W dzisiejszych czasach bazy danych obejmujące wiele chmur są dość powszechne. Obiecują wysoką dostępność i możliwość łatwego wdrożenia procedur odtwarzania po awarii. Są również sposobem na uniknięcie uzależnienia od dostawcy:jeśli projektujesz środowisko bazy danych tak, aby mogło działać u wielu dostawców chmury, najprawdopodobniej nie jesteś przywiązany do funkcji i implementacji specyficznych dla jednego konkretnego dostawcy. Ułatwia to dodanie kolejnego dostawcy infrastruktury do środowiska, niezależnie od tego, czy jest to kolejna konfiguracja w chmurze, czy lokalna. Taka elastyczność jest bardzo ważna, biorąc pod uwagę ostrą konkurencję między dostawcami chmury, a migracja z jednego do drugiego może być całkiem wykonalna, jeśli będzie poparta zmniejszeniem kosztów.
Rozpięcie infrastruktury w wielu centrach danych (od tego samego dostawcy lub nie, nie ma to większego znaczenia) wiąże się z poważnymi problemami do rozwiązania. Jak zaprojektować całą infrastrukturę tak, aby dane były bezpieczne? Jak radzić sobie z wyzwaniami, z którymi musisz się zmierzyć pracując w środowisku multi-chmurowym? W tym blogu przyjrzymy się jednemu, ale prawdopodobnie najpoważniejszemu – potencjałowi rozszczepionego mózgu. Co to znaczy? Zagłębmy się trochę w to, czym jest rozszczepiony mózg.
Co to jest „Podział mózgu”?
Podział mózgu to stan, w którym środowisko składające się z wielu węzłów cierpi na partycjonowanie sieci i zostało podzielone na wiele segmentów, które nie mają ze sobą kontaktu. Najprostszy przypadek będzie wyglądał tak:
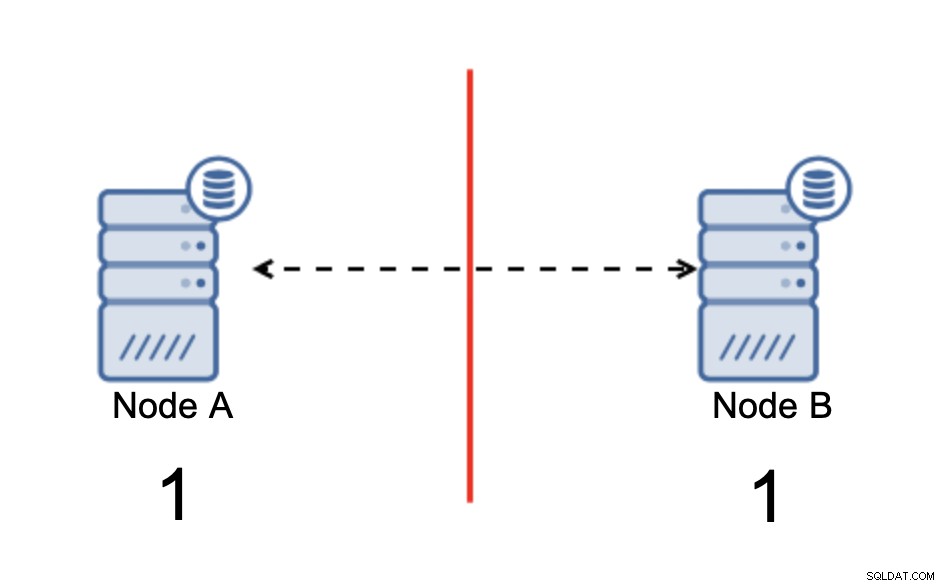
Mamy dwa węzły, A i B, połączone przez sieć za pomocą bi -kierunkowa replikacja asynchroniczna. Następnie połączenie sieciowe zostaje przerwane między tymi węzłami. W efekcie oba węzły nie mogą się ze sobą połączyć, a zmiany wykonane na węźle A nie mogą być przesyłane do węzła B i odwrotnie. Oba węzły, A i B, działają i akceptują połączenia, po prostu nie mogą wymieniać danych. Może to prowadzić do poważnych problemów, ponieważ aplikacja może wprowadzać zmiany na obu węzłach, oczekując pełnego stanu bazy danych, podczas gdy w rzeczywistości działa tylko na częściowo znanym stanie danych. W rezultacie aplikacja może podjąć nieprawidłowe działania, wyświetlić użytkownikowi nieprawidłowe wyniki i tak dalej. Uważamy, że jest jasne, że rozszczepiony mózg jest potencjalnie bardzo niebezpiecznym stanem i jednym z priorytetów byłoby radzenie sobie z nim do pewnego stopnia. Co można z tym zrobić?
Jak uniknąć rozszczepienia mózgu
W skrócie, to zależy. Głównym problemem, z którym należy sobie poradzić, jest fakt, że węzły działają, ale nie mają między nimi połączenia, dlatego nie są świadome stanu drugiego węzła. Ogólnie rzecz biorąc, asynchroniczna replikacja MySQL nie ma żadnego mechanizmu, który wewnętrznie rozwiązałby problem rozszczepienia mózgu. Możesz spróbować wdrożyć pewne rozwiązania, które pomogą ci uniknąć rozszczepienia mózgu, ale mają one ograniczenia lub nadal nie rozwiązują w pełni problemu.
Kiedy odchodzimy od replikacji asynchronicznej, sprawy wyglądają inaczej. MySQL Group Replication i MySQL Galera Cluster to technologie, które korzystają ze świadomości klastrów typu build-it. Oba te rozwiązania utrzymują komunikację między węzłami i zapewniają, że klaster jest świadomy stanu węzłów. Wdrażają mechanizm kworum, który określa, czy klastry mogą działać, czy nie.
Omówmy te dwa rozwiązania (replikacja asynchroniczna i klastry oparte na kworum) bardziej szczegółowo.
Klastrowanie oparte na kworum
Nie będziemy omawiać różnic w implementacji między MySQL Galera Cluster a MySQL Group Replication, skupimy się na podstawowej idei stojącej za podejściem opartym na kworum i sposobie, w jaki zostało ono zaprojektowane w celu rozwiązania problemu split-brain w twoim klastrze.
Najważniejsze jest to, że:klaster, aby działać, wymaga, aby większość jego węzłów była dostępna. Dzięki temu wymogowi możemy być pewni, że mniejszość nigdy nie będzie miała realnego wpływu na resztę klastra, ponieważ mniejszość nie powinna mieć możliwości wykonywania żadnych działań. Oznacza to również, że aby móc obsłużyć awarię jednego węzła, klaster powinien mieć co najmniej trzy węzły. Jeśli masz tylko dwa węzły:
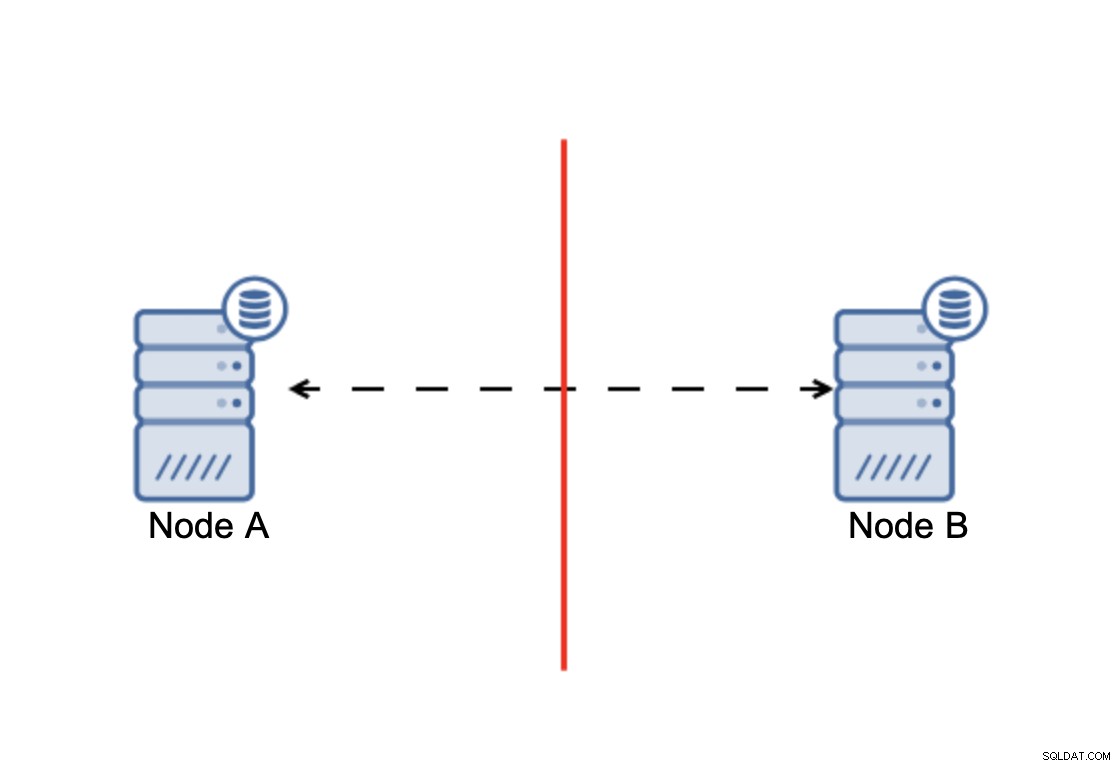
W przypadku podziału sieci powstają dwie części klaster, każdy składający się z dokładnie 50% wszystkich węzłów w klastrze. Żadna z tych części nie ma większości. Jeśli masz trzy węzły, sytuacja wygląda inaczej:
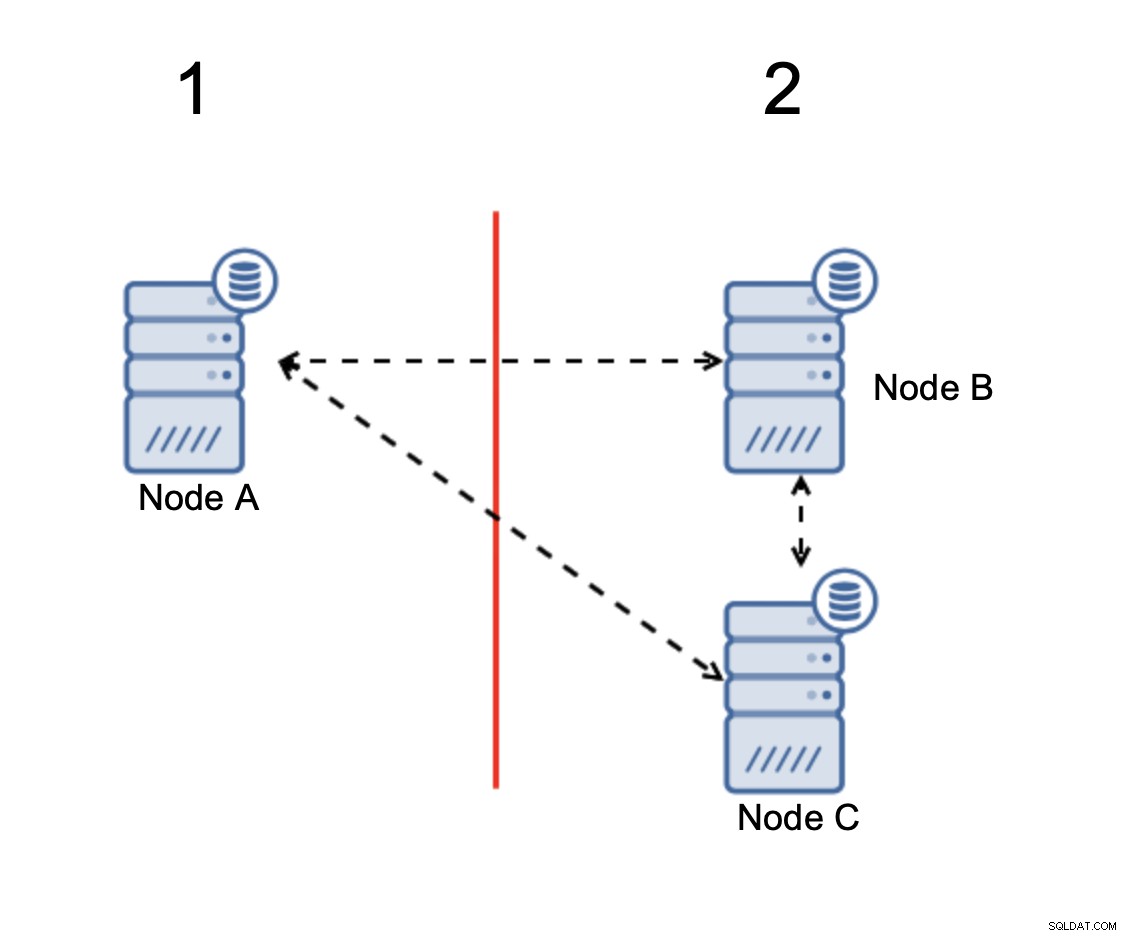
Węzły B i C mają większość:ta część składa się z dwóch węzłów na zewnątrz trzech, dzięki czemu może nadal działać. Z drugiej strony węzeł A reprezentuje tylko 33% węzłów w klastrze, więc nie ma większości i przestanie obsługiwać ruch, aby uniknąć podziału mózgu.
Przy takiej implementacji, rozszczepienie mózgu jest bardzo mało prawdopodobne (musiałoby być wprowadzone przez niektóre dziwne i nieoczekiwane stany sieci, wyścigi lub po prostu błędy w kodzie klastrowym. Chociaż nie jest to niemożliwe do napotkania w takich warunkach użycie jednego z rozwiązań opartych na kworum jest najlepszą opcją, aby uniknąć rozszczepienia mózgu, który istnieje w tej chwili.
Replikacja asynchroniczna
Chociaż nie jest to idealny wybór, jeśli chodzi o rozszczepienie mózgu, replikacja asynchroniczna jest nadal realną opcją. Jest kilka rzeczy, które należy wziąć pod uwagę przed wdrożeniem wielochmurowej bazy danych z replikacją asynchroniczną.
Po pierwsze przełączanie awaryjne. Replikacja asynchroniczna jest dostarczana z jednym modułem zapisującym — tylko master powinien być zapisywalny, a inne węzły powinny obsługiwać tylko ruch tylko do odczytu. Wyzwanie polega na tym, jak poradzić sobie z główną porażką?
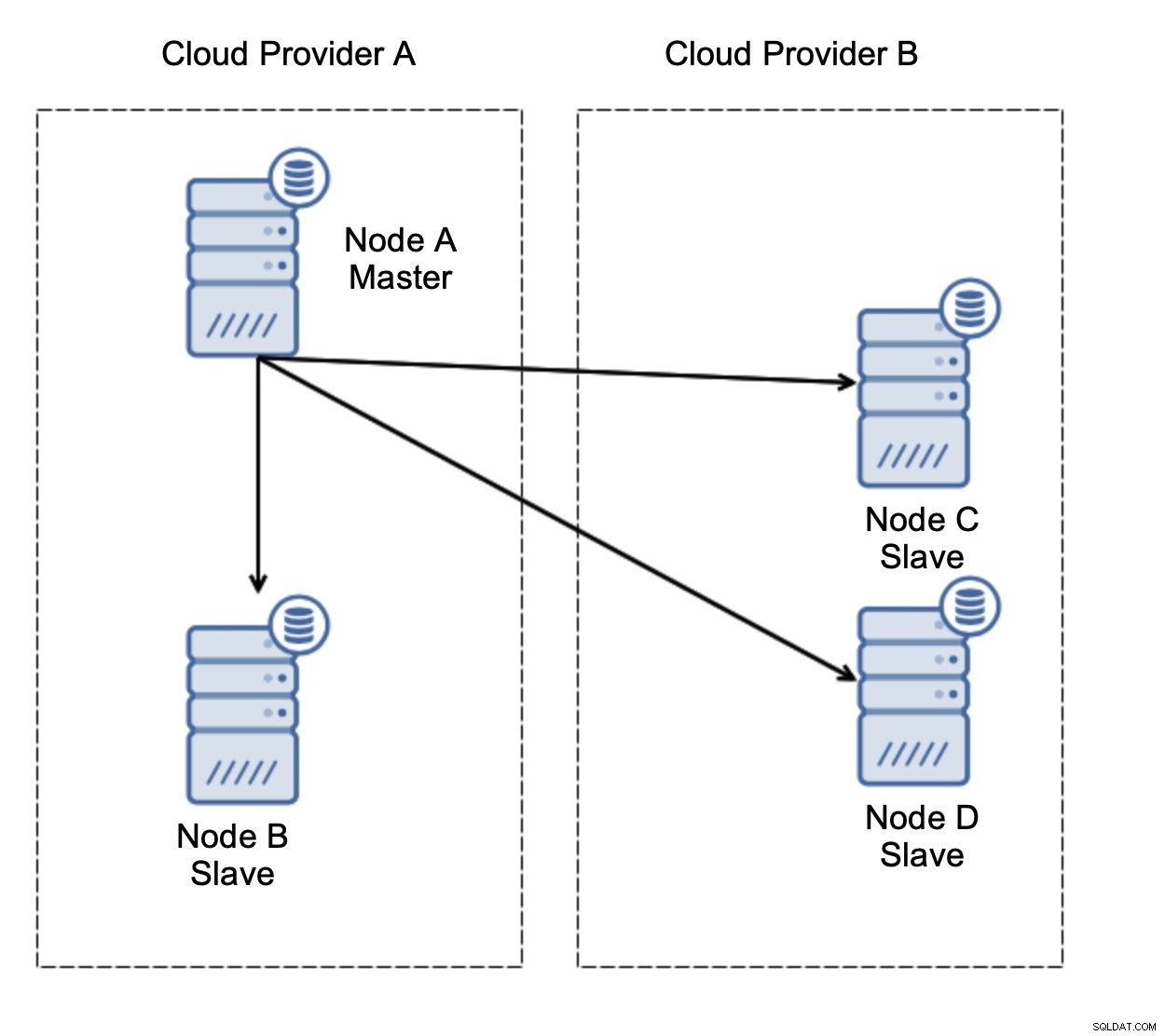
Rozważmy konfigurację jak na powyższym schemacie. Mamy dwóch dostawców chmury, po dwa węzły w każdym. Dostawca A obsługuje również mastera. Co powinno się stać, jeśli mistrz zawiedzie? Należy awansować jednego z niewolników, aby baza danych nadal działała. Najlepiej byłoby, gdyby był to proces zautomatyzowany, aby skrócić czas potrzebny na doprowadzenie bazy danych do stanu operacyjnego. Co by się jednak stało, gdyby nastąpiło partycjonowanie sieci? Jak mamy zweryfikować stan klastra?
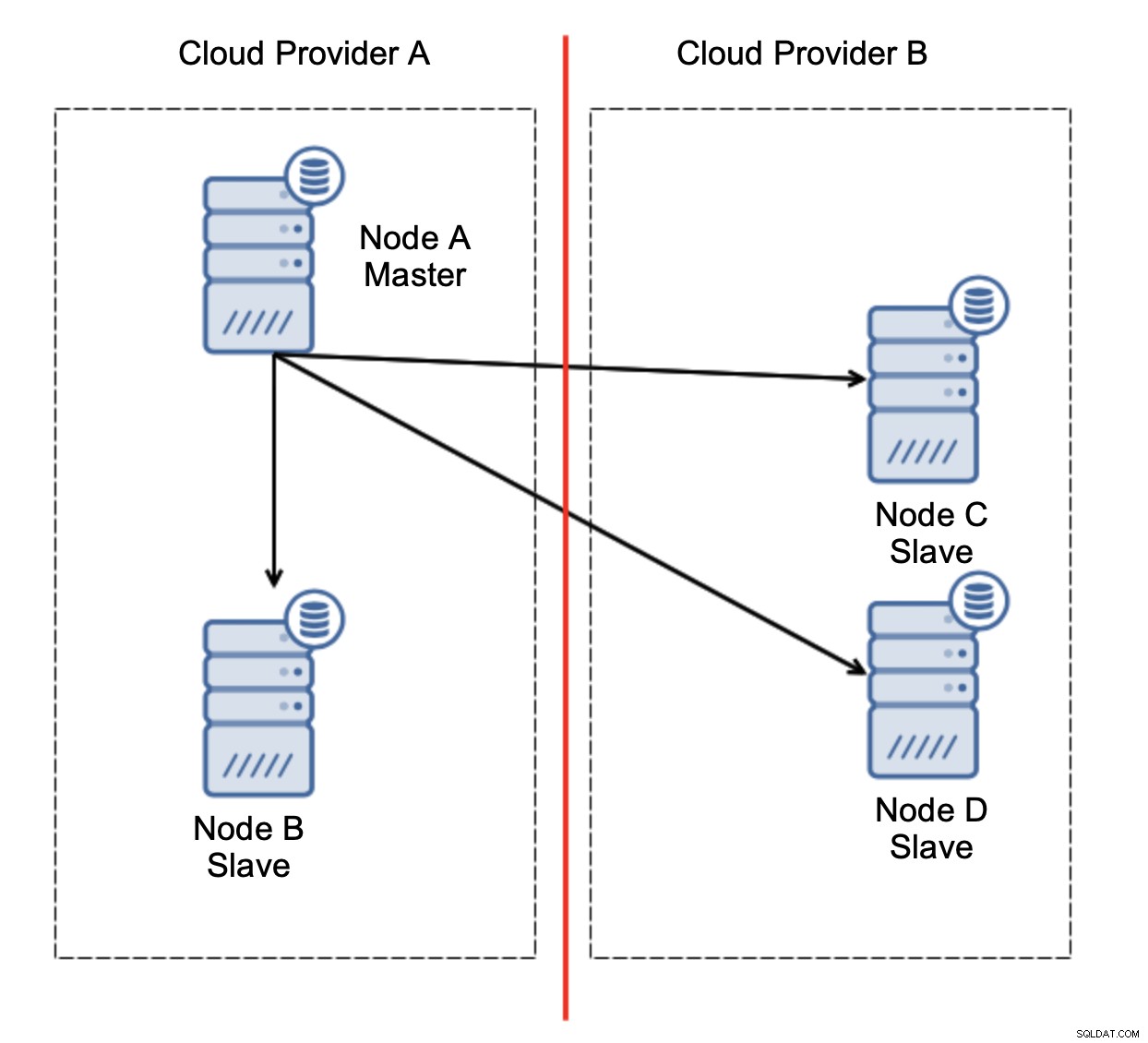
Oto wyzwanie. Utracono łączność sieciową między dwoma dostawcami chmury. Z punktu widzenia węzłów C i D, zarówno węzeł B, jak i węzeł główny, węzeł A jest w trybie offline. Czy węzeł C lub D powinien zostać awansowany na mastera? Ale stary master nadal działa - nie uległ awarii, po prostu nie jest dostępny przez sieć. Gdybyśmy promowali jeden z węzłów zlokalizowanych u dostawcy B, otrzymalibyśmy dwa zapisywalne wzorce, dwa zestawy danych i podzielony mózg:
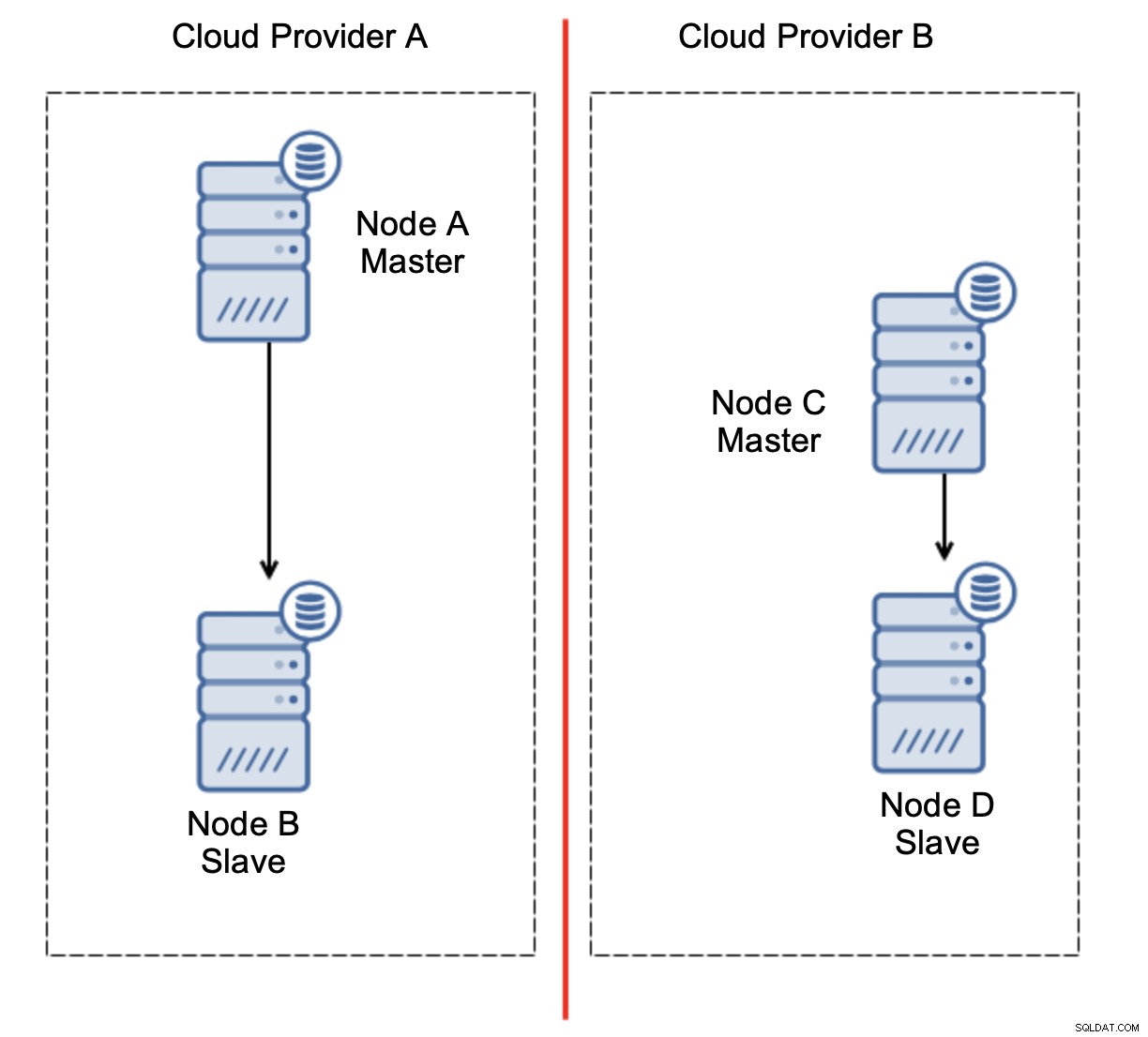
To zdecydowanie nie jest coś, czego chcemy. Jest tu kilka opcji. Po pierwsze, możemy zdefiniować reguły przełączania awaryjnego w taki sposób, aby przełączenie awaryjne mogło nastąpić tylko w jednym z segmentów sieci, w którym znajduje się master. W naszym przypadku oznaczałoby to, że tylko węzeł B mógłby zostać automatycznie awansowany na mastera. W ten sposób możemy zapewnić, że automatyczne przełączanie awaryjne nastąpi, jeśli węzeł A nie będzie działać, ale nie zostaną podjęte żadne działania w przypadku partycjonowania sieci. Niektóre narzędzia, które mogą pomóc w obsłudze automatycznych przełączeń awaryjnych (takich jak ClusterControl), obsługują białe i czarne listy, umożliwiając użytkownikom zdefiniowanie, które węzły mogą być uważane za kandydatów do przełączenia awaryjnego, a które nigdy nie powinny być używane jako nadrzędne.
Inną opcją byłoby zaimplementowanie pewnego rodzaju rozwiązania „świadomości topologii”. Na przykład można spróbować sprawdzić stan główny za pomocą usług zewnętrznych, takich jak load balancery.
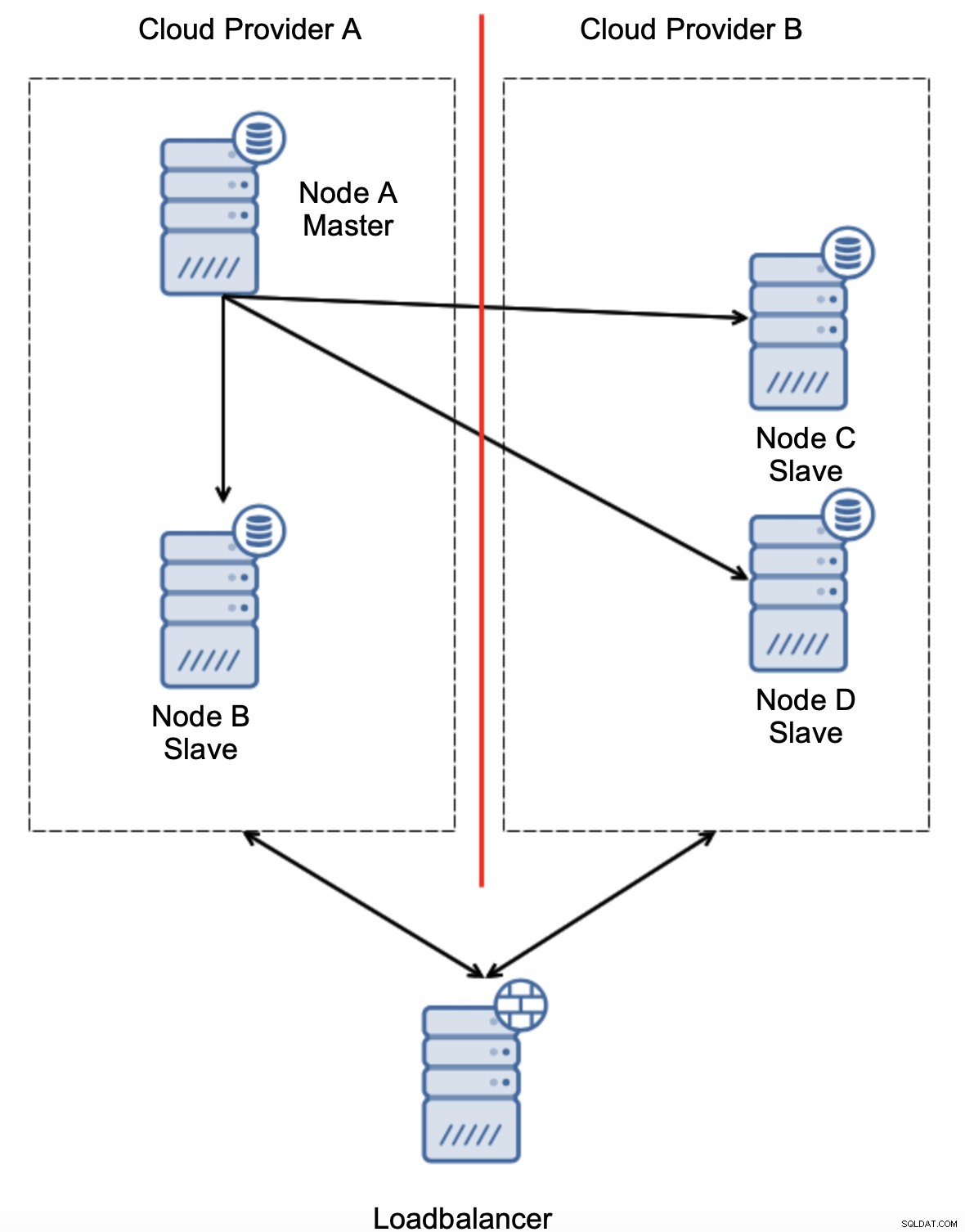
Jeśli automatyzacja przełączania awaryjnego może sprawdzić stan topologii widziany przez load balancer, może być tak, że load balancer, znajdujący się w trzeciej lokalizacji, może faktycznie dotrzeć do obu centrów danych i jasno dać do zrozumienia, że węzły dostawcy chmury A nie są wyłączone, po prostu nie można do nich dotrzeć od dostawcy chmury B. Takie dodatkowa warstwa kontroli jest zaimplementowana w ClusterControl.
Na koniec, niezależnie od narzędzia używanego do implementacji automatycznego przełączania awaryjnego, może ono być również zaprojektowane tak, aby uwzględniało kworum. Dzięki trzem węzłom w trzech lokalizacjach możesz łatwo stwierdzić, która część infrastruktury powinna być utrzymywana, a która nie.
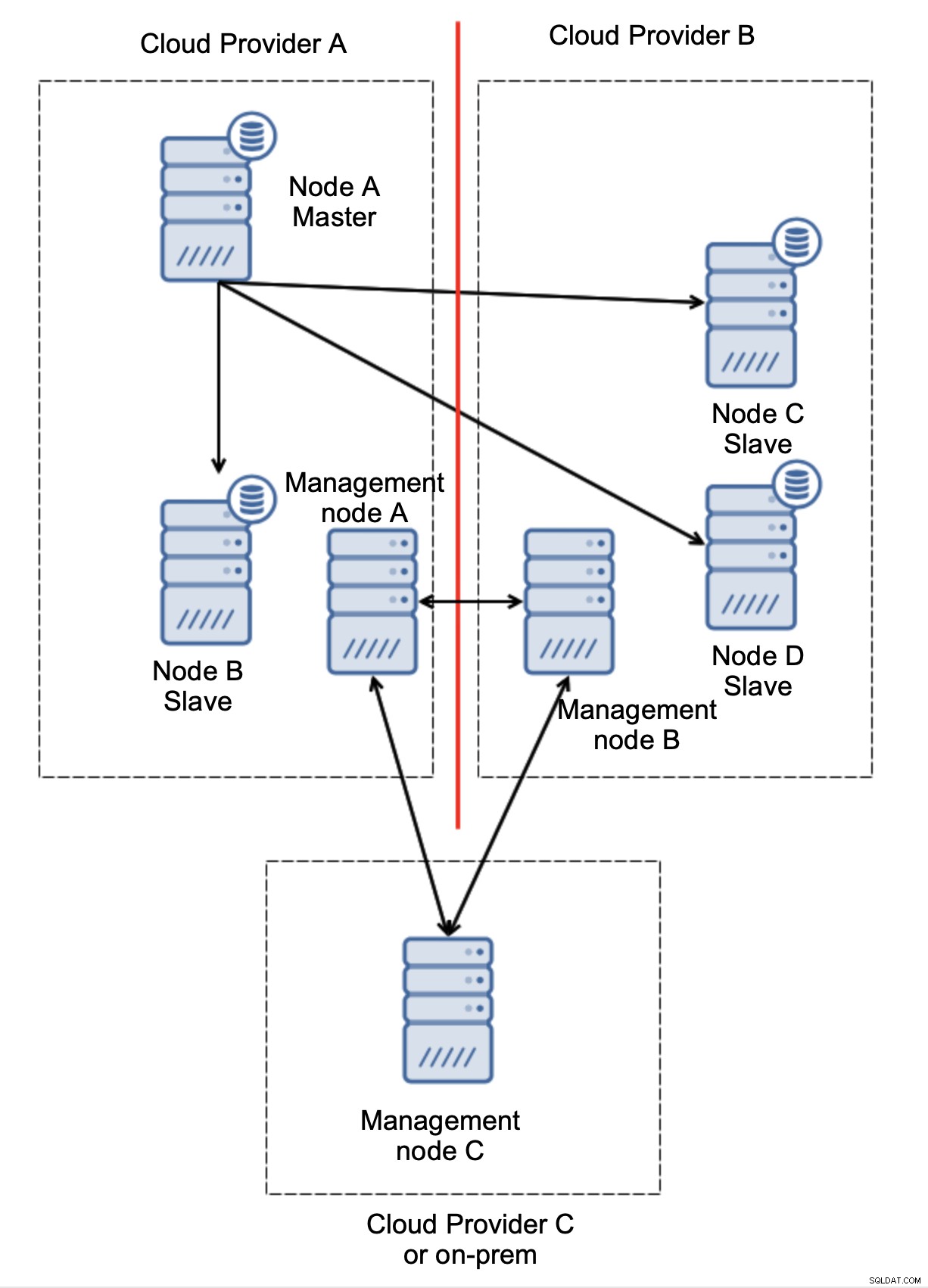
Wyraźnie widać, że problem dotyczy tylko łączności między dostawcami A i B. Węzeł zarządzania C będzie działał jako przekaźnik, w wyniku czego nie należy uruchamiać przełączania awaryjnego. Z drugiej strony, jeśli jedno centrum danych jest całkowicie odcięte:

Jest też całkiem jasne, co się stało. Węzeł zarządzania A zgłosi, że nie może dotrzeć do większości klastra, podczas gdy węzły zarządzania B i C będą stanowić większość. Można na tym bazować i na przykład pisać skrypty, które będą zarządzać topologią zgodnie ze stanem węzła zarządzania. Może to oznaczać, że skrypty wykonane u dostawcy chmury A wykryją, że węzeł zarządzania A nie stanowi większości i zatrzymają wszystkie węzły bazy danych, aby upewnić się, że u dostawcy chmury podzielonej na partycje nie nastąpią żadne zapisy.
ClusterControl, wdrożony w trybie wysokiej dostępności, może być traktowany jako węzły zarządzania, których użyliśmy w naszych przykładach. Trzy węzły ClusterControl, oprócz protokołu RAFT, mogą pomóc w ustaleniu, czy dany segment sieci jest podzielony na partycje, czy nie.
Wnioski
Mamy nadzieję, że ten post na blogu daje pewne pojęcie o scenariuszach podziału mózgu, które mogą wystąpić w przypadku wdrożeń MySQL obejmujących wiele platform chmurowych.