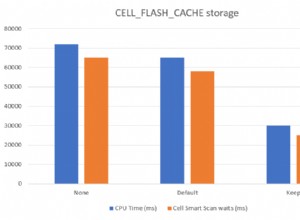
Nie ma gwarancji, że maks. grupowa będzie działać. W rzeczywistości MariaDB ją zepsuła, ale zapewniła ustawienie, aby ją odzyskać. Mam na myśli to:
SELECT *
FROM
( SELECT ... ORDER BY ... )
GROUP BY ...
gdzie chcesz pierwszy (lub ostatni) w każdej grupie z wewnętrznego zapytania. Problem polega na tym, że SQL może zoptymalizować tę intencję.
Grupowy kod max w dokumentach jest strasznie nieefektywny.
Aby przyspieszyć zapytanie, prawdopodobnie pomocne będzie odizolowanie Rules lub Places część klauzuli WHERE i przekształć ją w podzapytanie, które zwraca tylko KLUCZ PODSTAWOWY odpowiedniej tabeli. Następnie umieść to w JOIN ze wszystkimi stołami (w tym JOIN z powrotem do tego samego stołu). Masz już „indeks pokrywający” dla tego podzapytania, więc może to być „Korzystanie z indeksu” (w żargonie używanym przez EXPLAIN).
Czy innodb_buffer_pool_size jest ustawione na około 70% dostępnej pamięci RAM?
BIGINT zajmuje 8 bajtów; prawdopodobnie mógłbyś żyć ze MEDIUMINT UNSIGNED (0..16M). Mniejsze --> więcej pamięci podręcznej --> mniej I/O --> szybsze.
Para DOUBLE dla lat/lng zajmuje 16 bajtów. Para FLOAT zajęłaby 8 bajtów i miałaby rozdzielczość 6 stóp/2m. Lub DECIMAL(6,4) dla szerokości geograficznej i (7,4) dla długości geograficznej dla 7 bajtów i rozdzielczości 52 stóp/16m. Wystarczająco dobre dla „sklepów”, zwłaszcza, że używasz „kwadratu” zamiast „kółka” do określania odległości.
Kod „znajdź najbliższy...” jest trudny do zoptymalizowania. Oto najlepsze, jakie wymyśliłem:https://mysql.rjweb.org/doc .php/latlng