Przede wszystkim musisz zdecydować, czy chcesz utrzymać trwałe połączenie z MySQL. Ten ostatni działa lepiej, ale wymaga niewielkiej konserwacji.
Domyślne wait_timeout
w MySQL wynosi 8 godzin. Gdy połączenie jest bezczynne dłużej niż wait_timeout zamknięte. Po ponownym uruchomieniu serwera MySQL zamyka on również wszystkie nawiązane połączenia. Tak więc, jeśli używasz stałego połączenia, musisz sprawdzić przed użyciem połączenia, czy jest ono aktywne (a jeśli nie, połącz się ponownie). Jeśli używasz połączenia na żądanie, nie musisz utrzymywać stanu połączenia, ponieważ połączenie jest zawsze świeże.
Na żądanie połączenia
Nietrwałe połączenie z bazą danych ma ewidentne obciążenie związane z otwieraniem połączenia, uzgadnianiem i tak dalej (zarówno dla serwera bazy danych, jak i klienta) na każde przychodzące żądanie HTTP.
Oto cytat z oficjalnego samouczka Flask dotyczącego połączeń z bazami danych :
Pamiętaj jednak, że kontekst aplikacji jest inicjowany na żądanie (co jest nieco ukryte przez problemy z wydajnością i żargon Flask). A zatem nadal jest bardzo nieefektywny. Powinno to jednak rozwiązać Twój problem. Oto pozbawiony fragmentu tego, co sugeruje jako zastosowane do pymysql :
import pymysql
from flask import Flask, g, request
app = Flask(__name__)
def connect_db():
return pymysql.connect(
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per request.'''
if not hasattr(g, 'db'):
g.db = connect_db()
return g.db
@app.teardown_appcontext
def close_db(error):
'''Closes the database connection at the end of request.'''
if hasattr(g, 'db'):
g.db.close()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Stałe połączenie
W przypadku stałego połączenia z bazą danych istnieją dwie główne opcje. Albo masz pulę połączeń, albo mapujesz połączenia na procesy robocze. Ponieważ normalnie aplikacje Flask WSGI są obsługiwane przez serwery wątkowe ze stałą liczbą wątków (np. uWSGI), mapowanie wątków jest łatwiejsze i równie wydajne.
Jest pakiet DBUtils
, który implementuje oba, oraz PersistentDB
dla połączeń z mapowaniem wątków.
Jednym z ważnych zastrzeżeń w utrzymywaniu trwałego połączenia są transakcje. Interfejs API do ponownego połączenia to ping
. Jest bezpieczny w przypadku automatycznego zatwierdzania pojedynczych instrukcji, ale może zakłócać między transakcjami (trochę więcej szczegółów tutaj
). DBUtils zajmuje się tym i powinien ponownie łączyć się tylko w przypadku dbapi.OperationalError i dbapi.InternalError (domyślnie kontrolowane przez failures do inicjatora PersistentDB ) podniesiony poza transakcją.
Oto jak powyższy fragment będzie wyglądał z PersistentDB .
import pymysql
from flask import Flask, g, request
from DBUtils.PersistentDB import PersistentDB
app = Flask(__name__)
def connect_db():
return PersistentDB(
creator = pymysql, # the rest keyword arguments belong to pymysql
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per app.'''
if not hasattr(app, 'db'):
app.db = connect_db()
return app.db.connection()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Mikrobenchmark
Aby dać małą wskazówkę, jaki wpływ na wydajność mają liczby, oto mikro-benchmark.
Biegłem:
uwsgi --http :5000 --wsgi-file app_persistent.py --callable app --master --processes 1 --threads 16uwsgi --http :5000 --wsgi-file app_per_req.py --callable app --master --processes 1 --threads 16
Przetestowałem je obciążeniowe ze współbieżnością 1, 4, 8, 16 za pomocą:
siege -b -t 15s -c 16 https://localhost:5000/?city=london
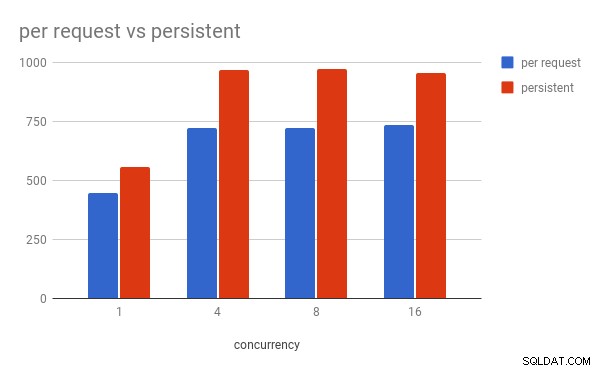
Obserwacje (dla mojej lokalnej konfiguracji):
- Stałe połączenie jest ~30% szybsze,
- W przypadku współbieżności 4 i wyższych, proces roboczy uWSGI osiąga szczyty przy ponad 100% wykorzystania procesora (
pymysqlmusi parsować protokół MySQL w czystym Pythonie, co jest wąskim gardłem), - Przy współbieżności 16,
mysqldWykorzystanie procesora wynosi ~55% na żądanie i ~45% na trwałe połączenie.