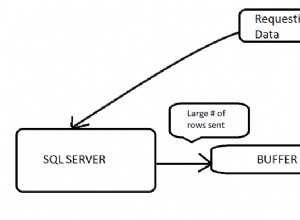
Próbujesz załadować do pamięci RAM za dużo danych . Najpierw należy zmniejszyć ilość danych pobieranych przez SQL, zanim osiągnie Spark i zoptymalizuj go za pomocą parametrów iskry, na przykład partycji .
Rozważ jedną lub więcej z tych optymalizacji:
- Określ w
SELECTjakie kolumny wyświetlić wprost, tylko te, których potrzebujesz, jeśli to możliwe; - (Zapytanie surowe) Pętla w
whilecykl aż będziesz mógłfetchwiersze, zapętlając każdy wiersz. Poniższe techniki mogą działać poprzez ustawienie stałejn_rowsczytać w pamięci i aktualizowaćiindeksuj każdą jazdę na rowerze:
LIMIT i,i+n_rows
BETWEEN i AND i+n_rows
WHILE primaryKey >= i AND primaryKey < i+n_rows
- Korzystanie z partycji . Użyj
partitionColumn,lowerBound,upperBoundinumPartitions(odniesienie 1) i (odniesienie 2) :
partitionColumn wybierz kolumnę, która będzie używana do określenia sposobu podziału danych (na przykład klucz podstawowy ).
lowerBound ustala wartość minimalną z partitionColumn które zostaną pobrane.
upperBound ustala wartość maksymalną z partitionColumn które zostaną pobrane.
numPartitions oznacza ile równoległych połączeń chcesz ustawić do odczytu danych przez RDBMS.
Tak więc Spark pobierze zestawy danych za pomocą wierszy, które otrzymasz, gdy wykonasz SELECT * FROM table WHERE partitionColumn BETWEEN lowerBound AND upperBound .