indexes on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 450000 records into 'sbtest3'
Creating secondary indexes on 'sbtest3'...
Creating table 'sbtest4'...Wyglądało na to, że wszystko działa dobrze, a ponieważ zbliżałem się do mojego budżetu, postanowiłem przerwać to zadanie.
Hiperskala (Citus)
Chociaż nie jest gotowa do produkcji, ta opcja zasługuje na przyjrzenie się, ponieważ zapewnia zaawansowane funkcje niedostępne w AWS i G Cloud.
W wyniku przejęcia Citus Data Microsoft oferuje wersję zapoznawczą swojego flagowego produktu PostgreSQL pod nazwą Hyperscale (Citus).
Kreator portalu sprawia, że konfiguracja skomplikowanego środowiska jest bardzo prosta:
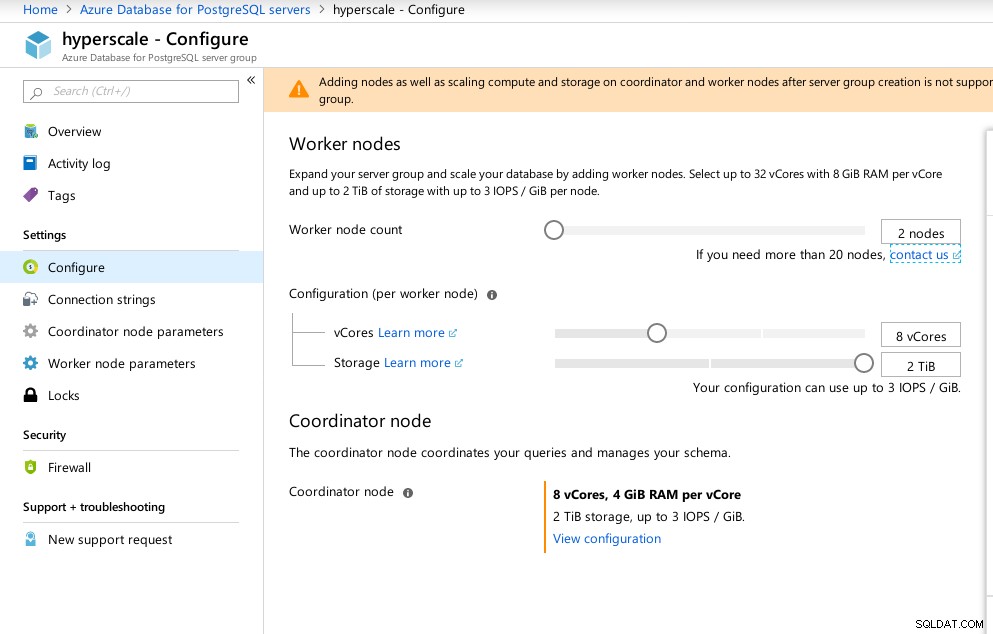 Konfiguracja Azure Hyperscale (Citus)
Konfiguracja Azure Hyperscale (Citus) Zauważyłem, że w przeciwieństwie do Azure PostgreSQL, który działa w systemie Windows, Hyperscale działa w systemie Linux:
example@sqldat.com:5432 citus> select version();
version
----------------------------------------------------------------------------------------------------------------
PostgreSQL 11.2 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609, 64-bit
(1 row)Niestety, podczas gdy Hyperscale obiecywał ekscytującą podróż, w tym czasie nie mogłem rozpocząć testów, ponieważ max_connections jest obecnie ograniczony do 300, bez opcji dostosowania, chociaż zdolność jest udokumentowana dla natywnego Citus PosgreSQL:
example@sqldat.com:5432 citus> show max_connections ;
max_connections
-----------------
300
(1 row)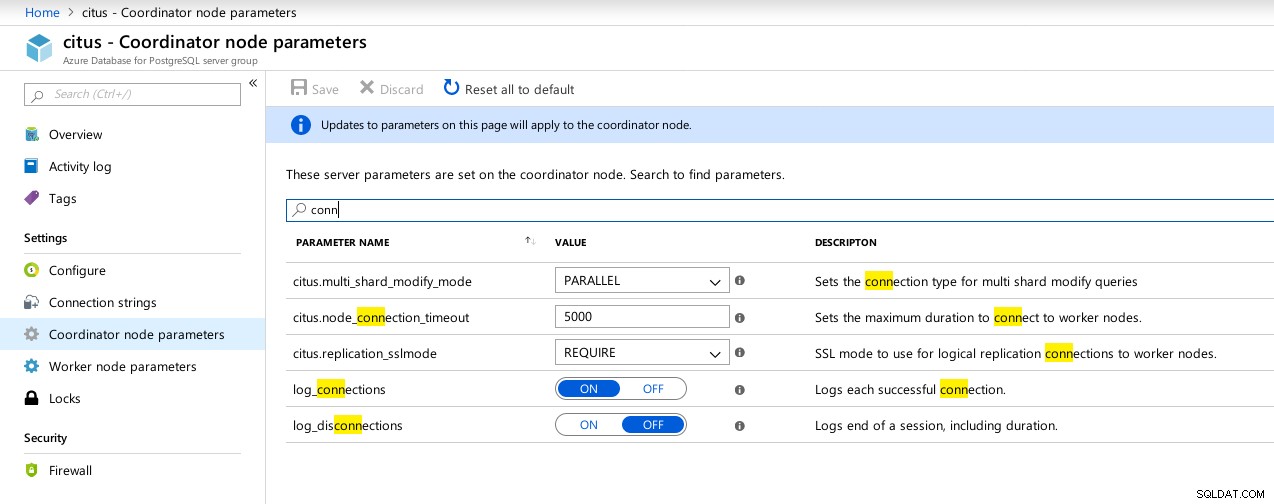 Dostępne parametry połączeń Hyperscale (Citus) Coordinator
Dostępne parametry połączeń Hyperscale (Citus) Coordinator 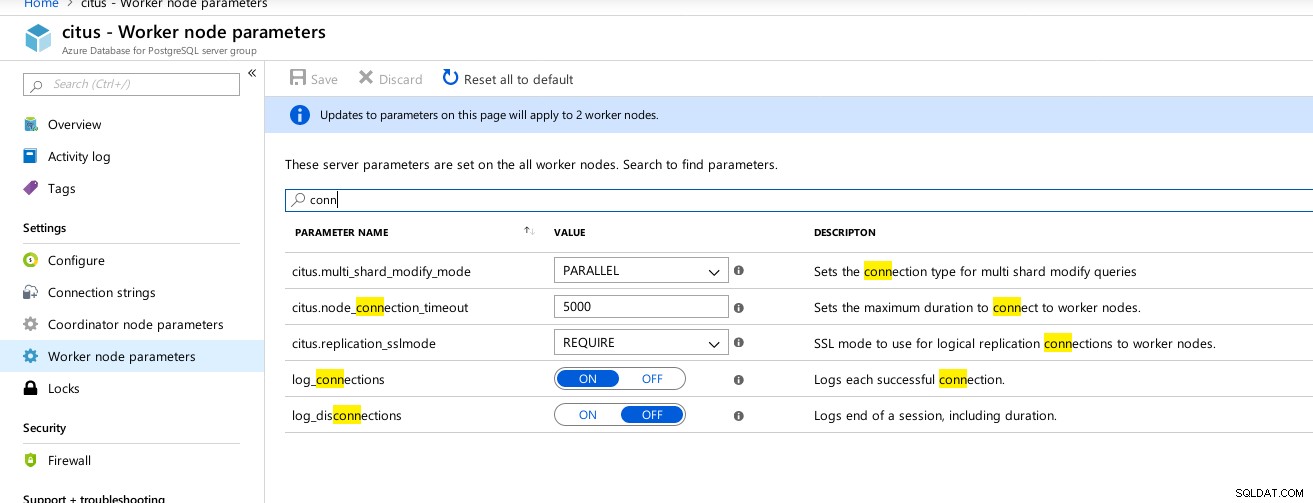 Hiperscale (Citus) Workers:max_connections niedostępne
Hiperscale (Citus) Workers:max_connections niedostępne Dane porównawcze
Kilka wskaźników wskazujących na wydajność klienta i serwera oraz zachowanie:
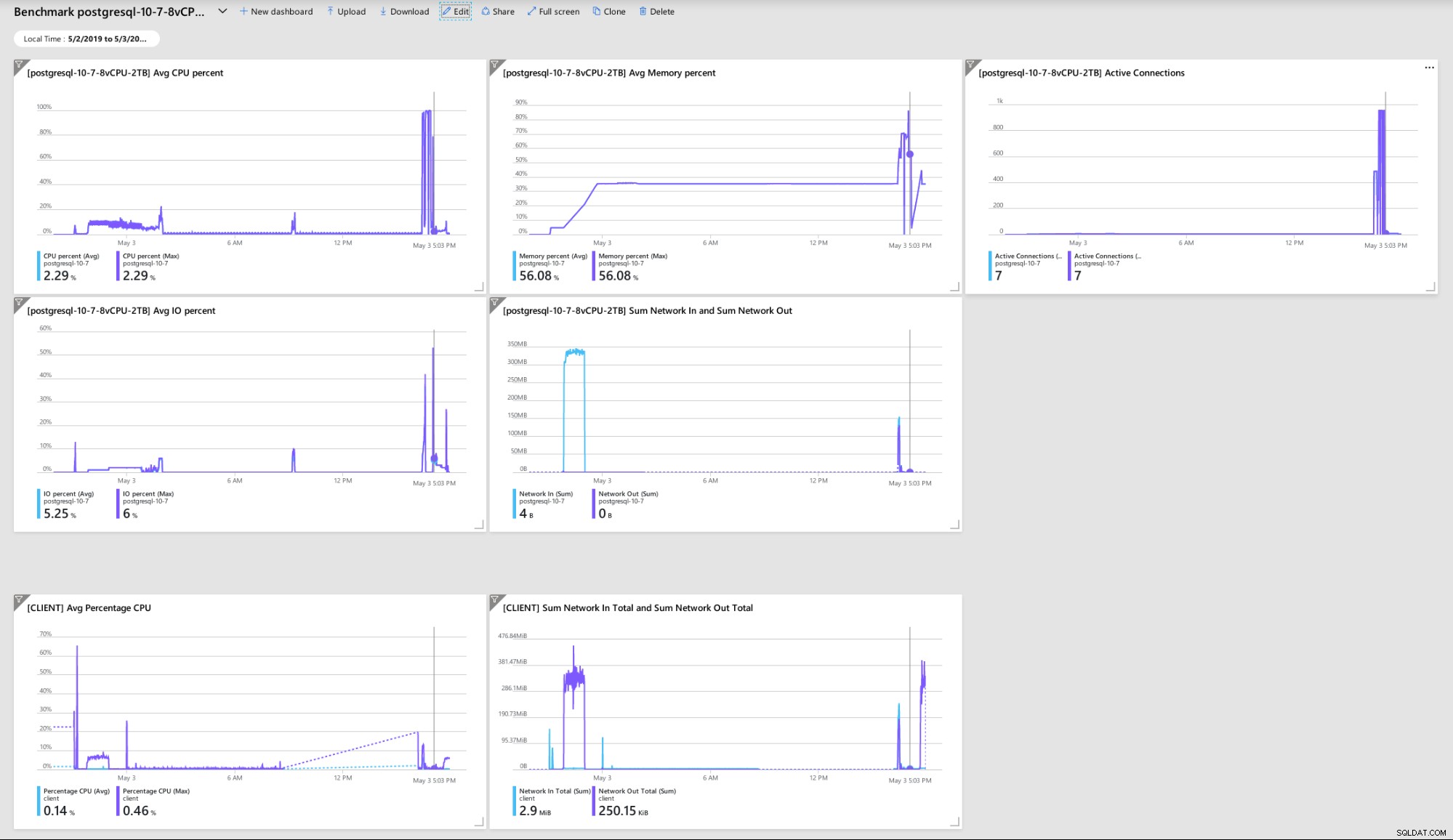 Pulpit nawigacyjny portalu Azure — metryki dla klienta i serwera
Pulpit nawigacyjny portalu Azure — metryki dla klienta i serwera Metryki PostgreSQL zebrane za pomocą Query Performance Insight:
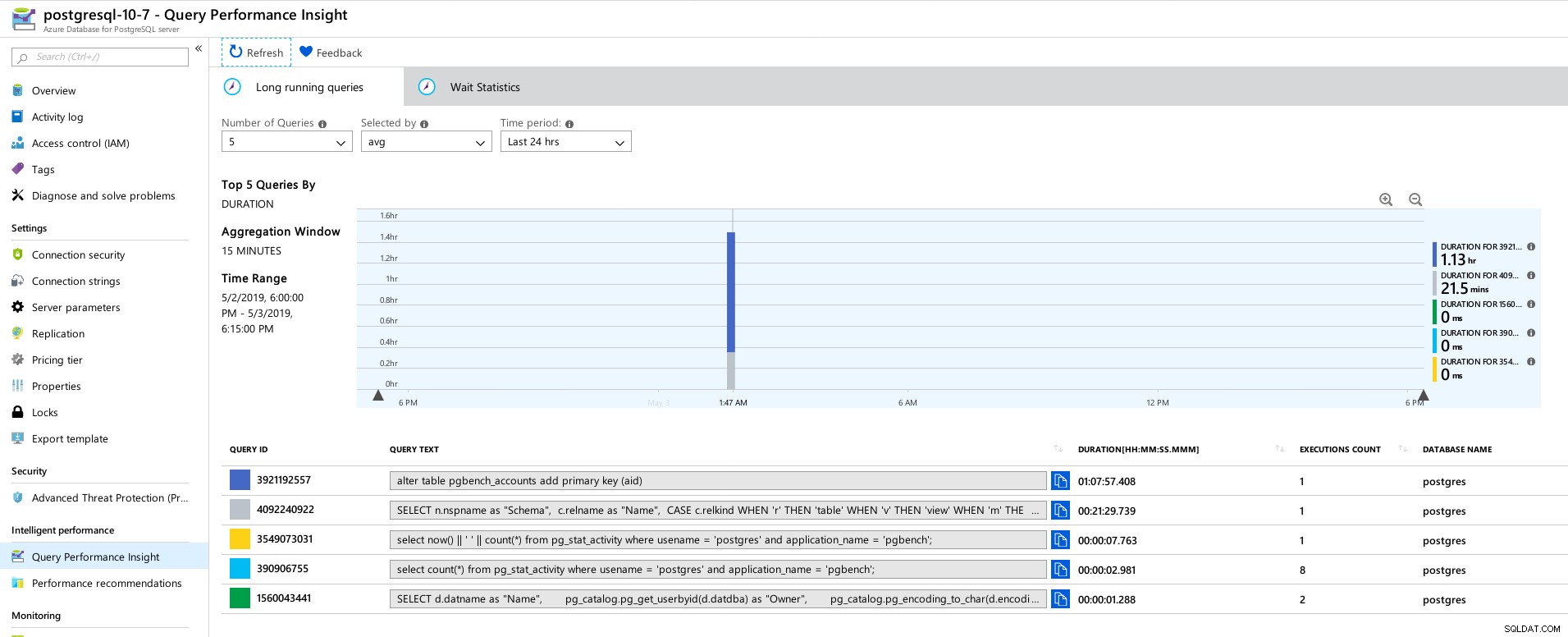 Azure PostgreSQL — informacje o wydajności zapytań:5 najczęstszych zapytań
Azure PostgreSQL — informacje o wydajności zapytań:5 najczęstszych zapytań 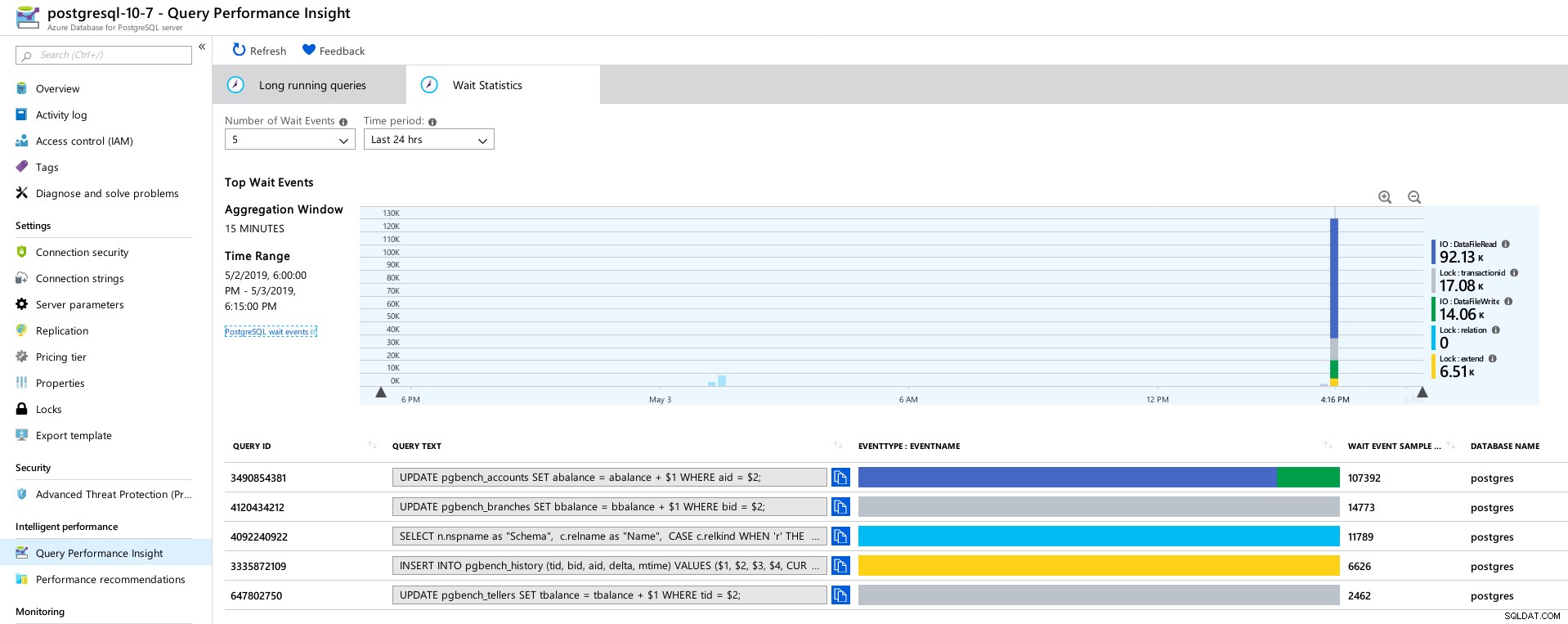 Azure PostgreSQL — informacje o wydajności zapytań:5 najważniejszych elementów czekających
Azure PostgreSQL — informacje o wydajności zapytań:5 najważniejszych elementów czekających Wniosek
Powiązane zasoby Benchmarking zarządzanych rozwiązań chmurowych PostgreSQL — część pierwsza:Analiza porównawcza Amazon Aurora — zarządzanych rozwiązań chmurowych PostgreSQL — część druga:Analiza porównawcza Amazon RDS zarządzanych rozwiązań chmurowych PostgreSQL — część trzecia:Google CloudPo pierwsze, jeśli dotarłeś tak daleko, dziękuję za przeczytanie, a jeśli zauważysz błędy, które mogły spowodować złe zachowanie środowiska, bardzo będę wdzięczny za informację zwrotną. Zakładając, że przegapiłem coś oczywistego, jestem gotów powtórzyć testy.
Awaria silnika bazy danych prowadząca do zrzutu szesnastkowego „NT HARD ERROR” wskazuje, że wydarzyło się coś poza kontrolą użytkownika, a dobrze zarządzana usługa zostałaby przywrócona za pomocą automatyzacji lub zaalarmowania odpowiedzialnych SRE. Gdybym czekał dłużej, mogłoby to mieć miejsce, chociaż pojawia się pytanie, jak długo użytkownicy muszą czekać, aż usługa zostanie przywrócona.
Zablokowanie max_connections do wartości opartej na warstwie cenowej i rdzeniach wirtualnych zaskoczyło mnie, zwłaszcza po przetestowaniu trzech innych usług zarządzanych, z Google Cloud umożliwiającym konfigurację parametru przez użytkownika, mimo że domyślna wartość była znacznie niższa (600 na G Chmura kontra 960 na Azure).
Test z instancją bazy danych w zakresie 16 rdzeni może być wymagany, aby uniknąć zmiany wartości domyślnych, chociaż w tym czasie wolałbym przetestować przy użyciu lepszych narzędzi, takich jak HammerDB (patrz Część 1, aby zapoznać się z omówieniem narzędzi) .