SQLAlchemy pomaga w pracy z bazami danych w Pythonie. W tym poście powiemy Ci wszystko, co musisz wiedzieć, aby rozpocząć korzystanie z tego modułu.
W poprzednim artykule mówiliśmy o tym, jak używać Pythona w procesie ETL. Skupiliśmy się na wykonaniu zadania, wykonując procedury składowane i zapytania SQL. W tym i następnym artykule zastosujemy inne podejście. Zamiast pisać kod SQL, użyjemy zestawu narzędzi SQLAlchemy. Możesz również użyć tego artykułu osobno, jako szybkiego wprowadzenia do instalacji i używania SQLAlchemy.
Gotowy? Zacznijmy.
Co to jest SQLAlchemia?
Python jest dobrze znany ze swojej liczby i różnorodności modułów. Moduły te znacznie skracają czas kodowania, ponieważ wdrażają procedury potrzebne do osiągnięcia określonego zadania. Dostępnych jest wiele modułów, które pracują z danymi, w tym SQLAlchemy.
Aby opisać SQLAlchemy, użyję cytatu z SQLAlchemy.org:
SQLAlchemy to zestaw narzędzi Python SQL i Object Relational Mapper, który zapewnia programistom aplikacji pełną moc i elastyczność SQL.
Zapewnia pełny zestaw dobrze znanej trwałości na poziomie przedsiębiorstwa wzorce, zaprojektowane z myślą o wydajnym i wydajnym dostępie do bazy danych, dostosowane do prostego i Pythonowego języka domeny.
Najważniejszą częścią jest tutaj fragment o ORM (maper obiektowo-relacyjny), który pomaga nam traktować obiekty bazy danych jako obiekty Pythona, a nie listy.
Zanim przejdziemy dalej z SQLAlchemy, zatrzymajmy się i porozmawiajmy o ORM-ach.
Wady i zalety korzystania z ORM
W porównaniu z surowym SQL, ORM-y mają swoje wady i zalety – a większość z nich dotyczy również SQLAlchemy.
Dobre rzeczy:
- Przenośność kodu. ORM zajmuje się różnicami składniowymi między bazami danych.
- Tylko jeden język jest potrzebny do obsługi Twojej bazy danych. Chociaż, szczerze mówiąc, nie powinno to być główną motywacją do korzystania z ORM.
- ORM-y upraszczają Twój kod , np. dbają o relacje i traktują je jak przedmioty, co jest świetne, jeśli jesteś przyzwyczajony do OOP.
- Możesz manipulować danymi w programie .
Niestety wszystko ma swoją cenę. Niezbyt dobre rzeczy dotyczące ORM:
- W niektórych przypadkach ORM może być powolny .
- Pisanie złożonych zapytań mogą stać się jeszcze bardziej skomplikowane lub mogą powodować powolne zapytania. Ale tak nie jest w przypadku korzystania z SQLAlchemy.
- Jeśli dobrze znasz swój DBMS, szkoda czasu, aby nauczyć się pisać te same rzeczy w ORM-ie.
Teraz, gdy zajęliśmy się tym tematem, wróćmy do SQLAlchemy.
Zanim zaczniemy...
… przypomnijmy sobie cel tego artykułu. Jeśli jesteś zainteresowany tylko instalacją SQLAlchemy i potrzebujesz krótkiego samouczka na temat wykonywania prostych poleceń, ten artykuł to zrobi. Jednak polecenia przedstawione w tym artykule zostaną użyte w następnym artykule do wykonania procesu ETL i zastąpienia kodu SQL (procedury składowane) i kodu Python, które przedstawiliśmy w poprzednich artykułach.
Dobra, teraz zacznijmy od samego początku:od instalacji SQLAlchemy.
Instalowanie SQLAlchemy
1. Sprawdź, czy moduł jest już zainstalowany
Aby użyć modułu Pythona, musisz go zainstalować (to znaczy, jeśli nie był wcześniej zainstalowany). Jednym ze sposobów sprawdzenia, które moduły zostały zainstalowane, jest użycie tego polecenia w powłoce Pythona:
help('modules')
Aby sprawdzić, czy określony moduł jest zainstalowany, po prostu spróbuj go zaimportować. Użyj tych poleceń:
import sqlalchemy sqlalchemy.__version__
Jeśli SQLAlchemy jest już zainstalowany, pierwsza linia zostanie wykonana pomyślnie. import to standardowe polecenie Pythona używane do importowania modułów. Jeśli moduł nie jest zainstalowany, Python zgłosi błąd – właściwie listę błędów w czerwonym tekście – którego nie możesz przegapić :)
Drugie polecenie zwraca bieżącą wersję SQLAlchemy. Zwrócony wynik jest przedstawiony poniżej:

Potrzebujemy też innego modułu, którym jest PyMySQL . Jest to lekka biblioteka klienta MySQL oparta na czystym Pythonie. Ten moduł obsługuje wszystko, czego potrzebujemy do pracy z bazą danych MySQL, od uruchamiania prostych zapytań do bardziej złożonych działań na bazie danych. Możemy sprawdzić, czy istnieje, używając help('modules') , jak opisano wcześniej, lub za pomocą następujących dwóch stwierdzeń:
import pymysql pymysql.__version__
Oczywiście są to te same polecenia, których użyliśmy do sprawdzenia, czy zainstalowano SQLAlchemy.
Co jeśli SQLAlchemy lub PyMySQL nie są jeszcze zainstalowane?
Importowanie wcześniej zainstalowanych modułów nie jest trudne. Ale co, jeśli potrzebne moduły nie są jeszcze zainstalowane?
Niektóre moduły mają pakiet instalacyjny, ale w większości przypadków użyjesz polecenia pip, aby je zainstalować. PIP to narzędzie Pythona używane do instalowania i odinstalowywania modułów. Najprostszym sposobem zainstalowania modułu (w systemie operacyjnym Windows) jest:
- Użyj Wiersza polecenia -> Uruchom -> cmd .
- Pozycja w katalogu Pythona cd C:\...\Python\Python37\Scripts .
- Uruchom polecenie pip
install(w naszym przypadku uruchomimypip install pyMySQLipip install sqlAlchemy.
PIP można również wykorzystać do odinstalowania istniejącego modułu. Aby to zrobić, powinieneś użyć pip uninstall .
2. Łączenie z bazą danych
Instalacja wszystkiego, co jest niezbędne do korzystania z SQLAlchemy, jest niezbędna, ale nie jest zbyt interesująca. Nie jest to też tak naprawdę część tego, co nas interesuje. Nie połączyliśmy się nawet z bazami danych, z których chcemy korzystać. Rozwiążemy to teraz:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Korzystając z powyższego skryptu, nawiążemy połączenie z bazą danych znajdującą się na naszym lokalnym serwerze subscription_live Baza danych.
(Uwaga: Zastąp
Przejdźmy przez skrypt, polecenie po poleceniu.
import sqlalchemy from sqlalchemy.engine import create_engine
Te dwie linie importują nasz moduł i create_engine funkcja.
Następnie nawiążemy połączenie z bazą danych znajdującą się na naszym serwerze.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Funkcja create_engine tworzy silnik i używa .connect() , łączy się z bazą danych. create_engine funkcja używa tych parametrów:
dialect+driver://username:password@host:port/database
W naszym przypadku dialektem jest mysql , sterownik to pymysql (poprzednio zainstalowane), a pozostałe zmienne są specyficzne dla serwera i bazy danych, z którymi chcemy się połączyć.
(Uwaga: Jeśli łączysz się lokalnie, użyj localhost zamiast Twojego „lokalnego” adresu IP, 127.0.0.1 i odpowiedni port :3306 .)

Wynik polecenia print(engine_live.table_names()) pokazano na powyższym obrazku. Zgodnie z oczekiwaniami otrzymaliśmy listę wszystkich tabel z naszej operacyjnej/żywej bazy danych.
3. Uruchamianie poleceń SQL przy użyciu SQLAlchemy
W tej sekcji przeanalizujemy najważniejsze polecenia SQL, zbadamy strukturę tabeli i wykonamy wszystkie cztery polecenia DML:SELECT, INSERT, UPDATE i DELETE.
Stwierdzenia użyte w tym skrypcie omówimy osobno. Należy pamiętać, że omówiliśmy już część tego skryptu dotyczącą połączenia i wymieniliśmy już nazwy tabel. W tej linii są drobne zmiany:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Właśnie zaimportowaliśmy wszystko, czego będziemy używać z SQLAlchemy.
Tabele i struktura
Uruchomimy skrypt, wpisując następujące polecenie w powłoce Pythona:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Wynikiem jest wykonany skrypt. Przeanalizujmy teraz resztę skryptu.
SQLAlchemy importuje informacje związane z tabelami, strukturą i relacjami. Aby pracować z tymi informacjami, przydatne może być sprawdzenie listy tabel (i ich kolumn) w bazie danych:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

To po prostu zwraca listę wszystkich tabel z połączonej bazy danych.
Uwaga: table_names() Metoda zwraca listę nazw tabel dla danego silnika. Możesz wydrukować całą listę lub iterować ją za pomocą pętli (tak jak w przypadku każdej innej listy).
Następnie zwrócimy listę wszystkich atrybutów z wybranej tabeli. Odpowiednia część skryptu i wynik są pokazane poniżej:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
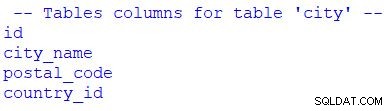
Widać, że użyłem for do pętli zestawu wyników. Moglibyśmy zastąpić table_city.c z table_city.columns .
Uwaga: Proces ładowania opisu bazy danych i tworzenia metadanych w SQLAlchemy nazywa się odbiciem.
Uwaga: MetaData to obiekt, który przechowuje informacje o obiektach w bazie danych, więc tabele w bazie danych są również połączone z tym obiektem. Ogólnie rzecz biorąc, ten obiekt przechowuje informacje o tym, jak wygląda schemat bazy danych. Użyjesz go jako pojedynczego punktu kontaktowego, gdy będziesz chciał wprowadzić zmiany lub uzyskać informacje na temat schematu bazy danych.
Uwaga: Atrybuty autoload = True i autoload_with = engine_live należy użyć, aby upewnić się, że atrybuty tabeli zostaną przesłane (jeśli jeszcze nie zostały).
WYBIERZ
Chyba nie muszę wyjaśniać, jak ważna jest instrukcja SELECT :) Powiedzmy więc, że możesz użyć SQLAlchemy do pisania instrukcji SELECT. Jeśli jesteś przyzwyczajony do składni MySQL, adaptacja zajmie trochę czasu; mimo to wszystko jest całkiem logiczne. Mówiąc najprościej, powiedziałbym, że instrukcja SELECT jest podzielona na kawałki i niektóre części są pominięte, ale wszystko jest nadal w tej samej kolejności.
Wypróbujmy teraz kilka instrukcji SELECT.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Pierwszy to prosta instrukcja SELECT zwracanie wszystkich wartości z podanej tabeli. Składnia tej instrukcji jest bardzo prosta:umieściłem nazwę tabeli w select() . Proszę zauważyć, że:
- Przygotowałem oświadczenie -
stmt = select([table_city]. - Wydrukowano oświadczenie za pomocą
print(stmt), co daje nam dobre wyobrażenie o właśnie wykonanej instrukcji. Może to być również użyte do debugowania. - Wydrukowano wynik za pomocą
print(connection_live.execute(stmt).fetchall()). - Przejrzałem wynik i wydrukowałem każdy pojedynczy rekord.
Uwaga: Ponieważ załadowaliśmy również ograniczenia klucza głównego i obcego do SQLAlchemy, instrukcja SELECT przyjmuje listę obiektów tabeli jako argumenty i automatycznie ustanawia relacje tam, gdzie jest to potrzebne.
Wynik jest pokazany na poniższym obrazku:

Python pobierze wszystkie atrybuty z tabeli i przechowa je w obiekcie. Jak pokazano, możemy użyć tego obiektu do wykonania dodatkowych operacji. Ostatecznym wynikiem naszego zestawienia jest lista wszystkich miast z city tabela.
Teraz jesteśmy gotowi na bardziej złożone zapytanie. Właśnie dodałem klauzulę ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Uwaga: asc() Metoda wykonuje sortowanie rosnąco względem obiektu nadrzędnego, używając zdefiniowanych kolumn jako parametrów.
Zwrócona lista jest taka sama, ale teraz jest posortowana według wartości id, w porządku rosnącym. Należy zauważyć, że po prostu dodaliśmy .order_by( do poprzedniego zapytania SELECT. .order_by(...) Metoda pozwala nam zmienić kolejność zwracanego zestawu wyników w taki sam sposób, jak w zapytaniu SQL. Dlatego parametry powinny być zgodne z logiką SQL, używając nazw kolumn lub kolejności kolumn oraz ASC lub DESC.
Następnie dodamy GDZIE do naszej instrukcji SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Uwaga: .where() Metoda służy do testowania warunku, którego użyliśmy jako argumentu. Możemy również użyć .filter() metoda, która jest lepsza w filtrowaniu bardziej złożonych warunków.
Jeszcze raz .where część jest po prostu łączona z naszą instrukcją SELECT. Zauważ, że umieściliśmy warunek w nawiasach. Jakikolwiek warunek znajduje się w nawiasach, jest testowany w taki sam sposób, jak w części WHERE instrukcji SELECT. Warunek równości jest testowany za pomocą ==zamiast =.
Ostatnią rzeczą, jaką wypróbujemy z SELECT, jest połączenie dwóch stołów. Przyjrzyjmy się najpierw kodowi i jego wynikowi.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Powyższe stwierdzenie składa się z dwóch ważnych części:
select([table_city.columns.city_name, table_country.columns.country_name])określa, które kolumny zostaną zwrócone w naszym wyniku..select_from(table_city.join(table_country))definiuje warunek/tabela łączenia. Zauważ, że nie musieliśmy zapisywać pełnego warunku złączenia, w tym kluczy. Dzieje się tak, ponieważ SQLAlchemy „wie”, jak te dwie tabele są połączone, ponieważ klucze podstawowe i reguły kluczy obcych są importowane w tle.
WSTAW / AKTUALIZUJ / USUŃ
Oto trzy pozostałe polecenia DML, które omówimy w tym artykule. Chociaż ich struktura może być bardzo złożona, polecenia te są zwykle znacznie prostsze. Użyty kod przedstawiono poniżej.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Ten sam wzorzec jest stosowany do wszystkich trzech instrukcji:przygotowania instrukcji, wydrukowania i wykonania jej oraz wydrukowania wyniku po każdej instrukcji, abyśmy mogli zobaczyć, co faktycznie wydarzyło się w bazie danych. Zauważ jeszcze raz, że części instrukcji zostały potraktowane jako obiekty (.values(), .where()).

Wykorzystamy tę wiedzę w nadchodzącym artykule, aby zbudować cały skrypt ETL przy użyciu SQLAlchemy.
Dalej:SQLAlchemia w procesie ETL
Dzisiaj przeanalizowaliśmy, jak skonfigurować SQLAlchemy i jak wykonywać proste polecenia DML. W następnym artykule wykorzystamy tę wiedzę do napisania pełnego procesu ETL przy użyciu SQLAlchemy.
Możesz pobrać cały skrypt użyty w tym artykule tutaj.