Chociaż wiążą się z wieloma ograniczeniami i kilkoma ważnymi zastrzeżeniami dotyczącymi implementacji, widoki indeksowane są nadal bardzo potężną funkcją SQL Server, gdy są prawidłowo stosowane w odpowiednich okolicznościach. Jednym z typowych zastosowań jest zapewnienie wstępnie zagregowanego widoku podstawowych danych, dając użytkownikom możliwość bezpośredniego zapytania o wyniki bez ponoszenia kosztów przetwarzania podstawowych sprzężeń, filtrów i agregacji za każdym razem, gdy wykonywane jest zapytanie.
Chociaż nowe funkcje Enterprise Edition, takie jak przechowywanie kolumnowe i przetwarzanie w trybie wsadowym, zmieniły charakterystykę wydajności wielu dużych zapytań tego typu, nadal nie ma szybszego sposobu uzyskania wyniku niż całkowite uniknięcie przetwarzania bazowego, bez względu na to, jak wydajne jest to przetwarzanie. mogło się stać.
Przed dodaniem do produktu widoków indeksowanych (i ich bardziej ograniczonych kuzynów, kolumn wyliczanych), specjaliści od baz danych czasami pisali złożony kod z wieloma wyzwalaczami, aby przedstawić wyniki ważnego zapytania w rzeczywistej tabeli. Tego rodzaju ustalenia są notorycznie trudne do osiągnięcia we wszystkich okolicznościach, zwłaszcza gdy często występują jednoczesne zmiany danych podstawowych.
Funkcja widoków indeksowanych znacznie ułatwia to wszystko tam, gdzie jest rozsądnie i poprawnie zastosowana. Silnik bazy danych dba o wszystko, co jest potrzebne, aby dane odczytywane z indeksowanego widoku przez cały czas były zgodne z bazowym zapytaniem i danymi tabeli.
Konserwacja przyrostowa
SQL Server utrzymuje indeksowane dane widoku zsynchronizowane z zapytaniem bazowym, automatycznie aktualizując odpowiednio indeksy widoków po każdej zmianie danych w tabelach podstawowych. Koszt tej czynności konserwacyjnej ponosi proces zmiany danych bazowych. Dodatkowe operacje potrzebne do utrzymania indeksów widoku są dyskretnie dodawane do planu wykonania oryginalnej operacji wstawiania, aktualizowania, usuwania lub scalania. W tle SQL Server zajmuje się również bardziej subtelnymi kwestiami dotyczącymi izolacji transakcji, na przykład zapewniając prawidłową obsługę transakcji działających w ramach migawki lub odczytuj zatwierdzonej izolacji migawki.
Konstruowanie dodatkowych operacji planu wykonania potrzebnych do prawidłowego utrzymania indeksów widoku nie jest sprawą trywialną, o czym wie każdy, kto próbował implementacji „tabeli podsumowującej obsługiwanej przez kod wyzwalacza”. Złożoność zadania jest jednym z powodów, dla których zindeksowane widoki mają tak wiele ograniczeń. Ograniczenie obsługiwanej powierzchni do połączeń wewnętrznych, projekcji, selekcji (filtrów) oraz agregatów SUM i COUNT_BIG znacznie zmniejsza złożoność implementacji.
Zindeksowane widoki są utrzymywane narastająco . Oznacza to, że procesor zapytań określa wpływ netto zmian tabeli podstawowej na widok i stosuje tylko te zmiany, które są niezbędne do zaktualizowania widoku. W prostych przypadkach może obliczyć niezbędne delty tylko na podstawie zmian w tabeli podstawowej i danych aktualnie przechowywanych w widoku. Tam, gdzie definicja widoku zawiera połączenia, część planu wykonania dotycząca obsługi widoków indeksowanych będzie musiała również uzyskać dostęp do połączonych tabel, ale zwykle można to wykonać wydajnie, biorąc pod uwagę odpowiednie indeksy tabel bazowych.
Aby jeszcze bardziej uprościć implementację, SQL Server zawsze używa tego samego podstawowego kształtu planu (jako punktu wyjścia) do implementacji operacji konserwacji widoku indeksowanego. Zwykłe funkcje zapewniane przez optymalizator zapytań są wykorzystywane do uproszczenia i optymalizacji standardowego kształtu konserwacji zgodnie z potrzebami. Przejdziemy teraz do przykładu, który pomoże połączyć te koncepcje.
Przykład 1 – Wkładka jednorzędowa
Załóżmy, że mamy następującą prostą tabelę i zindeksowany widok:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Po uruchomieniu tego skryptu dane w przykładowej tabeli wyglądają tak:

Widok indeksowany zawiera:

Najprostszy przykład planu konserwacji widoku indeksowanego dla tej konfiguracji występuje, gdy dodajemy pojedynczy wiersz do tabeli podstawowej:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Plan wykonania tej wkładki pokazano poniżej:
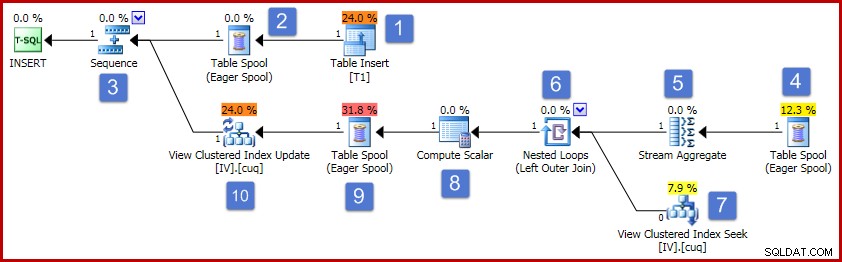
Zgodnie z liczbami na diagramie, działanie tego planu wykonania przebiega w następujący sposób:
- Operator wstawiania tabeli dodaje nowy wiersz do tabeli podstawowej. Jest to jedyny operator planu związany z wstawianiem tabeli podstawowej; wszyscy pozostali operatorzy zajmują się utrzymaniem zindeksowanego widoku.
- Buforowanie tabeli Chętni zapisuje wstawione dane wiersza w pamięci tymczasowej.
- Operator Sekwencji zapewnia, że górna gałąź planu działa do końca przed aktywacją następnej gałęzi w Sekwencji. W tym szczególnym przypadku (wstawienie pojedynczego wiersza) byłoby poprawne usunięcie Sekwencji (i szpuli w pozycjach 2 i 4), bezpośrednio łącząc wejście Stream Aggregate z wyjściem Table Insert. Ta możliwa optymalizacja nie jest zaimplementowana, więc Sekwencja i Spool pozostają.
- Ten Chętny bufor tabeli jest powiązany z buforem na pozycji 2 (ma właściwość identyfikatora węzła podstawowego, która jawnie udostępnia to łącze). Bufor odtwarza wiersze (jeden wiersz w niniejszym przypadku) z tej samej pamięci tymczasowej, do której jest zapisywany przez bufor podstawowy. Jak wspomniano powyżej, bufory i pozycje 2 i 4 są niepotrzebne i działają po prostu dlatego, że istnieją w ogólnym szablonie do konserwacji widoków indeksowanych.
- Agregacja strumienia oblicza sumę danych kolumny Wartość we wstawionym zestawie i zlicza liczbę wierszy występujących w grupie kluczy widoku. Wynikiem są dane przyrostowe potrzebne do utrzymania synchronizacji widoku z danymi podstawowymi. Należy zauważyć, że Stream Aggregate nie zawiera elementu Grupuj według, ponieważ optymalizator zapytań wie, że przetwarzana jest tylko jedna wartość. Jednak optymalizator nie stosuje podobnej logiki w celu zastąpienia agregatów prognozami (suma pojedynczej wartości jest tylko samą wartością, a licznik zawsze będzie równy jeden dla wstawienia pojedynczego wiersza). Obliczanie sumy i liczebności agregatów dla pojedynczego wiersza danych nie jest kosztowną operacją, więc ta pominięta optymalizacja nie jest zbytnio niepokojąca.
- Złączenie wiąże każdą obliczoną zmianę przyrostową z istniejącym kluczem w widoku indeksowanym. Łączenie jest łączeniem zewnętrznym, ponieważ nowo wstawione dane mogą nie odpowiadać żadnym istniejącym danym w widoku.
- Ten operator lokalizuje wiersz do modyfikacji w widoku.
- Skalar obliczeniowy ma dwa ważne zadania. Po pierwsze, określa, czy każda przyrostowa zmiana wpłynie na istniejący wiersz w widoku, czy też trzeba będzie utworzyć nowy wiersz. Robi to, sprawdzając, czy sprzężenie zewnętrzne wygenerowało wartość null po stronie widoku sprzężenia. Nasz przykładowy wstawka jest dla grupy 3, która aktualnie nie istnieje w widoku, więc zostanie utworzony nowy wiersz. Drugą funkcją Compute Skalar jest obliczanie nowych wartości dla kolumn widoku. Jeśli do widoku ma zostać dodany nowy wiersz, jest to po prostu wynik sumy przyrostowej z Stream Aggregate. Jeśli istniejący wiersz w widoku ma zostać zaktualizowany, nowa wartość to istniejąca wartość w wierszu widoku plus suma przyrostowa z Stream Aggregate.
- Ta gorliwa szpula stołu służy do ochrony na Halloween. Jest to wymagane dla poprawności, gdy operacja wstawiania wpływa na tabelę, do której odwołuje się również po stronie dostępu do danych w zapytaniu. Z technicznego punktu widzenia nie jest to wymagane, jeśli operacja konserwacji pojedynczego wiersza powoduje aktualizację istniejącego wiersza widoku, ale i tak pozostaje w planie.
- Ostateczny operator w planie jest oznaczony jako operator aktualizacji, ale wykona wstawienie lub aktualizację dla każdego otrzymanego wiersza, w zależności od wartości kolumny „kod akcji” dodanej przez skalar obliczeniowy w węźle 8 Ogólnie rzecz biorąc, ten operator aktualizacji może wstawiać, aktualizować i usuwać.
Jest tam sporo szczegółów, więc podsumowując:
- Agregacja grupuje zmiany danych według unikalnego klucza klastrowego widoku. Oblicza efekt netto zmian tabeli podstawowej w każdej kolumnie na klucz.
- Zewnętrzne sprzężenie łączy przyrostowe zmiany według klucza z istniejącymi wierszami w widoku.
- Skalar obliczeniowy oblicza, czy do widoku należy dodać nowy wiersz, czy zaktualizować istniejący wiersz. Oblicza końcowe wartości kolumn dla operacji wstawiania lub aktualizacji widoku.
- Operator aktualizacji widoku wstawia nowy wiersz lub aktualizuje istniejący zgodnie z kodem akcji.
Przykład 2 – Wkładka wielorzędowa
Wierzcie lub nie, ale omówiony powyżej plan wykonania jednowierszowego wstawiania tabeli bazowej został poddany wielu uproszczeniom. Chociaż pominięto niektóre możliwe dalsze optymalizacje (jak zauważono), optymalizator zapytań nadal zdołał usunąć niektóre operacje z ogólnego szablonu konserwacji widoku indeksowanego i zmniejszyć złożoność innych.
Kilka z tych optymalizacji było dozwolonych, ponieważ wstawialiśmy tylko jeden wiersz, ale inne były włączone, ponieważ optymalizator mógł zobaczyć wartości literalne dodawane do tabeli podstawowej. Na przykład optymalizator może zobaczyć, że wstawiona wartość grupy przekaże predykat w klauzuli WHERE widoku.
Jeśli teraz wstawimy dwa wiersze z wartościami „ukrytymi” w zmiennych lokalnych, otrzymamy nieco bardziej złożony plan:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
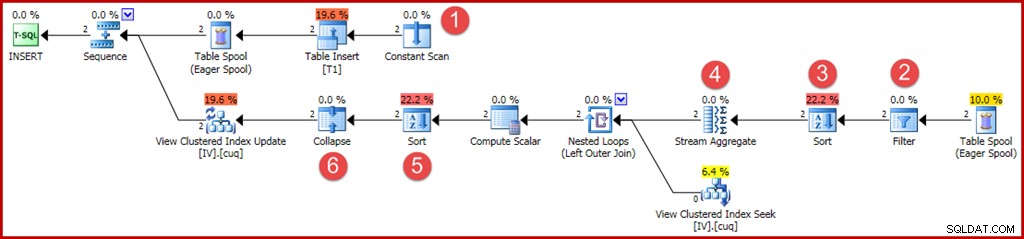
Nowe lub zmienione operatory są opisane jak poprzednio:
- Skanowanie ciągłe dostarcza wartości do wstawienia. Wcześniej optymalizacja dla wstawek jednorzędowych pozwalała na pominięcie tego operatora.
- Wyraźny operator filtru jest teraz wymagany do sprawdzenia, czy grupy wstawione do tabeli bazowej pasują do klauzuli WHERE w widoku. Tak się składa, że oba nowe wiersze przejdą test, ale optymalizator nie widzi wartości w zmiennych, aby wiedzieć o tym z góry. Ponadto nie byłoby bezpieczne buforowanie planu, który pominął ten filtr, ponieważ przyszłe ponowne użycie planu może mieć różne wartości w zmiennych.
- Sortowanie jest teraz wymagane, aby upewnić się, że wiersze docierają do agregacji strumienia w kolejności grupowej. Sortowanie zostało wcześniej usunięte, ponieważ nie ma sensu sortować jednego wiersza.
- Agregacja strumienia ma teraz właściwość „grupuj według”, dopasowującą się do unikalnego klucza klastrowego widoku.
- To sortowanie jest wymagane do przedstawienia wierszy w kolejności klucza widoku i kodu akcji, co jest wymagane do prawidłowego działania operatora zwijania. Sort jest operatorem w pełni blokującym, więc nie ma już potrzeby używania szpuli stołu Chętnej do ochrony na Halloween.
- Nowy operator Collapse łączy sąsiednie wstawianie i usuwanie tej samej wartości klucza w jedną operację aktualizacji. Ten operator nie jest w rzeczywistości wymagany w tym przypadku, ponieważ nie można wygenerować kodów akcji usuwania (tylko wstawienia i aktualizacje). Wydaje się, że to przeoczenie, a może coś pozostawionego ze względów bezpieczeństwa. Automatycznie generowane części planu zapytań aktualizujących mogą stać się niezwykle złożone, więc trudno jest mieć pewność.
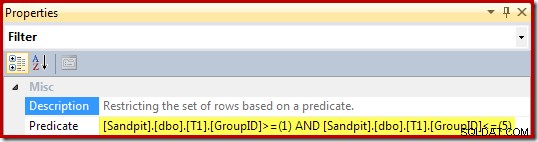
Właściwości filtra (pochodzące z klauzuli WHERE widoku) to:
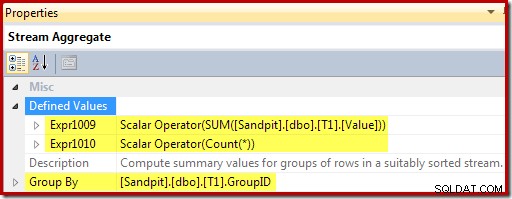
Stream Aggregate grupuje według klucza widoku i oblicza sumę i liczbę agregatów na grupę:
Skalar obliczeniowy identyfikuje akcję do wykonania na wiersz (w tym przypadku wstawianie lub aktualizowanie) i oblicza wartość do wstawienia lub zaktualizowania w widoku:
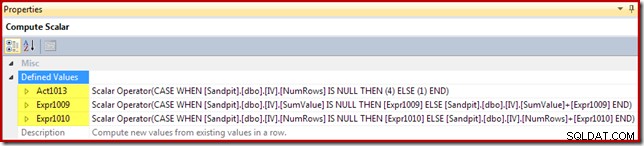
Kod akcji otrzymuje etykietę wyrażenia [Act1xxx]. Prawidłowe wartości to 1 dla aktualizacji, 3 dla usunięcia i 4 dla wstawienia. To wyrażenie akcji powoduje wstawienie (kod 4), jeśli w widoku nie znaleziono pasującego wiersza (tj. sprzężenie zewnętrzne zwróciło wartość null dla kolumny NumRows). Jeśli znaleziono pasujący wiersz, kod działania to 1 (aktualizacja).
Zauważ, że NumRows to nazwa nadana wymaganej kolumnie COUNT_BIG(*) w widoku. W planie, który może spowodować usunięcie z widoku, skalar obliczeniowy wykryje, kiedy ta wartość stanie się zero (brak wierszy dla bieżącej grupy) i wygeneruje kod czynności usunięcia (3).
Pozostałe wyrażenia zachowują w widoku agregaty sumy i liczby. Zauważ jednak, że etykiety wyrażeń [Wyr1009] i [Wyr1010] nie są nowe; odnoszą się do etykiet utworzonych przez Stream Aggregate. Logika jest prosta:jeśli nie znaleziono pasującego wiersza, nowa wartość do wstawienia jest tylko wartością obliczoną w agregacji. Jeśli znaleziono pasujący wiersz w widoku, zaktualizowana wartość to bieżąca wartość w wierszu plus przyrost obliczony przez agregat.
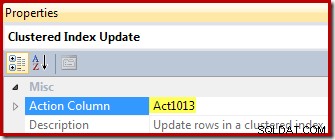
Na koniec operator aktualizacji widoku (pokazany jako aktualizacja indeksu klastrowego w SSMS) pokazuje odwołanie do kolumny akcji ([Act1013] zdefiniowane przez skalar obliczeniowy):
Przykład 3 – Aktualizacja wielowierszowa
Do tej pory przyglądaliśmy się tylko wstawkom do tabeli bazowej. Plany wykonania usunięcia są bardzo podobne, z kilkoma niewielkimi różnicami w szczegółowych obliczeniach. Dlatego kolejny przykład przechodzi do przeglądu planu konserwacji dla aktualizacji tabeli podstawowej:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Tak jak poprzednio, w zapytaniu tym używane są zmienne do ukrywania wartości literałów przed optymalizatorem, co zapobiega stosowaniu niektórych uproszczeń. Warto również zaktualizować dwie oddzielne grupy, zapobiegając optymalizacji, które można zastosować, gdy optymalizator wie, że tylko jedna grupa (pojedynczy wiersz zindeksowanego widoku) zostanie naruszona. Plan wykonania z adnotacjami dla zapytania aktualizującego znajduje się poniżej:
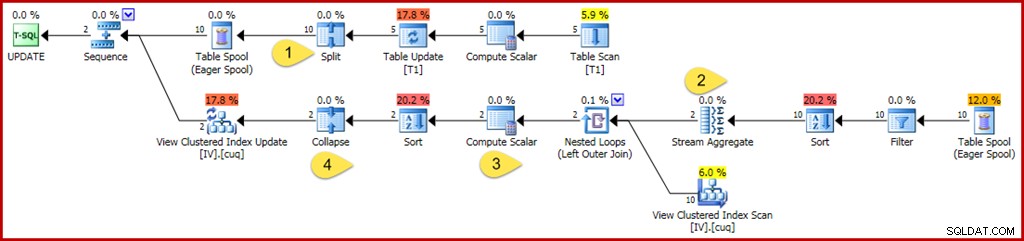
Zmiany i interesujące miejsca to:
- Nowy operator Split przekształca każdą aktualizację wiersza tabeli bazowej w oddzielną operację usuwania i wstawiania. Każdy wiersz aktualizacji jest podzielony na dwa oddzielne wiersze, co podwaja liczbę wierszy po tym punkcie planu. Split jest częścią wzorca split-sort-collapse potrzebnego do ochrony przed nieprawidłowymi przejściowymi błędami naruszeń unikalnych kluczy.
- Agregacja strumienia jest modyfikowana w celu uwzględnienia wierszy przychodzących, które mogą określać usuwanie lub wstawianie (ze względu na podział i określane przez kolumnę kodu akcji w wierszu). Wstaw wiersz wnosi oryginalną wartość w agregatach sum; znak jest odwrócony dla wierszy akcji usuwania. Podobnie, agregacja liczby wierszy tutaj liczy wstawianie wierszy jako +1 i usuwanie wierszy jako –1.
- Logika Compute Scalar jest również modyfikowana, aby odzwierciedlić, że efekt netto zmian na grupę może wymagać ewentualnej akcji wstawiania, aktualizowania lub usuwania względem zmaterializowanego widoku. W rzeczywistości nie jest możliwe, aby to konkretne zapytanie aktualizacyjne spowodowało wstawienie lub usunięcie wiersza w tym widoku, ale logika wymagana do wywnioskowania wykracza poza obecne możliwości rozumowania optymalizatora. Nieco inna kwerenda aktualizacji lub definicja widoku może rzeczywiście skutkować kombinacją akcji wstawiania, usuwania i aktualizowania widoku.
- Operator Collapse jest wyróżniony wyłącznie ze względu na jego rolę we wzorcu split-sort-collapse wspomnianym powyżej. Zauważ, że zwija usuwa i wstawia tylko ten sam klucz; niezrównane usunięcia i wstawienia po zwinięciu są całkowicie możliwe (i całkiem zwykle).
Tak jak poprzednio, właściwości operatora głównego, na które należy spojrzeć, aby zrozumieć prace związane z konserwacją widoku indeksowanego, to filtr, agregacja strumienia, sprzężenie zewnętrzne i skalar obliczeniowy.
Przykład 4 – Aktualizacja wielowierszowa z połączeniami
Aby uzupełnić przegląd planów wykonania konserwacji widoków indeksowanych, będziemy potrzebować nowego przykładowego widoku, który łączy ze sobą kilka tabel i zawiera projekcję na liście wyboru:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Aby zapewnić poprawność, jednym z wymagań dotyczących widoku indeksowanego jest to, że agregacja sum nie może działać na wyrażeniu, które może mieć wartość null. Powyższa definicja widoku używa ISNULL, aby spełnić to wymaganie. Przykładowe zapytanie aktualizacyjne, które generuje dość kompleksowy składnik planu utrzymania indeksu, pokazano poniżej, wraz z generowanym planem wykonania:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
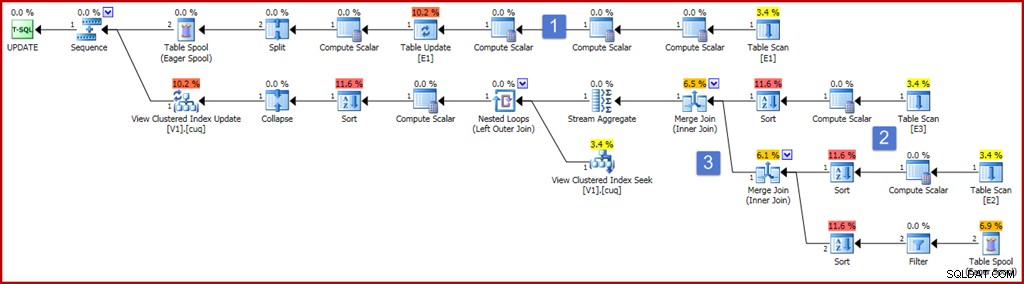
Plan wygląda teraz na dość duży i skomplikowany, ale większość elementów jest dokładnie taka, jak już widzieliśmy. Kluczowe różnice to:
- Górna gałąź planu obejmuje szereg dodatkowych operatorów obliczeniowych skalarnych. Mogłyby one być bardziej zwarte, ale zasadniczo są obecne, aby uchwycić wartości sprzed aktualizacji z kolumn niezwiązanych z grupowaniem. Skalar obliczeniowy po lewej stronie aktualizacji tabeli przechwytuje wartość po aktualizacji kolumny „a” z stosowaną projekcją ISNULL.
- Nowe skalary obliczeniowe w tym obszarze planu obliczają wartość wytworzoną przez wyrażenie ISNULL w każdej tabeli źródłowej. Ogólnie, projekcje na połączonych tabelach w widoku będą tutaj reprezentowane przez skalary obliczeniowe. Sortowanie w tym obszarze planu są obecne wyłącznie dlatego, że optymalizator wybrał strategię łączenia przez scalanie ze względu na koszty (pamiętaj, że scalanie wymaga posortowanych danych wejściowych według klucza łączenia).
- Dwa operatory złączenia są nowe i po prostu implementują złączenia w definicji widoku. Te sprzężenia zawsze pojawiają się przed Stream Aggregate, który oblicza przyrostowy wpływ zmian na widok. Należy zauważyć, że zmiana w tabeli podstawowej może spowodować, że wiersz, który spełniał kryteria łączenia, nie będzie już dołączany i na odwrót. Wszystkie te potencjalne złożoności są obsługiwane poprawnie (biorąc pod uwagę ograniczenia widoków indeksowanych) przez Stream Aggregate, tworząc podsumowanie zmian na klucz widoku po wykonaniu złączeń.
Ostateczne myśli
Ten ostatni plan reprezentuje prawie pełny szablon do utrzymywania indeksowanego widoku, chociaż dodanie indeksów nieklastrowanych do widoku spowodowałoby dodanie dodatkowych operatorów buforowanych z danych wyjściowych operatora aktualizacji widoku. Poza dodatkowym podziałem (i kombinacją Sortuj i Zwiń, jeśli nieklastrowany indeks widoku jest unikalny), nie ma nic szczególnego w tej możliwości. Dodanie klauzuli wyjściowej do zapytania o tabelę bazową może również generować kilka interesujących dodatkowych operatorów, ale znowu nie są one szczególnie związane z obsługą widoków indeksowanych per se.
Podsumowując całą ogólną strategię:
- Zmiany w tabeli podstawowej są stosowane normalnie; mogą zostać przechwycone wartości sprzed aktualizacji.
- Operatora podziału można użyć do przekształcenia aktualizacji w pary usuń/wstaw.
- Instynktowne buforowanie zapisuje informacje o zmianie tabeli podstawowej w pamięci tymczasowej.
- Dostępne są wszystkie tabele w widoku, z wyjątkiem zaktualizowanej tabeli podstawowej (która jest odczytywana z bufora).
- Rzuty w widoku są reprezentowane przez skalary obliczeniowe.
- Zastosowane są filtry w widoku. Filtry mogą być umieszczane w skanach lub wyszukiwane jako pozostałości.
- Wykonywane są połączenia określone w widoku.
- Agregacja oblicza przyrostowe zmiany netto pogrupowane według klucza widoku klastrowego.
- Zbiór zmian przyrostowych jest zewnętrznie połączony z widokiem.
- Skalar obliczeniowy oblicza kod akcji (wstaw/aktualizuj/usuń względem widoku) dla każdej zmiany i oblicza rzeczywiste wartości do wstawienia lub zaktualizowania. Logika obliczeniowa opiera się na danych wyjściowych agregatu i wyniku połączenia zewnętrznego z widokiem.
- Zmiany są sortowane według kolejności klawiszy widoku i kodu czynności oraz zwijane odpowiednio do aktualizacji.
- Na koniec, zmiany przyrostowe są stosowane do samego widoku.
Jak widzieliśmy, normalny zestaw narzędzi dostępnych dla optymalizatora zapytań jest nadal stosowany do automatycznie generowanych części planu, co oznacza, że jeden lub więcej z powyższych kroków można uprościć, przekształcić lub całkowicie usunąć. Jednak podstawowy kształt i działanie planu pozostają nienaruszone.
Jeśli śledziłeś wraz z przykładami kodu, możesz użyć następującego skryptu, aby wyczyścić:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;



